
浅谈spring
spring流程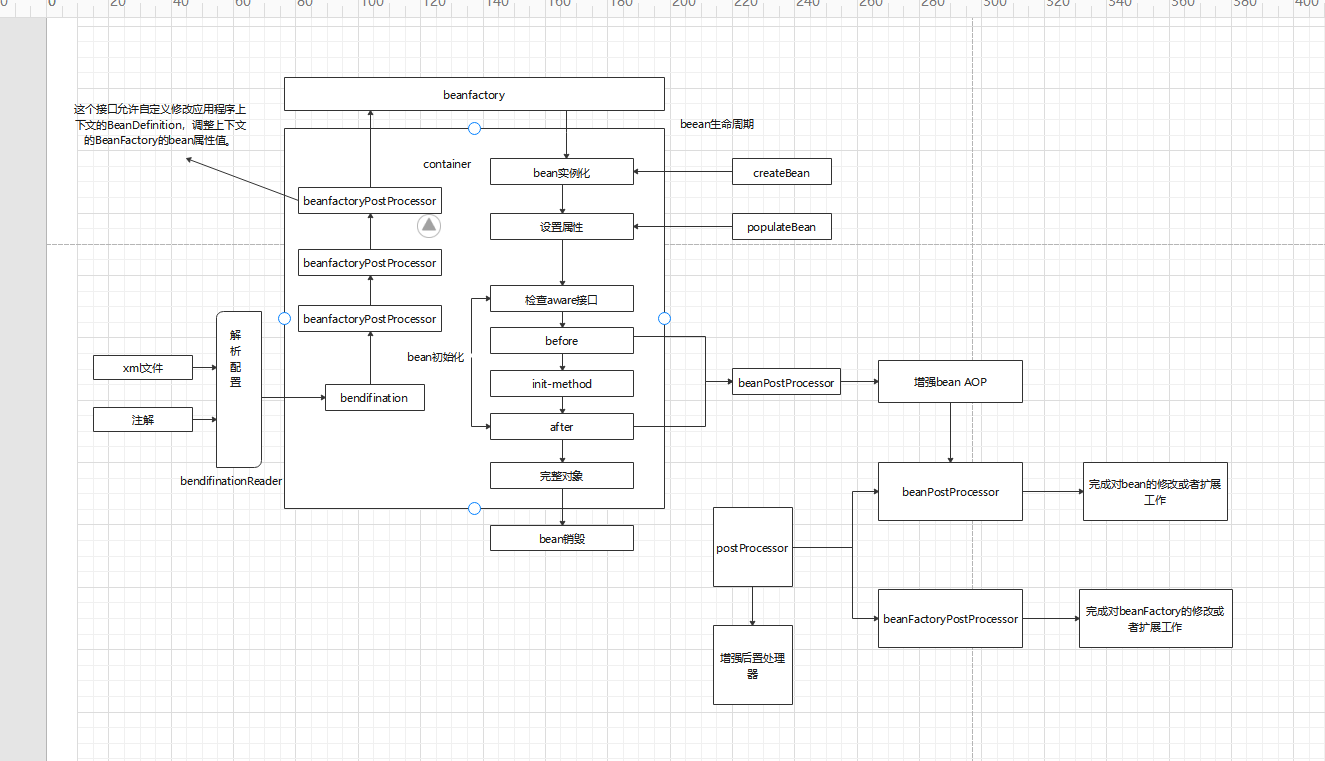
扩展点:下图来自此篇文章:https://www.jianshu.com/p/397c15cbf34a
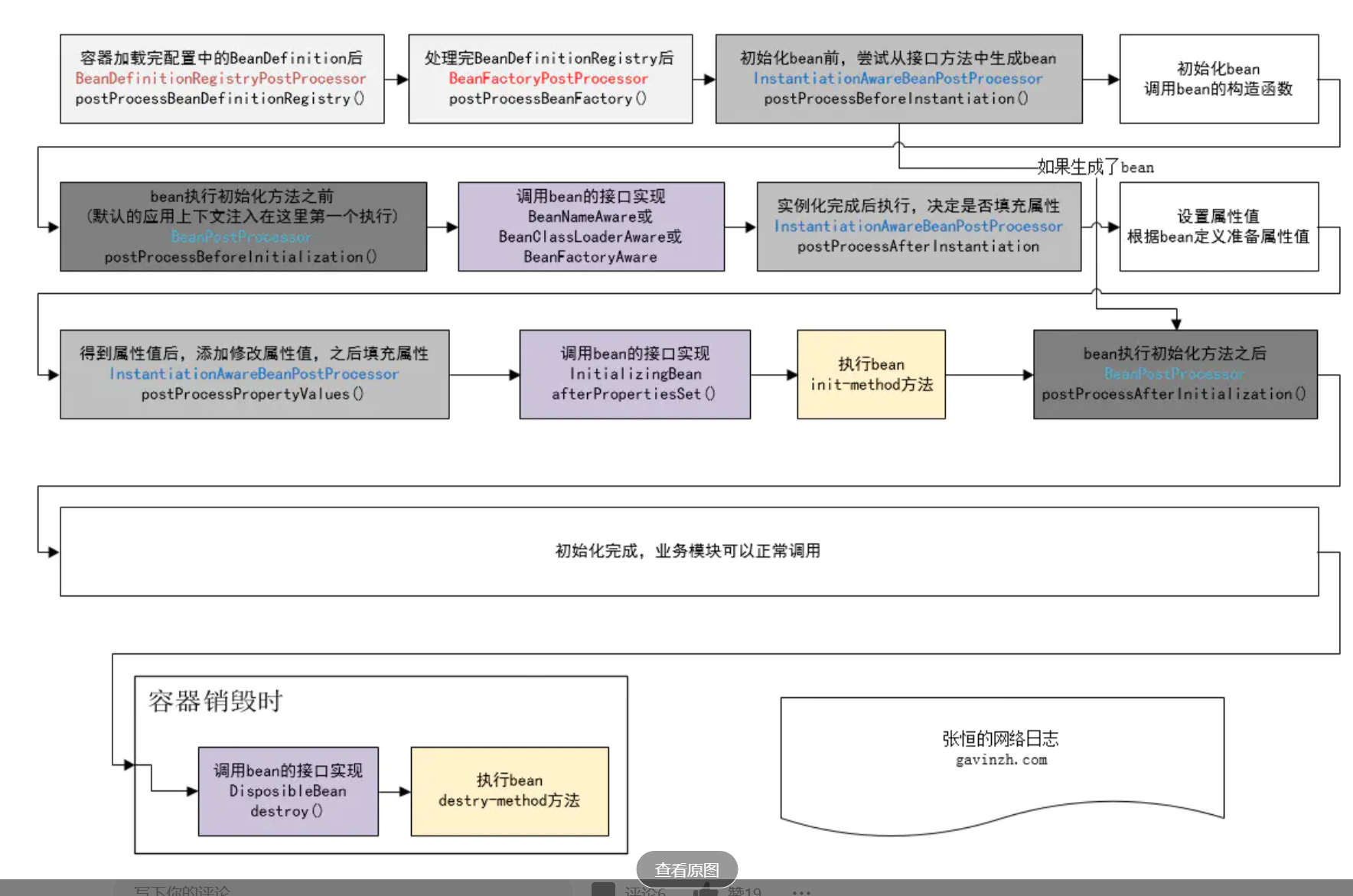
三级缓存
Spring能够轻松的解决属性的循环依赖正式用到了三级缓存,在AbstractBeanFactory中有详细的注释。
一级缓存:singletonObjects,存放完全实例化属性赋值完成的Bean,直接可以使用。
二级缓存:earlySingletonObjects,存放早期Bean的引用,尚未属性装配的Bean三级缓存:singletonFactories,
三级缓存,存放实例化完成的Bean工厂。
【1】为什么Spring不能解决构造器的循环依赖?
从流程图应该不难看出来,在Bean调用构造器实例化之前,一二三级缓存并没有Bean的任何相关信息,在实例化之后才放入三级缓存中,因此当getBean的时候缓存并没有命中,这样就抛出了循环依赖的异常了。
【2】为什么多实例Bean不能解决循环依赖?
多实例Bean是每次创建都会调用doGetBean方法,根本没有使用一二三级缓存,肯定不能解决循环依赖。
总结
了解一点:一级缓存放的是完成的bean,二级缓存放的是实例化后的bean,三级缓存放的是早期的bean的工厂
根据以上的分析,大概清楚了Spring是如何解决循环依赖的。假设A依赖B,B依赖A(注意:这里是set属性依赖)分以下步骤执行:
A创建过程需要 B,先将A放到三级缓存,去实例化B
B实例化过程需要A,于是B先查一级缓存,没有A,去查询二级,再查三级,结果拿到A,r然后把三级的A移到二级,删除三级的A
B顺利实例化后,将自己放到一级缓存。然后再回来创建A,A需要B,但是可以从一级缓存中拿到B,然后A也就顺利创建完成,放到一级缓存
注解底层原理?
@Autowired 的使用简化了我们的开发,其原理是使用 AutowiredAnnotationBeanPostProcessor 类来实现,该类实现了 Spring 框架的一些扩展接口,通过实现 BeanFactoryAware 接口使其内部持有了 BeanFactory(可轻松的获取需要依赖的的 Bean);通过实现 MergedBeanDefinitionPostProcessor 扩展接口,在 BeanFactory 里面的每个 Bean 实例化前获取到每个 Bean 里面的 @Autowired 信息并缓存下来;通过实现 Spring 框架的 postProcessPropertyValues 扩展接口在 BeanFactory 里面的每个 Bean 实例后从缓存取出对应的注解信息,获取依赖对象,并通过反射设置到 Bean 属性里面。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)