爬取 院士名单以及简介
爬取 院士名单以及简介
续作 人才及研究方向信息爬取爬虫 - 英飞 - 博客园 (cnblogs.com)
需求与思路
需求 : 爬取经济管理相关国家级人才
思路:
1 从title出发,比如中国科学院网站 查看不同学部中院士的介绍
具体步骤
1 中国工程院院士 和 中国科学院院士 官网
2 打开中国工程院院士 工程管理学部 名单
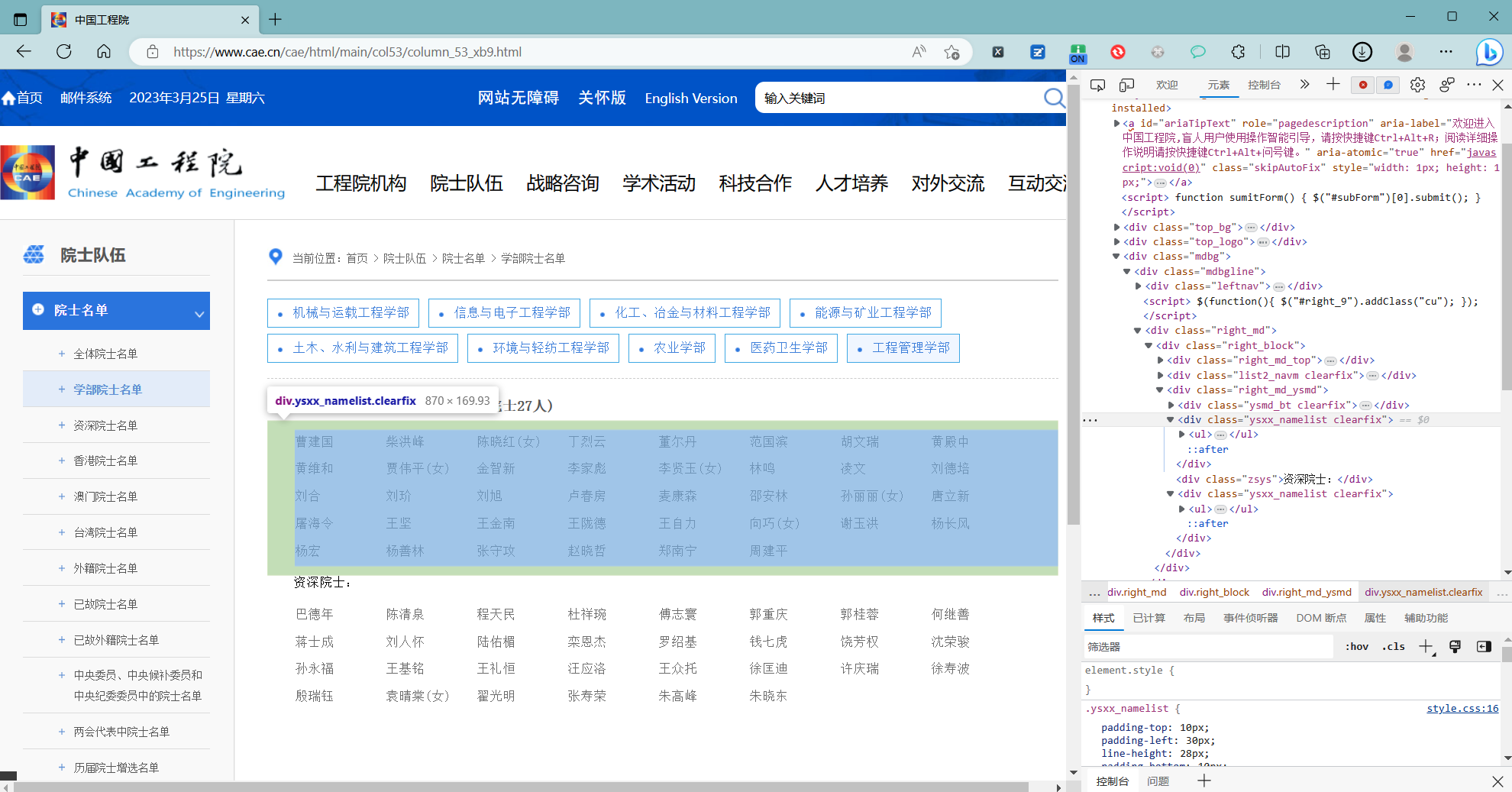
定位对应元素
body > div.mdbg > div > div.right_md > div > div.right_md_ysmd > div:nth-child(2)
3 点击跳转
姓名
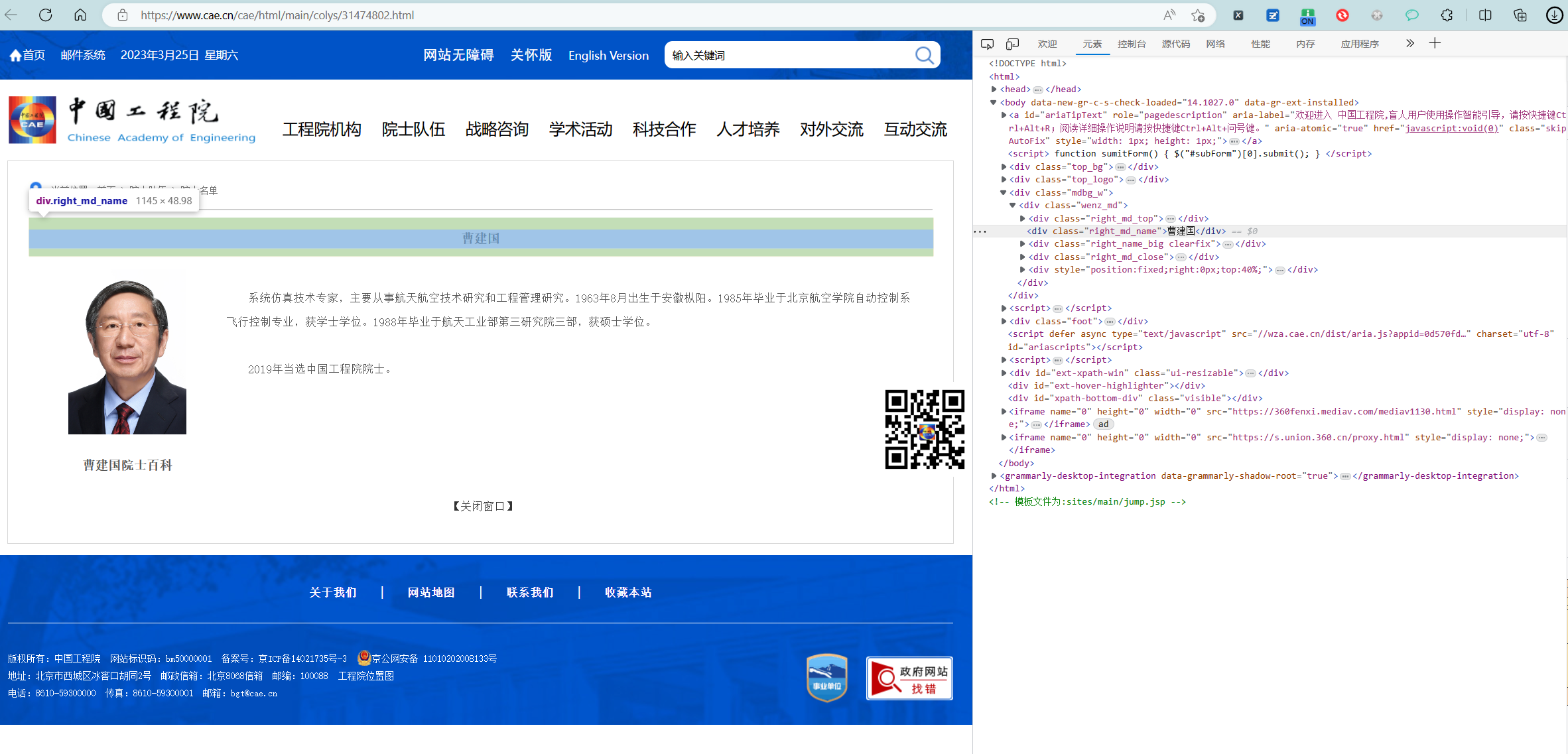
body > div.mdbg_w > div > div.right_md_name
个人介绍
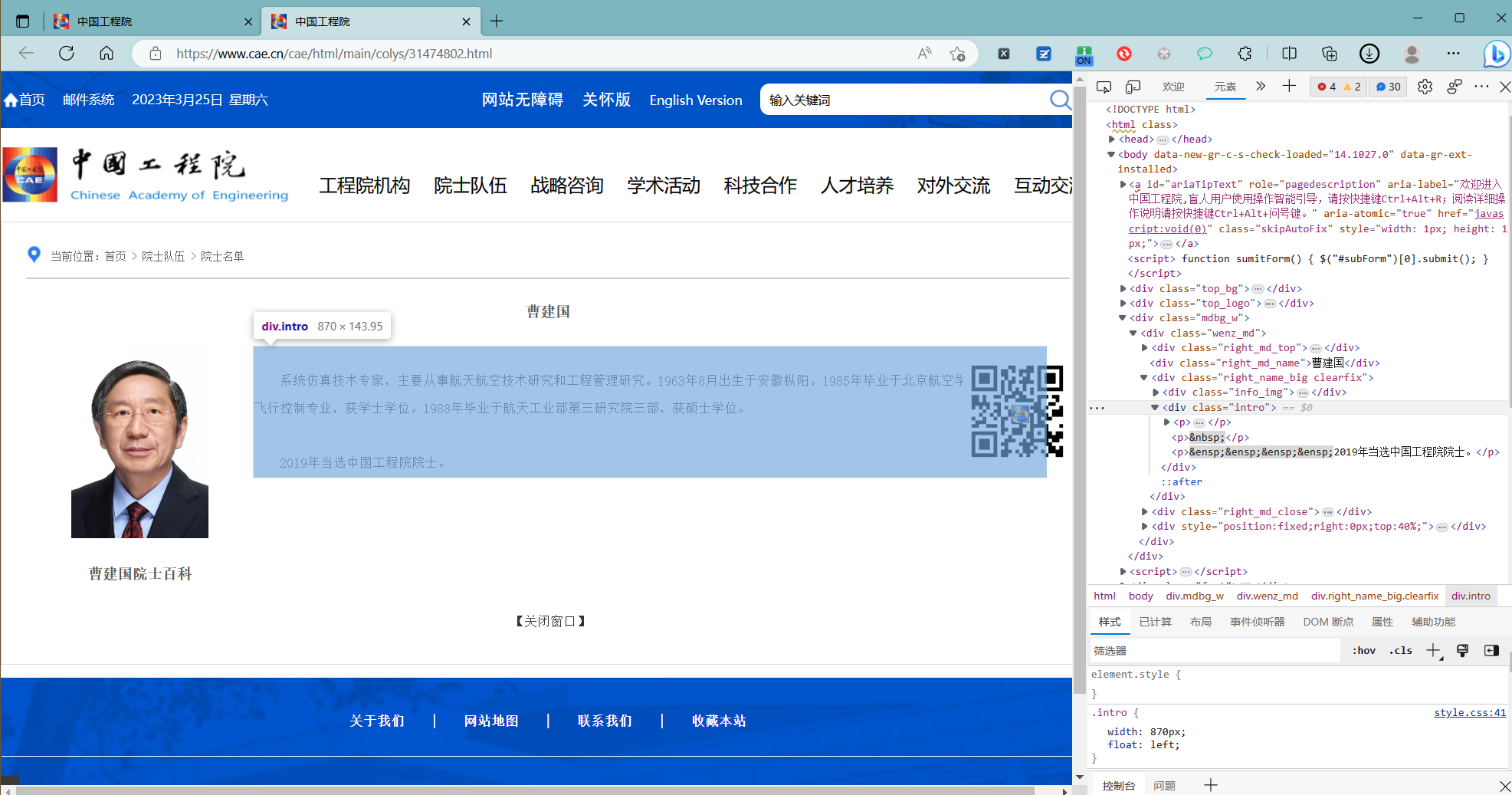
定位元素
body > div.mdbg_w > div > div.right_name_big.clearfix > div.intro
代码实现
# -*- coding: utf-8 -*-
"""
@author : zuti
@software : PyCharm
@file : pahcong.py
@time : 2023/3/25 10:30
@desc :
"""
import pandas as pd
from requests_html import HTMLSession
gcys_url = "https://www.cae.cn/cae/html/main/col53/column_53_xb9.html"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36',
'Content-Type': 'application/json;charset=UTF-8'
}
# 1.创建session对象
session = HTMLSession()
# 2.发送请求
resp = session.get(url=gcys_url, headers=headers,verify=False)
# 3.在页面中查找
"""总的院士名单 https://www.cae.cn/cae/html/main/col48/column_48_1.html"""
# s0 = 'body > div.mdbg > div > div.right_md > div > div.right_md_ysmd > div:nth-child(5)'
# s1 = 'body > div.mdbg > div > div.right_md > div > div.right_md_ysmd > div:nth-child(7)'
# ys_link_list = []
# for i in range(5,40,2):
# s0 = 'body > div.mdbg > div > div.right_md > div > div.right_md_ysmd > div:nth-child('+str(i)+')'
# print(s0)
# ys_list_0 = resp.html.find(selector=s0)
# ys_link_list_0 = ys_list_0[0].absolute_links
# ys_link_list.extend(ys_link_list_0)
ys_link_list = []
#管理院士名单
s0 ='body > div.mdbg > div > div.right_md > div > div.right_md_ysmd > div:nth-child(2)'
ys_list_0 = resp.html.find(selector=s0)
ys_link_list_0 = ys_list_0[0].absolute_links
#
#资深管理院士名单
#s0 ='body > div.mdbg > div > div.right_md > div > div.right_md_ysmd > div:nth-child(4)'
# ys_list_1 = resp.html.find(selector=s1)
# ys_link_list_1 = ys_list_1[0].absolute_links
#
#
ys_link_list.extend(ys_link_list_0)
# ys_link_list.extend(ys_link_list_1)
#print(ys_link_list)
dict_guanli = {} #保存所有的工程管理学部院士
for l in ys_link_list:
#进入个人页面
session2 = HTMLSession()
resp_l = session2.get(url=l, headers=headers, verify=False)
#获取人才名
n = 'body > div.mdbg_w > div > div.right_md_name'
name = resp_l.html.find(selector=n)
name_text = name[0].full_text
# 获取个人介绍
i = 'body > div.mdbg_w > div > div.right_name_big.clearfix > div.intro'
intro = resp_l.html.find(selector=i)
intro_text = intro[0].text
dict_guanli[name_text] = intro_text
session2.close()
session.close()
#将字典保存为excel
# 写入excel
pf=pd.DataFrame()
pf['姓名'] = list(dict_guanli.keys())
pf['简介'] = list(dict_guanli.values())
file_path=pd.ExcelWriter('cae_guanli_zishen.xlsx')
# file_csv_path = pd.read_csv("compound.csv")
# 替换空单元格
pf.fillna(' ', inplace=True)
# 输出
pf.to_excel(file_path, encoding='utf-8', index=False)
# pf.to_csv(file_csv_path, encoding='utf-8', index=False)
# 保存表格
file_path.save()
效果展示

扩展思路
1 可以爬取所有院士
2 院士简介含有研究方向 出生地点 和 出生时间 以及当选时间 可以做一波数据分析 ,来看一下那个省份和年龄的院士最多
本文来自博客园,作者:{珇逖},转载请注明原文链接:https://www.cnblogs.com/zuti666/p/17254455.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号