单行函数:作用于一行,返回一个值
多行函数:作用于多行,返回一个值
单行函数
1、单行函数----字符函数upper和lower
(1)、upper和lower
upper把小写的字符转换成大小的字符 ,lower把大写字符变成小写字符 .
select upper('yes') from dual;--YES select lower('YES') from dual;--yes
项目中使用:
<if test="null!=batch and batch !=''">
and upper(t2.batch) LIKE '%' || upper(#{batch}) || '%'
</if>
2、单行函数----数值函数round、trunc和mod
(1)、round:
四舍五入函数,默认情况下 ROUND 四舍五入取整,可以自己指定保留的位数。函数后面的参数表示保留的位数,1表示保留一位小数,二表示保留两位小数,-1表示小数点前面进行1位的四舍五入,56就会变成60,-2表示小数点前面进行2为的四舍五入,56就会变成100.
select round(56.166, 1) from dual;--56.2
select round(56.166, 2) from dual;--56.17
select round(56.166, -1) from dual;--60
select round(56.166, -2) from dual;--100
项目中使用:
SELECT A.supplierName,ROUND(A.receiveWt/1000,2) as receiveWt,ROUND(IFNULL(B.qualifiedWt,0)/1000,2) AS qualifiedWt FROM 。。。
(2)、trunc:截断,是truncation的缩写
直接截取,不再看后面位数的数字是否大于5(前面大于5则四舍五入进一位)
select trunc(56.166, 1) from dual;--56.1 select trunc(56.166, 2) from dual;--56.16 select trunc(56.166, -1) from dual;--50 select trunc(56.166, -2) from dual;--0
(3)、mod:求余,是modulo的缩写
select mod(10, 6) from dual;
3、单行函数----日期函数
Oracle 中提供了很多和日期相关的函数,包括日期的加减,在日期加减时有一些规律:
日期 – 数字 = 日期
日期 + 数字 = 日期
日期 – 日期 = 数字
(1)、SYSDATE函数
SYSDATE函数可以得到目前系统的时间,如:select sysdate from dual;
----查询出emp表中所有员工入职距离现在几天。 select sysdate-e.hiredate from emp e; ----算出明天此刻 select sysdate+1 from dual; ----查询出emp表中所有员工入职距离现在几周。 select round((sysdate-e.hiredate)/7) from emp e;
date类型可以直接加减,单位为天。
(2)、MONTHS_BETWEEN() :获得两个时间段中的月数;
----查询出emp表中所有员工入职距离现在几月。 select months_between(sysdate,e.hiredate) from emp e; ----查询出emp表中所有员工入职距离现在几年。 select months_between(sysdate,e.hiredate)/12 from emp e;
(3)、add_months():加多少个月
select sysdate,add_months(sysdate,12) from dual; --加1年
项目中使用:
insert into SYS_DATA_SET values(seqId, 'audit_type', '审核状态类型', '0', null, null, sysdate, null, sysdate);
<insert id="saveMobileMenu">
insert into sys_role_menu_mobile (role_id, menu_id, del_flag, create_by, create_time) VALUES
<foreach collection="list" item="item" separator=",">
(#{roleId}, #{item},0,#{userId}, sysdate())
</foreach>
</insert>
<update id="softDeleteByKey" parameterType="com.jawasoft.pts.entity.IntelDrugStore">
update t_intel_drugstore
set del_flag = '2',
update_by = #{updateBy},
update_time = sysdate
where id = #{id}
</update>
4、单行函数----转换函数
(1)、TO_DATE:将字符串的数据转换成日期类型
to_date()用法如下:
TO_DATE('2020-11-05 23:59:59', 'yyyy-mm-dd hh24:mi:ss')
前者为字符串,后者为转换日期格式。前后两者要以一对应。
日期格式没有大小写之分,由于月不区分大小写故写成mm,所以分不要写成mm,而是写成mi,如果是24小时制,则在hh后面加24,不加24则表示12小时制。
项目中使用:
<if test="null!=startDate and startDate !=''">
and t1.upload_time >= to_date('${startDate}','yyyy-mm-dd')
</if>
<if test="null!=endDate and endDate !=''">
and t1.upload_time <= to_date('${endDate}','yyyy-mm-dd')
</if>
(2)、TO_CHAR:将日期按一定格式转换成字符类型
to_char()用法如下:
select empno,ename,to_char(hiredate,'yyyy-mm-dd') from emp;
在结果中,如1981-02-20, 10 以下的月前面被被补了前导零,可以使用 fm 去掉前导零 to_char(hiredate,'fm yyyy-mm-dd'),改完之后1981-2-20
日期格式没有大小写之分,由于月不区分大小写故写成mm,所以分不要写成mm,而是写成mi,如果是24小时制,则在hh后面加24,不加24则表示12小时制。
(3)、TO_NUMBER:将日期按一定格式转换成字符类型
将char或varchar2类型的string转换为一个number类型的数值,
需要注意的是,被转换的字符串必须符合数值类型格式,如果被转换的字符串不符合数值型格式,Oracle将抛出错误提示;
to_number和to_char恰好是两个相反的函数;
select to_number('88877') from dual;
5、单行函数----通用函数
(1)、空值处理nvl:是null value的缩写,表示如果是null,则用后面的。
范例:查询所有的雇员的年薪
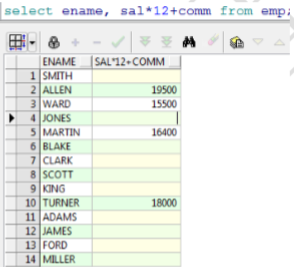
我们发现很多员工的年薪是空的,原因是很多员工的奖金是 null,null和任何数值计算都是null,这时我们可以使用 nvl来处理。
select ename,nvl(comm,0),sal*12+nvl(comm,0) from emo;

(2)、Decode函数(Oracle专用条件表达式)
该函数类似 if....else if...esle ,语法:DECODE(col/expression, [search1,result1],[search2, result2]....[default])
Col/expression:列名或表达式;Search1,search2...:用于比较的条件 ;Result1, result2...:返回值
如果 col/expression 和 Searchi匹配就返回 resulti,否则返回 default 的默认值
范例:查询出所有雇员的职位的中文名 :字段为job,如果job为clerk,则返回业务员,以此类推,如果都未匹配上,则返回无业
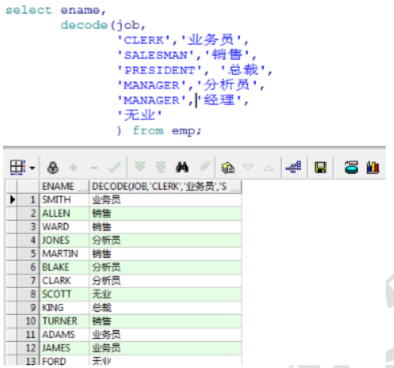
Oracle中除了起别名,都用单引号,起别名用双引号。

(3)、case when then else end(Oracle和mysql通用)
语法如下:
CASE expr WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
示例:
select t.empno, t.ename,case when t.job = 'CLERK' then '业务员' when t.job = 'MANAGER' then '经理' when t.job = 'ANALYST' then '分析员' when t.job = 'PRESIDENT' then '总裁' when t.job = 'SALESMAN' then '销售' else '无业' end from emp t
when和then可以有多个, else可省略,end必须有。
1、如果是等值判断,我们一般写成下面这种形式

在这里ename写在case后面,表示列名ename等于‘smith’。当然我们也可以写成case e.ename = 'smith'
2、如果是范围判断,则把列名放在when后面


在项目中的应用:
select update_time,create_time, case when (update_time is null or update_time = '') then create_time else update_time end from 表名;
<select id="selectTsList" resultType="java.util.Map"> select tts.ID "id",product_Name "productName", DECODE(tts.line_type, '1', tts.production_batch, tts.import_Batch) "batch", localtion "localtion", d.name as "productUnit" , tts.uom as "uom", (case when tts.LINE_TYPE='1' then tts.complete_Qty else tts.import_num end ) as "batchNum", material_Code "materialCode", '1' "materialType" from T_TRACEABILITY_SLICE tts left join sys_department d on tts.workshop_code=d.code <include refid="tsListWhere"></include> order by tts.create_time desc </select>
5、单行函数-sys_guid()
是一种生成不重复的数据的一个函数,sys_guid()一共32位,生成的依据主要是时间和机器码,具有世界唯一性,类似于java中的UUID(都是世界唯一的)。
是数据库中生成UUID的一种方式。
insert into 表名(ID,SYS_ID) values(sys_guid(),'xxx');
多行函数(聚合函数)
聚合函数又叫分组函数
1、统计记录数 count()
select count(1) from emp;
使用count(*)时,底层其实也是用的count(1)count(1)相当于count(主键).推荐大家写count(1),当然写count(*)也没错。
不建议使用 count(*),可以使用一个具体的列以免影响性能。
2、最小值查询 min() ,最大值查询 max() ,查询平均值 avg()
3、.求和函数 sum()
分组查询group by
分组查询需要使用 GROUP BY来分组
语法:SELECT * |列名 FROM 表名 {WEHRE 查询条件} {GROUP BY 分组字段} ORDER BY 列 名 1 ASC|DESC,列名 2...ASC|DESC
-- 查询出每个部门的平均工资 select deptno,avg(sal) from emp group by deptno;
一般每个后面的字段就是根据这个字段来分组
group by后面出现的字段就可以出现在select后面。
注意: 1. 如果使用分组函数,SQL 只可以把 GOURP BY 分组条件字段和分组(聚合)函数查询出来,不能有其 他字段。


注意:2. 如果使用分组函数,不使用 GROUP BY 只可以查询出来分组函数的值
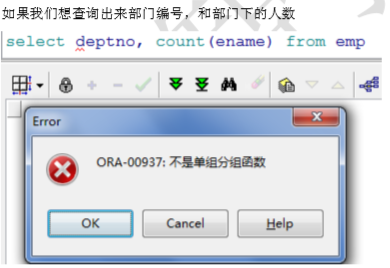
-- 查询平均工资高于2000的部门 select deptno,avg(sal) asal from emp group by deptno having avg(sal)>2000;

不能写成:
-- 查询平均工资高于2000的部门 select deptno,avg(sal) asal from emp group by deptno having asal>2000;
注意:所有条件(where或having后面的条件)都不能使用别名来判断,因为查询的时候是分先后顺序的,因为where和having条件在select之前执行。
--查询出每个部门工资高于800的员工的平均工资 select deptno,avg(sal) from emp where sal>800 group by deptno;
注意:where是过滤分组前的数据,having是过滤分组后的数据。表现形式:where必须在group by之前,having是在group by之后。
--查询出每个部门工资高于800的员工的平均工资,然后再查询出平均工资高于2000的部门 select deptno,avg(sal) from emp where sal>800 group by deptno having avg(sal)>2000;
范例:查询出部门人数大于 5 人的部门 分析:需要给 count(ename)加条件,此时在本查询中不能使用 where,可以使用HAVING
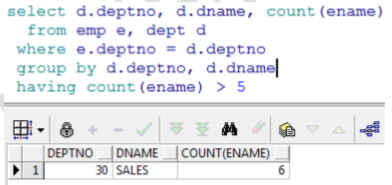
项目中使用group by
<select id="selectOriginalBySv" resultType="java.util.Map"> SELECT t2.id AS originalId, t2.original_name AS originalName FROM t_supplier_variety sv INNER JOIN t_supplier_variety_original svo ON svo.supplier_variety_id = sv.id AND svo.`is_historical` = 0 INNER JOIN t_supplier s ON s.`id` = sv.`supplier_id` INNER JOIN t_variety_original t1 ON sv.`variety_id` = t1.`variety_id` INNER JOIN t_original t2 ON FIND_IN_SET(t2.id, svo.original) WHERE 1=1 AND t1.del_flag = 0 AND t2.del_flag = 0 <if test="supplierId!=null"> AND s.`id` = #{supplierId} </if> <if test="supId!=null"> AND s.`sup_id` = #{supId} </if> <if test="prcId!=null"> AND s.`prc_id` = #{prcId} </if> <if test="varietyId!=null"> AND t1.variety_id = #{varietyId} </if> GROUP BY t2.id, t2.original_name </select>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号