人才及研究方向信息爬取爬虫
人才及研究方向信息爬取爬虫
需求与思路
需求 : 爬取经济管理相关国家级人才
思路:
1 从title出发,比如中国科学院网站 查看不同学部中院士的介绍
2 分学校,学校官网所在的人才页面,查看相关信息
当前师姐给按着学校分了任务,于是打算先从思路2完成
技术路线
使用 python 爬虫 对结果进行处理
requests库
Python requests 模块 | 菜鸟教程 (runoob.com)
Requests: 让 HTTP 服务人类 — Requests 2.18.1 文档
request库+ 网页分析
requests_html
requests 扩展 | Requests-HTML(增强版) - 腾讯云开发者社区-腾讯云 (tencent.com)
【网络教程】Python爬虫一个requests_html模块足矣!(支持JS加载&异步请求) - 知乎 (zhihu.com)
jieba 分词库
jieba分词-强大的Python 中文分词库 - 知乎 (zhihu.com)
中文分词原理及常用Python中文分词库介绍 - 知乎 (zhihu.com)
具体步骤
以兰州大学为例
1 打开官网
打开官网下的杰出人才网页 杰出人才_兰州大学 (lzu.edu.cn)
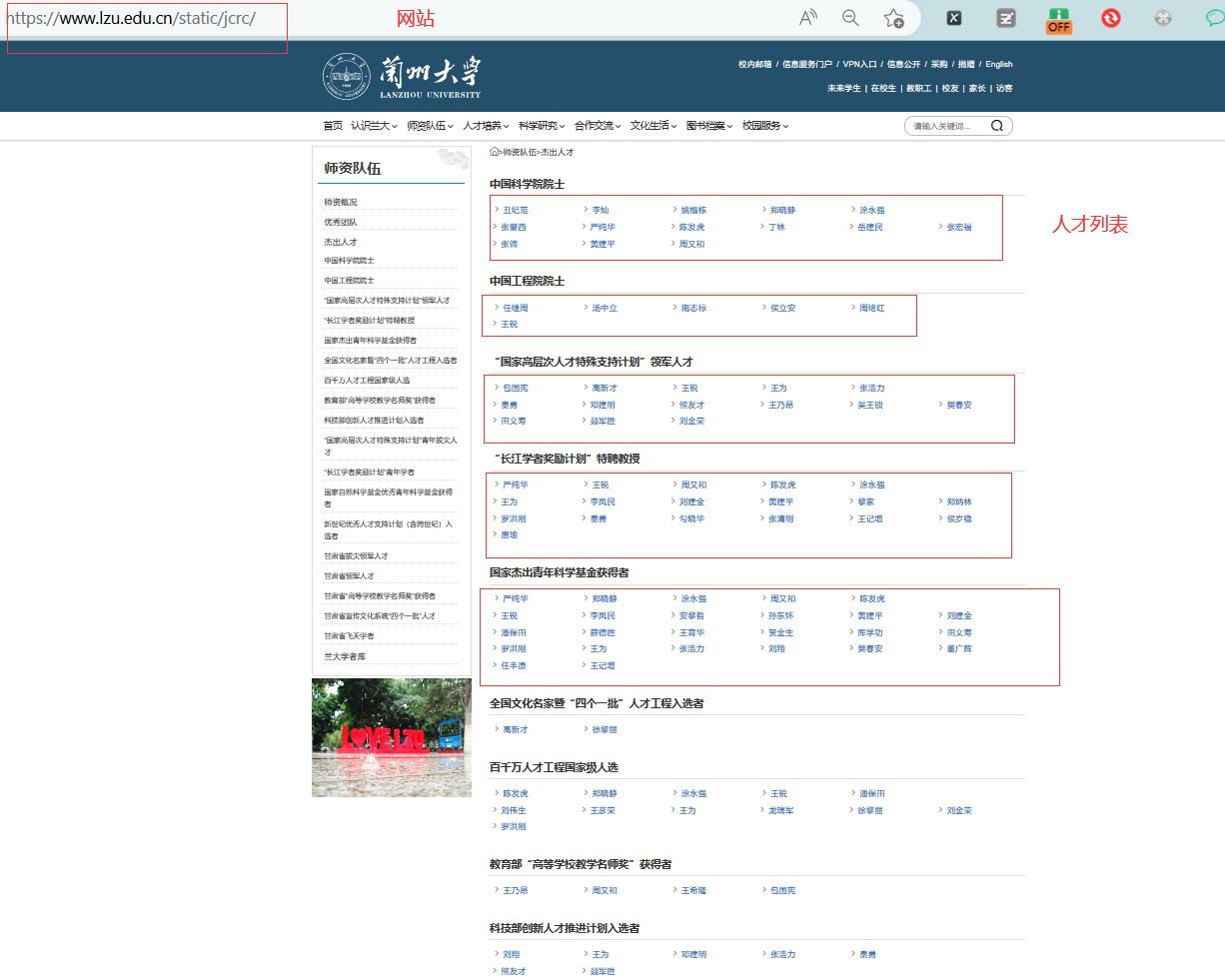
我们发现在兰州大学的官网,有一个总页是所有的人才,然后点击姓名,会跳转到相应教师主页
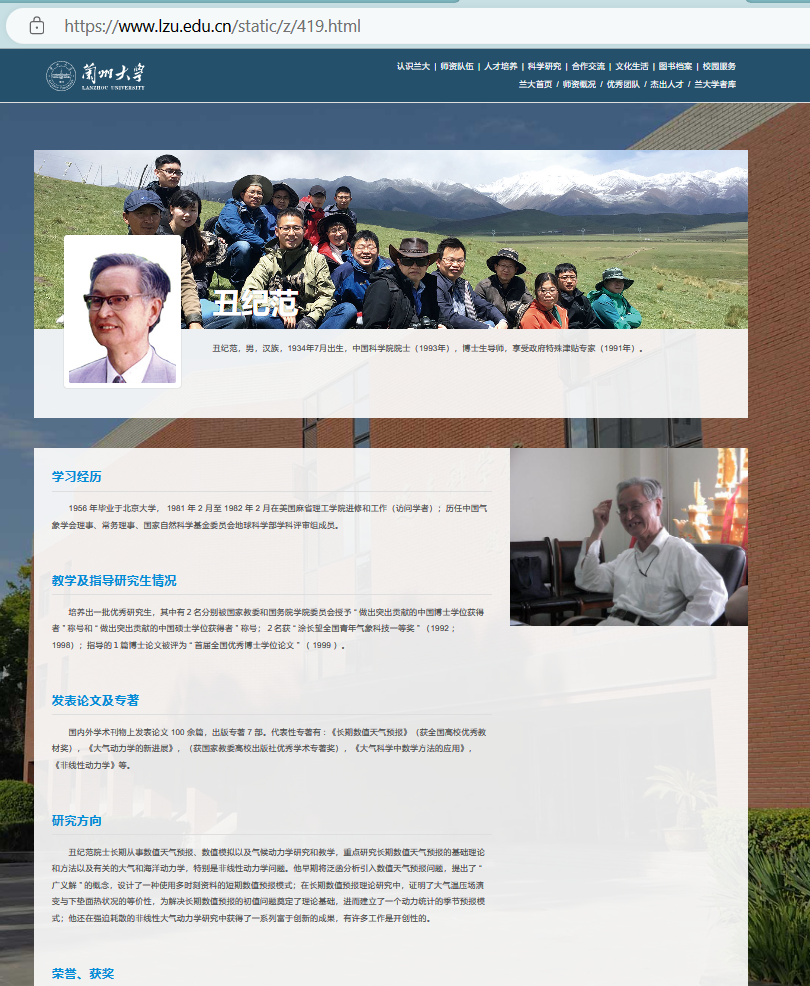
在教师主页有着相应的研究介绍
2 获取人才列表
使用开发者模式,查看网站人才列表所对应的元素或数据加载的请求
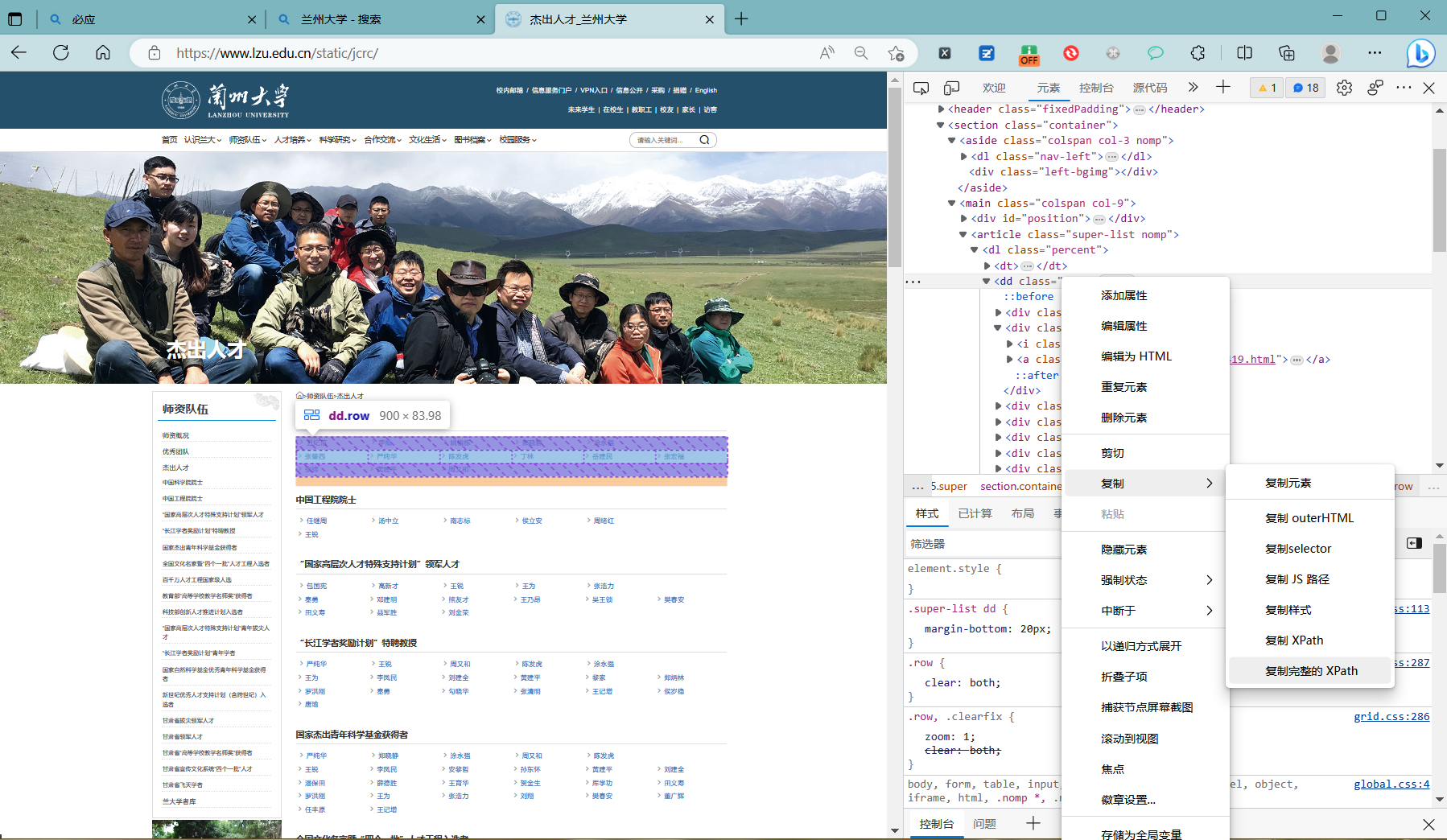
在开发者模式中,可以看到这些列表的 css 和xpath
1 头衔列表
比如第一个中国科学院院士列表,在网页中对应的元素为
#page-35 > section > main > article > dl:nth-child(1) > dd
第二个中国工程院院士,在网页中对应的元素为
#page-35 > section > main > article > dl:nth-child(2) > dd
于是对于这些不同的title 就可以遍历查找上述的所有selector元素
for i in range(1,18):
s='#page-35 > section > main > article > dl:nth-child('+str(i)+') > dd'
2 列表中的每个元素
从开发者模式可以看到,每个教师名称都在列表中的一个元素对应,内容为名字和链接
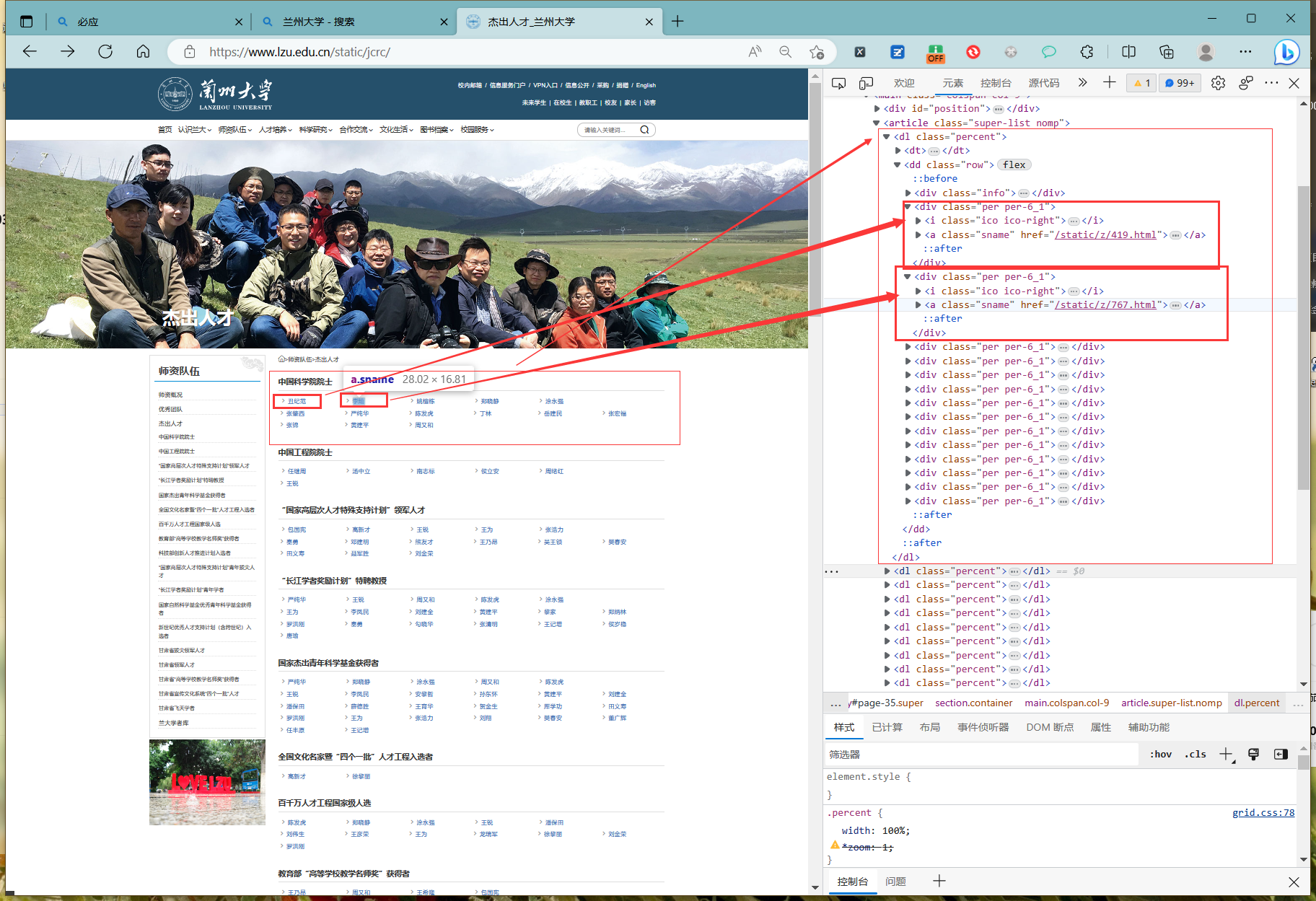
使用 request对网页发送请求,然后一下请求,得到列表元素对应的结果
from requests_html import HTMLSession
jcrc_url = "https://www.lzu.edu.cn/static/jcrc/"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36',
'Content-Type': 'application/json;charset=UTF-8'
}
# 1.创建session对象
session = HTMLSession()
# 2.发送请求
resp = session.get(url=jcrc_url, headers=headers,verify=False)
# 3.在页面中查找
s = '#page-35 > section > main > article > dl:nth-child(1) > dd'
cj_list = resp.html.find(selector=s)
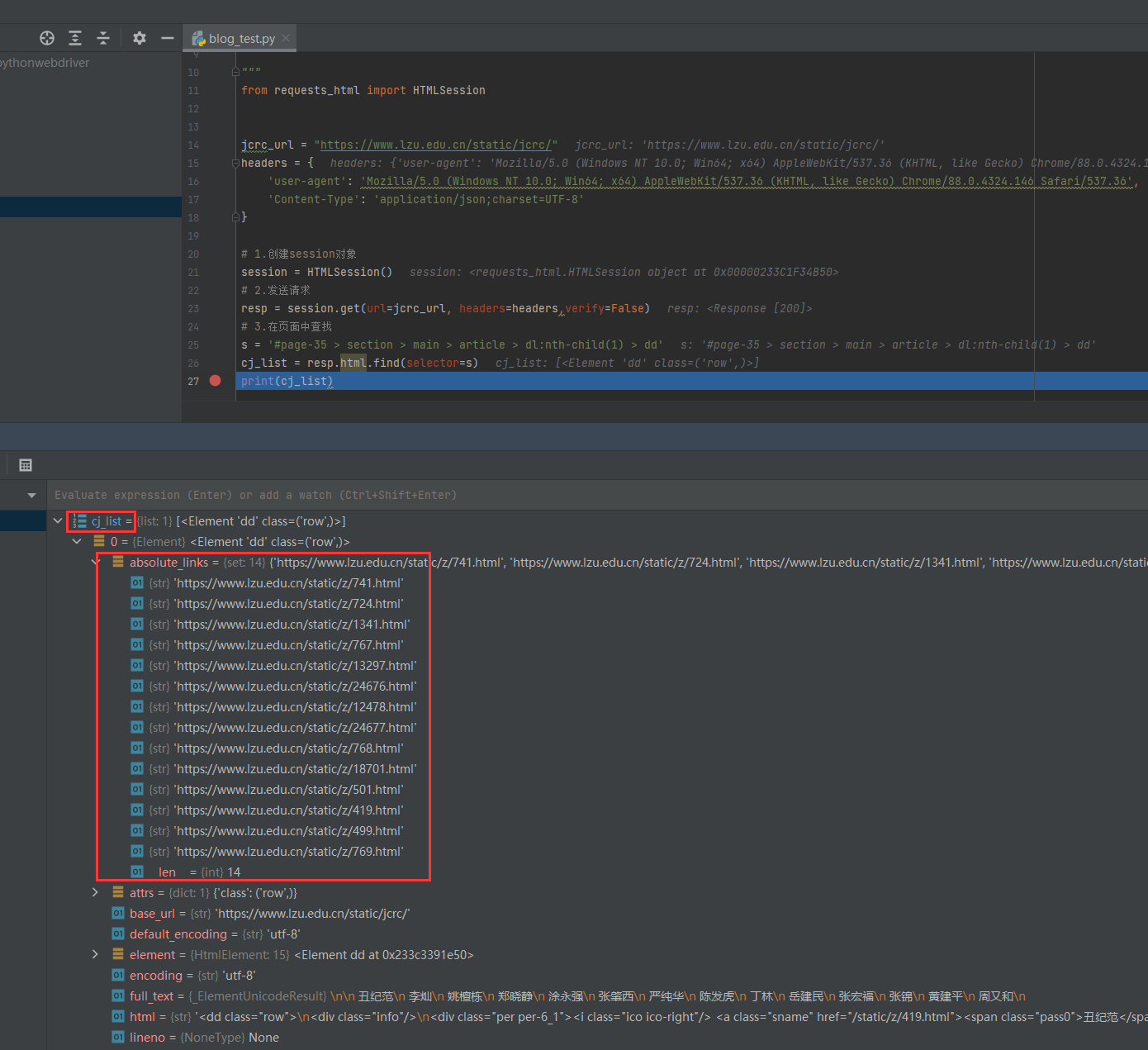
我们发现这个列表中就包含了所有教师的主页链接,然后这是第一个selector对应的结果,我们遍历所有的selector就能够得到所有的主页链接。
from requests_html import HTMLSession
jcrc_url = "https://www.lzu.edu.cn/static/jcrc/"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36',
'Content-Type': 'application/json;charset=UTF-8'
}
# 1.创建session对象
session = HTMLSession()
# 2.发送请求
resp = session.get(url=jcrc_url, headers=headers,verify=False)
# 3.在页面中查找,逐个遍历所有的头像
for i in range(1,18):
s = '#page-35 > section > main > article > dl:nth-child('+str(i)+') > dd'
cj_list = resp.html.find(selector=s)
link_list = cj_list[0].absolute_links
3 获取教师个人主页上研究方向的介绍
同样在开发者模式中查看网站人才列表所对应的元素或数据加载的请求
title
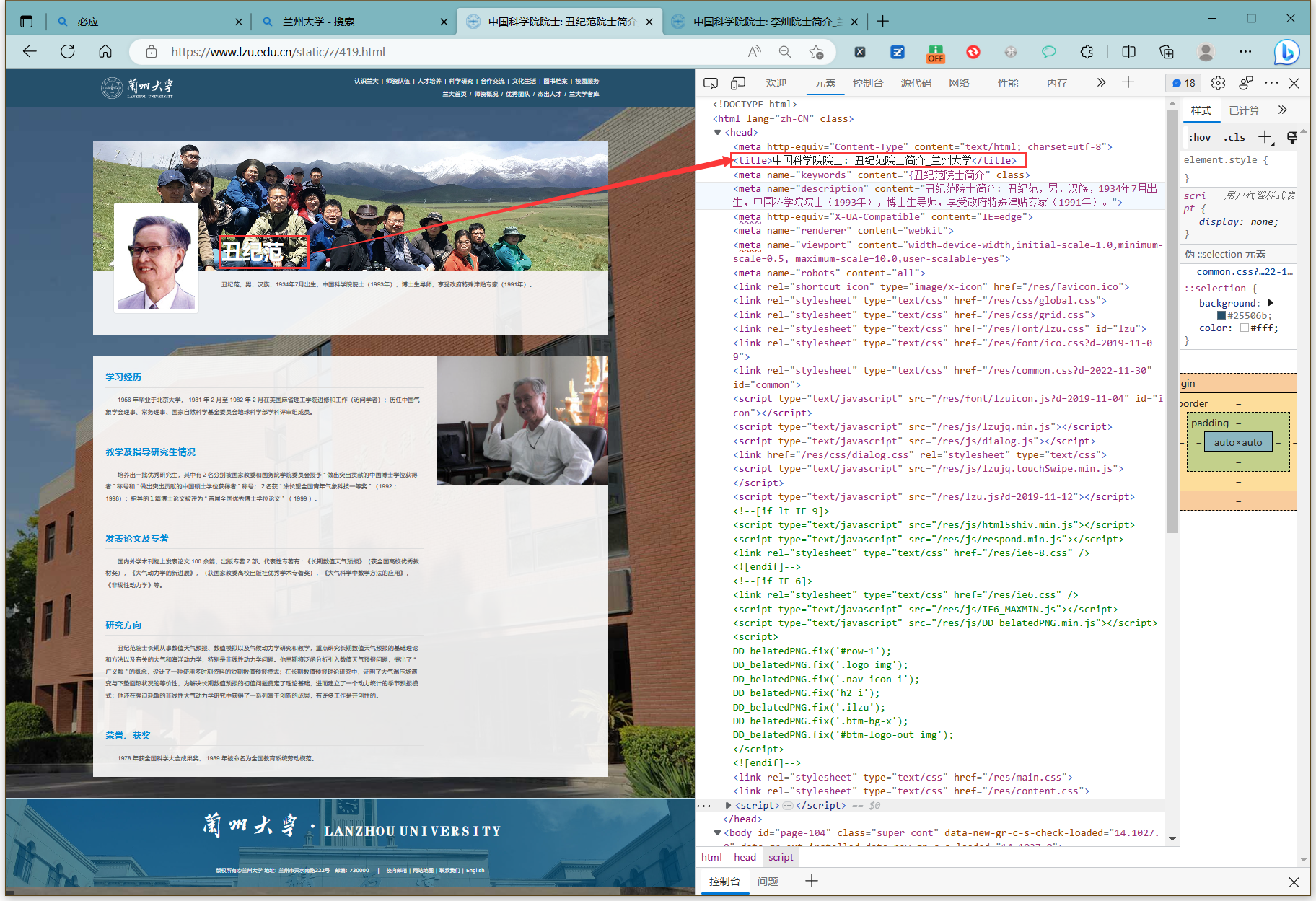
研究方向
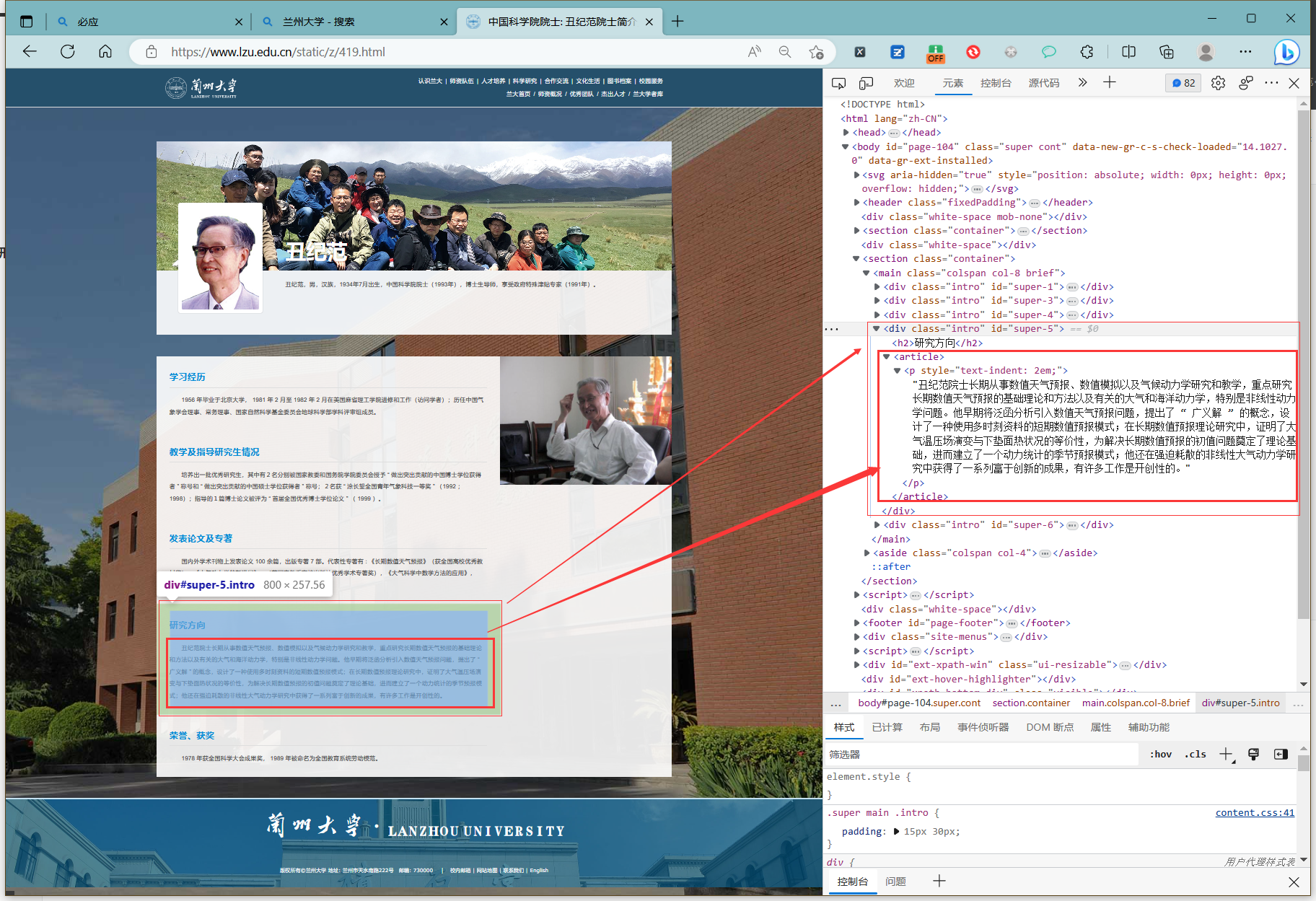
然后在打开多个教师主页查看,发现都有着一个title,但是下面的介绍有的教师缺少一些栏目,但基本都有研究方向这一栏
然后研究方向对应的文本都是
#super-5 > article > p
于是我们可以打开个人主页链接,爬取title和研究方向
session2 = HTMLSession()
resp_2 = session2.get(url=l, headers=headers, verify=False)
title = resp_2.html.xpath('/html/head/title')[0]
title_text = title.full_text
yjfx = resp_2.html.find(selector='#super-5 > article')[0]
#获取研究方向的文本
yjfx_text = yjfx.text
4 对研究方向进行分词 ,查看是否为经管方向
使用Jieba分词
#对研究方向进行分词,查看是否包含关键词
#将研究方向名词添加到jiab词典
jieba.add_word('金融风险')
yjfx_list=jieba.lcut(yjfx_text)
flag = False
for word in yjfx_list:
if in [ "经济" ,"管理" , "运筹" , "金融" , "物流" , "城乡" , "宏观" , "统计"] :
flag = True
break
#如果包含关键词,保存为字典类型
if flag:
dict_l_jingguan[title_text] = yjfx_text
5 将对应数据保存为字典类型,然后以json形式保存到文件中
dict_l[title_text] = yjfx_text
dict[grade_text] = dict_l
if isinstance(dict, str):
dict = eval(dict)
with open('guojia_lanzhou.txt', 'w', encoding='utf-8') as f:
# f.write(str(dict)) # 直接这样存储的时候,读取时会报错JSONDecodeError,因为json读取需要双引号{"aa":"BB"},python使用的是单引号{'aa':'bb'}
str_ = json.dumps(dict, ensure_ascii=False) # TODO:dumps 使用单引号''的dict ——> 单引号''变双引号"" + dict变str
print(type(str_), str_)
f.write(str_)
6 完整代码
# -*- coding: utf-8 -*-
"""
@author : zuti
@software : PyCharm
@file : LanZhou.py
@time : 2023/3/20 22:20
@desc :
使用Requests库爬取兰州大学人才以及研究方向
"""
#import requests
from requests_html import HTMLSession, AsyncHTMLSession
import json
import jieba
# import requests.packages.urllib3
# requests.packages.urllib3.disable_warnings()
jcrc_url = "https://www.lzu.edu.cn/static/jcrc/"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36',
'Content-Type': 'application/json;charset=UTF-8'
}
# 1.创建session对象
session = HTMLSession()
resp = session.get(url=jcrc_url, headers=headers,verify=False)
# print(resp.html)
#jcrc= resp.html.xpath('/html/body/section/main/article')[0]
# full_text = list.full_text
dict = {} #保存所有的国家人才
dict_jingguan = {} #保存所有的经管人才
for i in range(1,18):
g = '#page-35 > section > main > article > dl:nth-child('+str(i)+') > dt > h2 > a'
grade = resp.html.find(selector=g)
grade_text = grade[0].full_text
print(grade_text )
#获取人才名
s = '#page-35 > section > main > article > dl:nth-child('+str(i)+') > dd'
print(s)
cj_list = resp.html.find(selector=s)
#print(f'cj_list+{cj_list}')
link_list = cj_list[0].absolute_links
#print(link_list)
# 新建立一个词典
dict_l = {} #不同层级的国家人才
dict_l_jingguan = {} #不同层级的经管国家人才
for l in link_list:
# 判断
#print(l)
session2 = HTMLSession()
resp_l = session2.get(url=l, headers=headers, verify=False)
title = resp_l.html.xpath('/html/head/title')[0]
title_text = title.full_text
yjfx = resp_l.html.find(selector='#super-5 > article')[0]
#获取研究方向的文本
yjfx_text = yjfx.text
#对研究方向进行分词,查看是否包含关键词
yjfx_list=jieba.lcut(yjfx_text)
flag = False
for word in yjfx_list:
if word == "经济" or word == "管理" or word == "运筹" or word == "金融" or word =="物流" or word =="城乡" or word =="宏观" or word =="统计" :
flag = True
break
#如果包含关键词,保存为字典类型
if flag:
dict_l_jingguan[title_text] = yjfx_text
print(title_text)
print(yjfx_text)
# 保存为字典类型
dict_l[title_text] = yjfx_text
session2.close()
print(f':{dict_l}')
dict[grade_text] = dict_l
dict_jingguan[grade_text ] = dict_l_jingguan
print(f'dict:{dict}')
session.close()
if isinstance(dict, str):
dict = eval(dict)
with open('guojia_lanzhou.txt', 'w', encoding='utf-8') as f:
# f.write(str(dict)) # 直接这样存储的时候,读取时会报错JSONDecodeError,因为json读取需要双引号{"aa":"BB"},python使用的是单引号{'aa':'bb'}
str_ = json.dumps(dict, ensure_ascii=False) # TODO:dumps 使用单引号''的dict ——> 单引号''变双引号"" + dict变str
print(type(str_), str_)
f.write(str_)
if isinstance(dict_jingguan, str):
dict_jingguan = eval(dict_jingguan)
with open('jingguan_lanzhou.txt', 'w', encoding='utf-8') as f:
# f.write(str(dict)) # 直接这样存储的时候,读取时会报错JSONDecodeError,因为json读取需要双引号{"aa":"BB"},python使用的是单引号{'aa':'bb'}
str_ = json.dumps(dict_jingguan, ensure_ascii=False) # TODO:dumps 使用单引号''的dict ——> 单引号''变双引号"" + dict变str
print(type(str_), str_)
f.write(str_)
#print(absolute_list)
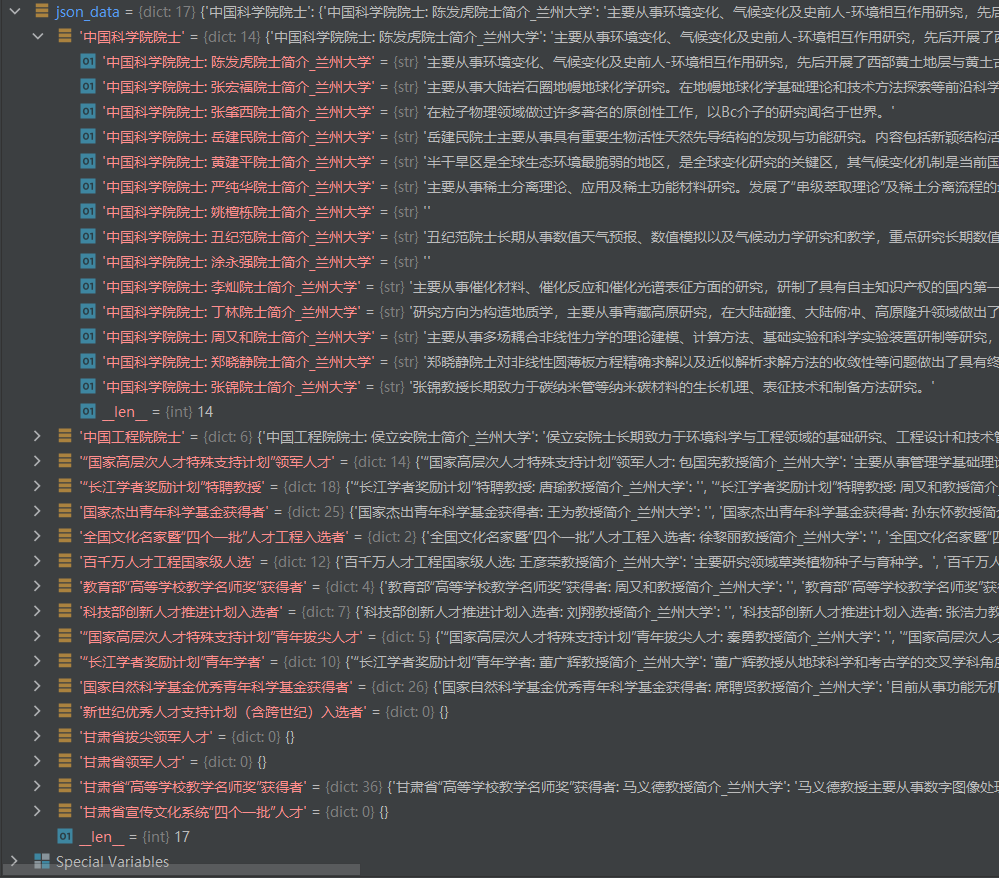
效果展示
读取保存的结果
代码
import json
with open('guojia_lanzhou.txt','r',encoding='utf8')as fp:
json_data = json.load(fp)
print('这是文件中的json数据:',json_data)
print('这是读取到文件数据的数据类型:', type(json_data))
效果
本文来自博客园,作者:{珇逖},转载请注明原文链接:https://www.cnblogs.com/zuti666/p/17242797.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· .NET10 - 预览版1新功能体验(一)