一、优化表结构
(1)、尽量将表字段定义为 NOT NULL约束,这时由于在MySQL中含有空值的列很难进行查询优化,NULL值会使索引以及索引的统计信息变得很复杂。
(2)、对于只包含特定类型的字段,可以使用 enum、set 等数据类型。
(3)、数值型字段的比较,比字符串的比较效率高得多,字段类型尽量使用最小、最简单的数据类型。例如IP地址可以使用int类型。
(4)、尽量使用 TINYINT、SMALLINT、MEDIUM_INT作为整数类型而非INT,如果非负则加上UNSIGNED。但对整数类型指定宽度,比如INT(11),没有任何用,因为指定的类型标识范围已经确定。
(5)、VARCHAR 的长度只分配真正需要的空间
(6)、尽量使用 TIMESTAMP而非DATETIME,但TIMESTAMP只能表示1970 - 2038年,比DATETIME表示的范围小得多,而且TIMESTAMP的值因时区不同而不同。
(7)、单表不要有太多字段,建议在 20以内
(8)、合理的加入冗余字段可以提高查询速度。
二、分库分表
分库分表的原因:
分库分表的原因的主要是让 MySQL 能支撑大数据量储存和高并发访问 ,单库(表)可能出现的性能瓶颈表现在下面几个方面:
- 大量请求阻塞:在高并发场景下,大量请求都需要操作数据库,导致连接数不够了,请求处于阻塞状态。。
- SQL 操作变慢:如果数据库中存在一张上亿数据量的表,一条 SQL 没有命中索引会全表扫描,耗时很久。
- 存储出现问题:业务量剧增,单库数据量越来越大,给存储造成巨大压力。
分库还是分表?
分库分表是两回事儿,可以只分库不分表,也可以只分表不分库,分库主要解决高并发瓶颈,分表主要解决数据量大瓶颈,但是一般情况下,我们都需要同时做分库分表。
ap_article 文章基本信息表
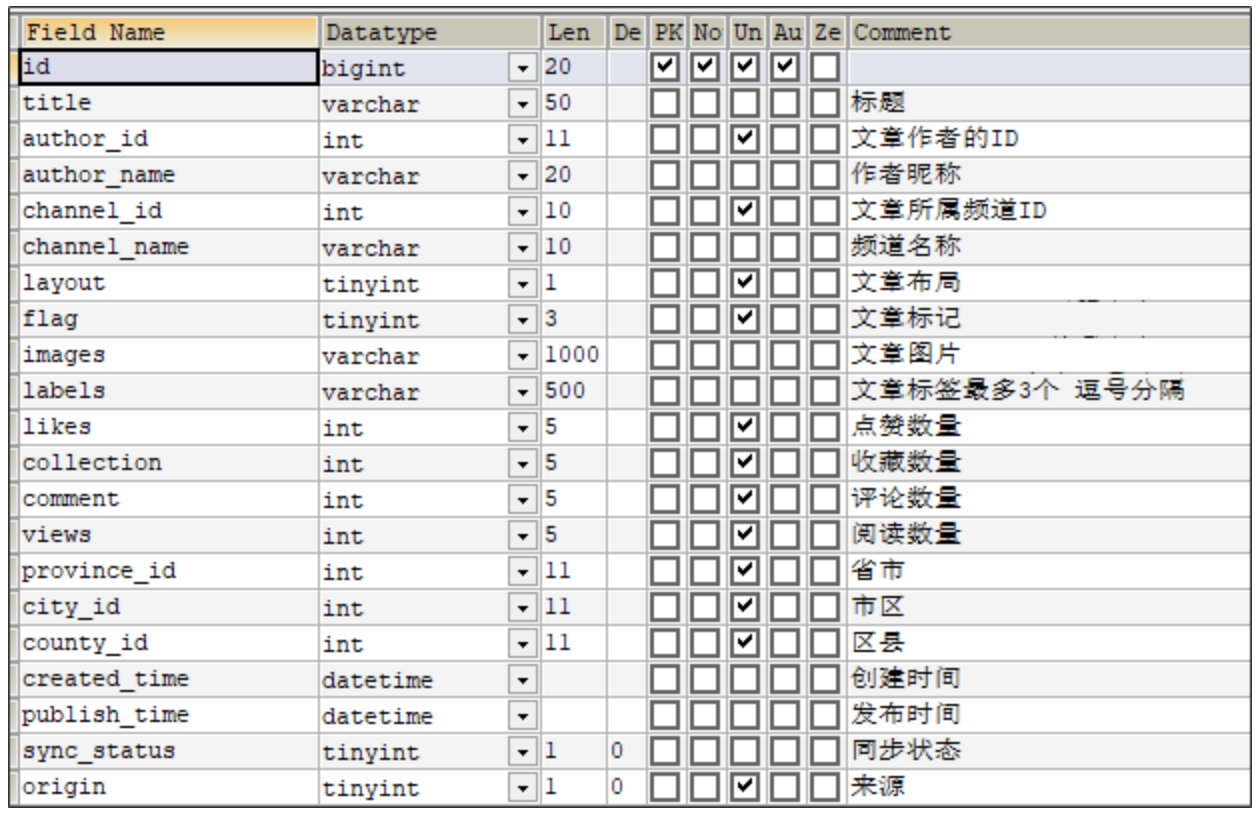
ap_article_config 文章配置表
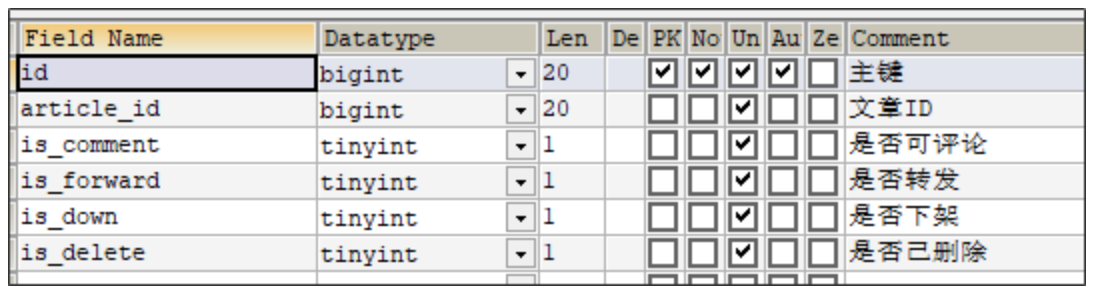
ap_article_content 文章内容表

1、垂直拆分
垂直拆分按照字段进行拆分,其实就是把组成一行的多个列分开放到不同的表中,这些表具有不同的结构,拆分后的表具有更少的列。例如用户表中的一些字段可能经常访问,可以把这些字段放进一张表里。另外一些不经常使用的信息就可以放进另外一张表里。
插入的时候使用事务,也可以保证两表的数据一致。缺点也很明显,由于拆分出来的两张表存在一对一的关系,需要使用冗余字段,而且需要join操作。但是我们可以在使用的时候可以分别取两次,这样的来说既可以避免join操作,又可以提高效率。
将一个表的字段分散到多个表中,每个表存储其中一部分字段。
分表的好处:
(1)、减少IO争抢,减少锁表的几率,查看文章概述和文章详情互不影响。
(2)、充分发挥高频数据的操作效率,对文章概述数据操作的高效率不会被操作文章详情数据的低效率所拖累。
ap_article_content表的效率比较低,因为该表的content字段为longtext类型,内容比较多时,效率就比较慢。而ap_article表的效率相对比较快,拆分之后,操作ap_article表是高效率的,操作ap_article_content是低效率的。我们经常操作ap_article不会被ap_article_content影响。
垂直分表的原则
(1)、把不常用的字段单独放一张表。
(2)、把text、blob等大字段拆分出来单独放在一张表。
(3)、经常组合查询的字段单独放在一张表中。
2、水平拆分
水平拆分按照行进行拆分,常见的就是分库分表。
以用户表为例,可以取用户ID,然后对ID取10的余数,将用户均匀的分配进这 0-9这10个表中。查找的时候也按照这种规则,又快又方便。
有些表业务关联比较强,那么可以使用按时间划分的。例如每天的数据量很大,需要每天新建一张表。这种业务类型就是需要高速插入,但是对于查询的效率不太关心。表越大,插入数据所需要索引维护的时间也就越长。
水平分表有按年分表,按月分表,还可以根据key值取模来分表。
(1)、按年分表和按月分表比较简单,根据表名通过存储过程来创建表
CREATE DEFINER=`root`@`%` PROCEDURE `p_create_b_outstore_upload_log_table`(IN `v_table_name` varchar(50)) BEGIN #Routine body goes here... DECLARE v_sql varchar(1000); # 声明局部变量v_sql # 给局部变量v_sql赋值 set v_sql = CONCAT('create table ',v_table_name,"(id bigint(20) NOT NULL comment '主键',entity_id bigint(20) NOT NULL comment '所属企业',order_no VARCHAR(50) NOT NULL comment '单据号',file_path VARCHAR(200) NOT NULL comment '文件路径',upload_time datetime NOT NULL comment '上传时间',app_key VARCHAR(100) NOT NULL comment '接口用户名',deal_status VARCHAR(50) NOT NULL comment '处理状态(0:待处理,1:处理中,2:处理成功,3:失败)',deal_desc VARCHAR(2000) NOT NULL comment '处理结果描述',order_time datetime NOT NULL comment '单据时间',order_year char(4) NOT NULL comment '单据年份',order_id bigint(20) comment '关联单据ID',error_count int default 0 comment '错误次数',create_user VARCHAR(20) comment '创建人',create_time datetime default CURRENT_TIMESTAMP comment '创建时间',update_user VARCHAR(20) comment '修改人', update_time datetime comment '修改时间',primary key(id))ENGINE=InnoDB DEFAULT CHARSET=utf8"); # 给用户变量@v_sql赋值 set @v_sql = v_sql; PREPARE stmt from @v_sql; EXECUTE stmt; DEALLOCATE PREPARE stmt; # 创建普通索引 set v_sql = CONCAT('alter table ',v_table_name,' add index ix_',v_table_name,'_deal_status(deal_status)'); set @v_sql = v_sql; PREPARE stmt from @v_sql; EXECUTE stmt; # 添加表名 set v_sql = CONCAT('alter table ',v_table_name," comment '出库上传记录表(按月份分表)'"); set @v_sql = v_sql; PREPARE stmt from @v_sql; EXECUTE stmt; END
(2)、根据key值取模来分表
工具类:工具类中basketnum字段确定分表的个数,如果分20个表,如下所示:b_code_relation_000001,b_code_relation_000002.....b_code_relation_000020。
import org.apache.commons.lang3.StringUtils; import java.math.BigDecimal; import java.nio.ByteBuffer; import java.nio.ByteOrder; /** * @Description 根据key值获取分表策略 * @Author * @Date 2020/11/24 10:52 * @Version 1.0 */ public class SplitTables { public static Integer basketnum = 20; public static Double totalInteger = Math.pow(2.0D, 32.0D); /** * * @param key * @return */ public static String getTableNumByShardingKey(String key) { Integer tbnum = getBasketnumByShardingKey(key); String tableNum = String.valueOf(tbnum); tableNum = StringUtils.leftPad(tableNum,6,'0' ); return tableNum; } /** * * @param key * @return */ private static Integer getBasketnumByShardingKey(String key) { Long hashvalue = hash(key); BigDecimal Bigcirclenum = new BigDecimal(Double.toString(totalInteger)); if (hashvalue == 0L){ return 1; } else if (hashvalue == Bigcirclenum.longValue()) { return basketnum; } else { BigDecimal Bignumbasket = new BigDecimal(Integer.toString(basketnum)); BigDecimal Biggapnum = Bigcirclenum.divide(Bignumbasket); BigDecimal Bighashvalue = new BigDecimal(Long.toString(hashvalue)); BigDecimal basketindex = Bighashvalue.divide(Biggapnum,2); Double basketindexd = basketindex.doubleValue(); Integer basketno = (int) Math.ceil(basketindexd); return basketno; } } /** * * @param key * @return */ private static Long hash(String key) { ByteBuffer buf = ByteBuffer.wrap(key.getBytes()); Integer seed = 305441741; ByteOrder byteOrder = buf.order(); buf.order(ByteOrder.LITTLE_ENDIAN); long m = -4132994306676758123L; Integer r = 47; long h; for (h = (long) seed ^ (long) buf.remaining() * m; buf.remaining() >= 8; h *= m) { long k = buf.getLong(); k *= m; k ^= k >>> r; k *= m; h ^= k; } if (buf.remaining() > 0) { ByteBuffer finish = ByteBuffer.allocate(8).order(ByteOrder.LITTLE_ENDIAN); finish.put(buf).rewind(); h ^= finish.getLong(); h *= m; } h ^= h >>> r; h *= m; h ^= h >>> r; long kk = 4294967295L; h &= kk; buf.order(byteOrder); return h; } public static void main(String[] args) { System.out.println(getBasketnumByShardingKey("100")); } }
调用工具类:
String tableName = b_code_relaton + SplitTables.getTableNumByShardingKey(code);
三、表分区
分区适用于例如日志记录,查询少。一般用于后台的数据报表分析。对于这些数据汇总需求,需要很多日志表去做数据聚合,我们能够容忍1s到2s的延迟,只要数据准确能够满足需求就可以。MySQL主要支持4种模式的分区:range分区、list预定义列表分区,hash 分区,key键值分区。
录入使用key键值分区:
CREATE TABLE `test2` ( `id` int(20) NOT NULL AUTO_INCREMENT COMMENT 'ID', `name` varchar(100) DEFAULT NULL COMMENT '名称', `state` int(1) DEFAULT NULL COMMENT '状态', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY KEY (id) PARTITIONS 10;
表分区详细讲解参考:https://www.cnblogs.com/zwh0910/p/15507138.html
四、读写分离
1、mysql数据库的集群方案
读写分离架构
大型网站会有大量的并发访问,如果还是传统的数据存储方案,只是靠一台服务器处理,如此多的数据库连接、读写操作,数据库必然会崩溃,数据丢失的话,后果更是不堪设想。这时候,我们需要考虑如何降低单台服务器的使用压力,提升整个数据库服务的承载能力。
我们发现一般情况对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,这样分析可以采用数据库集群的方案。其中一个是主库,负责写入数据,我们称为写库;其它都是从库,负责读取数据,我们称为读库。这样可以缓解一台服务器的访问压力。
MySql自带主从复制功能,我们可以使用主从复制的主库作为写库,从库和主库进行数据同步,那么可以使用多个从库作为读库,已完成读写分离的效果。
那么,对我们的要求是:
1. 读库和写库的数据一致;2. 写数据必须写到写库;3. 读数据必须到读库;
架构

从该系统架构中,可以看出:
(1)、数据库从之前的单节点变为多节点提供服务
(2)、主节点数据,同步到从节点数据
(3)、应用程序需要连接到 2个数据库节点,并且在程序内部实现判断读写操作
读写分离主从复制(一主一从)参考:https://www.cnblogs.com/zwh0910/p/16511041.html
读写分离主从复制(一主三从)参考:https://www.cnblogs.com/zwh0910/p/17247296.html
这种架构存在2个问题:
(1)、应用程序需要连接到多个节点,对应用程序而言开发变得复杂
办法一: 这个问题,可以通过中间件解决(建议)。
办法二:如果在程序内部实现,可使用 Spring的AOP功能实现
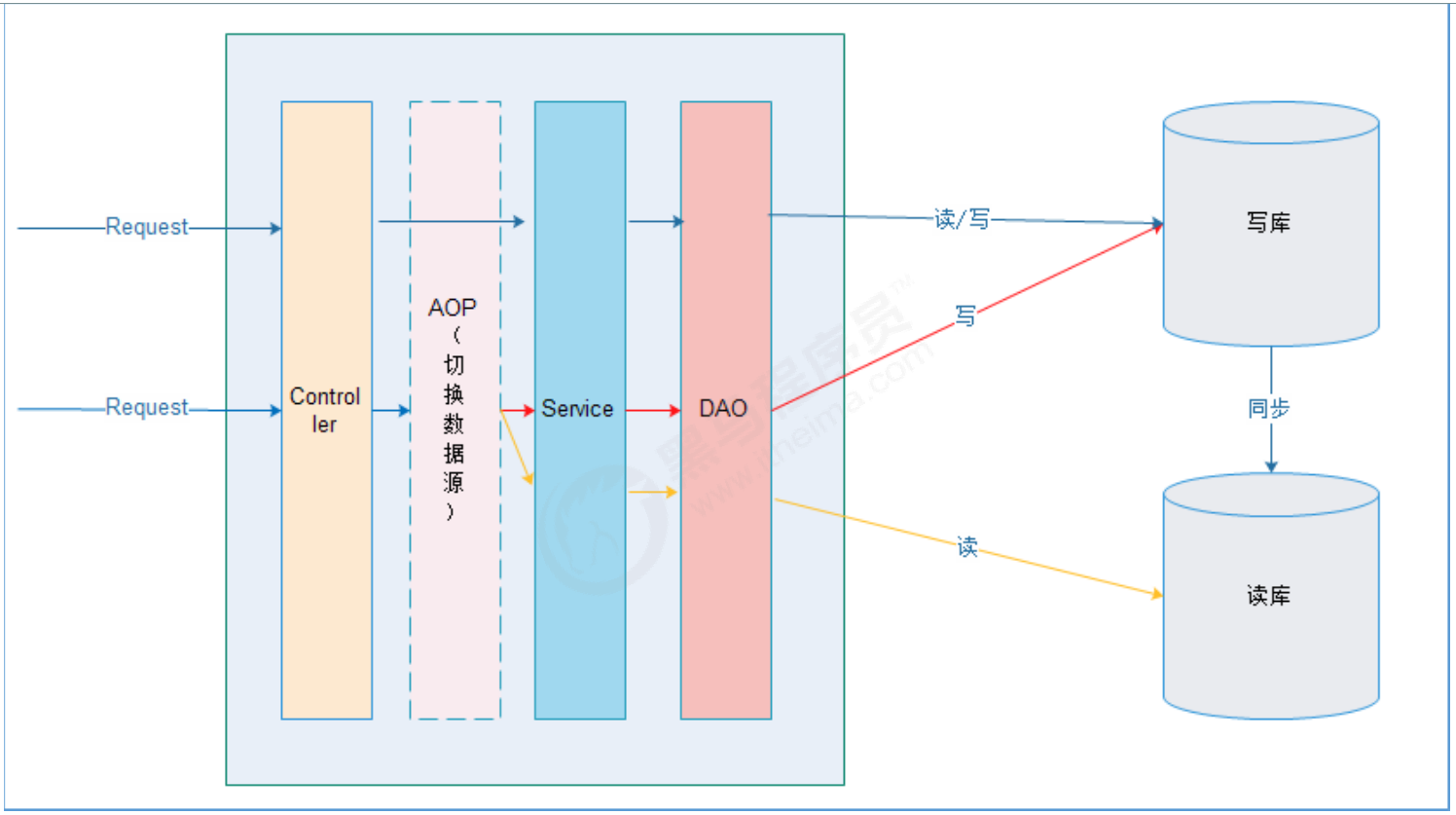
(2)、主从之间的同步,是异步完成,也就意味着这是 弱一致性
• 可能会导致,数据写入主库后,应用程序读取从库获取不到数据,或者可能会丢失数据,对于数据安全性要求比较高的应用是不合适的
• 该问题可以通过 PXC集群解决
中间件
通过上面的架构,可以看出,应用程序会连接到多个节点,使得应用程序的复杂度会提升,可以通过中间件方式解决,如下:
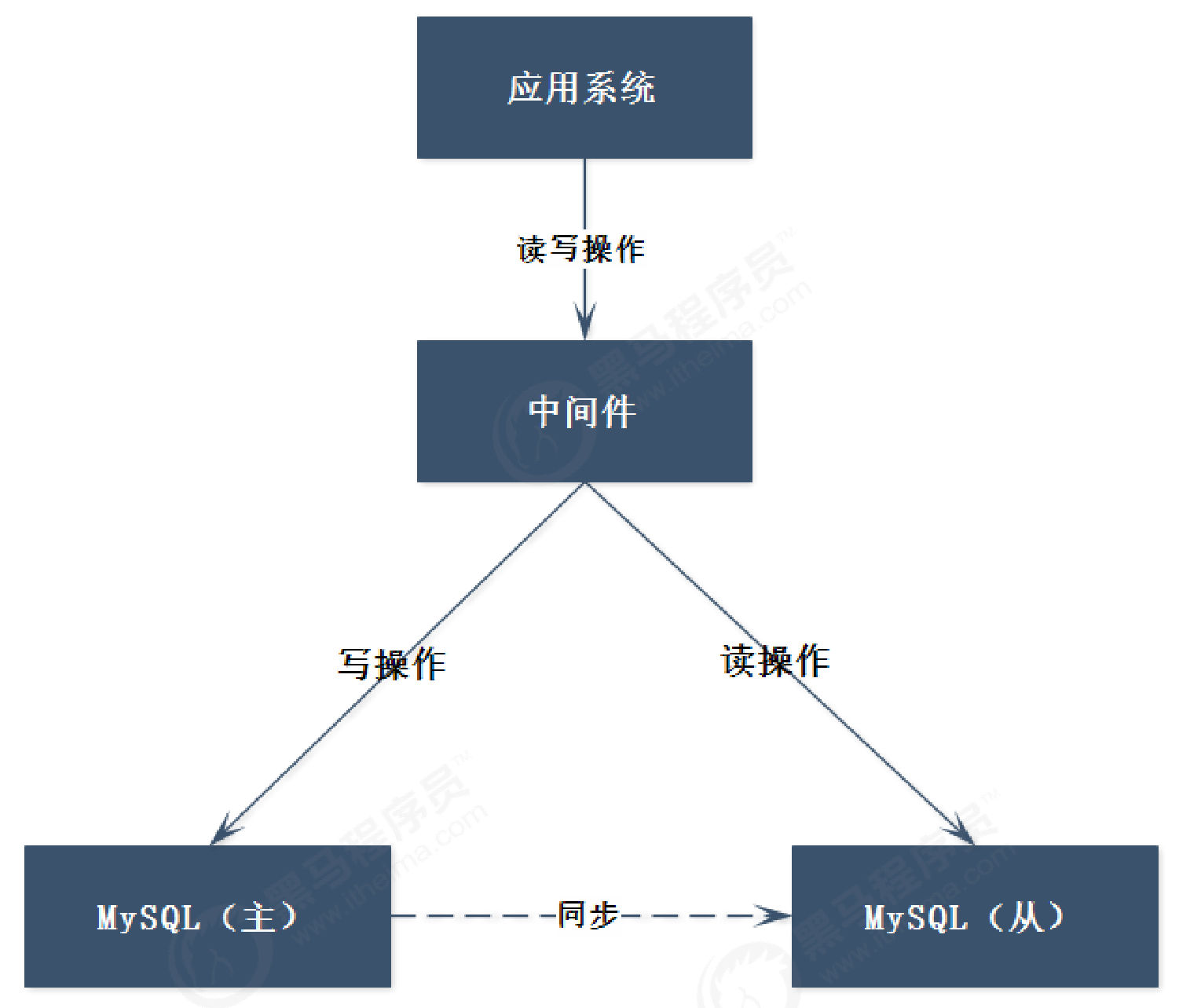
从架构中,可以看出:
(1)、应用程序只需要连接到中间件即可,无需连接多个数据库节点;
(2)、应用程序无需区分读写操作,对中间件直接进行读写操作即可;
(3)、在中间件中进行区分读写操作,读发送到从节点,写发送到主节点;
mycat分库分表(一主一从)参考:https://www.cnblogs.com/zwh0910/p/17267627.html
该架构也存在问题,中间件的性能成为了系统的瓶颈,那么架构可以改造成这样:
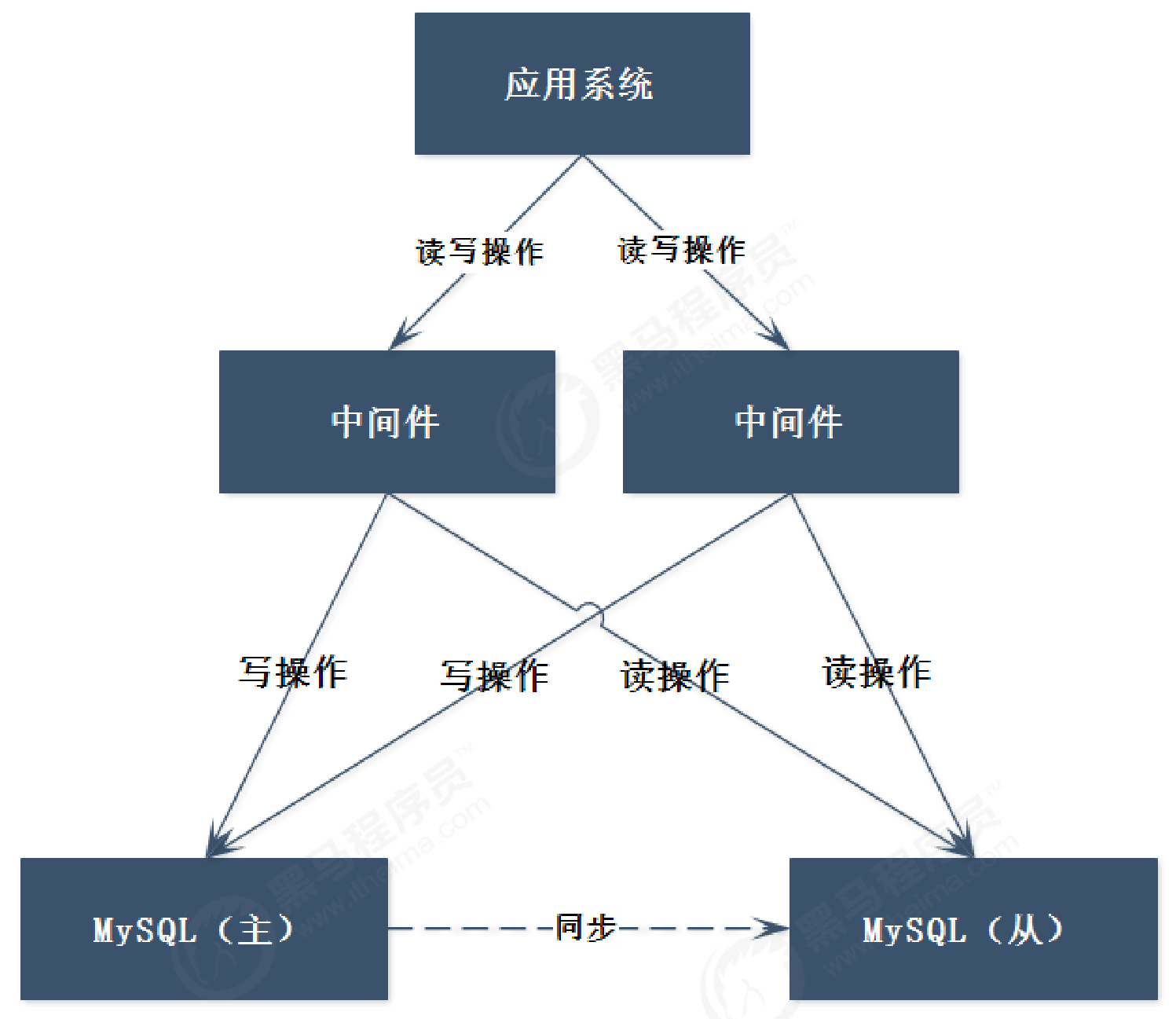
这样的话,中间件的可靠性得到了保证,但是也带来了新的问题,应用系统依然是需要连接到 2个中间件,又为应用系统带来了复杂度。
负载均衡
为了解决以上问题,我们将继续优化架构,在应用程序和中间件之间增加proxy代理,由代理来完成负载均衡的功能,应用程序只需要对接到proxy即可。

至此,主从复制架构的高可用架构才算是搭建完成。
PXC集群架构在前面的架构中,都是基于MySQL主从的架构,那么在主从架构中,弱一致性问题依然没有解决,如果在需要强一致性的需求中,显然这种架构是不能应对的,比如:交易数据。
PXC提供了读写强一致性的功能,可以保证数据在任何一个节点写入的同时可以同步到其它节点,也就意味着可以从其它的任何节点进行读取操作,无延迟。
架构如下:
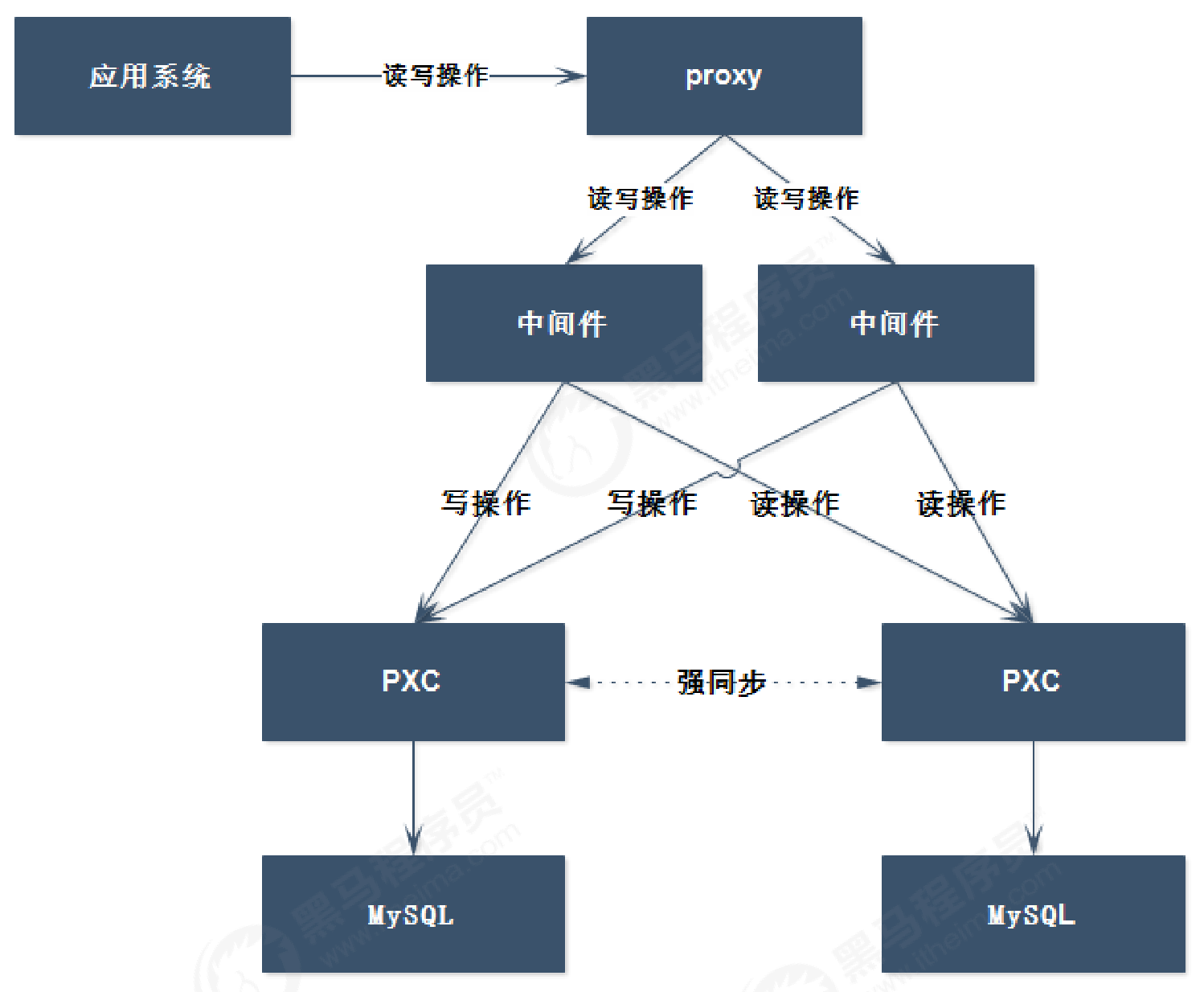
PXC是一个开源的MySQL高可用解决方案,它将Percona Server和Xtrabackup与Galera库集成,以实现同步多主复制。基于Galera的高可用方案主要有MariaDB Galera Cluster(MGC)和Percona XtraDB Cluster(PXC),目前PXC架构在生产环境中用的更多而且更成熟些,PXC相比那些传统的基于主从模式的集群架构MHA和双主,PXC最突出的特点就是解决了诟病已久的复制延迟问题,基本上可以达到实时同步。而且节点与节点之间,它们互相的关系是对等的。本身Galera Cluster也是一种多主架构。PXC是在存储引擎层实现的同步复制,而非异步复制,所以其数据的一致性是相当高的。
混合架构
在前面的PXC架构中,虽然可以实现了事务的强一致性,但是它是通过牺牲了性能换来的一致性,如果在某些业务场景下,如果没有强一致性的需求,那么使用PXC就不合适了。所以,在我们的系统架构中,需要将这两种方式综合起来,这样才是一个较为完善的架构。

2、搭建主从复制架构
主从复制原理
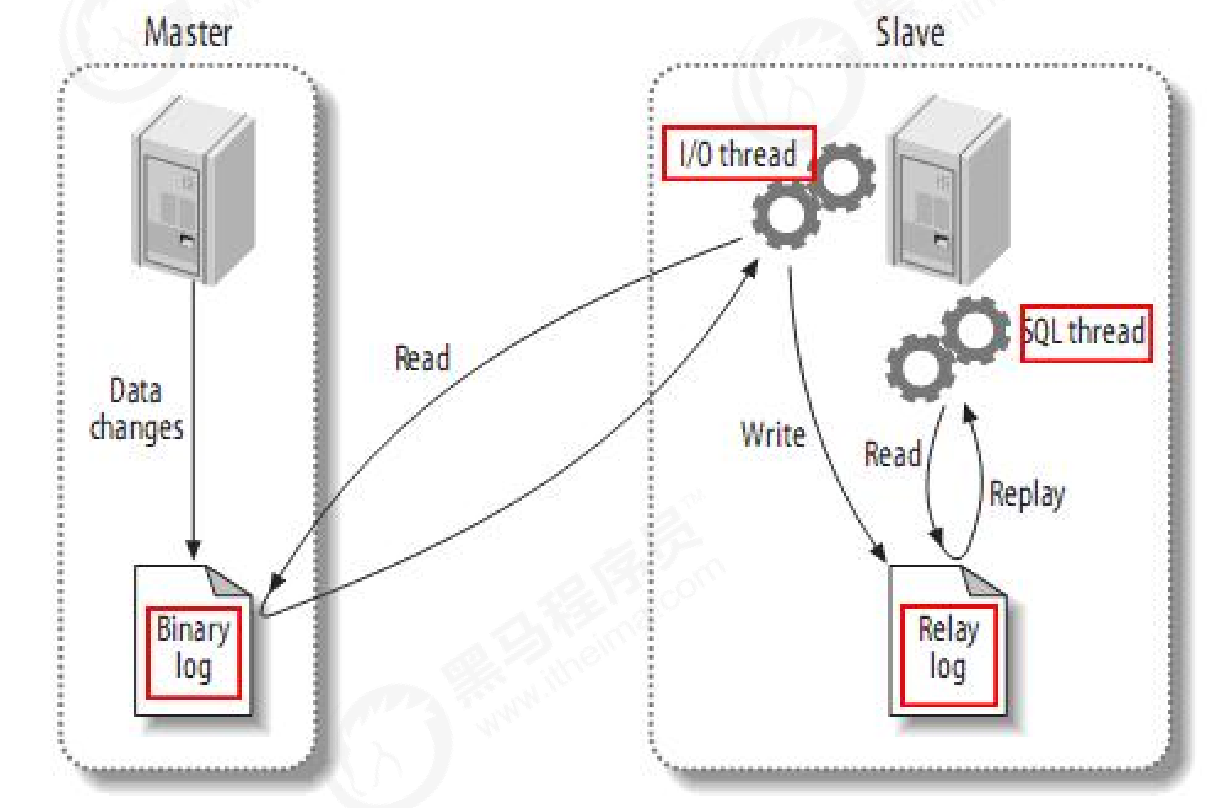
mysql 主(称master)从(称slave)复制的原理:
(1)、master 将数据改变记录到二进制日志(binary log)中,也即是配置文件log-bin指定的文件(这些记录叫做二进制日志事件,binary log events)
(2)、slave 将master的binary log events拷贝到它的中继日志(relay log)
(3)、slave 重做中继日志中的事件,将改变反映它自己的数据(数据重演)
主从配置需要注意的地方
(1)、主 Mysql和从Mysql数据库的版本一致
(2)、主 Mysql和从Mysql数据库数据一致
(3)、主 Mysql开启二进制日志,主Mysql和从Mysql的server_id都必须唯一
主从复制(一主一从)参考:https://www.cnblogs.com/zwh0910/p/16511041.html
主从复制(一主三从)参考:https://www.cnblogs.com/zwh0910/p/17247296.html
3、主从复制模式
进入容器中,执行以下命令:
show global variables like 'binlog%';
结果:
mysql> show global variables like 'binlog%'; +------------------------------------------------+--------------+ | Variable_name | Value | +------------------------------------------------+--------------+ | binlog_cache_size | 32768 | | binlog_checksum | CRC32 | | binlog_direct_non_transactional_updates | OFF | | binlog_encryption | OFF | | binlog_error_action | ABORT_SERVER | | binlog_expire_logs_seconds | 2592000 | | binlog_format | ROW | | binlog_group_commit_sync_delay | 0 | | binlog_group_commit_sync_no_delay_count | 0 | | binlog_gtid_simple_recovery | ON | | binlog_max_flush_queue_time | 0 | | binlog_order_commits | ON | | binlog_rotate_encryption_master_key_at_startup | OFF | | binlog_row_event_max_size | 8192 | | binlog_row_image | FULL | | binlog_row_metadata | MINIMAL | | binlog_row_value_options | | | binlog_rows_query_log_events | OFF | | binlog_stmt_cache_size | 32768 | | binlog_transaction_compression | OFF | | binlog_transaction_compression_level_zstd | 3 | | binlog_transaction_dependency_history_size | 25000 | | binlog_transaction_dependency_tracking | COMMIT_ORDER | +------------------------------------------------+--------------+ 23 rows in set (0.00 sec)
在查看二进制日志相关参数内容中,会发现默认的模式为 ROW,其实在MySQL中提供了有3种模式,基于SQL语句的复制(statement-based replication, SBR),基于行的复制(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。对应的,binlog的格式也有三种:STATEMENT,ROW,MIXED。
STATEMENT模式(SBR)
每一条会修改数据的sql语句会记录到binlog中。
优点是并不需要记录每一条 sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。
缺点是在某些情况下会导致 master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-definedfunctions(udf)等会出现问题)
ROW模式(RBR)
不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是altertable的时候会让日志暴涨。
MIXED模式(MBR)
以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
建议使用MIXED模式。
# 修改主库的配置
binlog_format=MIXED
如下:
server-id=100 log-bin=master-bin binlog-ignore-db=information_schema binlog-ignore-db=mysql binlog-ignore-db=performance_schema binlog-ignore-db=sys binlog_format=MIXED
重启容器
docker restart mysql-master
进入容器查看主从复制模式
结果如下:
mysql> show global variables like 'binlog%'; +------------------------------------------------+--------------+ | Variable_name | Value | +------------------------------------------------+--------------+ | binlog_cache_size | 32768 | | binlog_checksum | CRC32 | | binlog_direct_non_transactional_updates | OFF | | binlog_encryption | OFF | | binlog_error_action | ABORT_SERVER | | binlog_expire_logs_seconds | 2592000 | | binlog_format | MIXED | | binlog_group_commit_sync_delay | 0 | | binlog_group_commit_sync_no_delay_count | 0 | | binlog_gtid_simple_recovery | ON | | binlog_max_flush_queue_time | 0 | | binlog_order_commits | ON | | binlog_rotate_encryption_master_key_at_startup | OFF | | binlog_row_event_max_size | 8192 | | binlog_row_image | FULL | | binlog_row_metadata | MINIMAL | | binlog_row_value_options | | | binlog_rows_query_log_events | OFF | | binlog_stmt_cache_size | 32768 | | binlog_transaction_compression | OFF | | binlog_transaction_compression_level_zstd | 3 | | binlog_transaction_dependency_history_size | 25000 | | binlog_transaction_dependency_tracking | COMMIT_ORDER | +------------------------------------------------+--------------+ 23 rows in set (0.01 sec)
可以看到,设置已经生效。并且进行测试,同步功能正常。
五、数据库集群
如果访问量非常大,虽然使用读写分离能够缓解压力,但是一旦写操作一台服务器都不能承受了,这个时候我们就需要考虑使用多台服务器实现写操作。
例如可以使用MyCat搭建MySql集群,对ID求3的余数,这样可以把数据分别存放到3台不同的服务器上,由MyCat负责维护集群节点的使用。

