量化投资学习笔记27——《Python机器学习应用》课程笔记01
北京理工大学在线课程:
http://www.icourse163.org/course/BIT-1001872001
机器学习分类
监督学习
无监督学习
半监督学习
强化学习
深度学习
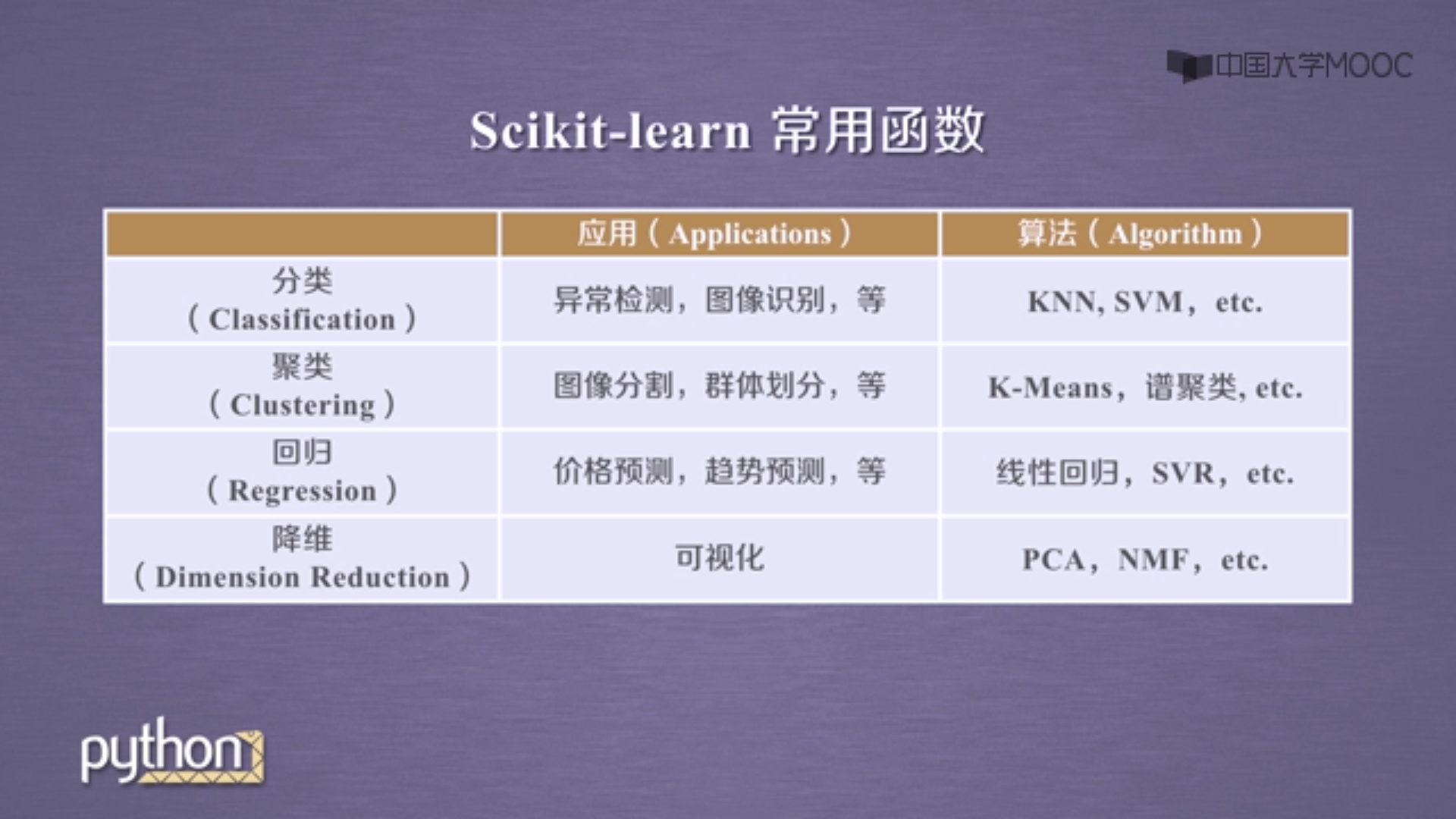
Scikit-learn算法分类
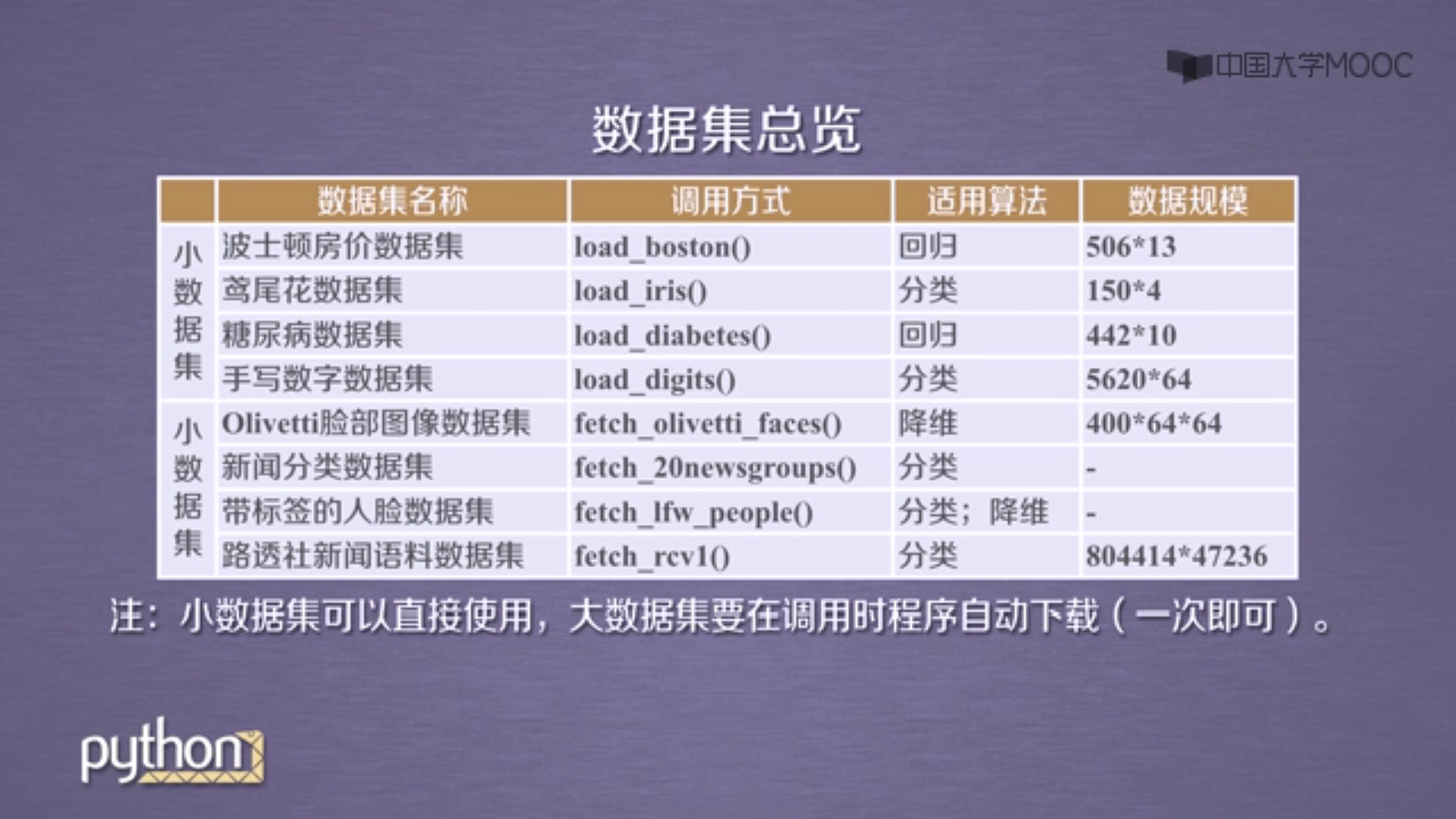
sklearn自带的标准数据集
sklearn的六大任务:分类、回归、聚类、降维、模型选择、数据预处理。
一、无监督学习:数据没有标签。最常用的是聚类和降维。
聚类:根据数据的相似性将数据分为多类的过程。使用样本的“距离”来估算样本的相似性,不同的距离计算方法有不同的分类结果。常用的距离计算方法有欧氏距离,曼哈顿距离,马氏距离,余弦相似度。
sklearn的聚类功能包含在sklearn.cluster中。同样的数据集应用不同的算法可能得到不同的结果,运行时间也不同。
其所接受的数据输入格式:
标准输入格式:[样本个数,特征个数]定义的矩阵形式。
相似矩阵形式输入:以[样本数目]定义的矩阵,矩阵中每个元素为样本相似度。
常用聚类算法

降维:在保证数据所具有的代表特性或分布的情况下,将高维数据转化为低维数据。
用于数据的可视化,或精简数据。
sklearn的降维算法包含在decomposition模块中,含有7种降维算法。主要有

1.聚类
①k-means算法及应用
以k为参数,把n个对象分为k个簇,使簇内具有较高的相似度,而簇间的相似度较低。
过程:
随机选择k个点作为初始的聚类中心。
对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇。
对每个簇,计算所有点的均值作为新的聚类中心。
重复前两步直到聚类中心不再发生改变。
实例:31省市居民收入分类。详见文章的github代码库。
拓展和改进:KMeans默认使用欧氏距离进行计算。如果要用其它距离计算方法,要修改源码。
②DBSCAN算法
是一种基于密度的聚类算法。聚类时不需要预先指定簇的个数。
将数据点分为三类:
核心点:在半径Eps内含有超过MinPts数目的点。
边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内。
噪音点:既不是核心点也不是边界点。
过程:
将所有点标记为核心点,边界点或噪音点。
删除噪声点
为距离在Eps之内的所有核心点之间赋予一条边。
每组连通的核心点形成一个簇。
将每个边界点指派到一个与之关联的核心点的簇中(哪一个核心点的半径范围之内)。
实例:学生上网时间分类。详见文章的github代码库。
技巧:长尾数据不适宜聚类,可以用对数转换。
本文代码:
https://github.com/zwdnet/MyQuant/tree/master/25
我发文章的四个地方,欢迎大家在朋友圈等地方分享,欢迎点“在看”。
我的个人博客地址:https://zwdnet.github.io
我的知乎文章地址: https://www.zhihu.com/people/zhao-you-min/posts
我的博客园博客地址: https://www.cnblogs.com/zwdnet/
我的微信个人订阅号:赵瑜敏的口腔医学学习园地

 浙公网安备 33010602011771号
浙公网安备 33010602011771号