



Hive (http://en.wikipedia.org/wiki/Apache_Hive )(非严格的原文顺序翻译)
Apache Hive是一个构建在Hadoop上的数据仓库框架,它提供数据的概要信息、查询和分析功能。最早是Facebook开发的,现在也被像Netflix这样的公司使用。Amazon维护了一个为自己定制的分支。
Hive提供了一个类SQL的语音--HiveQL,它将对关系数据库的模式操作转换为Hadoop的map/reduce、Apache Tez和Spark 执行引擎所支持的操作。以上的三种执行引擎都可以在YARN框架下运行。为了加速执行,它添加了indexes特性,包括bitmap indexes。
其他特性:
- 加速用的索引功能(有什么特别的?)
- 不同的存储类型文件,例如plain text, RCFile, HBase, ORC, and others.
- 元数据保存在关系数据库中,默认是(Apache Derbydatabase),可替换为Mysql等;
- 可对hadoop生态系统的压缩数据操作,支持多种算法:gzip, bzip2, snappy, etc.
- 内置UDF(自定义函数)
- 类SQL查询,是转换为Mapreduce执行的。
HiveQL不完全兼容SQL-92标准:
1)它额外支持多行插入功能和通过select创建表功能;
2)仅支持基本的索引功能;
3)不支持事务和物化视图功能;
4) 仅支持有限的子查询功能
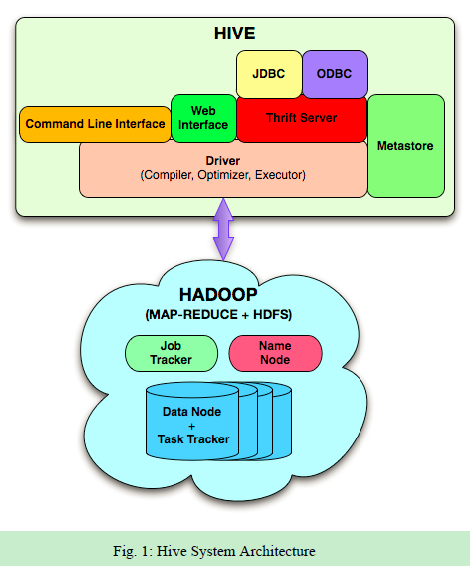
在Hive内部,HiveQL语句通过编译器转换为DAG(有向无环图)关系的mapReduce,然后提交给hadoop执行;
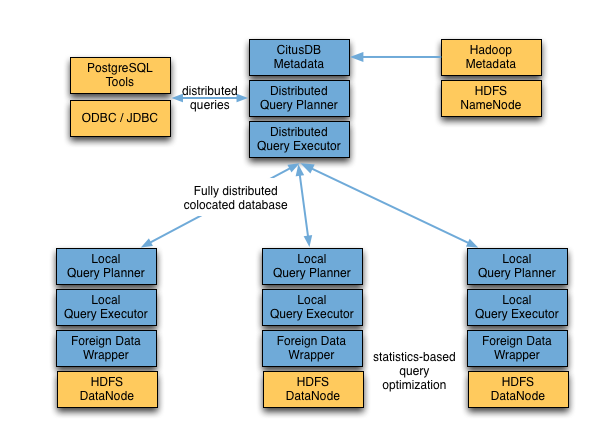
Shark是一个为spark设计的大规模数据仓库系统,它与Hive兼容。。。balabala
Shark将停止开发,而Spark SQL将取代并兼容Shark 0.9的所有功能,并提供额外的功能。
Hive的缺点:
- 性能不佳;
- 为了执行交互查询,需要部署昂贵且私有的数据仓库,且这些数据仓库(EDWs )需要严格而冗长的ETL处理。
Hive与EDWs的显著性能差异导致了业界怀疑通用数据处理引擎在查询处理上有与生俱来的缺陷。许多人相信交互性SQL需要昂贵的专业查询系统(相对于通用数据引擎。)(如EDWs)。Shark是其中一个最早建立在Hadoop系统上的交互式SQL工具,且是唯一一个建立在spark上的。Shark证明Hive的缺陷不是固有的,像spark这样的通用数据引擎能同时做到:像EDW那样快,像Hive/MapReduce那样大规模。
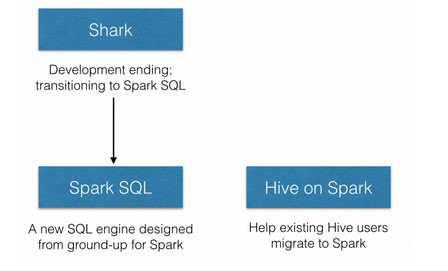
从Shark 到 Spark SQL
Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来(by swapping out the physical execution engine part of Hive)。这个方法使得Shark的用户可以加速Hive的查询,但是Shark继承了Hive的大且复杂的代码基线使得Shark很难优化和维护。随着我们遇到了性能优化的上限,以及集成SQL的一些复杂的分析功能,我们发现Hive那位MapReduce设计的框架限制了Shark的发展。
基于上述的理由我们停止Shark这个独立项目的开发,而转向spark SQL。Spark SQL是作为spark一个组件,充分利用spark的有事从头开始设计的。这种新的设计使我们数据更快,且最终交付给用户一个体验更好且更强大的工具。
对于SQL用户,spark SQL提供很好的性能并且与Shark、Hive兼容。(性能提高一个数量级)。
对spark用户,spark SQL提供了对结构化数据的简便( narrow-waist)操作。那是真正的为高级的数据分析统一了SQL(结构化查询语言)与命令式语言的混合使用。
对开源的高手来说,Spark SQL提供了新颖而优雅的构建查询计划的方法。人们可以很容易添加新的优化到这个框架内。我们也被开源贡献者的热情所感动。。。balabala
Hive on Spark Project (HIVE-7292)
说大家都希望Hive尽快支持Hive on spark功能。。以及未来多么美好。。balabala

