一、传统集合的多步遍历代码
public class Demo01ForEach { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("张强"); list.add("张三丰"); for (String name : list) { System.out.println(name); } } }
这是一段非常简单的集合遍历操作:对集合中的每一个字符串都进行打印输出操作。
循环遍历的弊端
Java 8的Lambda让我们可以更加专注于做什么(What),而不是怎么做(How),这点此前已经结合内部类进行了对比说明。现在,我们仔细体会一下上例代码,可以发现:
• for循环的语法就是“怎么做”
• for循环的循环体才是“做什么”
为什么使用循环?因为要进行遍历。但循环是遍历的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从第一个到最后一个顺次处理的循环。前者是目的,后者是方式。
试想一下,如果希望对集合中的元素进行筛选过滤:
1. 将集合A根据条件一过滤为子集B;
2. 然后再根据条件二过滤为子集C。
那怎么办?在Java 8之前的做法可能为:
public class Demo02NormalFilter { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("张强"); list.add("张三丰"); List<String> zhangList = new ArrayList<>(); for (String name : list) { if (name.startsWith("张")) { zhangList.add(name); } } List<String> shortList = new ArrayList<>(); for (String name : zhangList) { if (name.length() == 3) { shortList.add(name); } } for (String name : shortList) { System.out.println(name); } } }
这段代码中含有三个循环,每一个作用不同:
1. 首先筛选所有姓张的人;
2. 然后筛选名字有三个字的人;
3. 最后进行对结果进行打印输出。
每当我们需要对集合中的元素进行操作的时候,总是需要进行循环、循环、再循环。这是理所当然的么?不是。循环是做事情的方式,而不是目的。另一方面,使用线性循环就意味着只能遍历一次。如果希望再次遍历,只能再使用另一个循环从头开始。
那,Lambda的衍生物Stream能给我们带来怎样更加优雅的写法呢?
public class Demo03StreamFilter { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("张强"); list.add("张三丰"); list.stream() .filter(s ‐> s.startsWith("张")) .filter(s ‐> s.length() == 3) .forEach(System.out::println); } }
直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:获取流、过滤姓张、过滤长度为3、逐一打印。代码中并没有体现使用线性循环或是其他任何算法进行遍历,我们真正要做的事情内容被更好地体现在代码中。
注意:forEach方法的参数为函数式接口,所以才能使用方法引用。
void forEach(Consumer<? super T> action);
二、流式思想概述
注意:请暂时忘记对传统IO流的固有印象!
整体来看,流式思想类似于工厂车间的“生产流水线”。
当需要对多个元素进行操作(特别是多步操作)的时候,考虑到性能及便利性,我们应该首先拼好一个“模型”步骤方案,然后再按照方案去执行它。
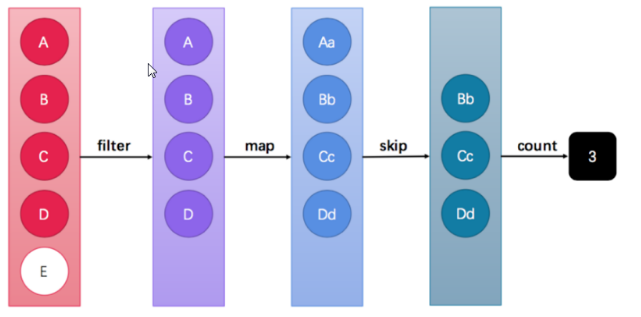
这张图中展示了过滤、映射、跳过、计数等多步操作,这是一种集合元素的处理方案,而方案就是一种“函数模型”。图中的每一个方框都是一个“流”,调用指定的方法,可以从一个流模型转换为另一个流模型。而最右侧的数字3是最终结果。
备注:“Stream流”其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)。
Stream(流)是一个来自数据源的元素队列
• 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
• 数据源 流的来源。 可以是集合,数组 等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
• Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(flfluentstyle)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
•内部迭代: 以前对集合遍历都是通过Iterator或者增强for的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式,流可以直接调用遍历方法。
当使用一个流的时候,通常包括三个基本步骤:获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道。
流的延迟执行特点
三、通过集合、映射map或数组获取流
java.util.stream.Stream<T>是Java 8新加入的最常用的流接口。(这并不是一个函数式接口。)
获取一个流非常简单,有以下几种常用的方式
• 所有的 Collection 集合(List和Set)都可以通过 stream 默认方法获取流;
• Stream 接口的静态方法 of 可以获取数组对应的流。
1、根据Collection获取流
public class Demo04GetStream { public static void main(String[] args) { List<String> list = new ArrayList<>(); // ... Stream<String> stream1 = list.stream(); Set<String> set = new HashSet<>(); // ... Stream<String> stream2 = set.stream(); Vector<String> vector = new Vector<>(); // ... Stream<String> stream3 = vector.stream(); } }
2、根据Map获取流
public class Demo05GetStream { public static void main(String[] args) { Map<String, String> map = new HashMap<>(); // ... Stream<String> keyStream = map.keySet().stream(); Stream<String> valueStream = map.values().stream(); Stream<Map.Entry<String, String>> entryStream = map.entrySet().stream(); } }
3、根据数组获取流
public class Demo06GetStream { public static void main(String[] args) { String[] array = { "张无忌", "张翠山", "张三丰", "张一元" }; Stream<String> stream = Stream.of(array); } }
备注: of 方法的参数其实是一个可变参数,而可变参数等价于数组,所以支持数组。
四、掌握常用的流操作
延迟方法:返回值类型仍然是Stream接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为延迟方法。)
终结方法:返回值类型不再是Stream接口自身类型的方法,因此不再支持类似 StringBuilder 那样的链式调用。
本小节中,终结方法包括count 和 forEach 方法。
1、逐一处理:forEach(终结方法)
虽然方法名字叫 forEach ,但是与for循环中的“for-each”昵称不同。
void forEach(Consumer<? super T> action);
该方法接收一个 Consumer接口函数,会将每一个流元素交给该函数进行处理。
public class Demo12StreamForEach { public static void main(String[] args) { Stream<String> stream = Stream.of("张无忌", "张三丰", "周芷若"); // of的参数是可变参数 stream.forEach(name‐> System.out.println(name)); } }
2、过滤:filter(延迟方法)
可以通过 filter 方法将一个流转换成另一个子集流。方法签名:
Stream<T> filter(Predicate<? super T> predicate);
该接口接收一个 Predicate函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
此前我们已经学习过 java.util.stream.Predicate 函数式接口,其中唯一的抽象方法为:
boolean test(T t);
该方法将会产生一个boolean值结果,代表指定的条件是否满足。如果结果为true,那么Stream流的filter 方法将会留用元素;如果结果为false,那么 filter 方法将会舍弃元素。
Stream流中的filter方法基本使用的代码如:
public class Demo07StreamFilter { public static void main(String[] args) { Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若"); Stream<String> result = original.filter(s ‐> s.startsWith("张")); } }
在这里通过Lambda表达式来指定了筛选的条件:必须姓张。
public class demo4 { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("张无忌"); list.add("周芷若"); list.add("赵敏"); list.add("张强"); list.add("张三丰"); List<String> list1 = list.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 3).collect(Collectors.toList()); list1.forEach(System.out::println); } }
结果:
张无忌
张三丰
对数组进行过滤:
ThirdPartyPlatform[] values = ThirdPartyPlatform.values(); // ThirdPartyPlatform为枚举类型enum
List<ThirdPartyPlatform> collect = Arrays.stream(values).filter(i -> i.getName().equals(entityName)).collect(Collectors.toList());
过滤掉List集合为空的记录
List<RetailOrder> collect = retailOrders.stream().filter(s -> CollectionUtils.isNotEmpty(s.getDrugDetail())).collect(Collectors.toList());
3、映射:map(延迟方法)
如果需要将流中的元素映射到另一个流中,可以使用map 方法。方法签名:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
该接口需要一个 Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
此前我们已经学习过 java.util.stream.Function函数式接口,其中唯一的抽象方法为:
R apply(T t);
这可以将一种T类型转换成为R类型,而这种转换的动作,就称为“映射”。
Stream流中的map方法基本使用的代码如:
public class Demo08StreamMap { public static void main(String[] args) { Stream<String> original = Stream.of("10", "12", "18"); Stream<Integer> result = original.map(Integer::parseInt); // 使用Lamdab表达式进行类型转换 } }
这段代码中, map 方法的参数通过方法引用,将字符串类型转换成为了int类型(并自动装箱为Integer 类对象)。
public class demo5 { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("12"); list.add("14"); list.add("16"); List<Integer> list1 = list.stream().map(Integer::parseInt).collect(Collectors.toList()); } }
抽取内容,生成集合
首先先初始化一些数据:
// 表达式: personList.add(new Person(String name, Integer age, Integer sex)); // 初始化数据 personList.add(new Person("张三", 18, 1)); personList.add(new Person("李四", 20, 2)); personList.add(new Person("王五", 16, 2)); personList.add(new Person("赵六", 32, 1)); personList.add(new Person("陆七", 19, 1));
取出对象集合中的姓名,并生成List集合,代码如下:
private static void testMap() { List<String> nameList = personList.stream().map(Person::getName).collect(Collectors.toList()); nameList.forEach(name ->{ System.out.println(name); }); }
运行结果:

项目代码:
// 通过用户去加载权限 List<Map<String, String>> li = menuMapper.selectMenuCode(u.getUserId(), isApplet); if (u.getSupper() != 1) { // 判断企业关联功能集是否过期 List<Menu> menuList = roleMapper.selectRoleMenuAll(u.getEnterpriseId()); List<String> menus = menuList.stream().map(x -> x.getMenuCode()).collect(Collectors.toList()); li.removeIf(item -> !menus.contains(item.get("code"))); // 如果不包含则删除 }
简单的案例
public class demo6 { public static void main(String[] args) { // 删除List<Map>中过期的数据 List<Map<String, String>> li =new ArrayList<>(); Map<String, String> map = new HashMap<>(); map.put("name","张三"); Map<String, String> map1 = new HashMap<>(); map1.put("name","李四"); li.add(map); li.add(map1); // 最新的数据 List list = new ArrayList<>(); list.add("王五"); list.add("李四"); li.removeIf(item->!list.contains(item.get("name"))); System.out.println(li.toString()); } }
结果:[{name=李四}]
这样的话,不用遍历List就能删除元素。
removeIf方法根据条件删除Collection集合中的数据,如下:
default boolean removeIf(Predicate<? super E> filter) { Objects.requireNonNull(filter); boolean removed = false; final Iterator<E> each = iterator(); while (each.hasNext()) { if (filter.test(each.next())) { each.remove(); removed = true; } } return removed; }
求和
BigDecimal sumArrival = list.stream().map(CDayPowerDetail::getSupply).reduce(BigDecimal.ZERO, BigDecimal::add);
4、聚合函数
统计个数:count(终结方法)
long count();
该方法返回一个long值代表元素个数(不再像旧集合那样是int值)。基本使用:
public class Demo09StreamCount { public static void main(String[] args) { Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若"); Stream<String> result = original.filter(s ‐> s.startsWith("张")); System.out.println(result.count()); // 2 } }
获取最大值
案例1:获取对象集合中的某个属性值最大的对象。
//获取最大更新时间 CoalPriceMine coalPriceMine = tmpList.stream().max(Comparator.comparing(s -> s.getCreateTime())).get();
案例2:获取字符串集合中字符串长度最大的字符串
List<String> list = Arrays.asList("chang","tiao","rap","dalanqiu"); Optional<String> max = list.stream().max(Comparator.comparing(String::length)); Optional<String> min = list.stream().min(Comparator.comparing(String::length)); System.out.println("最长的字符串:" + max.get()); System.out.println("最短的字符串:" + min.get());
5、取用前几个:limit(延迟方法)
Stream<T> limit(long maxSize);
参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。基本使用:
public class Demo10StreamLimit { public static void main(String[] args) { Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若"); Stream<String> result = original.limit(2); System.out.println(result.count()); // 2 } }
结果:2
public class Demo10StreamLimit { public static void main(String[] args) { Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若"); Stream<String> result = original.limit(2); result.forEach(System.out::println); // System.out.println(result.count()); // 2 } }
结果:
张无忌
张三丰
6、跳过前几个:skip(延迟方法)
如果希望跳过前几个元素,可以使用skip方法获取一个截取之后的新流:
Stream<T> skip(long n);
如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。基本使用:
public class Demo11StreamSkip { public static void main(String[] args) { Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若"); Stream<String> result = original.skip(2); System.out.println(result.count()); // 1 } }
结果:1
public class Demo10StreamLimit { public static void main(String[] args) { Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若"); Stream<String> result = original.skip(2); result.forEach(System.out::println); // System.out.println(result.count()); // 1 } }
结果:周芷若
实际应用:集合分批插入数据库
int totalCount = codeReigstrations.size(); //分批插入,每次两千五 int pageSize = 2500; int page = totalCount % pageSize == 0 ? totalCount / pageSize : totalCount / pageSize + 1; List<CodeReigstration> batchUpdateDataList = null; for (int i = 0; i < page; i++) { batchUpdateDataList = codeReigstrations.stream().skip(i * pageSize).limit(pageSize).collect(Collectors.toList()); codePrefixDao.batchDealCodeReigstration(batchUpdateDataList); }
7、组合:concat(延迟方法)
如果有两个流,希望合并成为一个流,那么可以使用Stream 接口的静态方法 concat :
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)
备注:这是一个静态方法,与 java.lang.String 当中的 concat 方法是不同的。
public class Demo10StreamLimit { public static void main(String[] args) { Stream<String> streamA = Stream.of("张无忌"); Stream<String> streamB = Stream.of("张翠山"); Stream<String> result = Stream.concat(streamA, streamB); result.forEach(System.out::println); } }
结果:
张无忌
张翠山
PS:如果只看上面说法" 如果有两个流,希望合并成为一个流,那么可以使用Stream 接口的静态方法 concat ",我们可能并不知道这在实际开发中有什么用,实际上我们将两个List分别转成两个Stream,然后将这两个Stream通过concat方法合成一个Stream,再对这个合并的Stream进行相应的操作。
List<PublishDetailDTO> publishDetailEntityDTO = ctsProManageDao.selectEntityMonitorCtsProductsByEntityId(entityId); List<PublishDetailDTO> publishDetailAreaDTO = ctsProManageDao.selectEntityMonitorCtsProductsByEntityArea(entityId); List<Long> ctsProductIds = Stream.concat( publishDetailEntityDTO.stream().map(PublishDetailDTO::getProductId), publishDetailAreaDTO.stream().map(PublishDetailDTO::getProductId) ).collect(Collectors.toList());
8、sorted排序(延迟方法)
Stream<T> sorted(Comparator<? super T> comparator);
其中:Comparator接口为函数式接口
@FunctionalInterface public interface Comparator<T> {
按年龄进行排序,代码如下:
private static void testSorted() { System.out.println("------ 按年龄升序排序 ------"); personList.stream().sorted(Comparator.comparing(Person::getAge)).forEach(person -> { System.out.println(person.toString()); }); System.out.println("------ 按年龄降序排序 ------"); personList.stream().sorted(Comparator.comparing(Person::getAge).reversed()).forEach(person -> { System.out.println(person.toString()); }); }
其中:Comparator函数式接口的comparing方法的参数为函数式接口Function,故可以用方法引用取代
public static <T, U extends Comparable<? super U>> Comparator<T> comparing( Function<? super T, ? extends U> keyExtractor) { Objects.requireNonNull(keyExtractor); return (Comparator<T> & Serializable) (c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2)); }
运行结果:

当对多个字段进行排序时,可直接在sql中进行排序,也可以在代码中利用stream进行排序。
下面就对用户信息进行排序,要求是根据更新时间降序,姓名和性别升序排序:
User实体类
@Data @AllArgsConstructor public class User { private String name; private String sex; private String birthDay; private Date updateTime; }
默认是按升序排序,降序时采用reverseOrder()方法即可
public class demo3 { public static void main(String[] args) { List<User> userList = new ArrayList<>(); userList.add(new User("张三","男","1988-09-10", DateUtil.stringToDate("2022-09-10 12:12:12",DateUtil.LONG_MODEL))); userList.add(new User("李思","女","1980-09-10",DateUtil.stringToDate("2022-09-11 12:12:12",DateUtil.LONG_MODEL))); userList.add(new User("老王","男","1970-09-10",DateUtil.stringToDate("2022-09-12 12:12:12",DateUtil.LONG_MODEL))); userList.add(new User("老李","男","1981-09-10",DateUtil.stringToDate("2022-09-13 12:12:12",DateUtil.LONG_MODEL))); List<User> sortList = new ArrayList<>(); if (!CollectionUtils.isEmpty(userList)) { // 按某些字段进行排序 // 需要注意的是list.stream()对数据进行操作后,原list不会发现变化,要么不使用.stream()方法,要么使用新的集合接收 sortList = userList.stream().sorted( Comparator.comparing(User::getUpdateTime, Comparator.reverseOrder()) .thenComparing(User::getName) .thenComparing(User::getSex) ).collect(Collectors.toList()); } System.out.println(sortList); }
结果:
[User(name=老李, sex=男, birthDay=1981-09-10, updateTime=Tue Sep 13 12:12:12 CST 2022), User(name=老王, sex=男, birthDay=1970-09-10, updateTime=Mon Sep 12 12:12:12 CST 2022), User(name=李思, sex=女, birthDay=1980-09-10, updateTime=Sun Sep 11 12:12:12 CST 2022), User(name=张三, sex=男, birthDay=1988-09-10, updateTime=Sat Sep 10 12:12:12 CST 2022)]
9、distinct去重(延迟方法)
Stream<T> distinct();
代码如下:
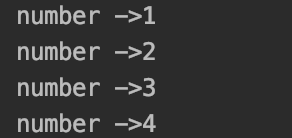
private static void testDistinct() { int[] ints = {1, 1, 2, 2, 3, 3, 3, 4, 4, 4, 4}; Arrays.stream(ints).distinct().forEach(number -> { System.out.println("number ->" + number); }); }
运行结果:
使用distinct对对象中的某个属性去重
实体类
@Data @AllArgsConstructor public class UserInfo { private Integer Id; private String name; private Integer age; @Override public boolean equals(Object obj) { if (obj instanceof UserInfo) { UserInfo tmp = (UserInfo) obj; if (this.getId().equals(tmp.getId())) { return true; } } return false; } @Override public int hashCode() { return Objects.hash(Id); } }
测试类
public class distinctTest { public static void main(String[] args) { List<UserInfo> list = new ArrayList(); list.add(new UserInfo(1,"小明",1)); list.add(new UserInfo(2,"小s",2)); list.add(new UserInfo(1,"小明",2)); List<UserInfo> collect = list.stream().distinct().collect(Collectors.toList()); System.out.println(collect); } }
结果:
[UserInfo(Id=1, name=小明, age=1), UserInfo(Id=2, name=小s, age=2)]
10、mapTo 统计
IntStream mapToInt(ToIntFunction<? super T> mapper);
其中:ToIntFunction为函数时接口:
@FunctionalInterface public interface ToIntFunction<T> { /** * Applies this function to the given argument. * * @param value the function argument * @return the function result */ int applyAsInt(T value); }
统计人员的年龄情况,代码如下:
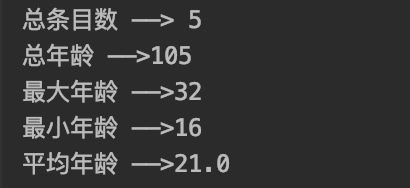
private static void testMapTo() { IntSummaryStatistics intSummaryStatistics = personList.stream().mapToInt(Person::getAge).summaryStatistics(); System.out.println("总条目数 ——> "+intSummaryStatistics.getCount()); System.out.println("总年龄 ——>"+intSummaryStatistics.getSum()); System.out.println("最大年龄 ——>"+intSummaryStatistics.getMax()); System.out.println("最小年龄 ——>"+intSummaryStatistics.getMin()); System.out.println("平均年龄 ——>"+intSummaryStatistics.getAverage()); }
其中:IntStream的summaryStatistics()方法如下:
IntSummaryStatistics summaryStatistics();
运行结果:
11、collect 规约操作
<R, A> R collect(Collector<? super T, A, R> collector);
另外:Collectors.toList()方法如下:
Collector<T, ?, List<T>> toList()
抽出人员名字,并以逗号分隔,代码如下:
private static void testCollect() { List<String> nameList = personList.stream().map(Person::getName).collect(Collectors.toList()); // 取出名字并生成List集合 String names = nameList.stream().collect(Collectors.joining(",")); System.out.println("names ->" + names); }
运行结果:
Collectors.toList是生成List集合,而Collectors.joining(",")是将字符串用逗号拼接起来。
public class Demo10StreamLimit { public static void main(String[] args) { List<String> nameList = new ArrayList<>(); nameList.add("张三"); nameList.add("李四"); nameList.add("王五"); nameList.add("赵六"); String names = nameList.stream().collect(Collectors.joining(",")); System.out.println(names); } }
结果如下:
张三,李四,王五,赵六
Collectors.groupingBy的用法:
Collectors.groupingBy根据一个或多个属性对集合中的项目进行分组
Product实体类
@Data public class Product { private Long id; private Integer num; private BigDecimal price; private String name; private String category; public Product(Long id, Integer num, BigDecimal price, String name, String category) { this.id = id; this.num = num; this.price = price; this.name = name; this.category = category; } }
测试类
public class Demo1 { public static void main(String[] args) { Product prod1 = new Product(1L, 1, new BigDecimal("15.5"), "面包", "零食"); Product prod2 = new Product(2L, 2, new BigDecimal("20"), "饼干", "零食"); Product prod3 = new Product(3L, 3, new BigDecimal("30"), "月饼", "零食"); Product prod4 = new Product(4L, 3, new BigDecimal("10"), "青岛啤酒", "啤酒"); Product prod5 = new Product(5L, 10, new BigDecimal("15"), "百威啤酒", "啤酒"); List<Product> prodList = new ArrayList<>(); prodList.add(prod1); prodList.add(prod2); prodList.add(prod3); prodList.add(prod4); prodList.add(prod5); // 按照类目分组 Map<String, List<Product>> prodMap= prodList.stream().collect(Collectors.groupingBy(Product::getCategory)); System.out.println(prodMap); // 按照几个属性拼接分组 Map<String, List<Product>> prodMap1 = prodList.stream().collect(Collectors.groupingBy(item -> item.getCategory() + "_" + item.getName())); System.out.println(prodMap1); // 根据不同条件分组 Map<String, List<Product>> prodMap3= prodList.stream().collect(Collectors.groupingBy(item -> { if(item.getNum() < 3) { return "3"; }else { return "other"; } })); System.out.println(prodMap3); } }
结果如下:
{啤酒=[Product(id=4, num=3, price=10, name=青岛啤酒, category=啤酒), Product(id=5, num=10, price=15, name=百威啤酒, category=啤酒)], 零食=[Product(id=1, num=1, price=15.5, name=面包, category=零食), Product(id=2, num=2, price=20, name=饼干, category=零食), Product(id=3, num=3, price=30, name=月饼, category=零食)]}
{零食_月饼=[Product(id=3, num=3, price=30, name=月饼, category=零食)], 零食_面包=[Product(id=1, num=1, price=15.5, name=面包, category=零食)], 啤酒_百威啤酒=[Product(id=5, num=10, price=15, name=百威啤酒, category=啤酒)], 啤酒_青岛啤酒=[Product(id=4, num=3, price=10, name=青岛啤酒, category=啤酒)], 零食_饼干=[Product(id=2, num=2, price=20, name=饼干, category=零食)]}
{other=[Product(id=3, num=3, price=30, name=月饼, category=零食), Product(id=4, num=3, price=10, name=青岛啤酒, category=啤酒), Product(id=5, num=10, price=15, name=百威啤酒, category=啤酒)], 3=[Product(id=1, num=1, price=15.5, name=面包, category=零食), Product(id=2, num=2, price=20, name=饼干, category=零食)]}
12、findAny()判断list集合对象的字段是否存在某个值
现有一个用户对象的集合,判断其中是否包含姓名为张三的用户,如何去做?
用户对象如下:
@Data @Accessors(chain = true) @AllArgsConstructor @NoArgsConstructor public class User { private Integer id; private String name; private String phone; }
使用isPresent()进行判断,其返回boolean类型,包含时返回true,不包含时返回false。当然可以使用get()方法获取此元素的值,其返回的值是第一个符合条件的元素:
public class demo1 { public static void main(String[] args) { List<User> userList = new ArrayList<>(); userList.add(new User(1, "张三丰", "15645854585")); userList.add(new User(2, "张三", "15645857858")); userList.add(new User(3, "李四", "15945854566")); userList.add(new User(4, "王五", "15755554585")); userList.add(new User(5, "张三", "15852254585")); Optional<User> any = userList.stream().filter(item -> "张三".equals(item.getName())).findAny(); if (any != null && any.isPresent()) { System.out.println(any.get()); } } }
结果:User(id=2, name=张三, phone=15645857858)
五、案例
1、案例1
集合元素处理(传统方式)
题目:现在有两个ArrayList集合存储队伍当中的多个成员姓名,要求使用传统的for循环(或增强for循环)依次进行以下若干操作步骤:
1. 第一个队伍只要名字为3个字的成员姓名;存储到一个新集合中。
2. 第一个队伍筛选之后只要前3个人;存储到一个新集合中。
3. 第二个队伍只要姓张的成员姓名;存储到一个新集合中。
4. 第二个队伍筛选之后不要前2个人;存储到一个新集合中。
5. 将两个队伍合并为一个队伍;存储到一个新集合中。
6. 根据姓名创建 Person 对象;存储到一个新集合中。
7. 打印整个队伍的Person对象信息。
public class DemoArrayListNames { public static void main(String[] args) { //第一支队伍 ArrayList<String> one = new ArrayList<>(); one.add("迪丽热巴"); one.add("宋远桥"); one.add("苏星河"); one.add("石破天"); one.add("石中玉"); one.add("老子"); one.add("庄子"); one.add("洪七公"); //第二支队伍 ArrayList<String> two = new ArrayList<>(); two.add("古力娜扎"); two.add("张无忌"); two.add("赵丽颖"); two.add("张三丰"); two.add("尼古拉斯赵四"); two.add("张天爱"); two.add("张二狗"); // .... } }
而 Person 类的代码为:
public class Person { private String name; public Person() {} public Person(String name) { this.name = name; } @Override public String toString() { return "Person{name='" + name + "'}"; } public String getName() { return name; } public void setName(String name) { this.name = name; } }
既然使用传统的for循环写法,那么:
public class DemoArrayListNames { public static void main(String[] args) { List<String> one = new ArrayList<>(); // ... List<String> two = new ArrayList<>(); // ... // 第一个队伍只要名字为3个字的成员姓名; List<String> oneA = new ArrayList<>(); for (String name : one) { if (name.length() == 3) { oneA.add(name); } } // 第一个队伍筛选之后只要前3个人; List<String> oneB = new ArrayList<>(); for (int i = 0; i < 3; i++) { oneB.add(oneA.get(i)); } // 第二个队伍只要姓张的成员姓名; List<String> twoA = new ArrayList<>(); for (String name : two) { if (name.startsWith("张")) { twoA.add(name); } } // 第二个队伍筛选之后不要前2个人; List<String> twoB = new ArrayList<>(); for (int i = 2; i < twoA.size(); i++) { twoB.add(twoA.get(i)); } // 将两个队伍合并为一个队伍; List<String> totalNames = new ArrayList<>(); totalNames.addAll(oneB); totalNames.addAll(twoB); // 根据姓名创建Person对象; List<Person> totalPersonList = new ArrayList<>(); for (String name : totalNames) { totalPersonList.add(new Person(name)); } // 打印整个队伍的Person对象信息。 for (Person person : totalPersonList) { System.out.println(person); } } }
运行结果为:
Person{name='宋远桥'}
Person{name='苏星河'}
Person{name='石破天'}
Person{name='张天爱'}
Person{name='张二狗'}
集合元素处理(Stream方式)
将上一题当中的传统for循环写法更换为Stream流式处理方式。两个集合的初始内容不变,Person 类的定义也不变
等效的Stream流式处理代码为:
public class DemoStreamNames { public static void main(String[] args) { List<String> one = new ArrayList<>(); // ... List<String> two = new ArrayList<>(); // ... // 第一个队伍只要名字为3个字的成员姓名; // 第一个队伍筛选之后只要前3个人; Stream<String> streamOne = one.stream() .filter(s ‐> s.length() == 3) .limit(3); // 第二个队伍只要姓张的成员姓名; // 第二个队伍筛选之后不要前2个人; Stream<String> streamTwo = two.stream() .filter(s ‐> s.startsWith("张")) .skip(2); // 将两个队伍合并为一个队伍; // 根据姓名创建Person对象; // 打印整个队伍的Person对象信息。 Stream.concat(streamOne, streamTwo) .map(Person::new) .forEach(System.out::println); } }
运行效果完全一样。
Stream流在项目中的使用:项目中用得最多的情况是遍历。
List<ProductMedicinalMaterials> materialsList = new ArrayList<>(); List<ProductMedicinalMaterials> tempList = productMedicinalMaterialsMapper.selectByExample(example); //获取药材的图片 if (tempList != null && tempList.size() > 0) { tempList.stream().forEach(item -> { List<AttachFile> fileList = attachFileService.getFileList(item.getId(), "T_PRODUCT_MEDICINAL_MATERIALS", "MATERIALS_PATH"); item.setMaterialsPath(fileList); materialsList.add(item); }); }
将数据收集进一个列表(Stream 转换为 List,允许重复值,有顺序):collect(Collectors.toList())
// 通过用户去加载权限 List<Map<String, String>> li = menuMapper.selectMenuCode(u.getUserId(), isApplet); if (u.getSupper() != 1) { // 判断企业关联功能集是否过期 List<Menu> menuList = roleMapper.selectRoleMenuAll(u.getEnterpriseId()); List<String> menus = menuList.stream().map(x -> x.getMenuCode()).collect(Collectors.toList()); li.removeIf(item -> !menus.contains(item.get("code"))); }
Stream流在项目的使用:
在导入Excel时对记录进行去重。
List<IntelDrugStoreTemplate> intelDrugStoreTemplateList = ExcelImportUtil.importExcel(file.getInputStream(), IntelDrugStoreTemplate.class, params); List<IntelDrugStoreTemplate> distinct = intelDrugStoreTemplateList.stream().filter(distinctByKey(IntelDrugStoreTemplate::getEquipmentCode1)) .collect(Collectors.toList());
其中distinctByKey方法如下:
private static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) { Map<Object, Boolean> seen = new ConcurrentHashMap<>(); return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null; }
其中putIfAbsent方法如下:
default V putIfAbsent(K key, V value) { V v = get(key); if (v == null) { v = put(key, value); } return v; }
对distinctByKey方法的解析如下:
代码分析:
1、可以通过 filter 方法将一个流转换成另一个子集流。filter方法的参数为Predicate
Stream<T> filter(Predicate<? super T> predicate);
2、distinctByKey方法返回一个Predicate函数式接口,
3、distinctByKey方法的参数是Function函数式接口
4、Function函数式接口的apply方法的作用是将distinctByKey方法的参数equipmentCode1的值传给Predicate函数式接口中的t,
5、通过putIfAbsent方法将key为t,value为true放入map中,如果key的值value存在,则返回旧值value,此时value为Boolean.TRUE。如果value不存在则put,仍返回旧值value,此时value为null。
6、再通过判断旧值是否为null来过滤,从而得到value为空的子集流。第一次put一个equipmentCode时,value为空,返回值为null。第二次及以后put相同的equipmentCode时,value值为Boolean.TRUE,此时不为空,即当equipmentCode作为key时,第二次及以后的equipmentCode相同的记录被过滤掉。
2、案例2:树形结构处理
现有一个包含行政区对象的集合,根据父级id获取所有行政区的父级编码,如何去做?
AreaCode对象
@Data @AllArgsConstructor public class AreaCode { private Integer id; private String areaName; private String code; private Integer parentId; private String parentCode; }
使用get()过滤符合条件的元素
public class demo2 { public static void main(String[] args) { List<AreaCode> list = new ArrayList<>(); list.add(new AreaCode(1, "湖北省", "101", 0, null)); list.add(new AreaCode(2, "武汉市", "10101", 1, null)); list.add(new AreaCode(3, "黄冈市", "10102", 1, null)); list.add(new AreaCode(4, "洪山区", "1010101", 2, null)); list.add(new AreaCode(5, "江夏区", "1010102", 2, null)); list.add(new AreaCode(6, "江岸区", "1010103", 2, null)); list.add(new AreaCode(6, "阳新县", "1010201", 3, null)); list.stream().forEach(l -> { String code = "0"; if (l.getParentId() != 0) { AreaCode areaCode = list.stream().filter(s -> s.getId().equals(l.getParentId())).findAny().get(); code = areaCode.getCode(); } l.setParentCode(code); }); System.out.println(list); } }
结果如下:
[AreaCode(id=1, areaName=湖北省, code=101, parentId=0, parentCode=0), AreaCode(id=2, areaName=武汉市, code=10101, parentId=1, parentCode=101), AreaCode(id=3, areaName=黄冈市, code=10102, parentId=1, parentCode=101), AreaCode(id=4, areaName=洪山区, code=1010101, parentId=2, parentCode=10101), AreaCode(id=5, areaName=江夏区, code=1010102, parentId=2, parentCode=10101), AreaCode(id=6, areaName=江岸区, code=1010103, parentId=2, parentCode=10101),

