


Kubernetes——Pod资源亲和调度
Pod资源亲和调度
出于高效通信的需求,偶尔需要把一些 Pod 对象组织在相似的位置(同一节点、机架、区域或地区等),如某业务的前端 Pod 和后端 Pod 等,此时可以将这些 Pod 对象间的关系称为亲和性。
偶尔,出于安全或分布式等原因也有可能需要将一些 Pod 对象在其运行的位置上隔离开来,如在每个区域运行一个应用代理 Pod 对象等,此时可把这些 Pod 对象间的关系称为反亲和性(anti-affinity)。
Kubernetes 调度器通过内建的 MatchInterPodAffinity 预选策略为这种调度方式完成节点预选,并基于 InterPodAffinityPriority 优选函数进行各节点的优先级评估。
一、位置拓扑
Pod亲和性调度需要各相关的 Pod 对象运行于“同一位置”,而反亲和性调度则要求它们不能运行于“同一位置”。何谓同一位置?事实上,它们取决于节点的位置拓扑,拓扑的方式不同。
如果以基于各节点的 kubernetes.io/hostname 标签作为评判标准,那么很显然,“同一位置” 意味着同一个节点,不同节点即不同的位置,如图所示:
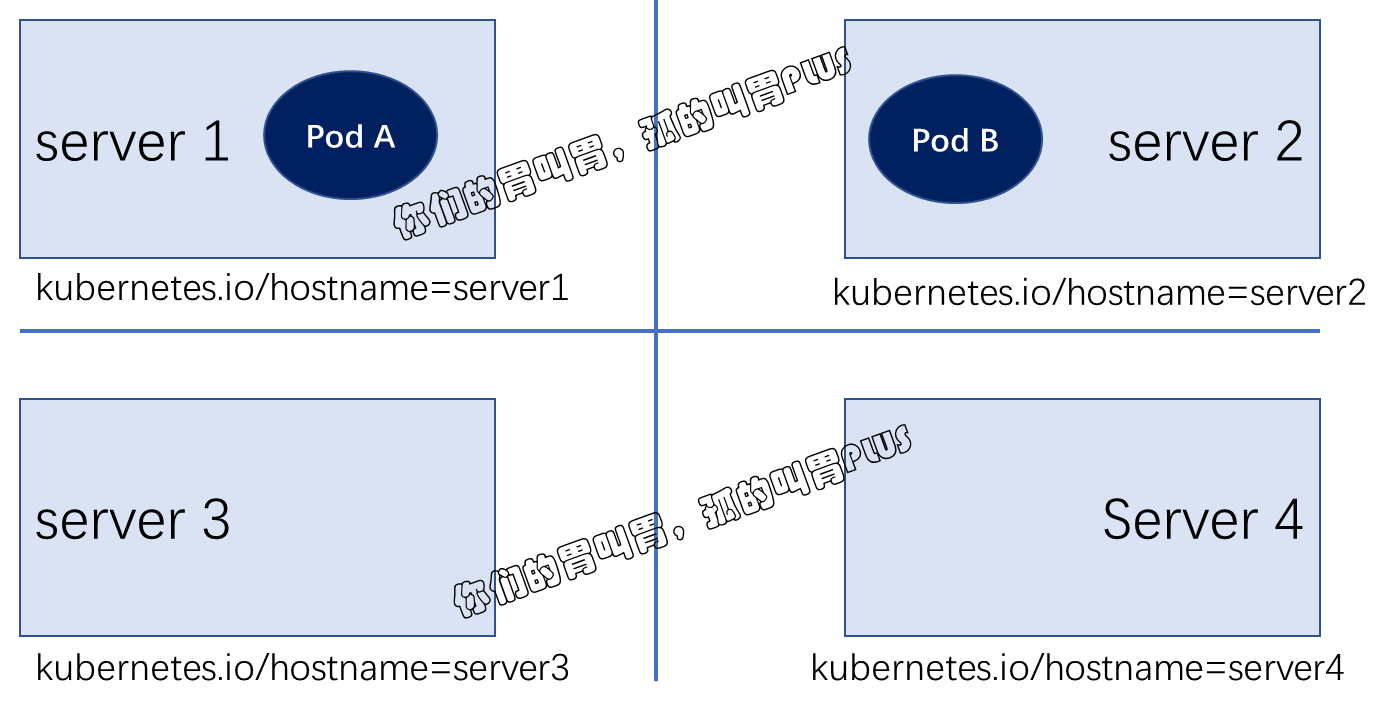
在定义 Pod 对象的亲和性与反亲和性时,需要借助于标签选择器来选择被依赖的 Pod 对象,并根据选出的 Pod 对象所在的节点的标签来判定 "同一位置" 的具体意义。
二、Pod硬亲和调度
Pod 强制约束的亲和性调度也使用 requiredDuringSchedulinglgnoredDuringExecution 属性进行定义。Pod 亲和性用于描述一个 Pod 对象与具有某特征的现存 Pod 对象运行位置的依赖关系,因此,测试使用 Pod 亲和性约束,需要事先存在被依赖的Pod对象,它们具有特别的识别标签。例如创建一个有着标签 app=tomcat 的 Deployment 资源部署一个 Pod 对象:
1 | kubectl run tomcat -l app=tomcat --image tomcat:alpine |
下面的资源配置清单(required-podAffinity-pod1.yaml)中定义了一个 Pod 对象,它通过 labelSelector 定义的标签选择器挑选感兴趣的现存 Pod 对象,而后根据挑选出的 Pod 对象所在节点的标签 "kubernetes.io/hostname" 来判断同一位置的具体含义,并将当前 Pod 对象调度至这一位置的某节点之上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | apiVersion: v1kind: Podmetadata: name: with-pod-affinity-1spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app, operator: In, values: ["tomcat"]} topologyKey: kubernetes.io/hostname containers: - name: nginx image: nginx |
事实上,kubernetes.io/hostname 标签是 Kubernetes 集群节点的内建标签,它的值为当前节点的节点主机名称标识,对于各个节点来说,各有不同。因此,新建的 Pod 象将被部署至被依赖的Pod 对象的同一节点上,requiredDuringSchedulingIgnoredDuringExecution 表示这种亲和性为强制约束。
1 2 | kubectl apply -f required-podAffinity-pod1.yamlkubectl get pods -o wide |
基于单一节点的 Pod 亲和性只在极个别的情况下才有可能会用到,较为常用的通常是基于同一地区 region、区域 zone 或机架 rack 的拓扑位置约束。例如部署应用程序服务 myapp 与数据库 db 服务相关的 Pod 时,db Pod 可能会部署于如上图所示的 foo 或 bar 这两个区域中的某节点之上,依赖于数据服务的 myapp Pod 对象可部署于 db Pod 所在区域内的节点上。当然,如果 db Pod 在两个区域 foo 和 bar 中各有副本运行,那么 myapp Pod 将可以运行于这两个区域的任何节点之上。
例如,创建具有两个拥有标签为 "app=db" 的副本 Pod 作为被依赖的资源,它们可能运行类似下图所示的三个节点中的任何一个或两个节点上,本示例中它们凑巧运行于两个 zone 标签值不同的节点上:
1 2 | kubectl run db -l app=db --image=redis:alpin --replicas=2kubectl get pods -l app=db -o wide -w |
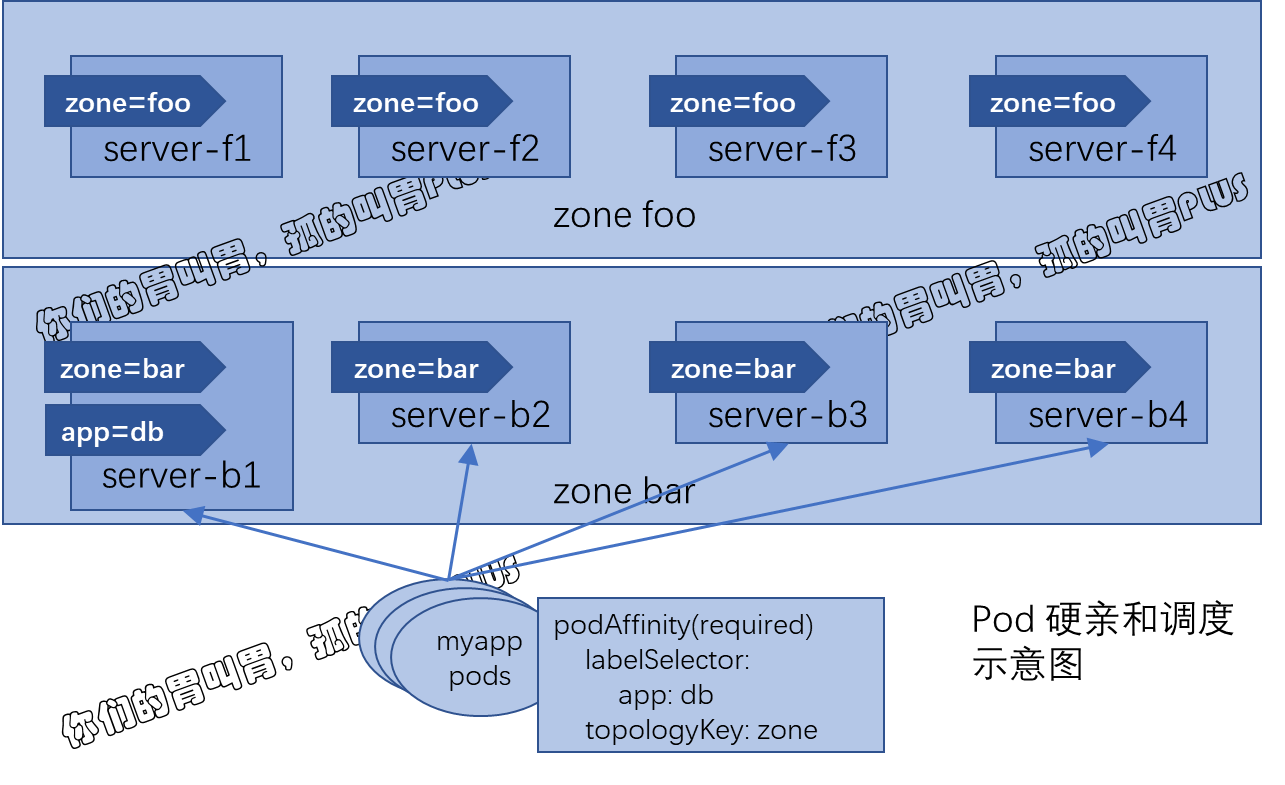
于是,依赖于亲和于这两个 Pod 的其他 Pod 对象可运行于 zone 标签值为 foo 和 bar 的区域内的所有节点之上。下面的资源清单(deploy-with-required-podAffinity.yaml)中正是定义了这样一些 Pod 资源,它们由 Deployment 控制器所创建:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | apiVersion: apps/v1kind: Deploymentmetadata: name: myapp-with-pod-affinityspec: replicas: 3 selector: matchLabels: app: myapp template: metadata: name: myapp labels: app: myapp spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app, operator: In, values: ["db"]} topologyKey: zone containers: - name: nginx image: nginx |
在调度示例中的 Deployment 控制器创建的 Pod资 源时,调度器首先会基于标签选择器查询拥有标签 "app=db" 的所有 Pod 资源,接着获取到它们分别所属的节点的 zone 标签值,接下来再查询拥有匹配这些标签值的所有节点,从而完成节点预选。而后根据优选函数计算这些节点的优先级,从而挑选出运行新建 Pod 对象的节点。
需要注意的是,如果节点上的标签在运行时发生了更改,以致它不再满足 Pod 上的亲和性规则,但该 Pod 还将继续在该节点上运行,因此它仅会影响新建的 Pod 资源;另外,labelSelector 属性仅匹配与被调度器的 Pod 在同一名称空间中的 Pod 资源,不过也可以通过为其添加 namespace 字段以指定其他名称空间 。
三、Pod 软亲和调度
类似于节点亲和性机制,Pod 也支持使用 preferredDuringSchedulinglgnoredDuringExecution 属性定义柔性亲和机制,调度器会尽力确保满足亲和约束的调度逻辑,然而在约束条件不能得到满足时,它也允许将 Pod 对象调度至其他节点运行。下面是一个使用了 Pod 软亲和性调度机制的资源配置清单示例(deploy-with-preferred-podAffinity.yaml):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | apiVersion: apps/v1kind: Deploymentmetadata: name: myapp-with-preferred-pod-affinityspec: replicas: 3 selector: matchLabels: app: myapp template: metadata: name: myapp labels: app: myapp spec: affinity: podAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 80 podAffinityTerm: labelSelector: matchExpressions: - {key: app, operator: In, values: ["cache"]} topologyKey: zone - weight: 20 podAffinityTerm: labelSelector: matchExpressions: - {key: app, operator: In, values: ["db"]} topologyKey: zone containers: - name: nginx image: nginx |
它定义了两组亲和性判定机制,一个是选择 cache Pod 所在节点的 zone 标签,并赋予了较高的权重 80,另一个是选择 db Pod 所在节点的 zone 标签,它有着略低的权重 20。于是,调度器会将目标节点分为四类 :cache Pod 和 db Pod 同时所属的 zone、cache Pod 单独所属的 zone、db Pod 单独所属的 zone,以及其他所有的 zone。
四、Pod反亲和调度
podAffinity 用于定义 Pod 对象的亲和约束,对应地,将其替换为 podAntiAffinty 即可用于定义Pod对象的反亲和约束。不过,反亲和性调度一般用于分散同一类应用的 Pod 对象等,也包括将不同安全级别的 Pod 对象调度至不同的区域、机架或节点等。下面的资源配置清单中定义了由同一 Deployment 创建但彼此基于节点位置互斥的 Pod 对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | apiVersion: apps/v1kind: Deploymentmetadata: name: myapp-with-pod-anti-affinityspec: replicas: 4 selector: matchLabels: app: myapp template: metadata: name: myapp labels: app: myapp spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app, operator: In, values: ["myapp"]} topologyKey: kubernetes.io/hostname containers: - name: nginx image: nginx |
由于定义的强制性反亲和和约束,因此,创建的 4 个 Pod 副本必须运行于不同的节点中。不过,本集群中一共只存在 3 个节点,因此,必然地会有一个 Pod 对象处于 Pending 状态。
Pod 反亲和调度也支持使用柔性约束机制,在调度时,它将尽量不把位置相斥的 Pod 对象调度于同一位置,但是,当约束关系无法得到满足时,也可以违反约束而调度。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2021-07-06 云原生监控系统Prometheus——k8s集群中Prometheus-Operator安装Prometheus+Grafana
2021-07-06 云原生监控系统Prometheus——Prometheus入门