网络流
建设中......
attention: 网络流通常是建模难,只要建出来了基本上就是板子......
一、最大流
网络流的基本问题:给出一个源点 \(S\) 和汇点 \(T\) ,中间还有若干点,点与点间有一些管道连接,这些管道的流量有上限,现在要求 \(S\) 到 \(T\) 的最大流量
显然我们有一种贪心的想法,让能流的都流过去
于是我们可以每次都找一条可行的路径,将流量 \(L\) 统计到答案后,将路径上的管道的流量都减去 \(L\),这种操作我们称之为增广,一条合法的路径叫做增广路,如下图:
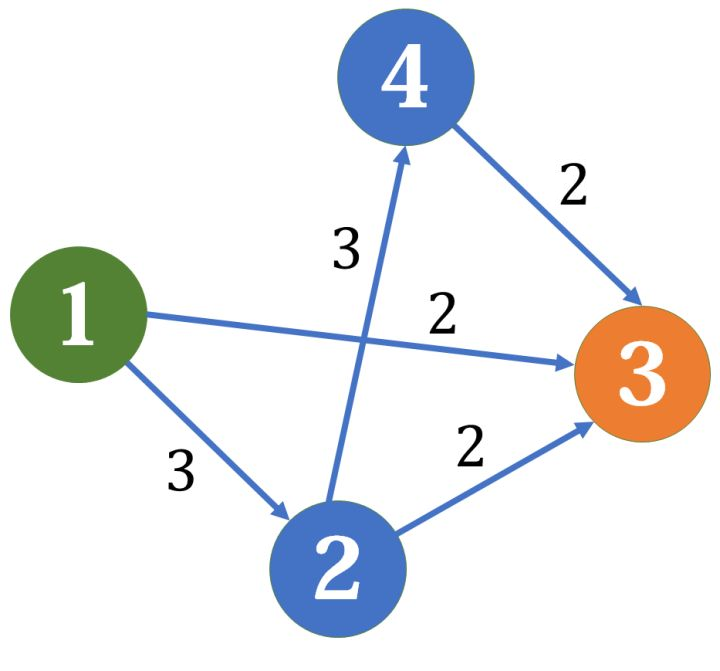
(\(1\) 为源点,\(3\) 为汇点)
我们找到 \(1-4-3\) ,答案计入 \(2\),再找到 \(1-3\),答案计入 \(2\),最后找到 \(1-2-3\),答案计入 \(1\),最大流就是 \(5\)
这个思想大体是正确的,但真的所有情况都是对的吗?
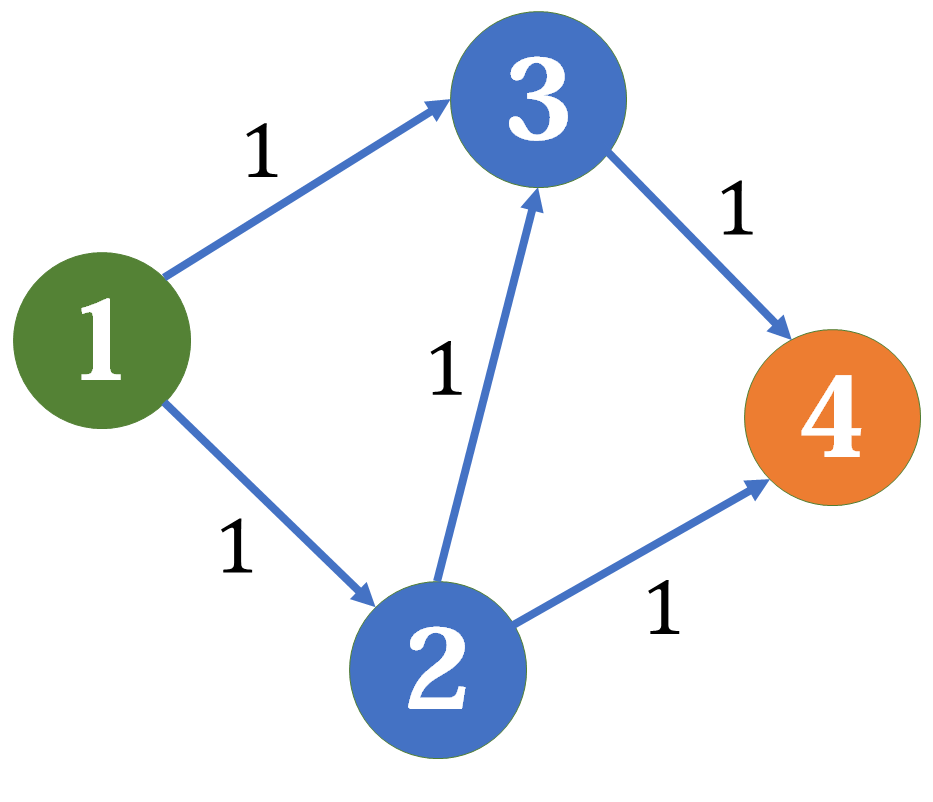
对于这种情况,如果我们先找到的是 \(1-2-3-4\) ,就会导致无法在继续增广
于是我们考虑加入反向边,当某个管道流量减去 \(L\) 时,它对应的反向边就加上 \(L\)
然后我们再看看这个例子,加入反向边后:
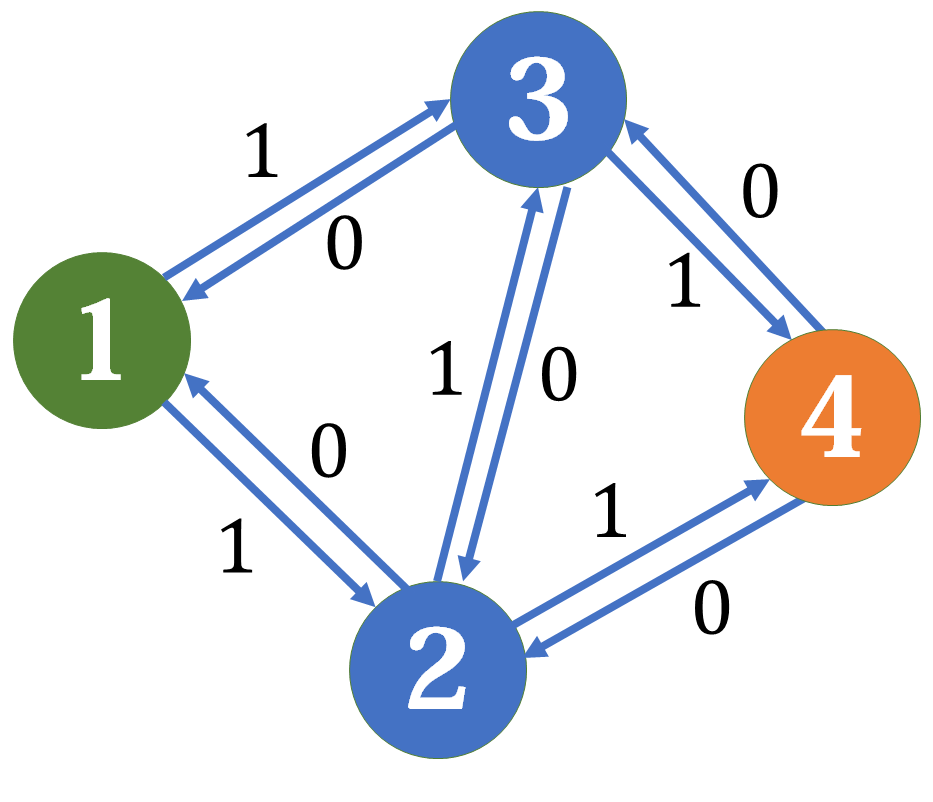
还是增广 \(1-2-3-4\)
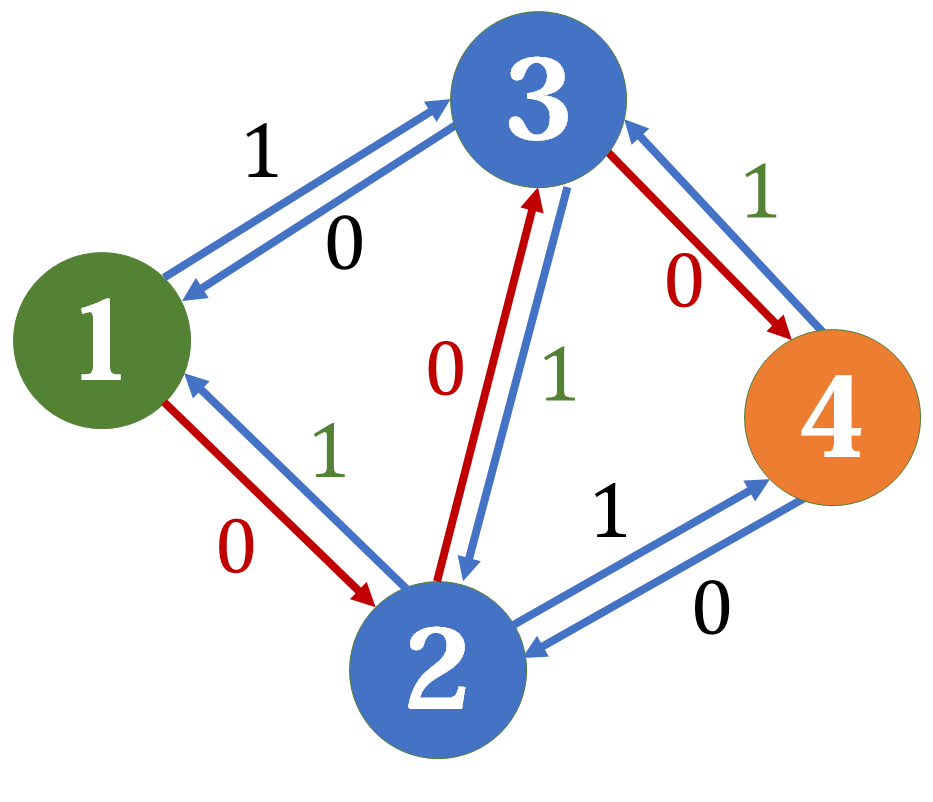
显然还可以找到 \(1-3-2-4\),于是就可以得到正确答案了
其实我们可以理解反向边是一个撤销的操作,这样就保证了我们可以找到一个最优的策略
根据这个思想,我们可以获得实现方式为 dfs ,时间为 \(O(ef)\) 的 FF 算法(\(e\) 表示边数, \(f\) 表示最大流)
当然,dfs 中我们可能会绕远路,而且会有许多不必要的操作,于是我们考虑将其替换成 bfs,这样我们就能获得时间为 \(O(ve^2)\) 的 EK 算法(其中 \(v\) 为点数),这样我们就至少不会被最大流限制我们的发挥了......
1. Dinic
但显然这些都是不够的,我们必须找到一个更为优秀的算法,于是 Dinic 横空出世!
它的主要思想:
每次从源点出发前,先用 bfs 将点分层(按 bfs 序),在 dfs 的增广过程中,我们只向层数比当前点高 \(1\) 的点进行增广
这其实是对上面两个算法的优化,这保证了我们 dfs 的过程中不会绕远路
同时我们进行多路增广,就是在某点找到一条增广路后,如果还剩下多余的流量未用,继续从该点 dfs 尝试找到更多增广路
时间是 \(O(v^2e)\)
一些 Dinic 的细节:
-
bfs编号的过程中,如果一条边 \((u,v)\) 流量已为 \(0\) ,那么 \(v\) 就不从 \(u\) 来编号
-
dfs中,如果流量 \(in\) 已经流完了,马上退出循环(因为后面的点可能还不少,一个个遍历会导致复杂度不正确)
-
dfs中,如果当前点的流出量为 \(0\) 那么将这个点的编号变成 \(0\) ,提醒其他点不要到这里来(因为这个点已经和 \(T\) 断开了)
2. ISAP
虽然说 Dinic 可以解决 99% 的最大流问题,但仍然不够啊 (吃饱了闲着的毒瘤出题人没事卡 Dinic 干嘛)
如果说能将 Dinic 每次的 bfs 分层给去掉就好了......
诶,ISAP 就能满足这个需求!
它的步骤如下:
-
- 先从 \(T\) 到 \(S\) 跑一遍
bfs(也就是倒着跑),并编号
- 先从 \(T\) 到 \(S\) 跑一遍
-
- 对于
dfs时的当前点,如果上一个点传来的流量 \(in\) 大于当前点流出去的流量 \(out\) ,说明这个点后面都走不动了,那么我们就将这个点的层数 +1
- 对于
-
- 如果起点 \(S\) 的层数大于了 \(n\) ,那么结束程序(这就是
bfs倒过来做的原因)
- 如果起点 \(S\) 的层数大于了 \(n\) ,那么结束程序(这就是
操作2成功让我们在 dfs 时改好层数,就不需要每次都跑一次 bfs 了
当然这还有不少的优化:
1. GAP优化
如果有某个层数没有一个点(也就是断层),显然网络是不连通的
2. 当前弧优化
其实这在 Dinic 同样适用
我们用一个数组 \(cur\) 记录当前遍历的边(弧)
在同一次增广中,显然我们是将遍历到的边增广完的,那么下次访问这个点时,我们就没必要在增广这条边了,于是可以直接访问下一条边,节省不少时间
3. 非递归写法
确实会优化到,但我觉得没必要 \(\color{White} 其实是因为懒\)
3. HLPP
声明:考场中 Dinic 或 ISAP 已经够用了,下面讲到的预留推进算法以及基于这个算法的 HLPP 只做扩展,实际中也没人会卡 ISAP,除非他是**出模板题
先放个大佬写的 HLPP (我感觉我写得不好)
先将一下基础:预留推进
我们先抛开增广,如果单纯贪心,我们会怎么做?
那肯定是给源点疯狂灌水,让水不断向相邻的点流去,最后统计 \(T\) 有多少的流量
这就是预留推进的核心思想
在这我们先给出 余流 的概念:当前点储存着(能流出)的流量大小
一个简单的实现过程就是:先从 \(S\) 向相邻点推流(推流的大小为边的最大流量),然后让周围点进入队列,注意 \(S\) 和 \(T\) 不可入队
每次取队首元素向周边元素推流,当队列为空时停止
但是,因为反向边的存在,会导致两个点来回推流,根本停不下来!
所以,我们考虑给点一个高度(注意:\(S\) 的高度始终为 \(n\)),水只从高处往低处流,如果一个点有余流却流不出去,我们就将当前点的高度更新为相邻点的最小高度+1,直到当前点没有余流就不加入队列
这为什么就不会来回推流了?因为如果有两个点会来回推流,他们的高度会不断升高,直到高于 \(S\) 后水就流回源点
但这似乎比 EK 还要慢
于是 最高标号预流推进(HLPP) 就此诞生!
我们仿照 ISAP,开始时从 \(T\) 到 \(S\) 跑 bfs,使每个点开始就有一个初始高度(对应 bfn)(注意,\(S\) 高度始终为 \(n\) ! ! !)
这样,我们就规定流向为 \(H[u]\) 流向 \(H[u]-1\)
同时,许多计算机科学家发现从队列中高度最高的点开始推流,时间复杂度会降不少(最高标号的名字也是这样来的),你可以感性理解一下:先将高处的点的水推流到低处,那么低处的节点推流时可以顺便将其带走
于是我们就考虑将上面的队列换成优先队列
但实际上,我们可以直接用链表等(如 vector, list)来做,在每个下标存储对应高度的已入队的点,这就又省去一个 \(O(logn)\) 了
同时,我们还有 GAP 优化
但这次的断层不是直接退出程序,因为断层了不代表没有余流了,但显然高处的点的余流无法再次流向 \(T\) ,所以我们将高处的点改成 \(n+1\) ,尽快将余流流回 \(S\)
(而在实际代码中,我们 \(n+1\) 都是直接从队列中移除,不进行回流的操作)
于是我们就可以做到 \(O(n^2\sqrt m)\)
将 HLPP 过程再归纳一下:
-
- 先跑
bfs,更新初始高度
- 先跑
-
- 从源点向相邻点推流,流量为边的最大流量
-
- 找到最高的一个点 \(u\),进行推流,推流时对于被推流的点 \(v\) ,如果 \(v\) 开始的余流为 0,则让 \(v\) 入队,并用 \(ht[v]\) 更新 \(maxh\)
-
- 如果 \(u\) 还有余流,我们就先让 \(ht[u]\) 的 \(gap\) 减一,同时如果 \(gap[ht[u]]\) 为 0,则将所有 \(ht[v]>ht[u]\) 的点 \(v\) 高度改为 \(n+1\);然后我们对 \(u\) 重贴标签(更新高度),取所有相邻的且边的流量不为 0的点的高度的最小值 +1,注意这时 \(u\) 的新高度也要更新 \(maxh\)
二、最小割
给定义:
有源汇割:一个边集,删去之后使得源汇不连通,而且其中任意一条边不割,则造成源汇连通(割是紧的)
有源汇最小割:割去的边的边权和最小的有源汇割
抛定理:
证明:
-
- 最大流 $\le $ 最小割
根据定义,所有的流一定会流过割集中的边,所以一个可行的割一定得至少将流上最小的边权割掉
-
- 最大流 $\ge $ 最小割
对于残量网络上流量为 0 的边(即满流边),这些边一定可以组成一个割,否则就会存在增广路
证毕
最小割的例题
- 最小割的可行边 \((u,v)\) :
- 残量网络中,\((u,v)\) 为满流边
如果不是满流边,那显然可以用这条边经过的流中的满流边来代替,代价更小
- 残量网络中,\(u\) 无法到达 \(v\)
如果可以到达,那割了也没意义了,流可以不经过你这个满流边,改道而行
- 最小割的必须边 \((u,v)\) :
-
首先,它得是可行边
-
残量网络中,\(S\) 可到达 \(u\),\(v\) 可到达 \(T\)
这代表这条边经过的流上只有 \((u,v)\) 是满流边,你不割它代价一定增大
说了这么多,怎么判断 \(m\) 条边是不是可行边或必须边?
我们跑完最大流后,用所有流量不为 0 边(包括反向边!)跑一遍 tarjan (缩点)
- 如果 \(u\) 和 \(v\) 不在一个强连通分量说明是可行边
因为 \((u,v)\) 满流,所以其反向边 \((v,u)\) 一定可以通行,那么这时如果有 \(u\) 到 \(v\) 的路径,那么 \(u,v\) 就会形成一个环,就会在同一个强联通内
- 如果 \(u\) 和 \(S\) 在同一个强连通,\(v\) 和 \(t\) 在一个强连通,说明是必须边
证明大概同上,自行思考
三、费用流:
声明:一般考场上 EK 费用流已经够用了,其他费用流算法仅做扩展!
费用流就是给每条边加上一个费用,要求在求出最大流的基础上,求出最小的费用
1. EK 费用流
一种算法就是将 EK 的 bfs 改为 最短路,如 SPFA 它又复活了
我们每次增广考虑 \(s\) 到 \(t\) 的距离最短
记录费用转移的边和上一个点,SPFA 跑完后就直接计入答案
复杂度是伪多项式级别的,但很有可能被卡成指数级别
2. 原始对偶费用流
我们在 EK 中使用 SPFA 的复杂度是 \(O(nm)\) 的
当我们边数达到 \(n^2\) 时,SPFA 就很慢很慢
如果我们可以用优先队列优化的 dij 代替 SPFA 就能降到 \(O(mlogm)\),只是可惜,负权的存在让我们望而却步
但参考一下 Johnson全源最短路,似乎有迹可循
我们仿照 Johnson ,开始时从 \(s\) 跑 SPFA ,得到一个势能数组 \(h\)
但我们每次增广后,会出现新的反向边啊,它们的边权该如何重新设置?
先抛方法:每次增广完一条路径后,所有 \(h[u]\) 都加上 \(dis'[u]\) ,这里的 \(dis'\) 指重新设置边权后跑出来的最短路
我们要证明的就是更新后,\(r[u,v]+h[u]-h[v]\) 仍然非负:
-
对于新加入的反向边,因为一定存在 \(dis'[u]+(r[u,v]+h[u]-h[v])=dis'[v]\)(否则就不会增广 \((u,v)\) 边了),所以有 \(r[v,u]+(h[v]+dis'[v])-(h[u]+dis'[u])=0\),因此新加入的反向边非负
-
对于原有的边,因为有 \(dis'[u]+(r[u,v]+h[u]-h[v])\ge dis'[v]\),所以 \(r[u,v]+(dis'[u]+h[u])-(dis'[v]+h[v])\ge 0\),因此还是非负
显然,dij 的优势大多体现在稠密图上,而对于大部分的费用流的题目,EK+SPFA 已经足够了
(从评测记录可以看出,模板题的图较为稠密,原始对偶比 EK-SPFA 快了不止一半)
3. 有负环的费用流
注:这里的可行流只需满足容量限制与流量平衡,也就是说环内的流量不一定要流到汇点!通俗地说,就是环里面直接可以循环流动,但不计入最终的最大流流量中,只计入费用中
下面仅代表个人理解,不一定保证理解正确(但算法应该是没问题的)
首先,我们让费用为负的边强行满流,就是在加边的时候,将原始边的流量设为 \(0\),反向边的流量为 \(w\) ,同时将 \(w\times v\) 加入费用(其中 \(w\) 表示流量,\(v\) 表示费用)
这一举动的目的是直接将负环的所有边转正,并将负环的费用直接计入答案
但显然,我们在加边时直接计算负边的费用,不仅可能将不在负环内的负边算进去了,还有环的流量应该是取环内所有边的最小值,而这个操作可能算多了
于是在加边遇到负边强行满流的同时,还要记录各个点的流量情况
对于结点流量为正的,我们将它连接到虚拟源点;为负的,我们将它连接到虚拟汇点
然后用虚拟源汇点跑一遍费用流,这样的目的就是解决上面说的问题
最后直接正常从真正的源汇点跑费用流即可
四、二分图模型:
图的前置芝士:
-
图的匹配:选出某些边,使得任意两条边没有公共端点。
-
图的独立集:选出某些点,使得任意两个点之间没有连边。
-
图的点覆盖:选出某些点,每条边都至少有一个端点被选择。
-
闭合子图:在一个有向图的子图中,满足任意点的边都仍指向子图内的点
-
图的路径覆盖:在
DAG上用(边)不相交的简单路径覆盖所有的节点。
二分图的前置芝士:
-
定义:分为两个部分的图(称为左部和右部),同一个部分内没有边。
-
判定:充要条件:没有奇环,
dfs染色判定即可。
1. 二分图最大匹配:
此处不讲 匈牙利算法
一个显然的想法,将左部的点连接一个超级源点,右部的点连接一个超级汇点
所有边的流量都为 \(1\) ,跑一遍 Dinic 即可
如果是最大权匹配,则跑最大费用最大流
2. 二分图最小点覆盖:
抛定理:
证明:
首先,根据最大匹配的定义,因为匹配的 \(e\) 条边是相互独立的,那么至少要选择边两端的其中一个点,也就是一共至少 \(e\) 个点
其次,我们称未被匹配边连接的点为空点,对于有被匹配边相连的点,如果有一条边另一端是空点,我们称这个点为必选点
显然,一条匹配边不可能出现两个必选点,否则我们在求最大匹配时可以将这条匹配边替换成这两条有空点的边
(建议自己画几个图理解一下)
另一种证明方法:
因为在最大匹配中,我们建立的最大流模型中间边的流量是无限的,说明我们要求最小割的话只能割与源汇点相连的边;显然一个最小割就是对应着一个最小点覆盖
如果是最小点权覆盖:源点 \(S\) 向左点集每一点连边,容量为点权值;右点集每一点向汇点 \(T\) 连边,容量为点权值。内部边,容量为无穷大。
然后跑最大流求最小割。
3. 二分图最大独立集:
又抛定理:
(也就是最小点覆盖的补集)
证明:
-
独立:如果有不独立的点,显然与点覆盖的定义相违背,因为有一条边连着两个点,必然有一个点要在点覆盖里面
-
最大:如果还有更大,显然要拆掉点覆盖的一部分,这又与最小相违背
也就是说,最大独立集和最小点覆盖是对偶问题。这对一般图也是成立的。
如果是最大点权独立集,类似最小点权覆盖,\(最大点权独立集权值 = 总点权 - 最小点权覆盖权值\)
4. 最大权闭合子图
还抛定理:
这里的最小割构造方式为:
-
正权点与源点连边,边权为点权;
-
负权点与汇点连边,边权为点权的绝对值;
-
原来的边边权设为 INF。
证明的话一张图可以解释完:
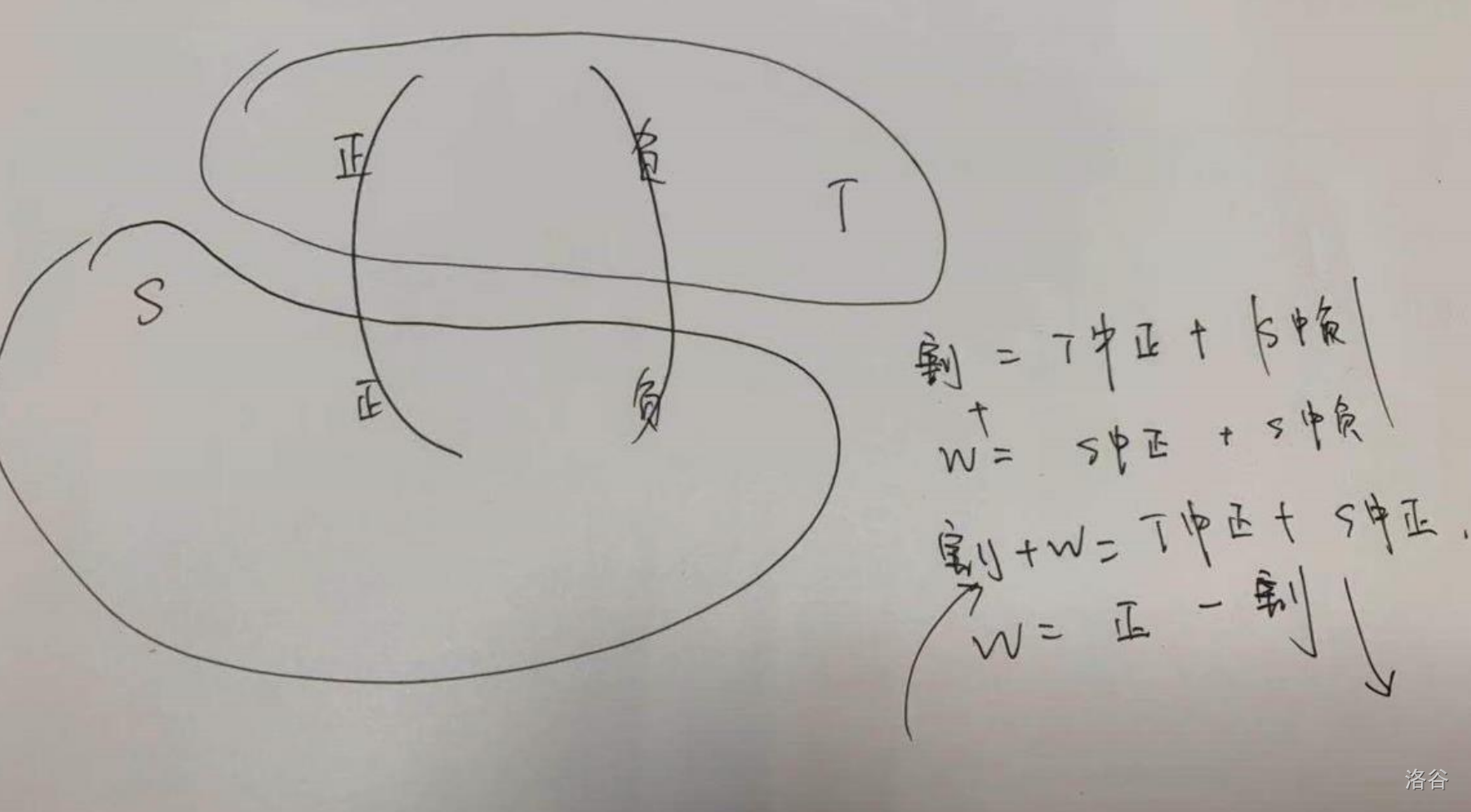
5. 最小路径覆盖
刚开始,我们把每个点都看做一个路径
当我们将两个点连接在一起时,路径数显然会减一
因为要路径无交,我们考虑将点拆成“入点”和“出点”
对于原图上的边 \((u,v)\),我们将 \(u\) 的入点指向 \(v\) 的出点
将两个点连接,就是在这个二分图上选择一条边;而要求“无交”刚好就是对应匹配问题
于是我们跑一次二分图最大匹配,记答案为 \(mx\),那么最小路径覆盖就是:点数 \(-~mx\)
6. 最大密度子图
- 给定一个无向图,要求选择一个点集,使得其导出子图的“边数与点数之比”最大。
我们令 \(e\) 表示边数,\(p\) 表示点数,题目即要求 \(\frac{e}{p}\) 最大。
考虑分数规划,二分答案 \(k\)。我们考虑构建一个二分图,左边的点表示原图上的边,权值为 1;右边的点表示原图上的点,权值为 \(-k\)。
我们将左侧结点与原边的两个端点对应的右侧结点连边,然后跑一次最大权闭合子图,判断其符号(\(<0\) 或 \(>0\))即可。

