1729 单词查找树 2000年NOI全国竞赛
1729 单词查找树
2000年NOI全国竞赛
时间限制: 2 s
空间限制: 128000 KB
题目等级 : 大师 Master
题目描述 Description
在进行文法分析的时候,通常需要检测一个单词是否在我们的单词列表里。为了提高查找和定位的速度,通常都要画出与单词列表所对应的单词查找树,其特点如下:
l 根节点不包含字母,除根节点外每一个节点都仅包含一个大写英文字母;
l 从根节点到某一节点,路径上经过的字母依次连起来所构成的字母序列,称为该节点对应的单词。单词列表中的每个词,都是该单词查找树某个节点所对应的单词;
l 在满足上述条件下,该单词查找树的节点数最少。
对一个确定的单词列表,请统计对应的单词查找树的节点数(包括根节点)
输入描述 Input Description
该文件为一个单词列表,每一行仅包含一个单词和一个换行/回车符。每个单词仅由大写的英文字符组成,长度不超过63个字符。文件总长度不超过32K,至少有一行数据。
输出描述 Output Description
该文件中仅包含一个整数和一个换行/回车符。该整数为单词列表对应的单词查找树的节点数。
样例输入 Sample Input
A
AN
ASP
AS
ASC
ASCII
BAS
BASIC
样例输出 Sample Output
13
数据范围及提示 Data Size & Hint
分析:
首先要对建树的过程有一个了解。对于当前被处理的单词和当前树:在根结点的子结点中找单词的第一位字母,若存在则进而在该结点的子结点中寻找第二位……如此下去直到单词结束,即不需要在该树中添加结点;或单词的第n位不能被找到,即将单词的第n位及其后的字母依次加入单词查找树中去。但,本问题只是问你结点总数,而非建树方案,且有32K文件,所以应该考虑能不能不通过建树就直接算出结点数?为了说明问题的本质,我们给出一个定义:一个单词相对于另一个单词的差:设单词1的长度为L,且与单词2从第N位开始不一致,则说单词1相对于单词2的差为L-N+1,这是描述单词相似程度的量。可见,将一个单词加入单词树的时候,须加入的结点数等于该单词树中已有单词的差的最小值。
单词的字典顺序排列后的序列则具有类似的特性,即在一个字典顺序序列中,第m个单词相对于第m-1个单词的差必定是它对于前m-1个单词的差中最小的。于是,得出建树的等效算法:
① 读入文件;
② 对单词列表进行字典顺序排序;
③ 依次计算每个单词对前一单词的差,并把差累加起来。注意:第 一个单词相对于“空”的差为该单词的长度;
④ 累加和再加上1(根结点),输出结果。
就给定的样例,按照这个算法求结点数的过程如下表:
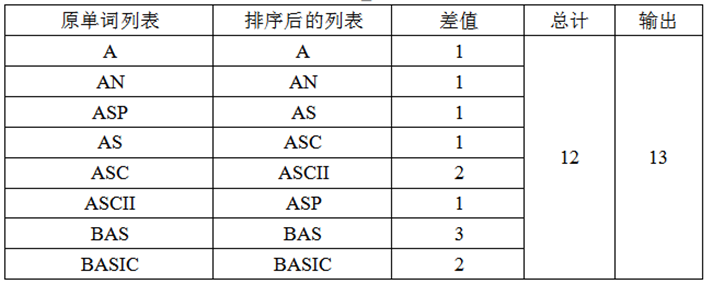
1 #include<iostream> 2 #include<algorithm> 3 #include<cstdio> 4 #include<cstring> 5 using namespace std; 6 string a[10001]; 7 int tot=1; 8 int main() 9 { 10 int n=1; 11 while(cin>>a[n]) 12 n++; 13 sort(a+1,a+n+1); 14 int l=a[1].length(); 15 for(int i=2;i<=n;i++) 16 { 17 int j=0; 18 while(a[i][j]==a[i-1][j]&&j<a[i].length()) 19 { 20 j++; 21 } 22 tot=tot+(a[i].length()-j); 23 } 24 cout<<tot; 25 return 0; 26 }
作者:自为风月马前卒
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

