一、存储过程(将业务逻辑写入存储过程)
存储过程:就是提前已经编译好的一段PL/SQL语言,放置在数据库,可以直接被调用。这一段PL/SQL一般都是固定步骤的业务。
java是面向对象的编程语言,PL/SQL是面向过程的编程语言,也可以用来写业务逻辑,它和java语言不同的是:如果涉及到数据库操作,java语言想要操作数据库必须从连接池中拿到connection对象,但是PL/SQL语言本身就写在数据库端,它不用连接也可以操作数据库,这是它的一个优势,但是PL/SQL不能写太复杂的业务。
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的 SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。
创建存储过程语法:
存储过程中的参数分in和out两种类型,不写默认为in。
create [or replace] PROCEDURE 过程名[(参数名 in/out 数据类型)] AS begin PLSQL 子程序体; End;
或者(AS可以写成is)
create [or replace] PROCEDURE 过程名[(参数名 in/out 数据类型)] is begin PLSQL 子程序体; End 过程名;
create or replace procedure helloworld is begin dbms_output.put_line('helloworld'); end helloworld;
调用存储过程
在 plsql 中调用存储过程
begin -- Call the procedure helloworld; end;
范例 2:给指定的员工涨 100 工资,并打印出涨前和涨后的工资
分析:我们需要使用带有参数的存储过程
create or replace procedure addSal1(eno in number) is pemp myemp%rowtype; begin select * into pemp from myemp where empno = eno; update myemp set sal = sal + 100 where empno = eno;
commit; dbms_output.put_line('涨工资前' || pemp.sal || '涨工资后' || (pemp.sal + 100)); end addSal1;
pemp为记录型变量,可以存放myemp表的一行记录。上述存储过程是先将eno对应的记录取出来放到myemp表中,修改myemp表的sal为原来的值加100,再提交,最后打印涨工资前和涨工资后的值。
执行之后会发现procedures目录下多了一个存储过程
注意:此时ADDSAL1存储过程添加失败,由于commit后面的分号为中文的分号,故产生错误。修改后重新执行
调用
begin -- Call the procedure addsal1(eno => 7902); commit; end;
二、存储函数
navicat创建函数
点击函数,右键,选择新建函数,进入如下所示页面:
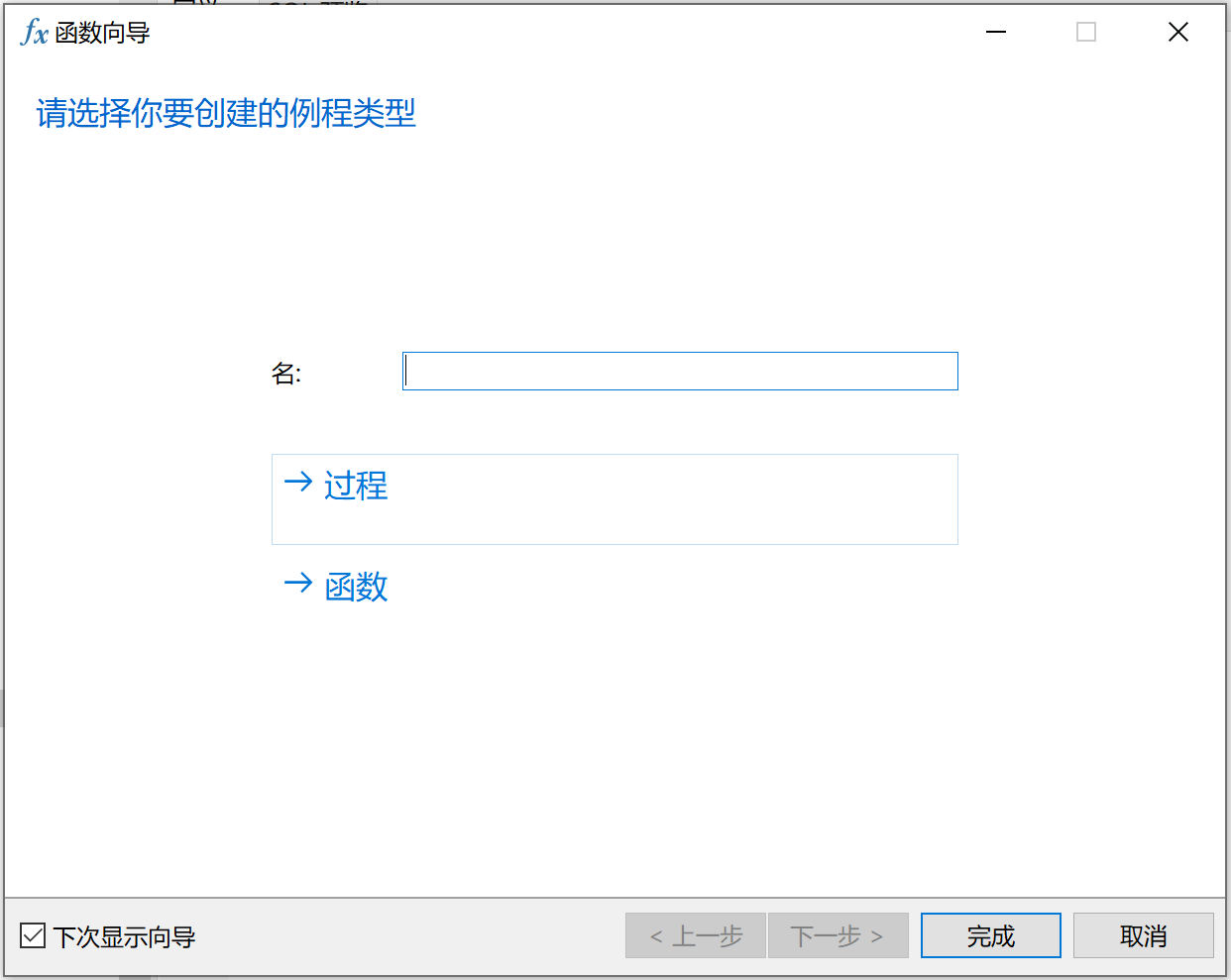
输入函数名,点击函数
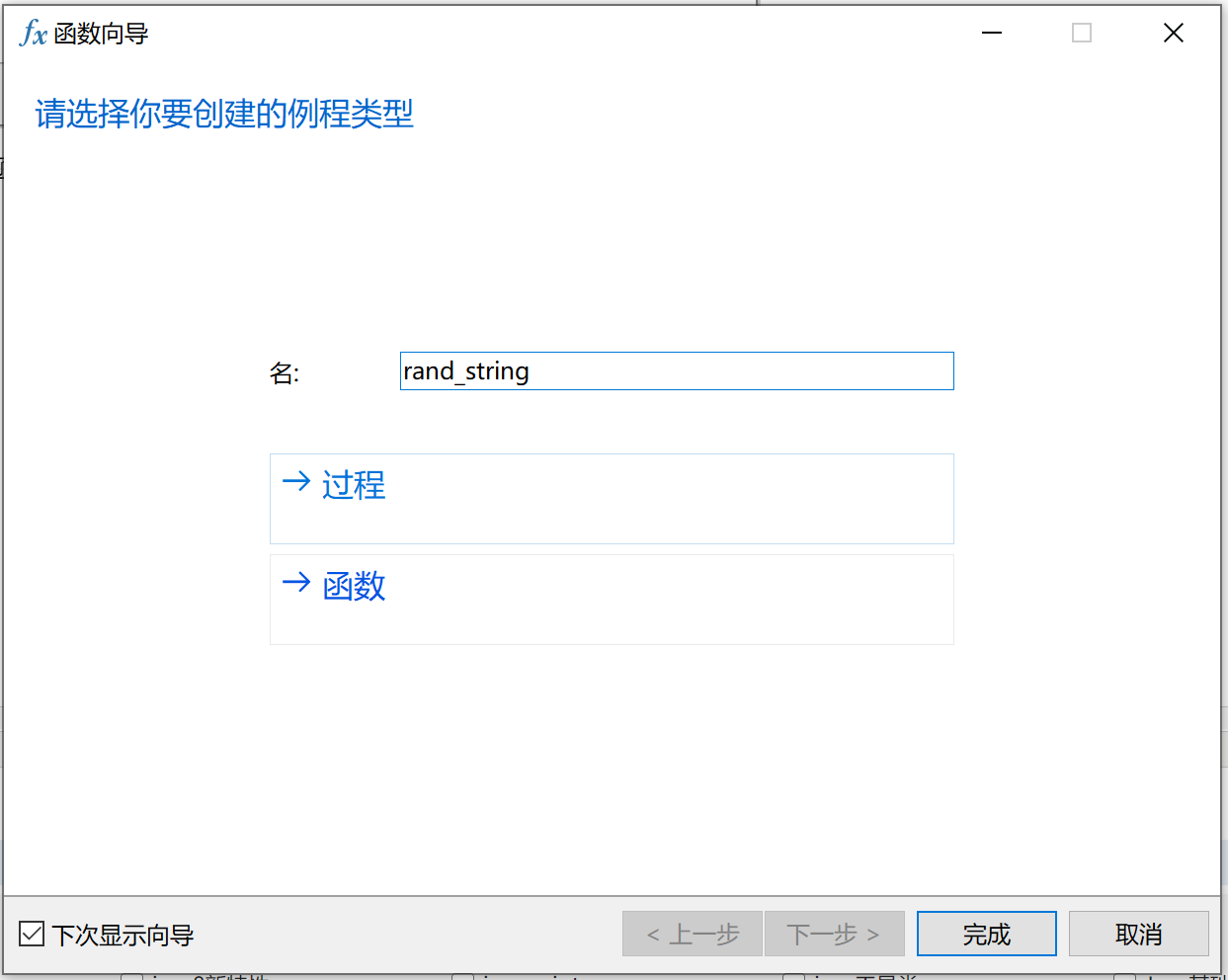
点击函数,输入参数名和参数类型
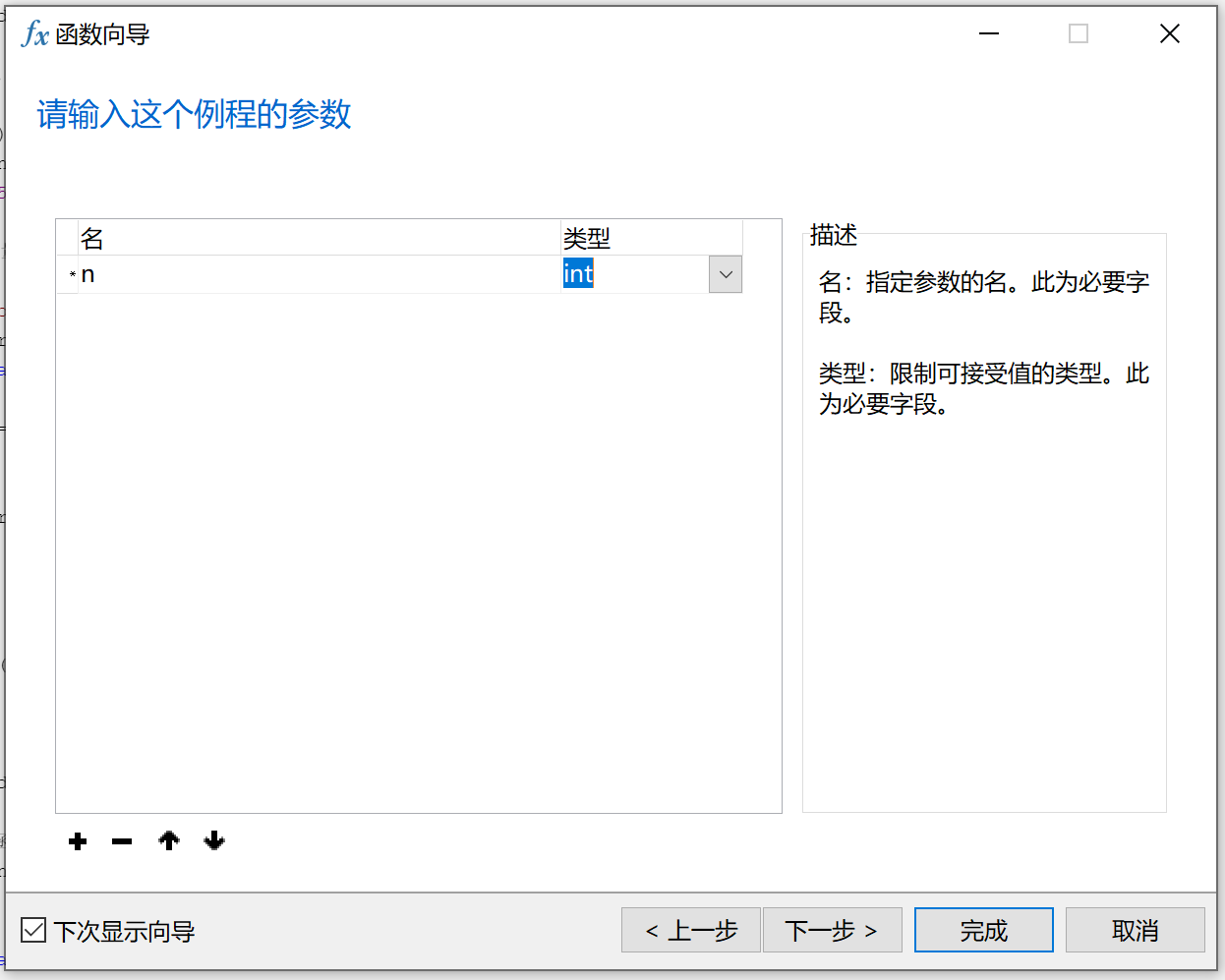
点击完成,进入如下页面:
CREATE DEFINER = CURRENT_USER FUNCTION `rand_string`(`n` int) RETURNS integer BEGIN #Routine body goes here... RETURN 0; END;
编写存储函数:
CREATE DEFINER = CURRENT_USER FUNCTION `rand_string`(`n` int) RETURNS varchar(255) BEGIN #Routine body goes here... declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i = i + 1; end while; return return_str; END;
调用存储函数rand_string
select rand_string(6);
语法:
create or replace function 函数名(Name in type, Name in type, ...) return 数据类型 is 结果变量 数据类型; begin return(结果变量); end 函数名;
注意:
1、存储函数的返回值类型不能带长度。第一个return后面的数据类型如果是number,不能带长度。
2、存储过程和存储函数的参数不能带长度,注意参数不是变量。引用型变量在不需要长度的时候会将长度去掉。
范例:使用存储函数来查询指定员工的年薪
create or replace function empincome(eno in emp.empno%type) return number is psal emp.sal%type; pcomm emp.comm%type; begin select t.sal into psal from emp t where t.empno = eno; return psal * 12 + nvl(pcomm, 0); end;
或者
create or replace function f_yearsal(eno emp.empno%type) return number is s number(10); begin select sal*12 + nvl(comm,0) into s from emp where empno = eno; return s; end;
引用型变量在不需要长度的时候会将长度去掉。故emp.empno%type实际上是没有长度的。
执行完成后,Functions目录就多了一个存储函数
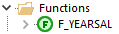
调用:
declare begin f_yearsal(7788); end;
执行发现报错:
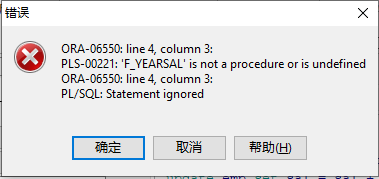
原因:存储函数在调用的时候,返回值需要接收。
declare s number(10); begin s:=f_yearsal(7788); dbms_output.put_line(s); end;
out类型参数如何使用?
mysql调用存储过程
call p_get_codenumber('https://www.tianyancha.com/625abc9e-3a69-4f8d-a688-7a527a7f31bb',@nums); SELECT @nums;
注意:mysql调用存储过程和oracle调用存储过程不一样。
使用存储过程来替换上面的例子
定义一个输出类型的参数income
create or replace procedure empincomep(eno in emp.empno%type, income out number) is psal emp.sal%type; pcomm emp.comm%type; begin select t.sal, t.comm into psal, pcomm from emp t where t.empno = eno; income := psal*12+nvl(pcomm,0); end empincomep;
注意:t.sal, t.comm into psal, pcomm表示分别将sal的值赋值给psal,将comm的值赋值给pcomm。
调用:
declare income number; begin empincomep(7369, income); dbms_output.put_line(income); end;
in和out类型参数的区别是什么?
凡是涉及到into查询语句赋值或者:=赋值操作的参数,都必须使用out来修饰。
存储函数案例1:
CREATE DEFINER=`root`@`%` FUNCTION `getAreaNodeName`(nodeId VARCHAR(50)) RETURNS varchar(100) CHARSET utf8mb4 BEGIN DECLARE parentName VARCHAR(100) DEFAULT ''; DECLARE tempNodeId VARCHAR(100); DECLARE tempName VARCHAR(100); DECLARE nodeIds VARCHAR(100) DEFAULT ''; DECLARE defaultNodeId VARCHAR(100) DEFAULT '401200965'; // 所有省级行政区的父节点ID set nodeIds = nodeId; SELECT chi_short_name,pid INTO tempName, tempNodeId FROM t_area_code where id = nodeId and isvalid = 1; // 根据id查中文和父ID if tempNodeId is null then return concat(parentName,'-',nodeIds); else SET parentName = CONCAT(tempName, parentName); // 将中文名赋值给parentName if tempNodeId !=defaultNodeId then // 如果查询出来的父ID不是省级行政区的父节点ID SET nodeIds = concat(tempNodeId,',',nodeIds); // 将查询出来的父节点ID和输入ID通过逗号进行拼接 end if; end if; WHILE tempNodeId != defaultNodeId do // SELECT chi_short_name,pid INTO tempName,tempNodeId FROM t_area_code where id = tempNodeId and isvalid = 1 limit 1; //再根据父节点id查 SET parentName = CONCAT(tempName, parentName); // 将查询出来的上一级的中文名与下一级进行拼接 if tempNodeId !=defaultNodeId then // 如果查询出来的父节点ID不是省级行政区的父节点ID SET nodeIds = concat(tempNodeId,',',nodeIds); // 将查询出来的父节点ID和前面的节点ID进行拼接 end if; END WHILE; return concat(parentName,'-',nodeIds); // 最后将完整的中文全名和所有的节点ID通过-进行拼接。 END
调用getAreaNodeName函数
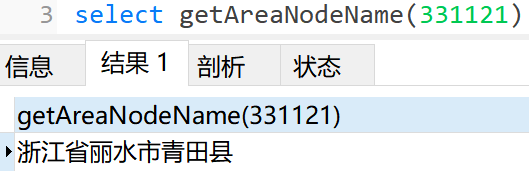
select getAreaNodeName('110111');
结果:北京市市辖区房山区-110000,110100,110111
分析:
第一次执行sql
SELECT chi_short_name as 'tempName',pid as 'tempNodeId' FROM t_area_code where id = '110111' and isvalid = 1;
结果:

此时parentName为房山区,nodeIds为110100,110111.
第二次执行sql
SELECT chi_short_name as 'tempName',pid as 'tempNodeId' FROM t_area_code where id = '110100' and isvalid = 1;
结果:

此时parentName为市辖区房山区,nodeIds为110000,110100,110111
第三次执行sql:
SELECT chi_short_name as 'tempName',pid as 'tempNodeId' FROM t_area_code where id = '110000' and isvalid = 1;
结果:

此时parentName为北京市市辖区房山区
根据区/县编码获取省市区名称
CREATE DEFINER=`root`@`%` FUNCTION `getAreaNodeName`(nodeId VARCHAR(50)) RETURNS varchar(100) CHARSET utf8mb4 BEGIN DECLARE parentName VARCHAR(100) DEFAULT ''; DECLARE tempNodeId VARCHAR(100); DECLARE tempName VARCHAR(100); DECLARE defaultNodeId VARCHAR(100) DEFAULT '401200965'; SELECT chi_short_name,pid INTO tempName, tempNodeId FROM t_area_code where id = nodeId and isvalid = 1; if tempNodeId is null then return concat(parentName); else SET parentName = CONCAT(tempName, parentName); end if; WHILE tempNodeId != defaultNodeId do SELECT chi_short_name,pid INTO tempName,tempNodeId FROM t_area_code where id = tempNodeId and isvalid = 1 limit 1; SET parentName = CONCAT(tempName, parentName); END WHILE; return concat(parentName); END
测试:
逻辑:根据区的编码得到区名称和市编码,再根据市编码得到市名称和省编码,根据省编码得到省名称,拼接成省市区返回。
存储函数案例2:
CREATE DEFINER=`root`@`%` FUNCTION `selectCityAndAreaName`(nodeId VARCHAR(20)) RETURNS varchar(100) CHARSET utf8mb4 BEGIN DECLARE cityName VARCHAR(100); DECLARE areaName VARCHAR(100) DEFAULT ''; DECLARE tempName VARCHAR(100); DECLARE tempNodeId VARCHAR(20); DECLARE tempLevel VARCHAR(20); -- 根据 SELECT chi_short_name,pid,area_level INTO tempName, tempNodeId,tempLevel FROM t_area_code where id = nodeId and isvalid = 1 and area_level <> 1; if (tempLevel = 2) then set cityName = tempName; elseif (tempLevel = 3) then set areaName = CONCAT('-',tempName); // -区名,如-章丘区 SELECT chi_short_name,pid INTO tempName, tempNodeId FROM t_area_code where id = tempNodeId and isvalid = 1; set cityName = tempName; // 市名,如济南市 end if; if (cityName = '市辖区') then SELECT chi_short_name INTO tempName FROM t_area_code where id = tempNodeId and isvalid = 1; set cityName = tempName; // 如果是市辖区,就再往上一级,如北京市 elseif (cityName like '%直辖县级行政区划') then SELECT chi_short_name INTO tempName FROM t_area_code where id = tempNodeId and isvalid = 1; set cityName = concat(tempName,'直辖县级行政区划'); // 如果包含直辖县级行政区划,则再往上一级,如河南省省直辖县级行政区划 end if; return concat(cityName,areaName); // 将市名和区名连接 END
解析:
(1)、先根据region查询t_area_code获取记录
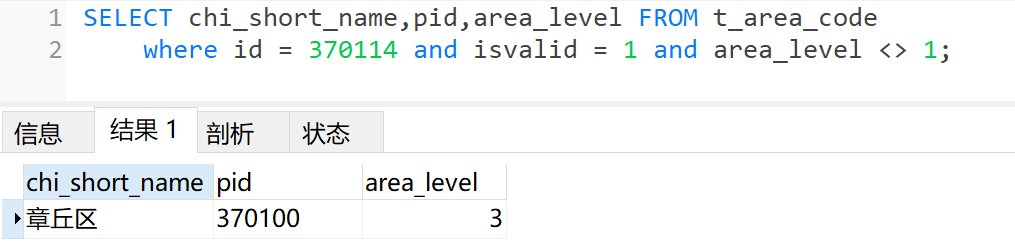
(2)、再根据pid查询上一级的记录

三、存储过程和存储函数的区别
一般来讲,过程和函数的区别在于函数可以有一个返回值;而过程没有返回值。
但过程和函数都可以通过 out 指定一个或多个输出参数。我们可以利用 out 参数,在过程和函数中实现返回多个值。
四、造数据
一个表中怎么样都得有四百万五百万数据,甚至1000万数据去测试。
压力测试脚本如下:
#创建表DEPT CREATE TABLE dept( /*部门表*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, dname VARCHAR(20) NOT NULL DEFAULT "", loc VARCHAR(13) NOT NULL DEFAULT "" ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; #创建表EMP雇员 CREATE TABLE emp (empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/ job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/ mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/ hiredate DATE NOT NULL,/*入职时间*/ sal DECIMAL(7,2) NOT NULL,/*薪水*/ comm DECIMAL(7,2) NOT NULL,/*红利*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/ )ENGINE=MyISAM DEFAULT CHARSET=utf8 ; #工资级别表 CREATE TABLE salgrade ( grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, losal DECIMAL(17,2) NOT NULL, hisal DECIMAL(17,2) NOT NULL )ENGINE=MyISAM DEFAULT CHARSET=utf8; INSERT INTO salgrade VALUES (1,700,1200); INSERT INTO salgrade VALUES (2,1201,1400); INSERT INTO salgrade VALUES (3,1401,2000); INSERT INTO salgrade VALUES (4,2001,3000); INSERT INTO salgrade VALUES (5,3001,9999); # 随机产生字符串 #定义一个新的命令结束符号$$,Delimiter就是告诉MySQL解释器,该段命令是否已经结束了,MySQL是否可以执行了。默认情况下,delimiter是分号;。在命令行客户端中,如果有一行命令以分号结束,
#那么回车后,mysql将会执行该命令。事先把delimiter换成其它符号,如//或$$,这样只有当//出现之后,mysql解释器才会执行这段语句 delimiter $$ #删除自定的函数 drop function rand_string $$ #这里我创建了一个函数. #rand_string(n INT) rand_string 是函数名 (n INT) //该函数接收一个整数 create function rand_string(n INT) returns varchar(255) #该函数会返回一个字符串 begin #chars_str定义一个变量 chars_str,类型是 varchar(100),默认值'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1)); #chars_str为要被截取的字符串,floor(1+rand()*52)为起始位置,1表示截取一位。 set i = i + 1; end while; return return_str; end $$ delimiter ; #定义一个新的命令结束符号; select rand_string(6); # 随机产生部门编号 delimiter $$ #定义一个新的名利结束符号$$ drop function rand_num $$ #这里我们又自定了一个函数 create function rand_num( ) returns int(5) begin declare i int default 0; set i = floor(10+rand()*500); #得到一个大于等于10小于510的整数 return i; end $$ delimiter ; # 定义一个新的命令结束符号; select rand_num(); #****************************************** #向emp表中插入记录(海量的数据) delimiter $$ #定义新的命令结束符号$$ drop procedure insert_emp $$ #随即添加雇员[光标] 500w create procedure insert_emp(in start int(10),in max_num int(10)) begin declare i int default 0; #set autocommit =0 把autocommit设置成0 set autocommit = 0; repeat set i = i + 1; insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num()); // 当start为1时,start+i的最小值为2。注意,只有empno、ename、deptno不同 until i = max_num end repeat; commit; end $$ delimiter ; #定义一个新的命令结束符号; #调用刚刚写好的函数, 1800000条记录,从100001号开始 call insert_emp(1,5000000); #************************************************************** # 向dept表中插入记录 delimiter $$ #定义一个新的命令结束符号$$ drop procedure insert_dept $$ create procedure insert_dept(in start int(10),in max_num int(10)) begin declare i int default 0; set autocommit = 0; repeat set i = i + 1; insert into dept values ((start+i) ,rand_string(10),rand_string(8)); #当start为100时,start+i的最小值为101,deptno、dname、loc均不同 until i = max_num end repeat; commit; end $$ delimiter ; call insert_dept(100,10); #------------------------------------------------ #向salgrade 表插入数据 delimiter $$ #定义一个新的命令结束符号$$ drop procedure insert_salgrade $$ create procedure insert_salgrade(in start int(10),in max_num int(10)) begin declare i int default 0; set autocommit = 0; ALTER TABLE emp DISABLE KEYS; repeat set i = i + 1; insert into salgrade values ((start+i) ,(start+i),(start+i)); until i = max_num end repeat; commit; end $$ delimiter ; #测试不需要了 #call insert_salgrade(10000,1000000);
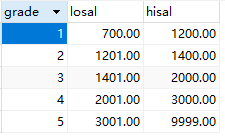
salgrade表如下:
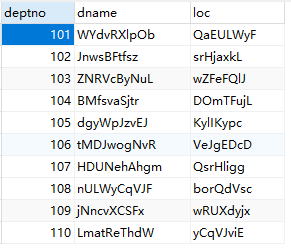
dept表如下:
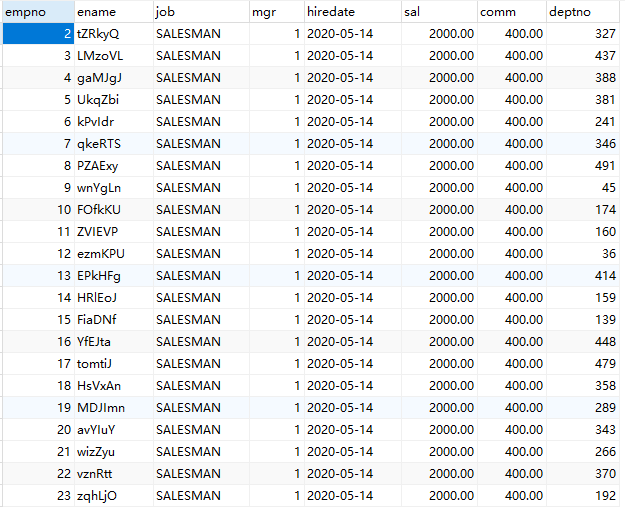
emp表如下:共有500万条记录。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号