


Elasticsearch专题精讲—— REST APIs —— Document APIs —— 读写文档
REST APIs —— Document APIs —— 读写文档
1、Introduction
https://www.elastic.co/guide/en/elasticsearch/reference/8.8/docs-replication.html
Each index in Elasticsearch is divided into shards and each shard can have multiple copies. These copies are known as a replication group and must be kept in sync when documents are added or removed. If we fail to do so, reading from one copy will result in very different results than reading from another. The process of keeping the shard copies in sync and serving reads from them is what we call the data replication model.
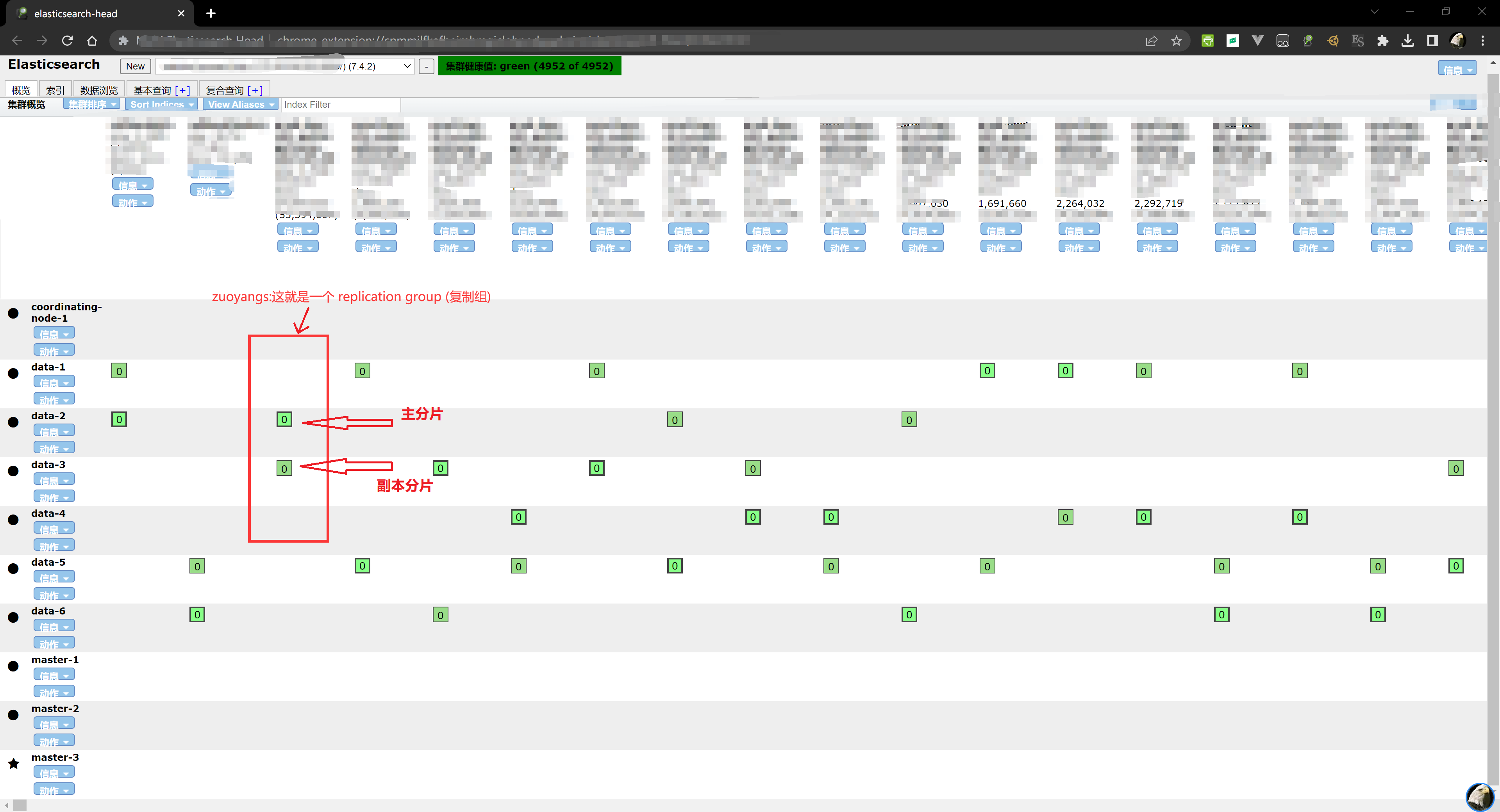
在 Elasticsearch ,每个索引都被划分为多个 shards,每个 shard 可以有多个 copies(副本分片),这些 copies(副本分片) 称为 replication group(复制组)。
在 added 或 removed documents 时必须保持同步。如果我们不这样做,将导致从一个 copy(副本分片)读取的数据与从另一个副本分片中读取的数据表现出截然不同的结果。
保持 shard、copies,两两副本间数据同步并提供读取数据的过程称为 data replication model(数据复制模型)。
下图展示了 replication group(复制组) 的含义,此复制组有1个分片,1个副本。这2个分片的数据必须保持一致,主分片和副本分片可以短时间内部一致,但是最终需要一致。
Elasticsearch’s data replication model is based on the primary-backup model and is described very well in the PacificA paper of Microsoft Research. That model is based on having a single copy from the replication group that acts as the primary shard. The other copies are called replica shards. The primary serves as the main entry point for all indexing operations. It is in charge of validating them and making sure they are correct. Once an index operation has been accepted by the primary, the primary is also responsible for replicating the operation to the other copies.
Elasticsearch 的数据复制模型是基于 primary-backup model 的,在微软研究院的 PacificA 论文(https://www.microsoft.com/en-us/research/wp-content/uploads/2008/03/sigmod08-final.pdf, 现在404了,如果有人知道,可以告诉我)中得到了很好的描述。
该模型基于具有 single copy(单个副本)的 replication group(复制组),该 single copy 扮演着 primary shard(主分片)。其他 copies (副本) 称为 replica shards (副本分片)。The primary serves 充当所有索引操作的主入口点。它负责验证它们,并确保它们是正确的。一旦 primary serves 接受了索引操作,primary serves 还负责将该操作复制到其他副本。
2、Basic write model(基本写模型)
https://www.elastic.co/guide/en/elasticsearch/reference/8.8/docs-replication.html#basic-write-model
Every indexing operation in Elasticsearch is first resolved to a replication group using routing, typically based on the document ID. Once the replication group has been determined, the operation is forwarded internally to the current primary shard of the group. This stage of indexing is referred to as the coordinating stage.
Elasticsearch 中的每个索引操作首先使用路由(通常基于 document ID)解析为 replication group(复制组)。
一旦确定了 replication group(复制组)之后,该操作将在内部转发到该组的当前 primary shard。这一阶段的索引被称为协调阶段。
The next stage of indexing is the primary stage, performed on the primary shard. The primary shard is responsible for validating the operation and forwarding it to the other replicas. Since replicas can be offline, the primary is not required to replicate to all replicas. Instead, Elasticsearch maintains a list of shard copies that should receive the operation. This list is called the in-sync copies and is maintained by the master node. As the name implies, these are the set of "good" shard copies that are guaranteed to have processed all of the index and delete operations that have been acknowledged to the user. The primary is responsible for maintaining this invariant and thus has to replicate all operations to each copy in this set.
索引的下一个阶段是主要阶段,由 primary shard 执行。primary shard(主分片)负责验证操作并将其转发给其他 replicas(副本)。由于 replicas(副本)可能处于离线状态,因此 primary shard(主分片)不需要复制到所有 replicas(副本)。
相反,Elasticsearch 维护着一个列表,该列表记录了应该接收这个操作的 shard copies(分片副本)。这个列表称为同步副本,由主节点维护。
如其名称所示,这是一组“good”的 shard copies(分片副本)集合,保证已处理所有已向用户确认的索引和删除操作。The primary(主分片)负责维护这个 invariant(不变量),因此必须将所有操作复制到该集合中的每个 copy (副本)。
The primary shard follows this basic flow: 1、Validate incoming operation and reject it if structurally invalid (Example: have an object field where a number is expected) 2、Execute the operation locally i.e. indexing or deleting the relevant document. This will also validate the content of fields and reject if needed (Example: a keyword value is too long for indexing in Lucene). 3、Forward the operation to each replica in the current in-sync copies set. If there are multiple replicas, this is done in parallel. 4、Once all in-sync replicas have successfully performed the operation and responded to the primary, the primary acknowledges the successful completion of the request to the client.
primary shard 遵循以下基本流程:
1、验证传入操作,如果结构无效则拒绝该操作。(例如: 向一个数字字段传输一个对象类型。)
2、在本地执行操作,即索引或删除相关文档。这还将验证字段的内容,并在需要时拒绝(例如: 关键字值太长,无法在 Lucene 中建立索引)。
3、将操作转发到当前 in-sync copies set(同步副本组)中的每个 replica(副本)。如果有 multiple replicas(多个副本),则 parallel(并行)执行。
4、一旦所有 in-sync replicas(同步副本)成功执行了操作并响应了 primary,primary 就会确认 client 的请求已成功完成。
Each in-sync replica copy performs the indexing operation locally so that it has a copy. This stage of indexing is the replica stage.
每个 in-sync replica copy(处于同步状态的副本)都会在本地执行索引操作,以便它拥有一份 copy(副本)。这个阶段称为 replica stage(副本阶段)。
These indexing stages (coordinating, primary, and replica) are sequential. To enable internal retries, the lifetime of each stage encompasses the lifetime of each subsequent stage. For example, the coordinating stage is not complete until each primary stage, which may be spread out across different primary shards, has completed. Each primary stage will not complete until the in-sync replicas have finished indexing the docs locally and responded to the replica requests.
这些索引阶段(coordinating(协调)、primary(主分片)和 replica(副本))是顺序执行的。为了启用内部重试,每个阶段的生命周期都包含了每个后续阶段的生命周期。例如,coordinating stage(协调阶段)在每个 primary stage(主要阶段)完成之前是不完整的,而这些 primary stage(主要阶段)可能分散在不同的 primary shards(主分片)中。每个 primary stage(主要阶段)都将在 in-sync replicas(处于同步状态的副本)本地完成文档的索引,并响应 replica(副本)请求后才能完成。
3、Failure handling(写流程错误处理)
https://www.elastic.co/guide/en/elasticsearch/reference/8.8/docs-replication.html#_failure_handling
These indexing Many things can go wrong during indexing — disks can get corrupted, nodes can be disconnected from each other, or some configuration mistake could cause an operation to fail on a replica despite it being successful on the primary. These are infrequent but the primary has to respond to them.
在索引过程中可能出现许多错误ーー磁盘可能损坏,节点可能彼此断开连接,或者一些配置错误可能导致操作在 replica(副本)上失败,尽管在 primary(主分片)上的操作是成功的。这种情况很少发生,但是 primary(主分片)必须对此作出反应。
In the case that the primary itself fails, the node hosting the primary will send a message to the master about it. The indexing operation will wait (up to 1 minute, by default) for the master to promote one of the replicas to be a new primary. The operation will then be forwarded to the new primary for processing. Note that the master also monitors the health of the nodes and may decide to proactively demote a primary. This typically happens when the node holding the primary is isolated from the cluster by a networking issue. See here for more details.
如果 primary(主分片)本身发生故障,primary(主分片)所在的节点将向 master 节点发送一条消息。索引操作将等待(默认最多1分钟)master 节点将其中一个 replicas(副本)to be a new primary(新的主分片)。然后,操作将被转发到 new primary(新的主分片)进行处理。请注意,master 节点还会监视节点的健康状况,并可能主动降级 primary(主分片)。当存持有 primary(主分片)的节点被网络故障隔离时,通常会发生这种情况。有关更多详细信息,请参见此处(https://www.elastic.co/guide/en/elasticsearch/reference/8.8/docs-replication.html#demoted-primary)。
Once the operation has been successfully performed on the primary, the primary has to deal with potential failures when executing it on the replica shards. This may be caused by an actual failure on the replica or due to a network issue preventing the operation from reaching the replica (or preventing the replica from responding). All of these share the same end result: a replica which is part of the in-sync replica set misses an operation that is about to be acknowledged. In order to avoid violating the invariant, the primary sends a message to the master requesting that the problematic shard be removed from the in-sync replica set. Only once removal of the shard has been acknowledged by the master does the primary acknowledge the operation. Note that the master will also instruct another node to start building a new shard copy in order to restore the system to a healthy state.
在主分片成功执行操作后,主分片必须处理在副本分片上执行操作时可能出现的故障。这可能是由副本实际故障或由于网络问题导致操作无法到达副本(或导致副本无法响应)而引起的。所有这些问题都有着同样的结果:处于同步副本集的副本错过了即将被确认的操作。为了避免破坏不变量,主分片向主节点发送一条消息,请求将有问题的分片从同步副本集中删除。只有在主节点确认移除分片后,主分片才会确认该操作。请注意,主节点还将指示另一个节点开始构建一个新的分片副本,以便将系统恢复到正常状态。
While forwarding an operation to the replicas, the primary will use the replicas to validate that it is still the active primary. If the primary has been isolated due to a network partition (or a long GC) it may continue to process incoming indexing operations before realising that it has been demoted. Operations that come from a stale primary will be rejected by the replicas. When the primary receives a response from the replica rejecting its request because it is no longer the primary then it will reach out to the master and will learn that it has been replaced. The operation is then routed to the new primary.
在将操作转发到 replicas(副本)时,primary 将使用 replica (副本)来验证自己仍然是活动的 primary。如果 primary 由于网络分区(或长时间的垃圾回收)而被隔离,则在知道它已降级之前,它可能会继续处理传入的索引操作。来自过时 primary 的操作将被 replica 拒绝。 primary 收到来自 replica 的拒绝请求的响应时,它将达到 master 并知它已经被替换,然后将操作路由到新的 primary。
What happens if there are no replicas?
This is a valid scenario that can happen due to index configuration or simply because all the replicas have failed. In that case the primary is processing operations without any external validation, which may seem problematic. On the other hand, the primary cannot fail other shards on its own but request the master to do so on its behalf. This means that the master knows that the primary is the only single good copy. We are therefore guaranteed that the master will not promote any other (out-of-date) shard copy to be a new primary and that any operation indexed into the primary will not be lost. Of course, since at that point we are running with only single copy of the data, physical hardware issues can cause data loss. See Active shards for some mitigation options.
4、Basic read model(基本读模型)
https://www.elastic.co/guide/en/elasticsearch/reference/8.8/docs-replication.html#_basic_read_model
Reads in Elasticsearch can be very lightweight lookups by ID or a heavy search request with complex aggregations that take non-trivial CPU power. One of the beauties of the primary-backup model is that it keeps all shard copies identical (with the exception of in-flight operations). As such, a single in-sync copy is sufficient to serve read requests.
在 Elasticsearch 中的读取可以是非常轻量的根据 ID 进行查找,也可以是有复杂聚合的耗费大量 CPU 资源的搜索请求。primary-backup model(主备模型)的优点之一是它保持所有 shard copies(分片副本)的一致性(除了正在进行的操作)。因此,single in-sync copy(单个同步副本)足以处理读取请求。
When a read request is received by a node, that node is responsible for forwarding it to the nodes that hold the relevant shards, collating the responses, and responding to the client. We call that node the coordinating node for that request.
当节点接收到读请求时,该节点负责将请求转发给持有相关 shards 的节点,整理、汇总这些节点的响应,并向客户端发送响应。我们将该节点称为该请求的协调节点。
The basic flow is as follows:
基本流程如下:
1、Resolve the read requests to the relevant shards. Note that since most searches will be sent to one or more indices, they typically need to read from multiple shards, each representing a different subset of the data.
1、将读取请求解析为相关的分片。需要注意的是,由于大多数搜索都会发送到一个或多个索引,因此它们通常需要从多个分片中读取,每个分片表示数据的不同子集。
2、Select an active copy of each relevant shard, from the shard replication group. This can be either the primary or a replica. By default, Elasticsearch uses adaptive replica selection to select the shard copies.
2、从 shard replication group(分片复制组)中选择每个相关 shard 的一个 active copy(活动副本),可以是 primary(主分片)或 replica(副本)。默认情况下,Elasticsearch 使用自适应副本选择(https://www.elastic.co/guide/en/elasticsearch/reference/8.8/search-shard-routing.html#search-adaptive-replica)来选择分片副本。
3、Send shard level read requests to the selected copies.
3、向选定的 copies(副本)发送 shard level read requests(分片级读请求)
我对 shard level read requests(分片级读请求)的理解: shard level read requests 是指在 Elasticsearch 集群中进行搜索或读取操作时,请求被分发到每个分片的过程。节点会将请求转发到负责相关分片的节点,并整理所有响应。在分片级别上进行读取操作可以提高查询效率和可扩展性,因为数据被切分并分布在不同的节点上。但是需要注意的是,当进行分片级别操作时,需要考虑数据一致性问题,因为不同的副本可能会返回不同的结果,需要选取最终结果。
4、Combine the results and respond. Note that in the case of get by ID look up, only one shard is relevant and this step can be skipped.
4、将结果合并并做出响应。请注意,在按ID查找的情况下,仅一个分片是相关的,因此可以跳过此步骤。
5、Shard failures(碎片故障)
When a shard fails to respond to a read request, the coordinating node sends the request to another shard copy in the same replication group. Repeated failures can result in no available shard copies.
当一个分片未能响应读取请求时,协调节点将该请求发送到同一 replication group(复制组)中的另一个 shard copy(分片副本)。重复失败可能导致没有可用的 shard copies(分片副本)。
To ensure fast responses, the following APIs will respond with partial results if one or more shards fail:
为了确保快速响应,如果一个或多个碎片失败,以下 API 将响应部分结果:
Responses containing partial results still provide a 200 OK HTTP status code. Shard failures are indicated by the timed_out and _shards fields of the response header.
包含部分结果的响应仍然提供200个 OK HTTP 状态码。Shard failures 由响应标头的 timeout 和 _shards 字段指示。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2022-05-30 Go从入门到精通——结构体(struct)——示例:使用匿名结构体分离 JSON 数据
2022-05-30 Go从入门到精通——结构体(struct)——类型内嵌和结构体内嵌
2022-05-30 Go从入门到精通——结构体(struct)——示例:使用事件系统实现事件的响应和处理
2022-05-30 Go从入门到精通——结构体——为类型添加方法
2022-05-30 Go从入门到精通——结构体(struct)——示例:二维矢量模拟玩家移动
2022-05-30 Go语言从入门到精通——结构体(struct)——方法