
数据挖掘 期末复习
第1章 绪论
1.1.为什么要进行数据挖掘?
- 数据爆炸但知识匮乏
- 从商业数据到商业智能的进化
- 科学发展范式
1.2.数据挖掘
1.2.1数据挖掘的定义
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的,但又是潜在有用的信息和知识的过程。
1.2.2数据挖掘的过程
问题定义->数据清理和集成->数据变换和规约->选择算法数据挖掘->结果解释模式评估->知识表示
1.2.3数据挖掘的对象
- 结构化数据(二维表格)
- 非结构化数据
- 文本数据
- 音频数据
- 视频数据
- 图像数据
重点是关系数据库和数据仓库的区别:
-
- 关系数据库

-
- 数据仓库

1.2.4数据挖掘的主要内容
- 关联规则挖掘
- 非监督式机器学习
- 聚类
- 监督式机器学习
- 标签分类
- 数值预测
- 回归


第2章 认识数据
2.1 数据对象与类型
2.1.1 数据对象
数据对象代表实体,数据集是由数据对象组成的
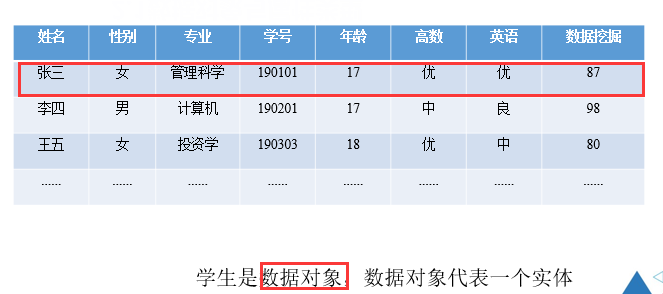
2.1.2 属性
属性:一个数据字段表示一个数据对象的某个特征
- 标称属性
- 二元属性
- 序数属性
- 数值属性
- 区间标度
- 比率标度
标称属性:事物的名称,其值表示类别或者状态,没有大小顺序。
二元属性(布尔属性):特殊的标称属性,其值只有0和1。
序数属性:其值有一个有意义的顺序。
数值属性:数值可以度量
- 区间属性:
- 相等的单位尺度
- 值有序
- 没有真正的0点
- 比率标度
- 有真正意义的0点
- 数值之间有倍数关系
2.2数据描述统计
2.2.1简单统计量
- 均值
- 中位数
- 众数
- 中列数:最大值与最小值的平均值
- 极差:数据中最大与最小的差距
正倾斜:众数小于中位数
负倾斜:众数大于中位数
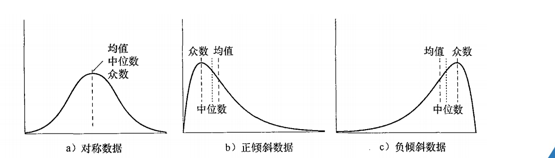
2.2.2复杂统计量
- 分位数、分位数极差
- 五数概括、箱线图
- 方差、标准差、变异系数
2.2.2.1.分位数
① 分位数:将一个随机变量的概率分布范围分为几个等分的数值点
② %p分位数:至少有p%的数据小于或者等于这个值,且至少有(100-p)%的数据项大于等于这个值。
%p分位数计算方法:
- 递增序列
- 计算位置的指数 i = (p/100)n 【n表示数据的个数】
- 判断i是否为整数:
-
- 如果 i 不是整数,将其向上取整 【大于小数的最小整数】
- 如果 i 是整数,则p分位数为第 i 和 i+1 项的数据的平均值。


③ 特定的百分位数:
- 第一个四分位数是25%百分位数
- 第二个四分位数是50%百分位数
- 第三个四分位数是75%百分位数
④ 四分位数:Q1,Q2,Q3 【25%,50%,75%】
Q1:下四分位数
Q2:中位数
Q3:上四分位数
四分位数的极差:IQR = Q3-Q1
2.2.2.2 五数概括、箱线图
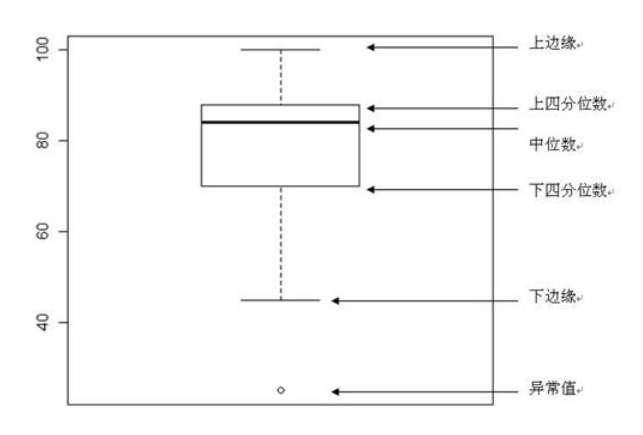
箱子的中间一条线:是数据的中位数,Q2
箱子的上下限,分别是数据的上四分位数,Q3和下四分位数,Q1
箱子的上边缘和下边缘:是数据的最大值和最小值,其中
最大值:Q3+1.5*IQR
最小值:Q1-1.5*IQR
异常值(离群点):小于最小值或者大于最大值的点。
2.2.2.3 方差、标准差和变异系数
① 方差

② 标准差

③ 变异系数

2.3 数据相似性和相异性度量
相似度:
- 度量两个对象的相似性
- 值越大表示数据对象越相似
- 取值范围 [0,1]
相似度:
- 度量两个数据对象的差别程度
- 值越小表示数据对象越相似
- 最小相似度通常为0
近邻性:指相似度或者相异度
2.3.1 标称属性的近邻度量
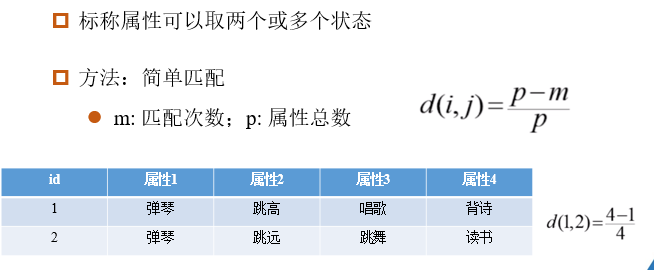
2.3.2 二值属性的近邻性度量

第3章 数据预处理
3.1 数据预处理的任务
- 数据清理:填写缺失值,平滑噪声数据,识别或者删除离群点,解决不一致问题
- 数据集成:整合多个数据库,多维数据集或文件
- 数据规约:
- 降维
- 降数据
- 数据压缩
- 数据转换
- 规范化
- 离散化
3.2 数据清理
3.2.1 处理丢失数据
- 手动填写
- 自动填写
- 使用最可能的值填充缺失值
- 回归分析
- 决策树
- 使用填充算法来处理缺失值
- K近邻算法
3.2.2 处理噪声数据
噪声:一个测量变量中的随机错误或者偏差,包括错误的值和偏离期望的孤立点。
常见方法:
- 分箱法
- 回归
- 聚类
3.2.3 处理异常值
异常值(离群点):在箱线图的上边缘和下边缘之外的点。
异常值处理方法:
- 删除异常值
- 不处理
- 平均值代替
- 视为缺失值
注意异常值和噪声数据的区别:

3.3 数据集成
将来自多个数据源的数据组合成一个连贯的数据源
3.4 数据归约
3.4.1.数据归约的原因
由于数据仓库存储数据的容量大,
因此在一个完成的数据集上运行时,复杂的数据分析需要很长时间
3.4.2 数据规约策略:
- 降维
- 降数据
- 数据压缩
3.5 数据转换
数据转换方法:
- 规范化
- 离散化
3.5.1 数据规范化
- 最小值-最大值规范化
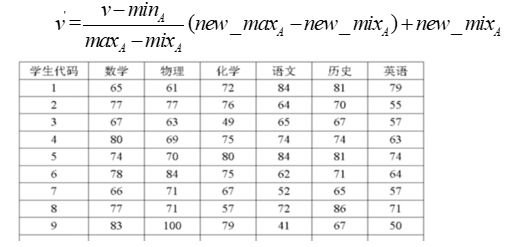
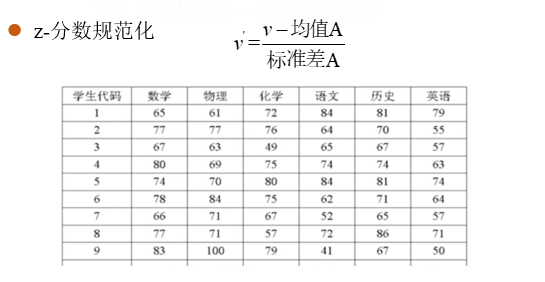
- Z-得分正常化
- 小数定标规范化

3.5.2 数据离散化
- 非监督离散
- 等宽法:根据属性的值域划分,使每个区间的宽度相等
- 等频法:根据取值出现的频数划分,将属性的值域划分成小区间,并且要求每个区间的样本数量相同。
- 聚类法
第4章 关联规则
关联规则反映一个事物与其他事物之间的相互依存性和关联性,如果两个或者多个事务之间存在一定的关联关系,
那么,其中一个事物的发生就能够预测与它相关联的事物的发生。
4.1 关联规则的相关概念
1.支持度
包含项集的事物数与总事物数的比值
2.频繁项集
满足最小支持阈值的所有项集。
3.最大频繁项集
直接超集【父集】都不是频繁的。
4.2 关联规则的产生
1. 关联规则
X->Y的表达式,X和Y是不相交的项集
- 支持度----确定项集的频繁程度
即(x,y)在数据集中出现的频率
- 置信度----确定Y在包含X的事物中出现的频繁程度
即X对Y的条件概率 P(Y|X) = P(XY)/P(X)

- 关联规则是在给定事物集T中,找出支持度不小于minsup并且置信度不小于minconf的所有规则,其中
- minsup表示支持度的阈值
- minconf表示置信度的阈值
2. 关联规则的任务
-
- 频繁项集产生
- 规则的产生
3. 关联规则的计算方法
-
- Apriori算法
- FT-Growth
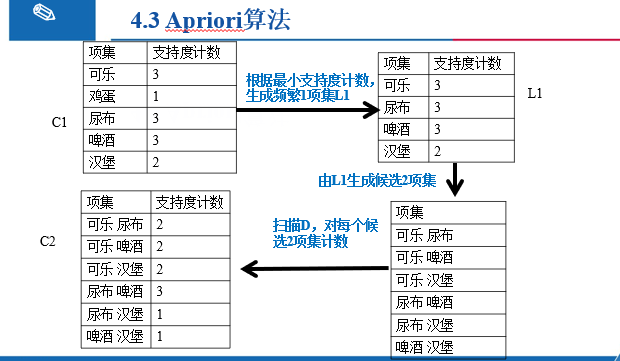
4.3 Apriori算法
算法步骤:
1.通过迭代,找出事物集中所有的频繁项集【不小于支持度阈值】
2.利用频繁项集构造出满足用户最小信任度的规则
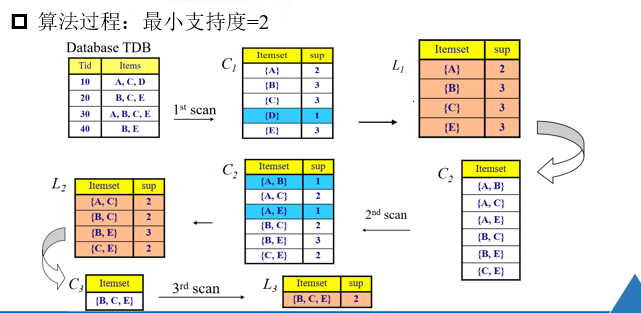
注意:
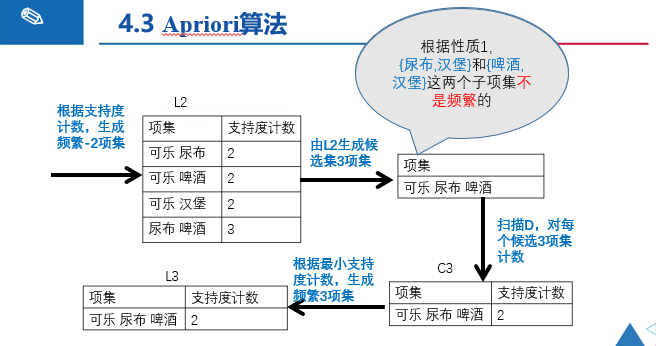
在L2中求出的频繁二项集,将L2中项集两两合并,例如
{A,C}和{B,C}--->{A,B,C},由于之前的{A,B}不是频繁二项集,所以{A,B,E}不可能是频繁三项集。
{A,C}和{B,E}是四项集了,不符合题意。
{A,C}和{C,E}--->{A,C,E},由于之前的{A,E}不是频繁二项集,所以{A,C,E}不可能是频繁三项集。
{B,C}和{C,E}--->{B,C,E},由于{B,C,E}中的二项集都是频繁二项集,所以{B,C,E}可能是频繁二项集。
k项集不是频繁项集,则k+i项集也不是频繁项集。
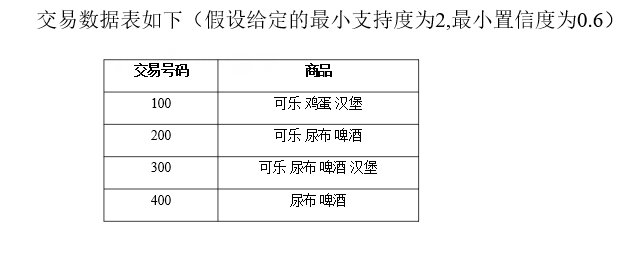
例题:




4.4 FP-Growth算法
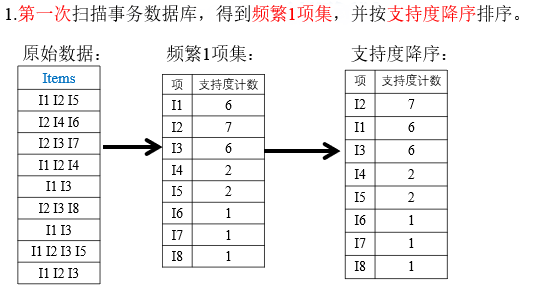
FP-Growth:频繁模式增长算法算法步骤:
- 构建FP树
- 从FP树中挖掘频繁项集
例题:
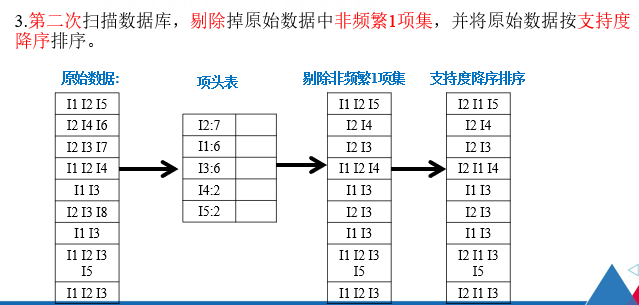
注解:
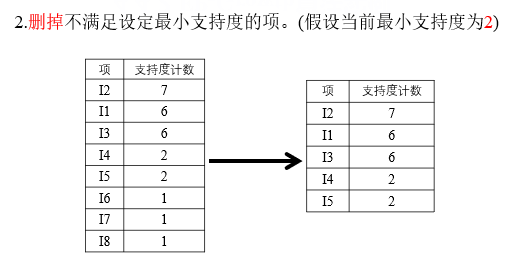
删除原始事物集中的非频繁1项集,即将I6,I7,I8删除。
并且在每个项集中按照支持度的降序排序。
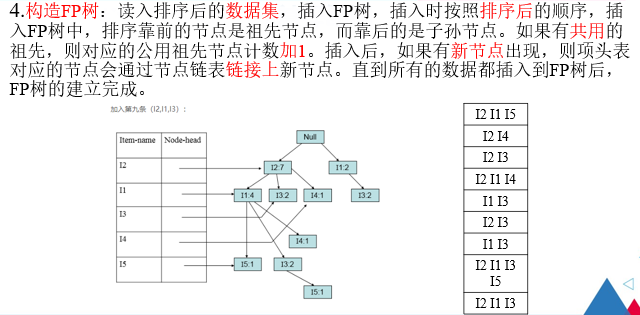
注解:
具体构建FP树的步骤,请见如下博客
FP-growth算法发现频繁项集(一)——构建FP树 - 我是8位的 - 博客园 (cnblogs.com)
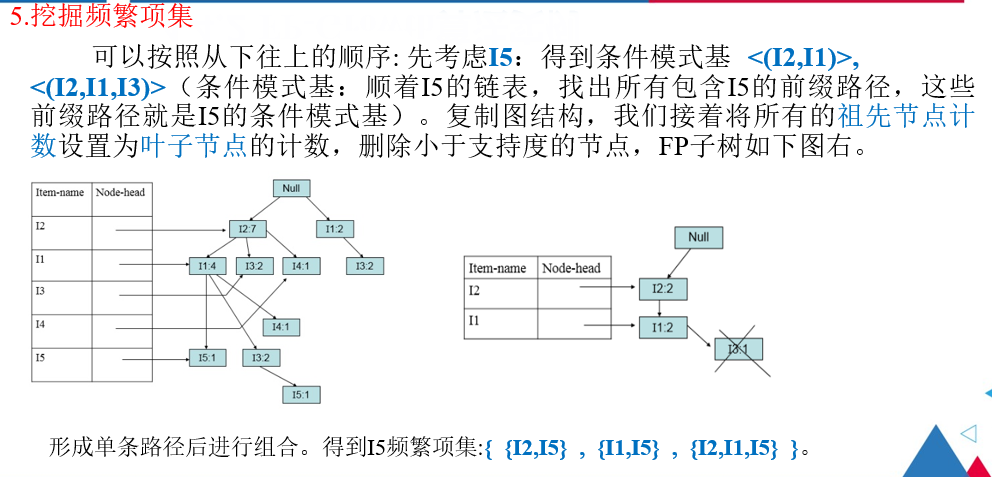
注解:
I5的条件模式基是{I1,I2}和{I1,I2,I3},接着将所有祖先节点计数设置为叶子节点的计数,即
将{I1,I2}的计数设置为1,1,将{I1,I2,I3}的计数设置为1,1,1。
此时I2的计数是2,I1的计数是2,I3的计数是1,I3的计数小于支持度,因此剔除I3。
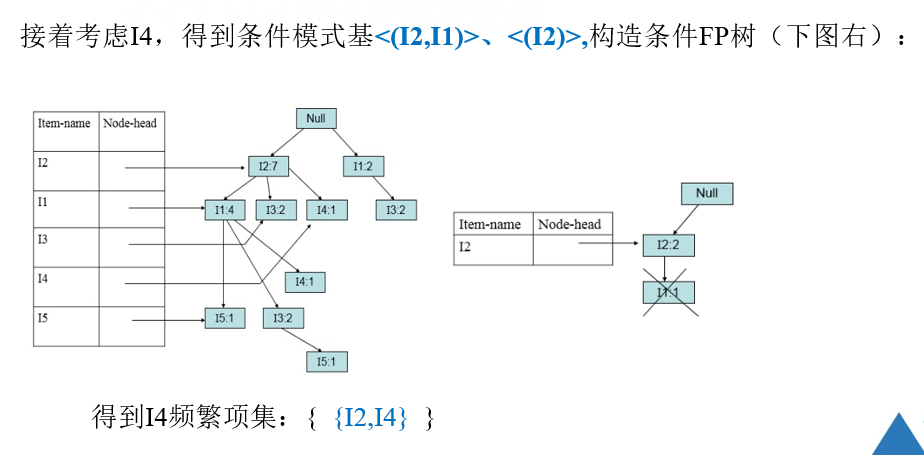
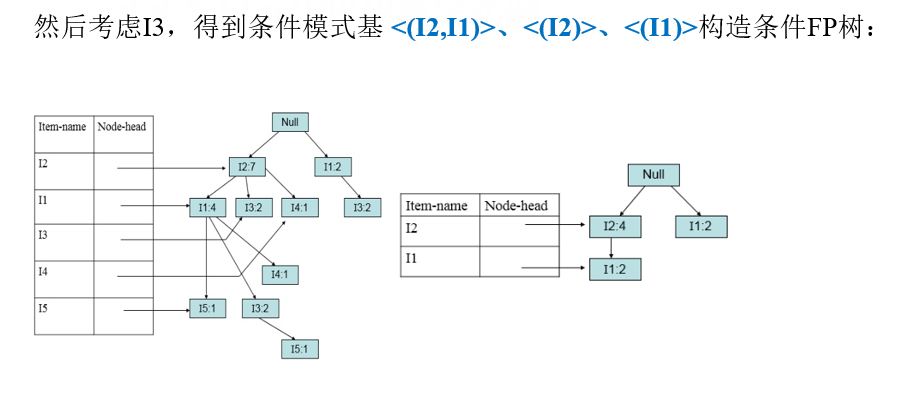
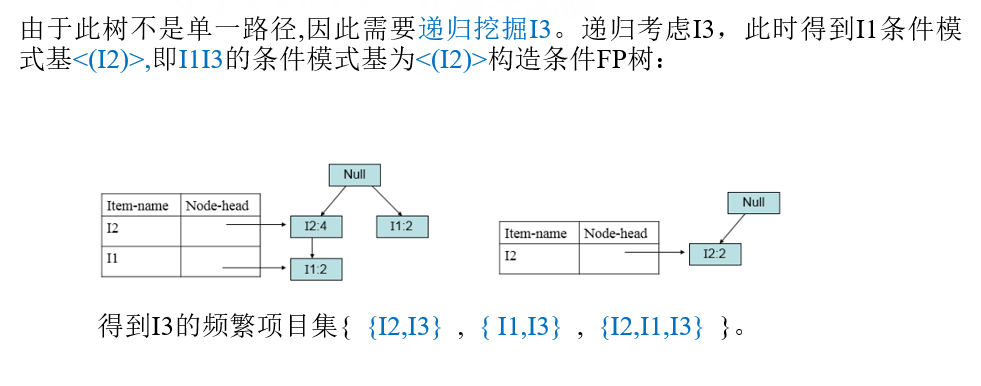
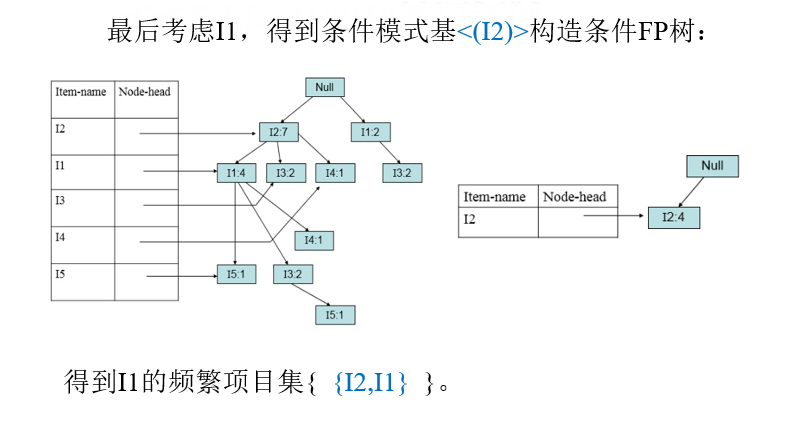
4.5 实用性度量(关联规则评价指标)
- 规则提升度
- 置信度
- 置信率
- 正太卡方
- 部署能力
(1).规则提升度:
规则提升度表示Lift:提升度表示X项集出现,对Y项集的出现有多大影响
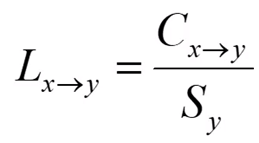
其中,C表示置信度,S表示支持度。
公式反映了项集X和Y的相关程度
- 若L(A->B) = 1,说明X与Y相互独立
- 若L(A->B) <1,说明X与Y负相关
- 若L(A->B) >1,说明X与Y正相关
(2).置信度D:
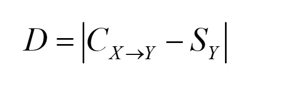

(3) 置信率R:
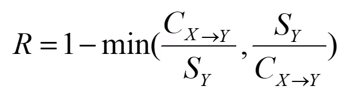

(4)正太卡方
(5)部署能力
第5章 聚类分析
5.1 聚类分析简介
聚类分析:将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合称为簇。
聚类目的:使得属于同一个簇的样本之间应该彼此相似,不同簇的样本应该尽量不相似。
即 簇内相似度尽量较大,簇间相似度尽量小。
注意 聚类与分类的区别:
- 聚类操作:簇的形成是数据驱动的,属于无指导的学习方法---->无监督式学习
- 分类操作:事先定义好类别,类别的数量在分类的过程中不变---->监督式学习
常见的聚类分析算法:
- 划分
- 层次
- 密度
- 概率
- 图和网络
5.2 基于划分的聚类方法
划分的思想:
- 将数据对象划分成不重叠的簇(子集)
- 给定一个含有n个数据对象的集合,以及构建数据的k个分区
- 将n个数据对象划分成k个组,每组至少包含一个数据对象。
典型的划分方法:
- k-means(K均值)
- k-medoids(K中心点)
5.2.1 K-means算法

例题:
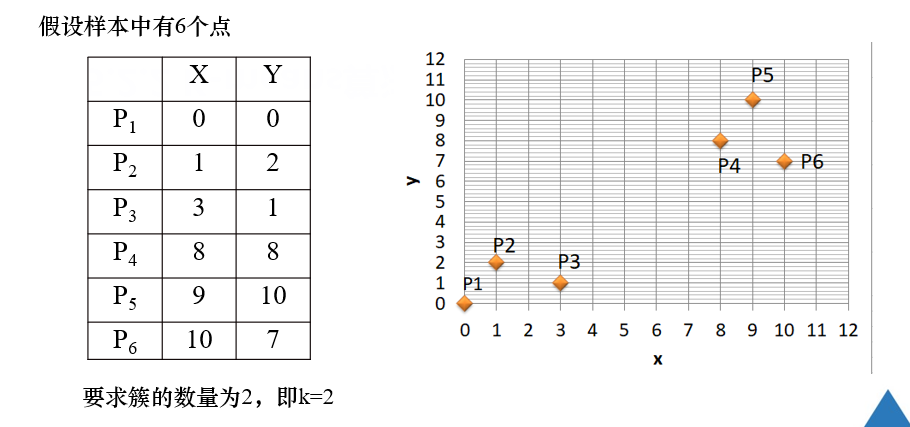
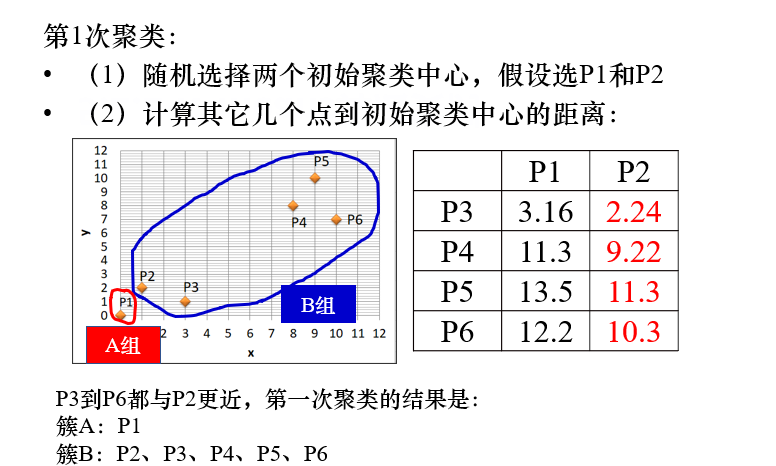
注解:
第一次聚类,随机选择初始聚类中心点【若出题,则题目肯定指定】
依据 初始聚类中心点,计算其余各点到中心点的距离,比较各点与p1和p2的距离,距离小的点和对应的中心点合并。
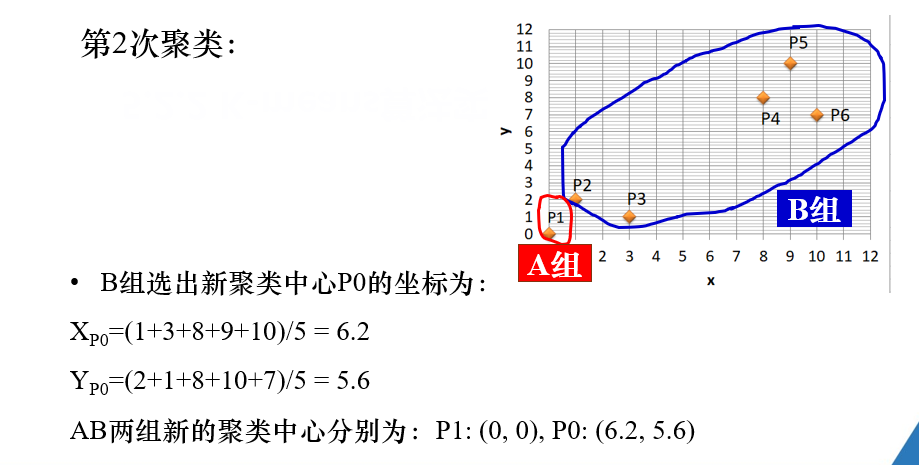
注解:
在第二次聚类过程中,B组的聚类中心点 p0,通过B组各点的x,y坐标的均值求得。
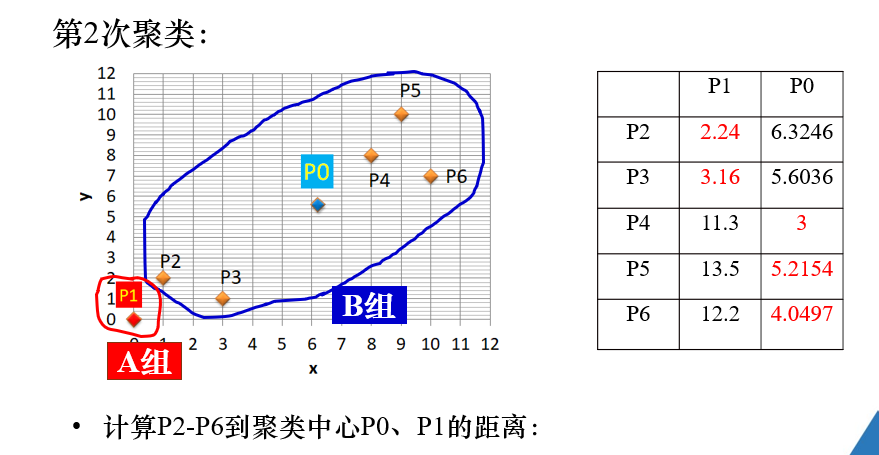
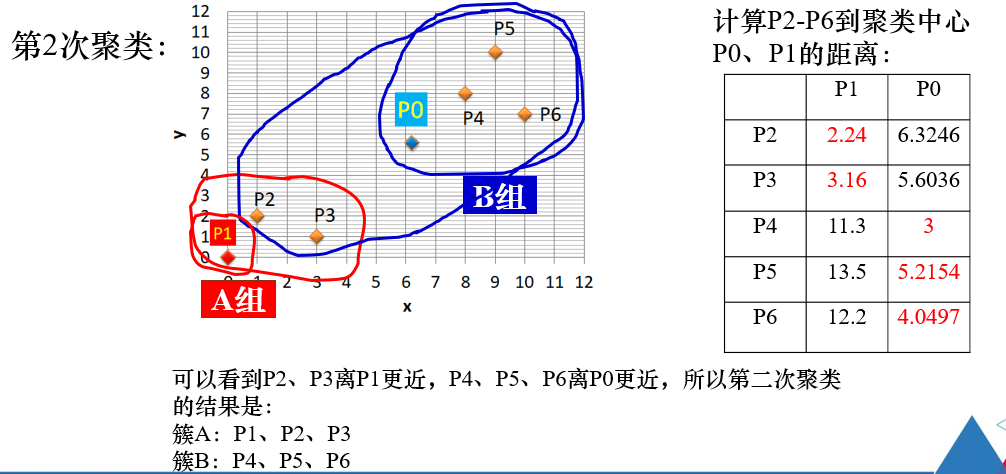
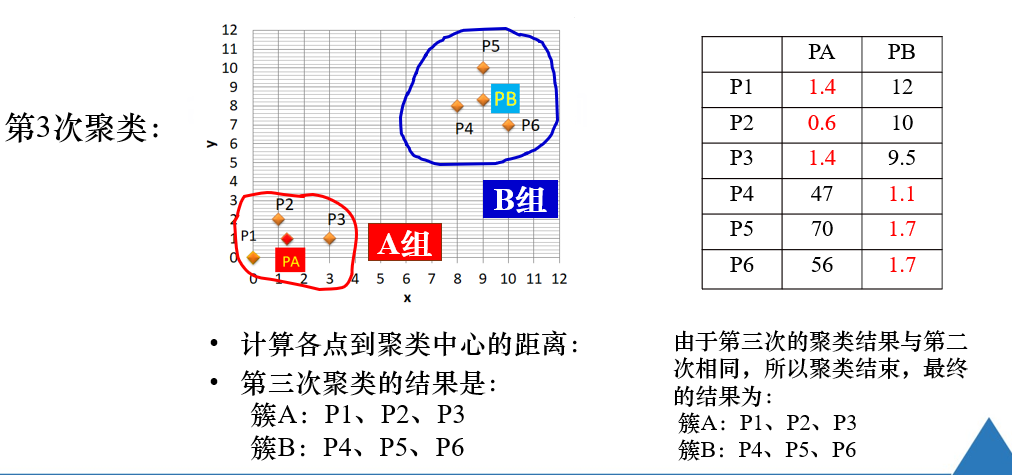
注解:
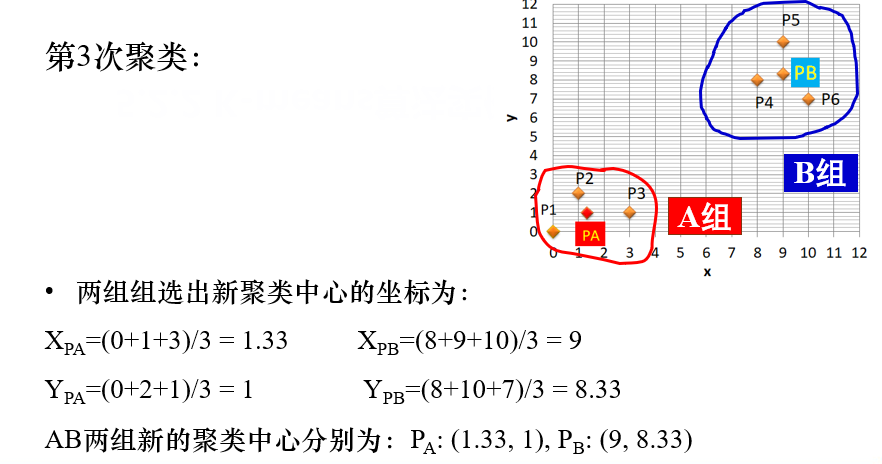
在第三次聚类后,结果与第二次聚类结果相同,即聚类中心不再发生变化,
因此结束,得到k个簇。
5.2.2 K-means算法的优缺点
- 优点

- 缺点

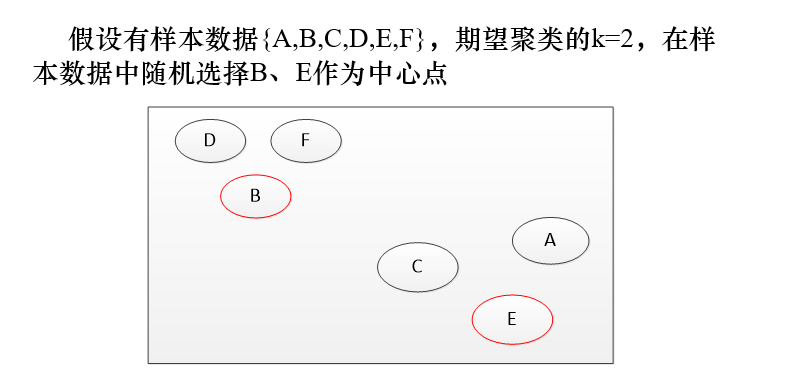
5.2.3 K-mediods算法

例题
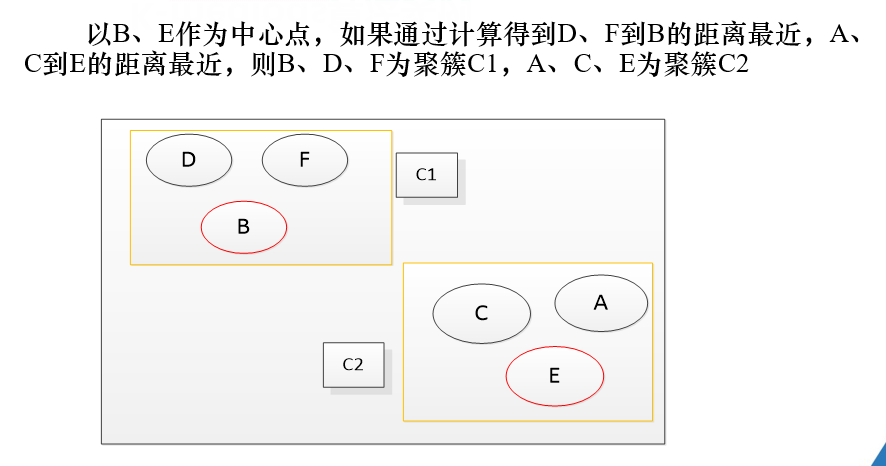
 。
。
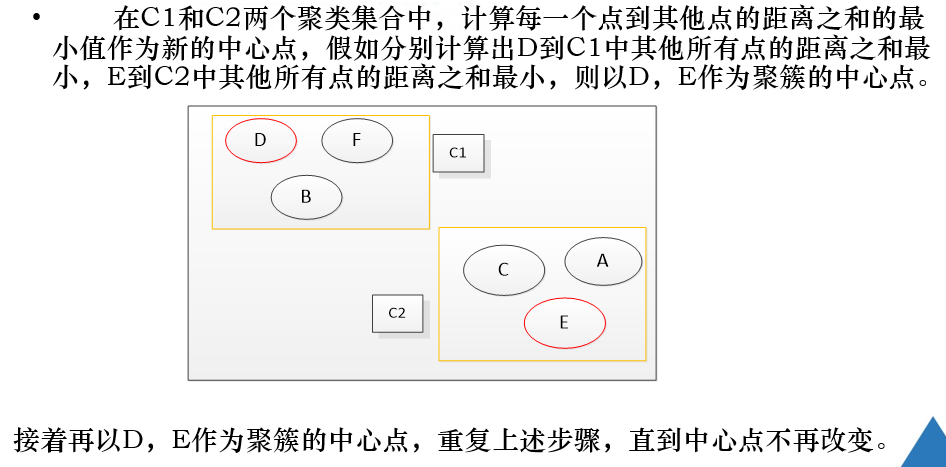
注解:
区别与k-means算法:
在选择聚类中心点的过程中:
- k-means算法:取簇内所有点的x,y坐标的平均值,作为该簇的聚类中心点。
- k-mediods算法:在簇中,选择与其他点【是同一簇内的点】之间的距离之和最小的点作为簇的聚类中心点。
5.2.4 k-mediods算法的优缺点

5.3 基于层次的聚类算法
层次法:将数据对象创建成一棵聚类的树。
由此分为
- 自顶向下
- 自底向上
常见的层次聚类方法:
- 凝聚式层次聚类【自底向上】
- 分裂式层次聚类【自顶向下】
5.3.1 基于层次聚类算法的基本概念
簇的直径:簇中任意两个对象之间的欧式距离的最大者
簇的内径:簇中任意两个对象之间的欧式距离的最小者
最小距离:两个簇中最靠近的两个元素间的距离
最大距离:两个簇中最远的两个元素之间的距离
中心距离:两个簇的中心点之间的距离
5.3.2 凝聚式层次聚类

注解:
凝聚式层次聚类是找出簇间距离最小的两个簇进行合并。
例题
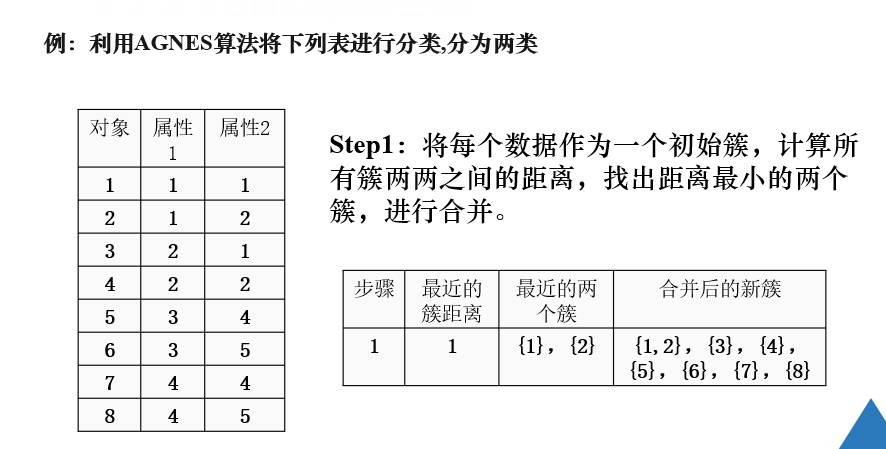
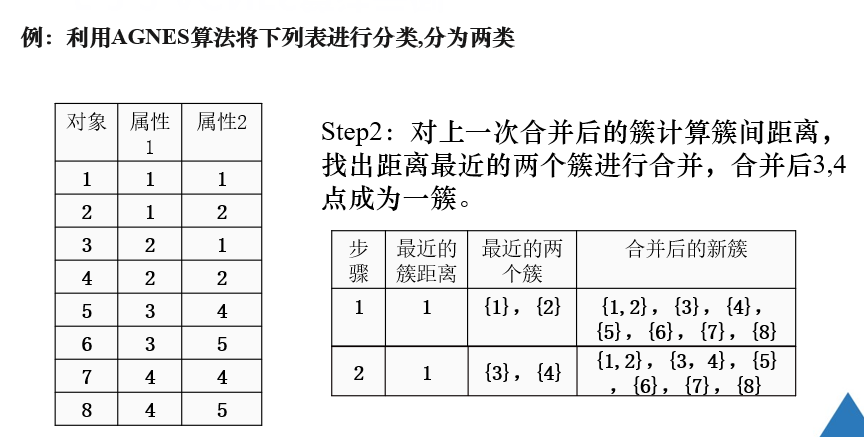
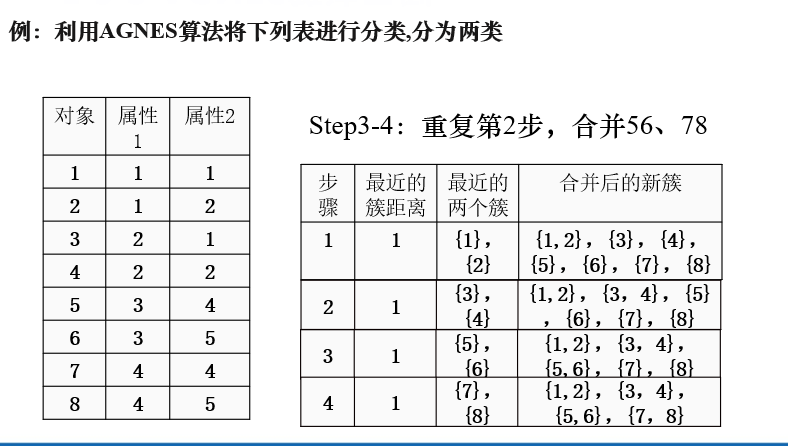
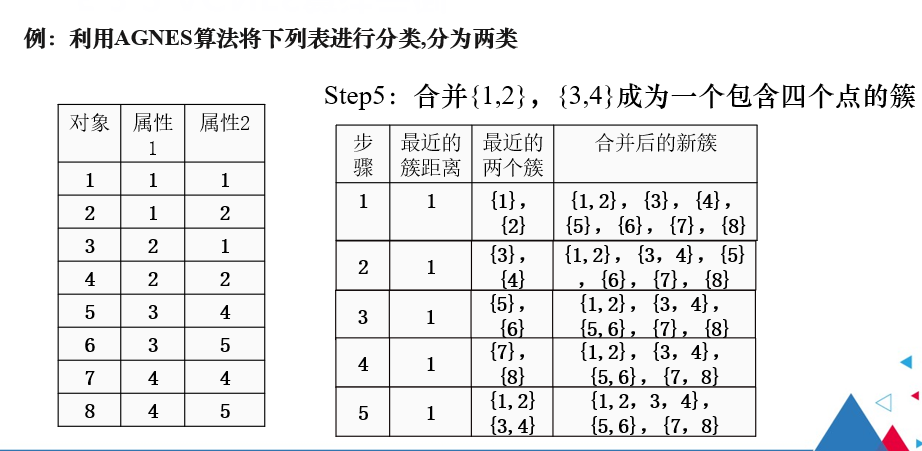
注解:
此时{1,2}和{3,4}簇间距离最小,因此将二者合并。
同理
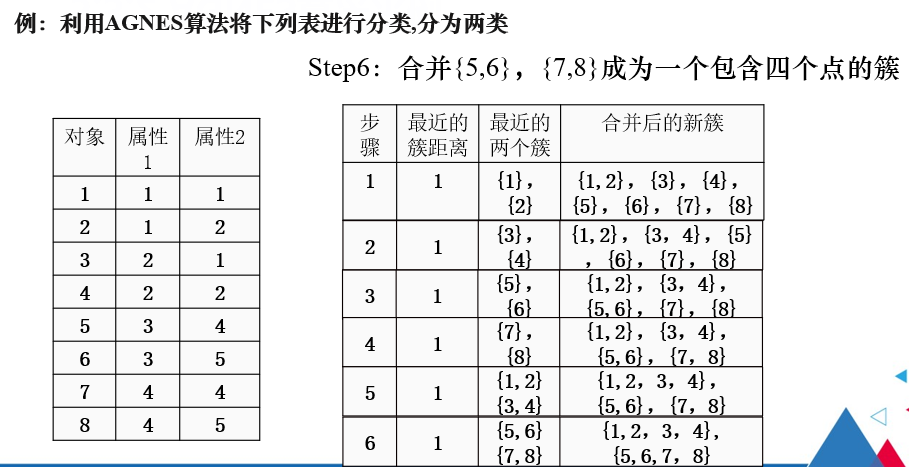
5.3.3 分裂式层次聚类

注解:
分裂式层次聚类是找出最大直径的簇,将其分裂出来。
例题
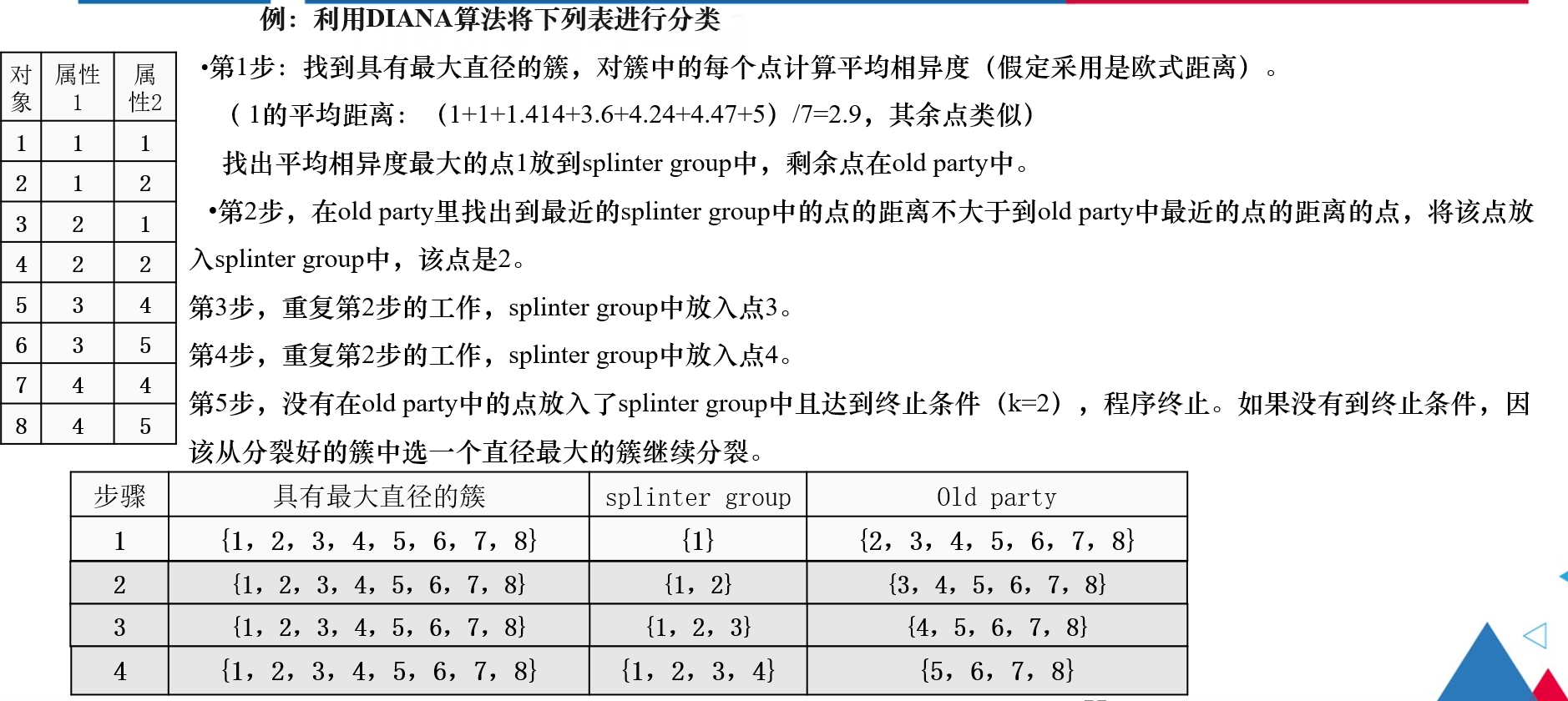
注解:
第一步:
找到具有最大直径的簇,对簇中各点计算平均相异度
平均相异度:
该点到簇中其余各点的欧式距离的平均值。
平均相异度越大,该点与簇中其余各点的相异度就越大。
第二步:
在oldparty中找出一点,使得该点到splintergroup中最近的点的距离不大于该点到oldparty中最近的点的距离。
始终保持是在具有最大簇直径的簇中,进行分裂操作。
5.4 基于密度的方法
DBSCAN
5.4.1 DBSCAN算法的相关概念


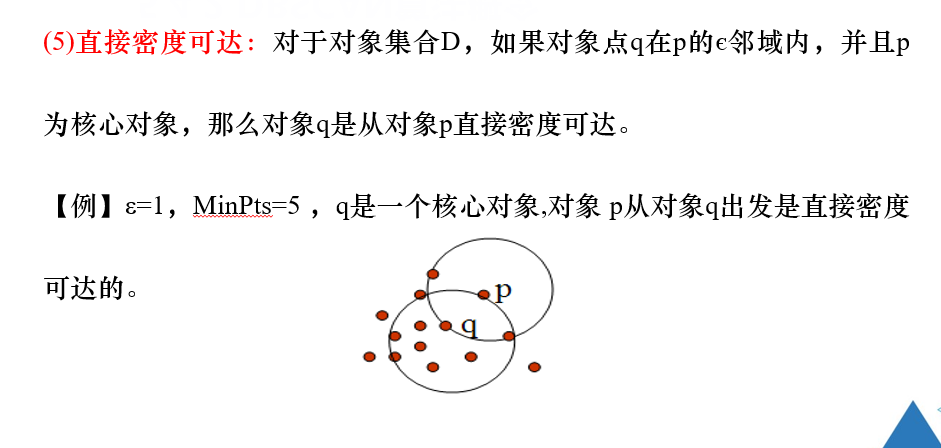
注解:
直接密度可达,是以核心点为参照的。
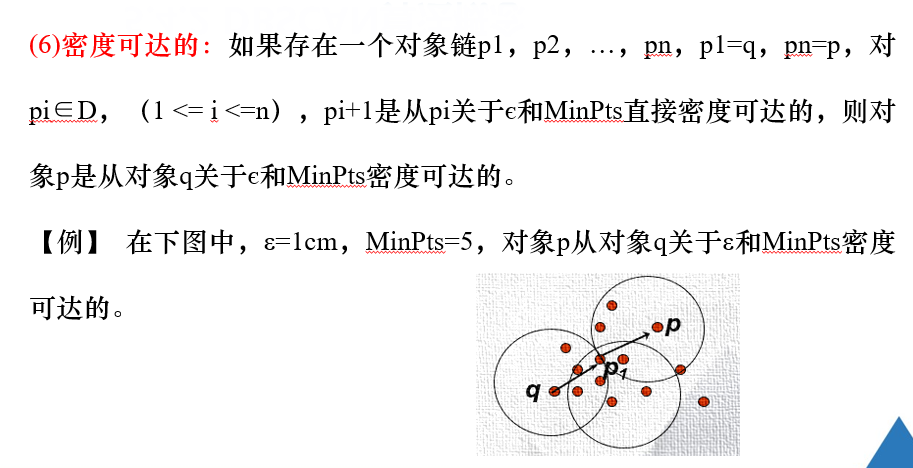
注解:
如图所示,p和q都是核心点,p1从对象p出发是直接密度可达的;p1从对象q出发是直接密度可达的,
则对象p从对象q出发是密度可达,
即密度可达是有若干个直接密度可达关联而成的。
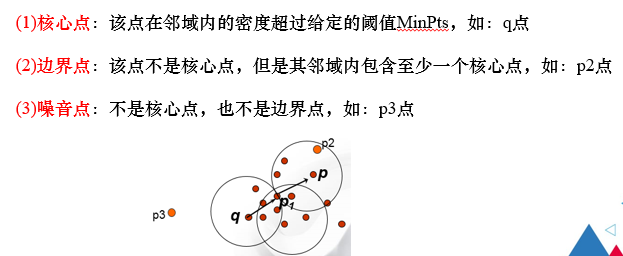
5.4.2 关于DBSCAN的几个定义
- 核心点
- 边界点
- 噪声点
5.4.3 DBSCAN的算法过程

例题
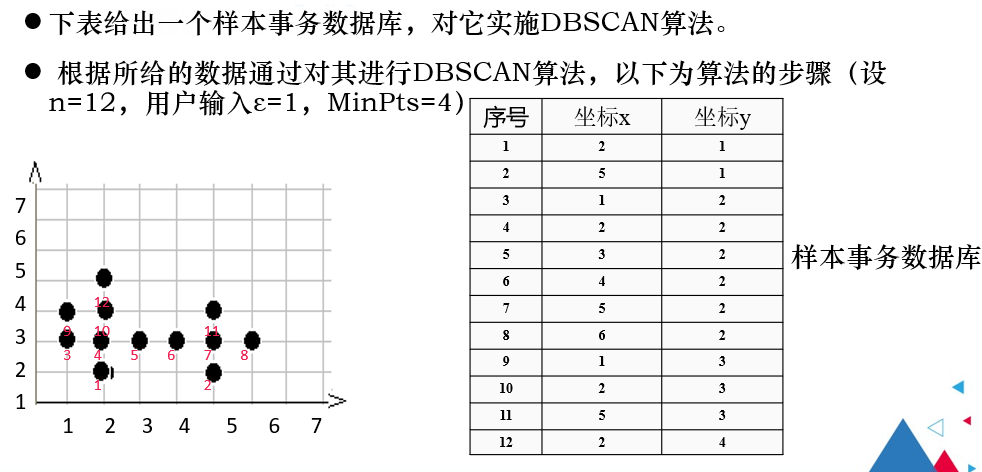
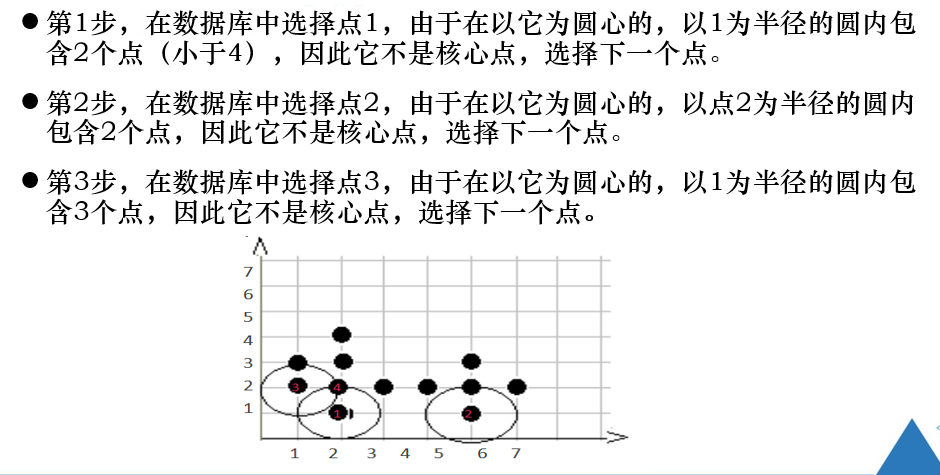
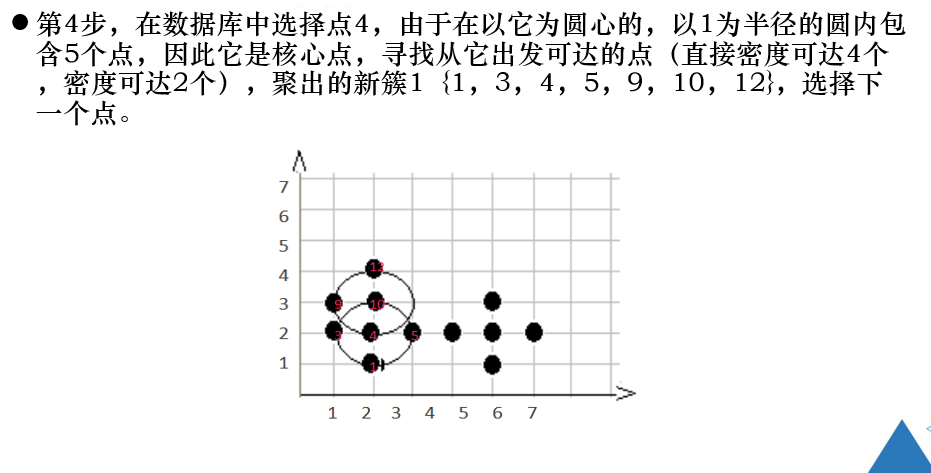
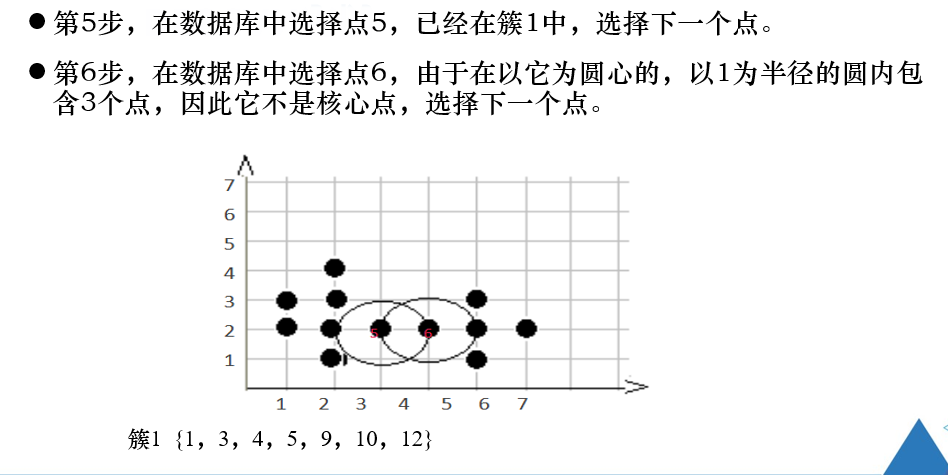
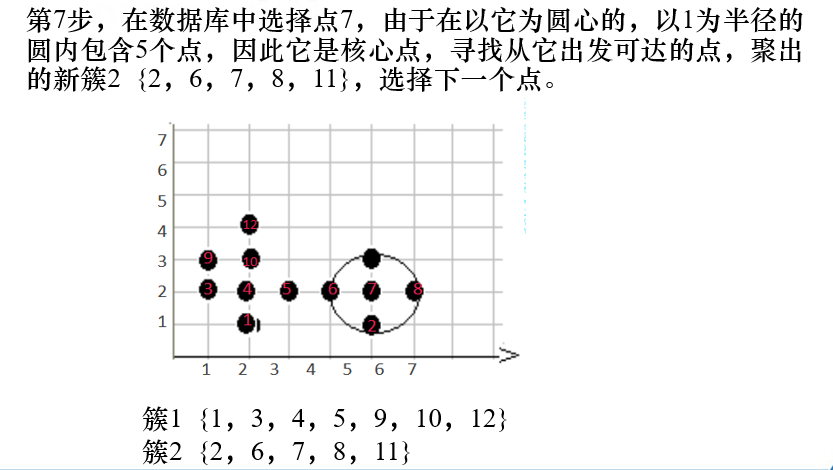
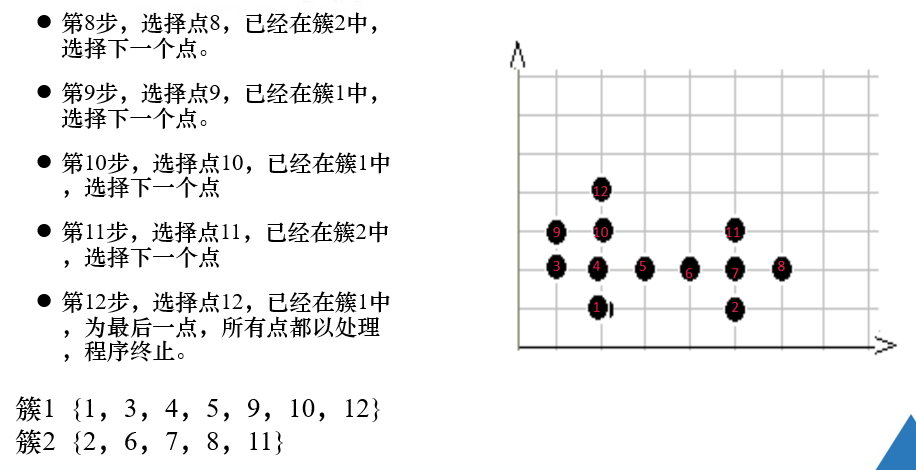
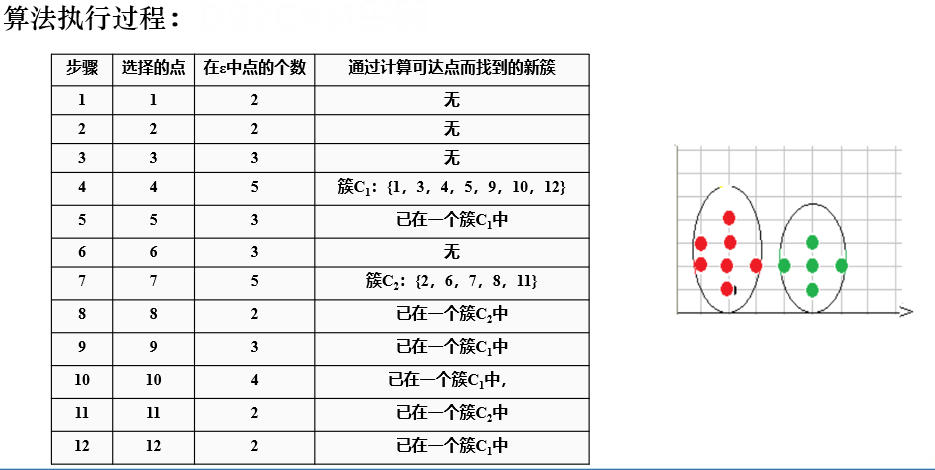
练习题
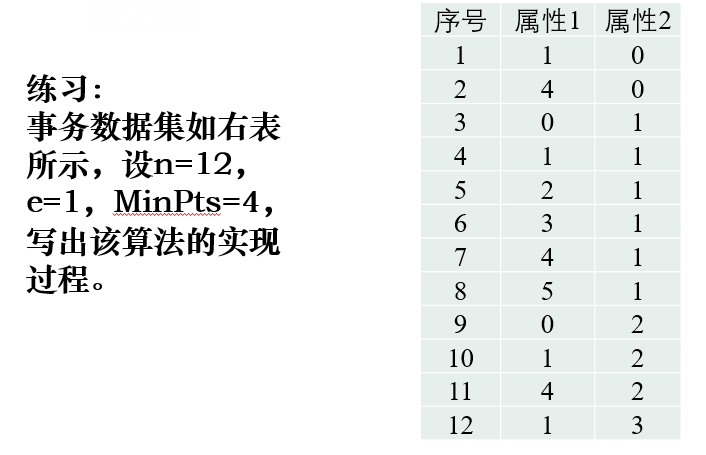
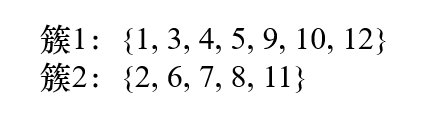
注意:
对象的领域中包含的样本点大于等于密度阈值,即为核心点。
是找密度可达的点。
5.5 轮廓系数


第6章 分类
常用的分类算法:
- 单一的分类算法:
- 决策树
- 贝叶斯
- K-近邻
- 人工神经网络
- 支持向量机
- 组合单一分类方法的集成学习算法 【不要求掌握】
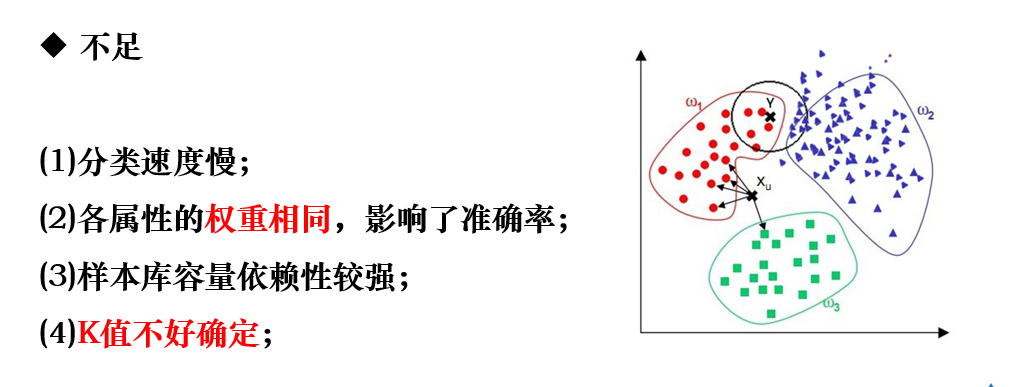
6.2 K近邻
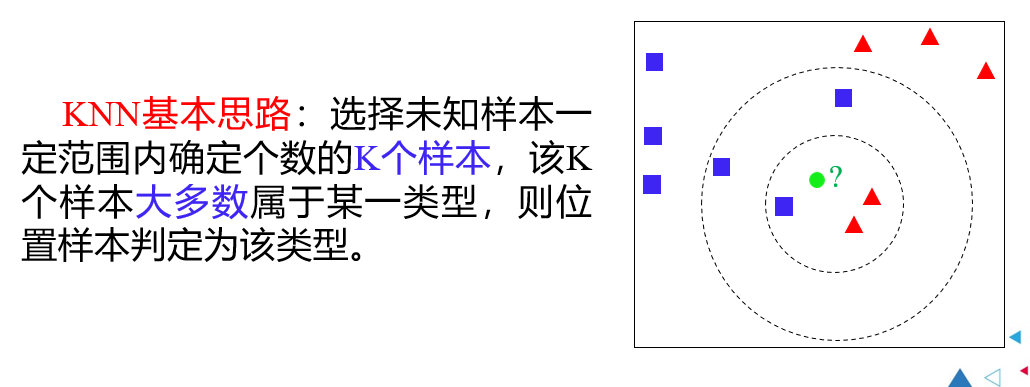
K近邻的优点、缺点:

6.3 贝叶斯分类
6.3.1 贝叶斯分类概述

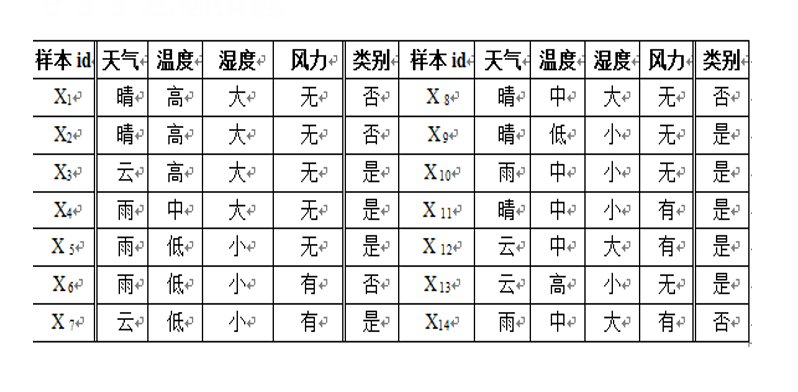
例题




6.4 决策树算法
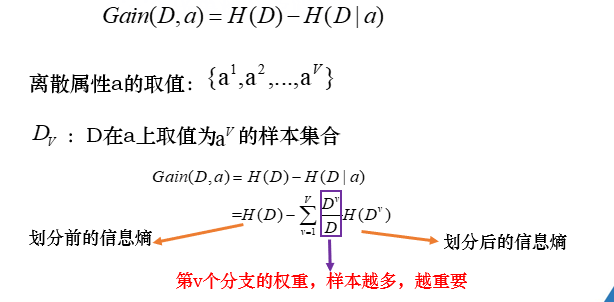
熵:随机变量不确定性的度量
熵越大,数据的不确定性越高;熵越小,数据的不确定性越低。
常用的算法:
- ID3
- C4.5
- CART
6.4.1 决策树分类原理---ID3
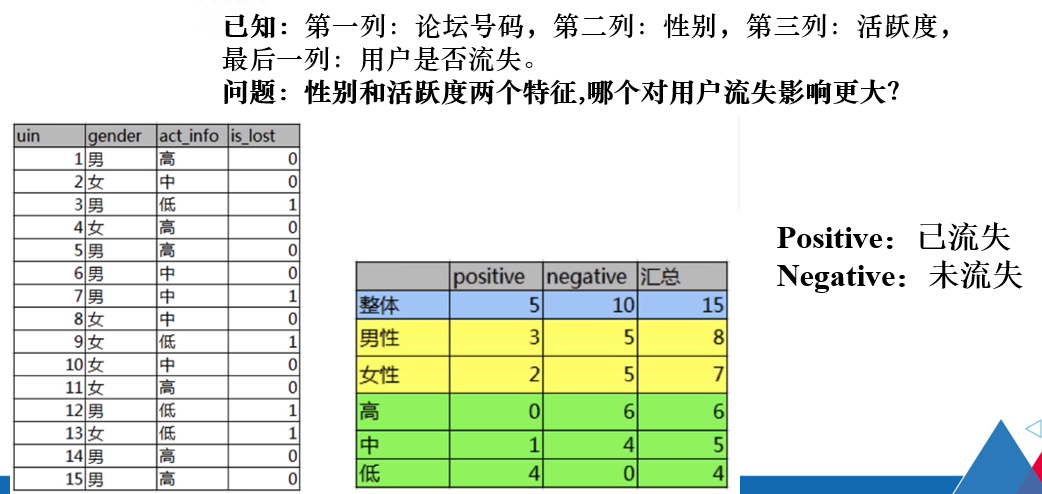
例题


6.4.2 决策树分类原理---C4.5


6.4.3 决策树分类原理---CART

例题
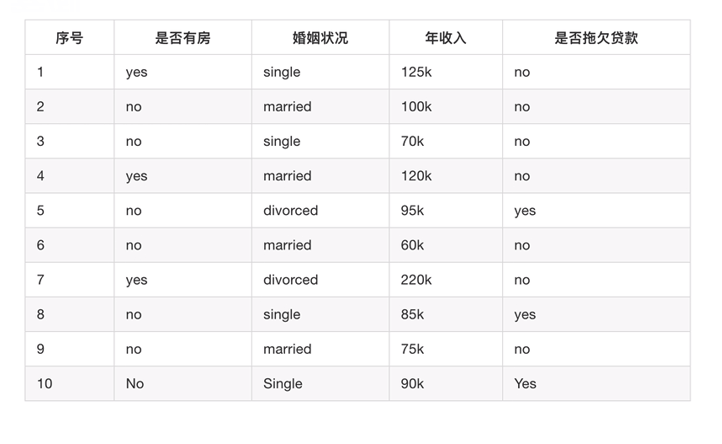


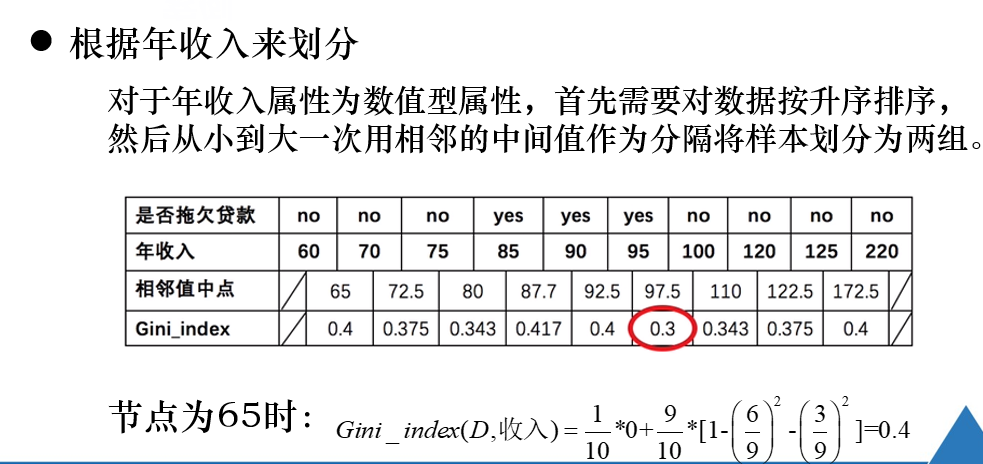
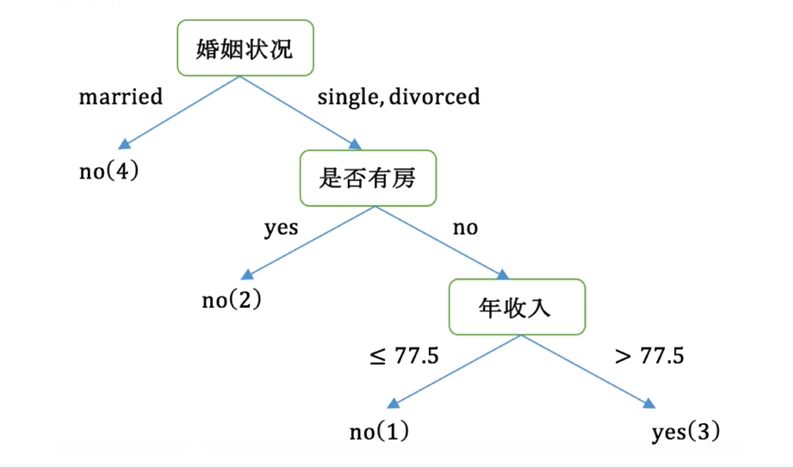
三种算法之间的比较:

6.5 评价指标
- 正确率
- 错误率
- 灵敏度
- 特效度
- 精度
- 召回率
- F-score

 浙公网安备 33010602011771号
浙公网安备 33010602011771号