
学习笔记——spark基础实验三
HDFS常用操作:
1.启动 Hadoop,在 HDFS 中创建用户目录“/user/hadoop”;
$cd /usr/local/hadoop $./sbin/start-dfs.sh #启动 HDFS $./bin/hdfs dfs -mkdir -p /user/hadoop #在 HDFS 中创建用户目录/user/hadoop

2. 在 Linux 系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件test.txt,并在该文件中随便输入一些内容,然后上传到 HDFS 的“/user/hadoop”目录下;
$cd /home/hadoop $vim test.txt #在 test.txt 中随便输入一些内容,并保存退出 vim 编辑器 $cd /usr/local/hadoop $./bin/hdfs dfs -put /home/hadoop/test.txt /user/hadoop

3.把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,下载到 Linux 系统的本地文件系统中的“/home/hadoop/下载”目录下;
$ cd /usr/local/hadoop
$./bin/hdfs dfs -get /user/hadoop/test.txt /home/hadoop/下载

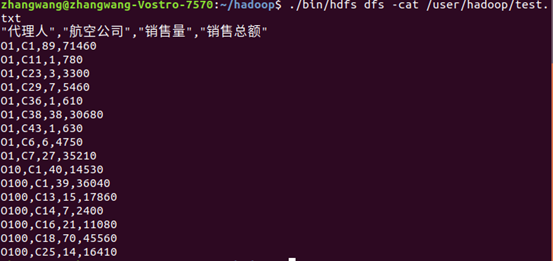
4.将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;
$ cd /usr/local/hadoop
$./bin/hdfs dfs -cat /user/hadoop/test.txt
5.在 HDFS 中的“/user/hadoop”目录下,创建子目录 input,把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,复制到“/user/hadoop/input”目录下;
$ cd /usr/local/hadoop $./bin/hdfs dfs -mkdir /user/hadoop/input $./bin/hdfs dfs -cp /user/hadoop/test.txt /user/hadoop/input

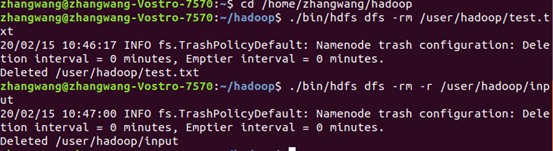
6. 删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop”目录下的 input 子目录及其子目录下的所有内容。
$ cd /usr/local/hadoop $./bin/hdfs dfs -rm /user/hadoop/test.txt $./bin/hdfs dfs -rm -r /user/hadoop/input
Spark读取文件系统的数据
1.在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
$ cd /usr/local/spark $./bin/spark-shell scala>val textFile=sc.textFile("file:///home/hadoop/test.txt") scala>textFile.count()

2.在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
scala>val textFile=sc.textFile("hdfs://localhost:9000/user/hadoop/test.txt")
scala>textFile.count()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号