飞机游戏五 强化学习算法库
1.空战博弈编程实现——2 初探JSBSIM2.空战博弈实现——3 gym自定义环境3.空战博弈编程实现——gym+jsbsim4.空战博弈编程实现5.空战编程实现——6 强化学习与控制器6.空战博弈编程实现7——将JSBSI和强化学习算法融合7.博弈论与强化学习 算法 一 MinimaxQ, NashQ ,FFQ8.博弈论与强化学习——基础1 扩展型博弈9.飞机游戏二 空战可视化+强化学习10.gym——1自定义Gym环境并注册11.博弈论与强化学习实战——CFR算法——剪刀石头布12.博弈论与强化学习——— 基础2 马尔科夫博弈13.飞机游戏六 空战强化学习环境6.1DBML 6.1.1DBML 使用
14.飞机游戏五 强化学习算法库
15.分层强化学习316.飞机游戏三仿真软件 3.2Airsim介绍17.强化学习与控制器18.飞机游戏四 飞机作战场景19.飞机游戏三仿真软件 3.1JSBSim介绍20.飞机游戏 一 飞行基础知识 1.1概念介绍21.空战编程实现1——小雅22.分层强化学习23.问题建模24.多智能体理论25.马尔可夫决策理论26.飞机基础知识一 1.3二维平面飞机运动学模型27.飞机游戏六 空战环境 6.1 DBRML 6.1.5 动作空间设置28.飞行基础知识一 1.2飞机的三自由度方程29.中远距空战对战场景30.飞机游戏六空战强化学习环境6.1DBML 6.1.4 DBML+强化学习算法使用31.飞机游戏六空战强化学习环境6.1DBML 6.1.3 DBML+强化学习算法使用32.飞机游戏三仿真软件 3.3 Dogfight介绍 33.飞机游戏六空战强化学习环境 6.1DBML 6.1.2源码阅读与分析飞机游戏五 强化学习算法库
目录
一 stable-baseline3
介绍
利用stable-baselines3优雅便捷地玩转深度强化学习算法 - 知乎 (zhihu.com)
项目地址
提供算法及适用场景
Implemented Algorithms
| Name | Recurrent | Box |
Discrete |
MultiDiscrete |
MultiBinary |
Multi Processing |
|---|---|---|---|---|---|---|
| ARS1 | ❌ | ✔️ | ✔️ | ❌ | ❌ | ✔️ |
| A2C | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| DDPG | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| DQN | ❌ | ❌ | ✔️ | ❌ | ❌ | ✔️ |
| HER | ❌ | ✔️ | ✔️ | ❌ | ❌ | ❌ |
| PPO | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| QR-DQN1 | ❌ | ❌ | ✔️ | ❌ | ❌ | ✔️ |
| RecurrentPPO1 | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| SAC | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| TD3 | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| TQC1 | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ |
| TRPO1 | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Maskable PPO1 | ❌ | ❌ | ✔️ | ✔️ | ✔️ | ✔️ |
1: Implemented in SB3 Contrib GitHub repository.
Actions gym.spaces:
Box: A N-dimensional box that containes every point in the action space.Discrete: A list of possible actions, where each timestep only one of the actions can be used.MultiDiscrete: A list of possible actions, where each timestep only one action of each discrete set can be used.MultiBinary: A list of possible actions, where each timestep any of the actions can be used in any combination.
二 小雅 ElegantRL
介绍
小雅 ElegantRL: 基于PyTorch的轻量-高效-稳定的深度强化学习框架 - 知乎 (zhihu.com)
项目地址
GitHub - AI4Finance-Foundation/ElegantRL: Cloud-native deep reinforcement learning. 🔥
提供算法及适用场景
ElegantRL implements the following model-free deep reinforcement learning (DRL) algorithms:
DDPG, TD3, SAC, PPO, REDQ for continuous actions in single-agent environment,
DQN, Double DQN, D3QN for discrete actions in single-agent environment,
QMIX, VDN, MADDPG, MAPPO, MATD3 in multi-agent environment.
项目架构
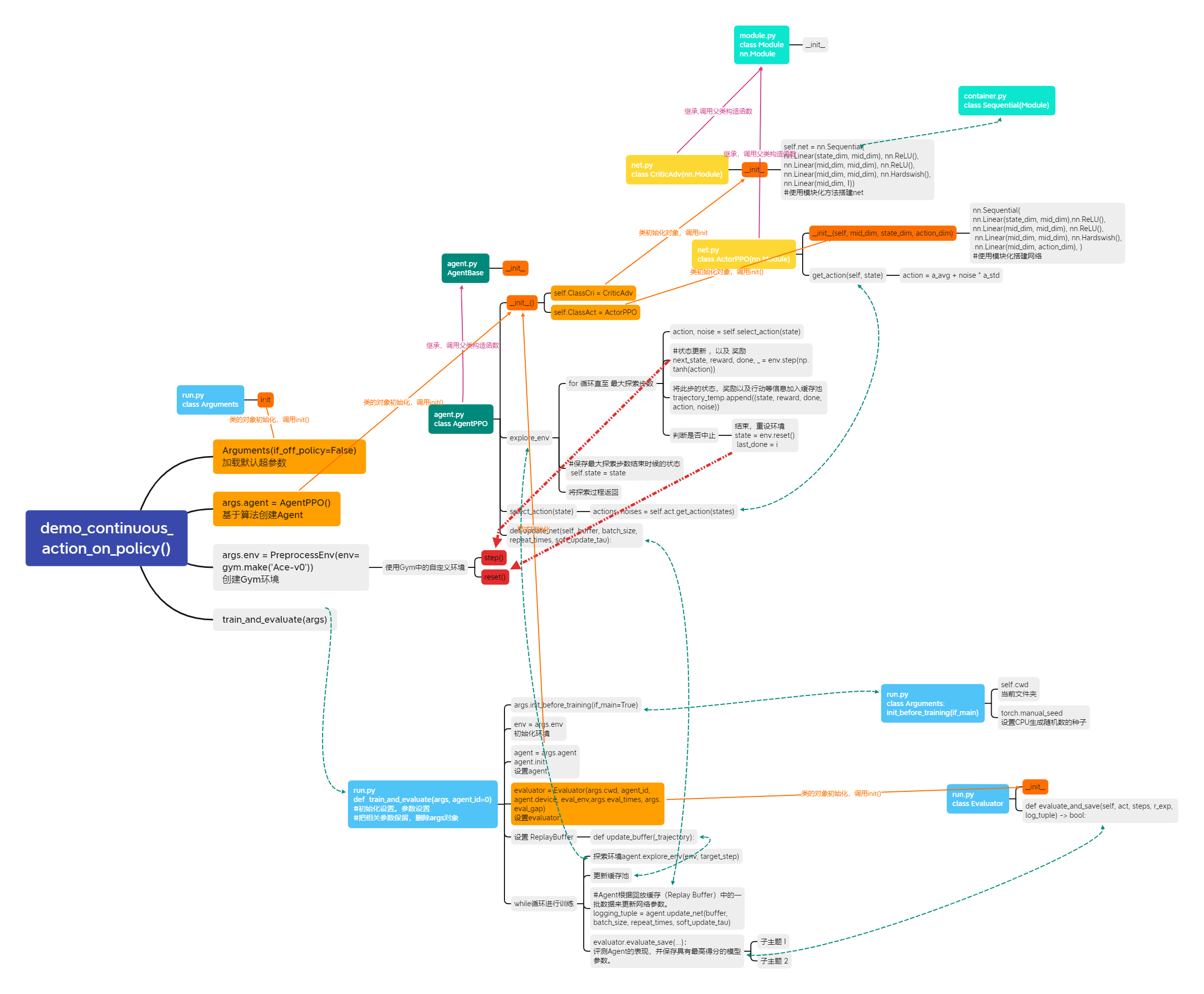
本文来自博客园,作者:{珇逖},转载请注明原文链接:https://www.cnblogs.com/zuti666/p/16967224.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律