Python 中数据类型可以分为 数字型 和 ⾮数字型
数字型:整型 ( int )、浮点型( float )、布尔型( bool )、复数型 ( complex )
非数字型:字符串、列表、元组、字典
在 Python 中,所有 ⾮数字型变量 都⽀持以下特点:
1. 都是⼀个 序列 sequence ,也可以理解为 容器
2. 取值 []
3. 遍历 for in
4. 计算⻓度、最⼤/最⼩值、⽐较、删除
5. 链接 + 和 重复 *
6. 切⽚
切⽚ 使⽤ 索引值 来限定范围,从⼀个⼤的 字符串 中 切出 ⼩的 字符串
列表 和 元组 都是 有序 的集合,都能够 通过索引值 获取到对应的数据
字典 是⼀个 ⽆序 的集合,是使⽤ 键值对 保存数据
一、列表(相当于java的数组)
列表是有序的集合
列表的定义
List (列表) 是 Python 中使⽤ 最频繁 的数据类型,在其他语⾔中通常叫做 数组
专⻔⽤于存储 ⼀串 数据,存储的数据 称为 元素
列表⽤ [] 定义,元素 之间使⽤ , 分隔
列表的 索引 从 0 开始
注意:从列表中取值时,如果 超出索引范围,程序会报错
列表常⽤操作
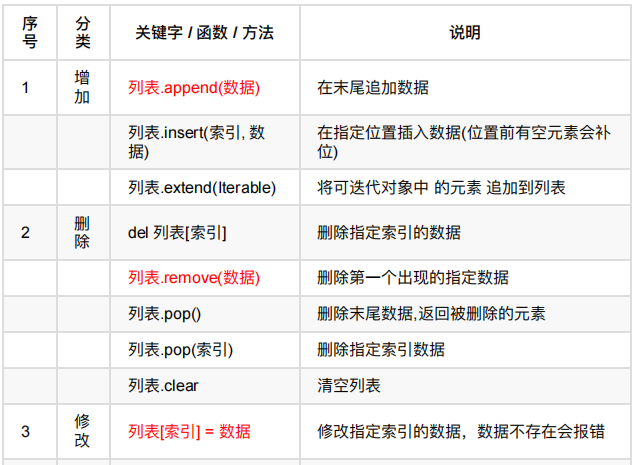
1、循环遍历
遍历 就是 从头到尾 依次 从 列表 中取出 每⼀个元素,并执⾏相同的操作
Python中实现遍历的⽅式很多,⽐如while循环、for循环、迭代器等
# while循环实现列表的遍历 i = 0 name_list = ["zhangsan", "lisi", "wangwu"] list_count = len(name_list) while i < list_count: name = name_list[i] print(name) i += 1
Python为了提⾼列表的遍历效率,专⻔提供 for循环 实现遍历
Python中for循环的本质是 迭代器
# for 实现列表的遍历 for name in name_list: 循环内部针对列表元素进⾏操作 print(name)
2、列表嵌套
schoolNames = [['北京⼤学','清华⼤学'], ['南开⼤学','天津⼤学','天津师范⼤学'], ['⼭东⼤学','中国海洋⼤学']]
示例:⼀个学校,有3个办公室,现在有8位⽼师等待⼯位的分配,请编写程序: 1> 完成随机的分配 2> 获取办公室信息 (每个办公室中的⼈数,及分别是谁)
import random # 定义⼀个列表⽤来保存3个办公室 offices = [[],[],[]] # 定义⼀个列表⽤来存储8位⽼师的名字 names = ['A','B','C','D','E','F','G','H'] # 完成随机分配 i = 0 for name in names: index = random.randint(0,2) offices[index].append(name) # 获取办公室信息 i = 1 for tempNames in offices: print('办公室%d的⼈数为:%d'%(i,len(tempNames))) i+=1 for name in tempNames: print("%s"%name,end='') print("\n") print("-"*20)
结果:
办公室1的⼈数为:2 EF -------------------- 办公室2的⼈数为:4 BCGH -------------------- 办公室3的⼈数为:2 AD --------------------
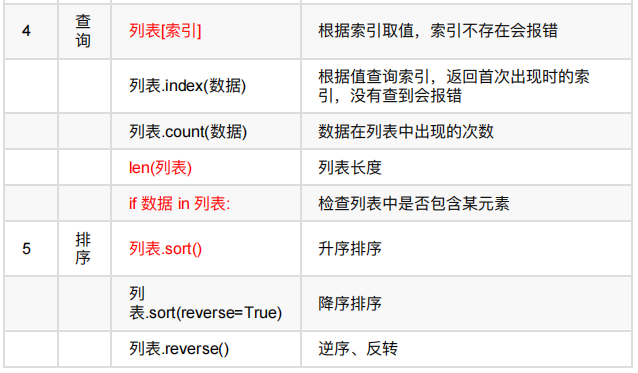
二、元组
元组是有序的集合
元组的定义
元组⽤ () 定义
⽤于存储 ⼀串 数据,元素 之间使⽤ , 分隔
元组的 索引 从 0 开始
# 定义元组 info_tuple = ("zhangsan", 18, 1.75) # 取出元素的值 print(info_tuple[0]) # 输出:zhangsan
元组中 只包含⼀个元素 时,需要 在元素后⾯添加逗号
info_tuple = (50, )
元组常⽤操作
Tuple (元组)与列表类似,不同之处在于元组的 元素不能修改
info_tuple = ("zhangsan", 18, 1.75) info_tuple[0] = "lisi" # 程序报错
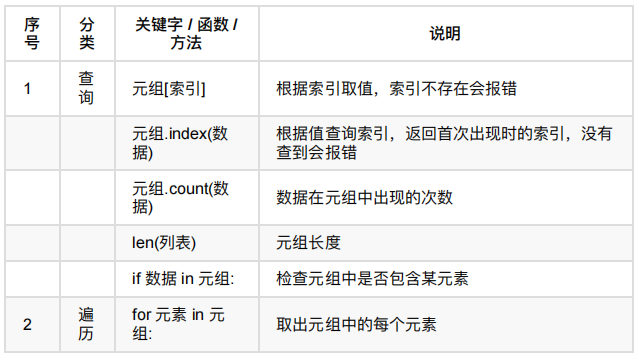
应⽤场景
1、作为⾃动组包的默认类型
info = 10, 20 print(type(info)) # 输出类型为 tuple # 交换变量的值 a = 10 b = 20 a, b = b, a # 先⾃动组包,后⾃动解包 print("a的值为%d"%a) print("b的值为%d"%b)
结果:
<class 'tuple'> a的值为20 b的值为10
2、格式字符串,格式化字符串后⾯的 () 本质上就是⼀个元组
info = ("zhangsan", 18) print("%s 的年龄是 %d" % info)
print("%s 的年龄是 %d" %("zhangsan", 18))
结果:zhangsan 的年龄是 18
3、让列表不可以被修改,以保护数据安全
4、元组和列表之间的转换
# 元组和列表之间的转换 # 使⽤ `tuple` 函数 把列表转换成元组 list1 = [10, 11] tuple1 = tuple(list1) # 使⽤ `list` 函数 把元组转换成列表 # list1 = list(tuple1)
三、字典(相当于json)
字典是无序的集合
字典的定义
1)、dictionary (字典) 是 除列表以外 Python 之中 最灵活 的数据类型
2)、字典同样可以⽤来 存储多个数据,常⽤于存储 描述⼀个 物体 的相关信息
3)、字典⽤ {} 定义
4)、字典使⽤ 键值对 存储数据,键值对之间使⽤ , 分隔
键 key 是索引
值 value 是数据
键 和 值 之间使⽤ : 分隔
值 可以取任何数据类型,但 键 只能使⽤ 字符串、数字或 元组
键必须是唯⼀的

# 定义字典 xiaoming = { "name": "⼩明", "age": 18, "gender": True, "height": 1.75 } # 取出元素的值 print(xiaoming["name"]) # 输出: ⼩明
字典常⽤操作
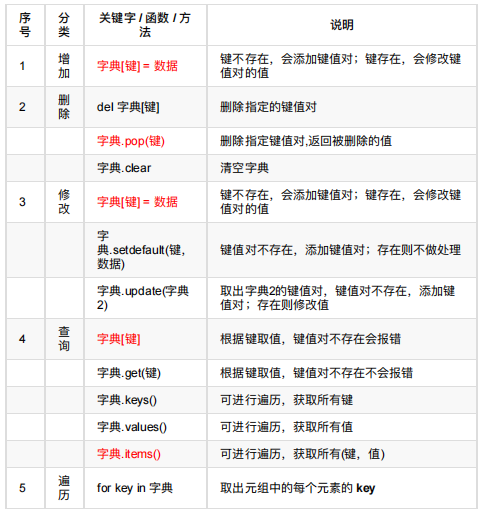
应⽤场景
在开发中,字典的应⽤场景是:
使⽤ 多个键值对,存储 描述⼀个 物体 的相关信息 —— 描述更复杂的数据信息
将 多个字典 放在 ⼀个列表 中,再进⾏遍历,在循环体内部针对每⼀个字典进⾏相同的处理
card_list = [
{"name": "张三", "qq": "12345", "phone": "110"},
{"name": "李四", "qq": "54321", "phone": "10086"}
]
四、字符串
字符串的定义
1)、字符串 就是 ⼀串字符,是编程语⾔中表示⽂本的数据类型
2)、在 Python 中可以使⽤ ⼀对双引号 " 或者 ⼀对单引号 ' 定义⼀个字符串
虽然可以使⽤ \" 或者 \' 做字符串的转义,但是在实际开发中:
如果字符串内部需要使⽤ " ,可以使⽤ ' 定义字符串
如果字符串内部需要使⽤ ' ,可以使⽤ " 定义字符串
3)、可以使⽤ 索引 获取⼀个字符串中 指定位置的字符,索引计数从 0 开始
4)、也可以使⽤ for 循环遍历 字符串中每⼀个字符
⼤多数编程语⾔都是⽤ " 来定义字符串
string = "Hello Python" for c in string: print(c)
字符串的常⽤操作
1、判断
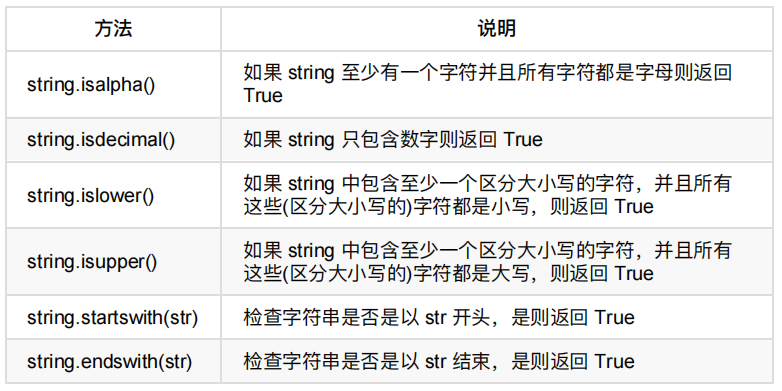
str = "runoob" print (str.isalpha()) # 字母和中文文字 str = "runoob菜鸟教程" print (str.isalpha()) str = "Runoob example....wow" print (str.isalpha())
结果:
True
True
False
str.isdecimal():
str = "runoob2016" print (str.isdecimal()) str = "23443434" print (str.isdecimal())
结果:
False
True
str.islower()
str = "RUNOOB example....wow!!!" print (str.islower()) str = "runoob example....wow!!!" print (str.islower())
结果:
False
True
isupper() 方法检测字符串中所有的字母是否都为大写
str = "THIS IS STRING EXAMPLE....WOW!!!" print (str.isupper()) str = "THIS is string example....wow!!!" print (str.isupper())
结果:
True
False
startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
str = "this is string example....wow!!!" print (str.startswith( 'this' )) # 字符串是否以 this 开头 print (str.startswith( 'string', 8 )) # 从第九个字符开始的字符串是否以 string 开头 print (str.startswith( 'this', 2, 4 )) # 从第2个字符开始到第四个字符结束的字符串是否以 this 开头
结果:
True
True
False
endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回 True,否则返回 False。可选参数 "start" 与 "end" 为检索字符串的开始与结束位置
Str='Runoob example....wow!!!' suffix='!!' print (Str.endswith(suffix)) print (Str.endswith(suffix,20)) suffix='run' print (Str.endswith(suffix)) print (Str.endswith(suffix, 0, 19))
结果:
True
True
False
False

find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。
str1 = "Runoob example....wow!!!" str2 = "exam"; print(str1.find(str2)) print(str1.find(str2, 5)) print(str1.find(str2, 10))
结果:
7 7 -1
rfind() 返回字符串最后一次出现的位置,如果没有匹配项则返回-1
str1 = "this is really a string example....wow!!!" str2 = "is" print (str1.rfind(str2)) print (str1.rfind(str2, 0, 10)) print (str1.rfind(str2, 10, 0)) print (str1.find(str2)) print (str1.find(str2, 0, 10)) print (str1.find(str2, 10, 0))
结果:
5 5 -1 2 2 -1
index() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常
str1 = "Runoob example....wow!!!" str2 = "exam"; print (str1.index(str2)) print (str1.index(str2, 5)) print (str1.index(str2, 10))
结果:
Traceback (most recent call last): File "D:\project\python\04-non-numericType.py", line 88, in <module> print (str1.index(str2, 10)) ValueError: substring not found 7 7
rindex() 返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常,你可以指定可选参数[beg:end]设置查找的区间。
str1 = "this is really a string example....wow!!!" str2 = "is" print (str1.rindex(str2)) print (str1.rindex(str2,10))
结果:
Traceback (most recent call last): File "D:\project\python\04-non-numericType.py", line 95, in <module> print (str1.rindex(str2,10)) ValueError: substring not found 5
replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
str = "www.w3cschool.cc" print("菜鸟教程旧地址:", str) print("菜鸟教程新地址:", str.replace("w3cschool.cc", "runoob.com")) str = "this is string example....wow!!!" print(str.replace("is", "was", 3))
结果:
菜鸟教程旧地址: www.w3cschool.cc 菜鸟教程新地址: www.runoob.com thwas was string example....wow!!!
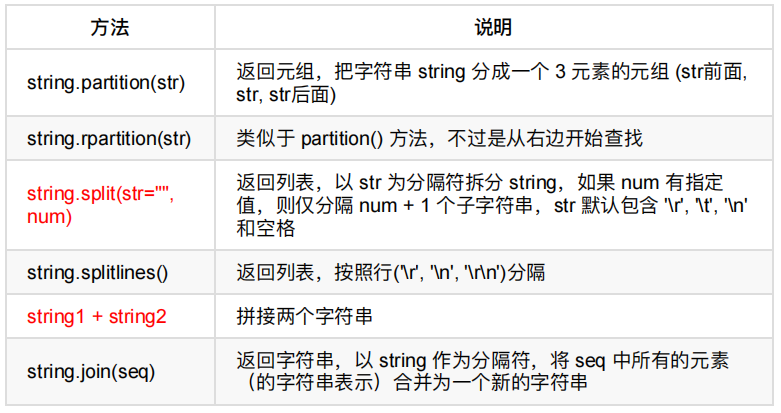
3、拆分和连接
str1 = "this is really a string example....wow!!!" str2 = "is" print (str1.partition(str2)) print (str1.rpartition(str2))
结果:
('th', 'is', ' is really a string example....wow!!!') ('this ', 'is', ' really a string example....wow!!!')
split() 方法通过指定分隔符对字符串进行切片,该方法将字符串分割成子字符串并返回一个由这些子字符串组成的列表。
如果第二个参数 num 有指定值,则分割为 num+1 个子字符串。
split()方法特别适用于根据特定的分隔符将字符串拆分成多个部分。
str = "this is string example....wow!!!" print (str.split()) # 默认以空格为分隔符 print (str.split('i',1)) # 以 i 为分隔符 print (str.split('w')) # 以 w 为分隔符
结果:
['this', 'is', 'string', 'example....wow!!!'] ['th', 's is string example....wow!!!'] ['this is string example....', 'o', '!!!']
splitlines() 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
s1 = "-" s2 = "" seq = ("r", "u", "n", "o", "o", "b") # 字符串序列 print (s1.join( seq )) print (s2.join( seq ))
结果
r-u-n-o-o-b
runoob
4、⼤⼩写转换

5、文本对齐

ljust() 方法返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。
str = "Runoob example....wow!!!" print (str.ljust(50, '*')) print (str.ljust(10, '*'))
结果:
Runoob example....wow!!!**************************
Runoob example....wow!!!
rjust() 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。
str = "this is string example....wow!!!" print (str.rjust(50, '*')) print (str.rjust(10, '*'))
结果:
******************this is string example....wow!!! this is string example....wow!!!
center() 方法返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。
str = "[runoob]" print ("str.center(40, '*') : ", str.center(40, '*'))
结果
str.center(40, '*') : ****************[runoob]****************
6、去除空白字符
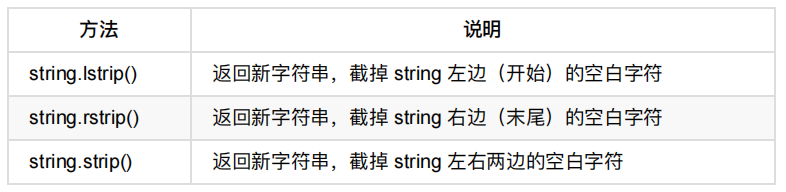
lstrip() 方法用于截掉字符串左边的空格或指定字符。
str = " this is string example....wow!!! "; print( str.lstrip() ); str = "88888888this is string example....wow!!!8888888"; print( str.lstrip('8') );
结果:
this is string example....wow!!! this is string example....wow!!!8888888
rstrip() 删除 string 字符串末尾的指定字符,默认为空白符,包括空格、换行符、回车符、制表符。
random_string = 'this is good ' # 字符串末尾的空格会被删除 print(random_string.rstrip()) # 'si oo' 不是尾随字符,因此不会删除任何内容 print(random_string.rstrip('si oo')) # 在 'sid oo' 中 'd oo' 是尾随字符,'ood' 从字符串中删除 print(random_string.rstrip('sid oo')) # 'm/' 是尾随字符,没有找到 '.' 号的尾随字符, 'm/' 从字符串中删除 website = 'www.runoob.com/' print(website.rstrip('m/.')) # 移除逗号(,)、点号(.)、字母 s、q 或 w,这几个都是尾随字符 txt = "banana,,,,,ssqqqww....." x = txt.rstrip(",.qsw") print(x) # 删除尾随字符 * str = "*****this is string example....wow!!!*****" print (str.rstrip('*'))
结果
this is good this is good this is g www.runoob.co banana *****this is string example....wow!!!
字符串的切⽚
切⽚ 译⾃英⽂单词 slice ,翻译成另⼀个解释更好理解: ⼀部分
切⽚ 使⽤ 索引值 来限定范围,根据 步⻓ 从原序列中 取出⼀部分 元素组成新序列
切⽚ ⽅法适⽤于 字符串、列表、元组
字符串[开始索引:结束索引:步⻓]
注意:
1. 指定的区间属于 左闭右开 型 [开始索引, 结束索引) 对应 开始索引 <= 范围 < 结束索引
从 起始 位开始,到 结束 位的前⼀位 结束(不包含结束位本身)
num_str = "0123456789" # 1. 截取从 2 ~ 5 位置 的字符串 print(num_str[2:6])
结果
2345
2. 从头开始,开始索引 数字可以省略,冒号不能省略
num_str = "0123456789" # 3. 截取从 `开始` ~ 5 位置 的字符串 print(num_str[:6])
结果:
012345
3. 到末尾结束,结束索引 数字和冒号都可以省略
num_str = "0123456789" # 2. 截取从 2 ~ `末尾` 的字符串 print(num_str[2:])
结果:
23456789
截取完整的字符串
num_str = "0123456789" # 4. 截取完整的字符串 print(num_str[:])
结果:0123456789
4. 步⻓默认为 1 ,如果元素连续,数字和冒号都可以省略
num_str = "0123456789" # 5. 从开始位置,每隔⼀个字符截取字符串 print(num_str[::2]) # 6. 从索引 1 开始,每隔⼀个取⼀个 print(num_str[1::2])
结果:
02468 13579
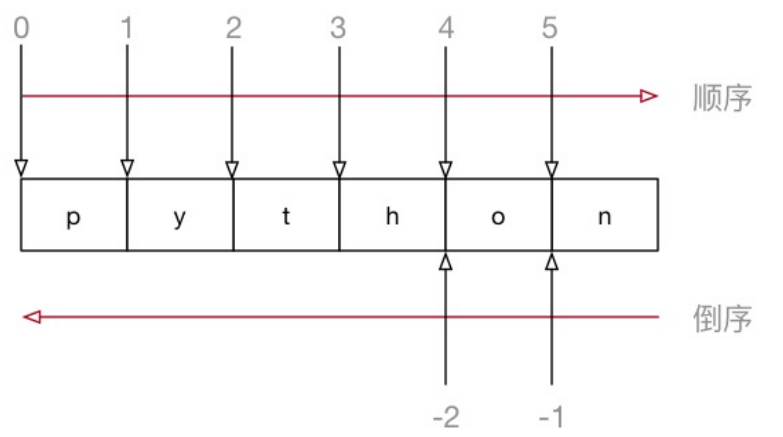
索引的顺序和倒序
1)、在 Python 中不仅⽀持 顺序索引,同时还⽀持 倒序索引
2)、所谓倒序索引就是 从右向左 计算索引,最右边的索引值是 -1,依次递减
3)、注意:如果 步⻓为负数,并省略了开始索引,则开始索引表示最后⼀位,并省略了结束索引,则结束索引表示第⼀位
# 倒序切⽚ # -1 表示倒数第⼀个字符 print(num_str[-1]) # 7. 截取从 2 ~ `末尾 - 1` 的字符串 print(num_str[2:-1]) # 8. 截取字符串末尾两个字符 print(num_str[-2:]) # 9. 字符串的逆序(⾯试题) print(num_str[::-1]) print(num_str[::-2])
结果
9 2345678 89 9876543210 97531
五、set集合
set的特点:无序,没有索引,set中的数据不会重复,格式:{1,2,3,4}
主要作用:列表或元组数据去重,把列表或元组转换成set类型可以数据去重。
list去重:
不使用set去重时的代码:
# 数组去重 如果i与第一次出现的索引相同,则表明是第一次出现,如果不同,表示已经出现过 list1 = [1,2,3,2,1] i = 0 list2 = [] while i < len(list1): element = list1[i] index = list1.index(element) if index == i: list2.append(element) i += 1 print(list2)
使用set去重
list1 = [1,2,3,2,1] list2 = list(set(list1)) print(list2)
结果:
[1, 2, 3]
set、list、tuple之间可以相互转换
tuple去重:
tuple1 = (1,2,1) tuple2 = tuple(set(tuple1)) print(tuple2)
结果:
(1, 2)
六、Python 内置函数
Python 包含了以下内置函数:
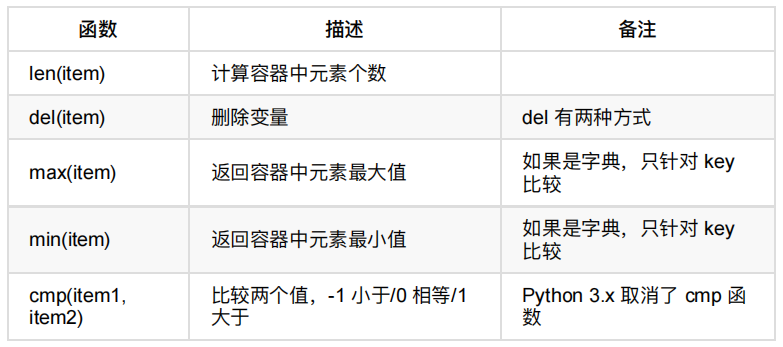
注意:字符串 ⽐较符合以下规则: "0" < "A" < "a"

