


Kubernetes——节点亲和调度
节点亲和调度
节点亲和性,是调度程序用来确定 Pod 对象调度位置的一组规则,这些规则基于节点上的自定义标签和 Pod 对象上指定的标签选择器进行定义。
节点亲和性允许 Pod 对象定义针对一组可以调度于其上的节点的亲和性或反亲和性,不过,它无法具体到某个特定的节点。例如,将 Pod 调度至有着特殊 CPU 的节点或一个可用区域内的节点之上。
定义节点亲和性规则时有 2 种类型的节点亲和性规则:
- 硬亲和性(required):实现是强制性的,它是 Pod 调度时必须要满足的规则,不存在满足规则的节点上,Pod 对象会被置位 Pending 装填。
- 软亲和性(preferred):实现是一种柔性调度限制,它倾向于将 Pod 对象运行于某类特定的节点之上,而调度器也将尽量满足此需求,但在无法满足调度需求时,它将退而其次地选择一个不匹配规则的节点。
定义节点亲和性规则的关键点有两个,一是为节点配置合乎需求的标签,另一个是为Pod对象定义合理的标签选择器,从而能够基于标签选择出符合期望的目标节点。不过preferredDuringSchedulingIgnoredDuringExecution 和 requiredDuringSchedulingIgnoredDuringExecution 名字中的后半段字符串 IgnoredDuringExecution 隐含的意义所指,在 Pod 资源基于节点亲和性规则调度至某节点之后,节点标签发生了改变而不再符合此节点亲和性规则时,调度器不会将 Pod 对象从此节点上移除,因为它仅对新建的Pod对象生效。节点亲和性模型如下:
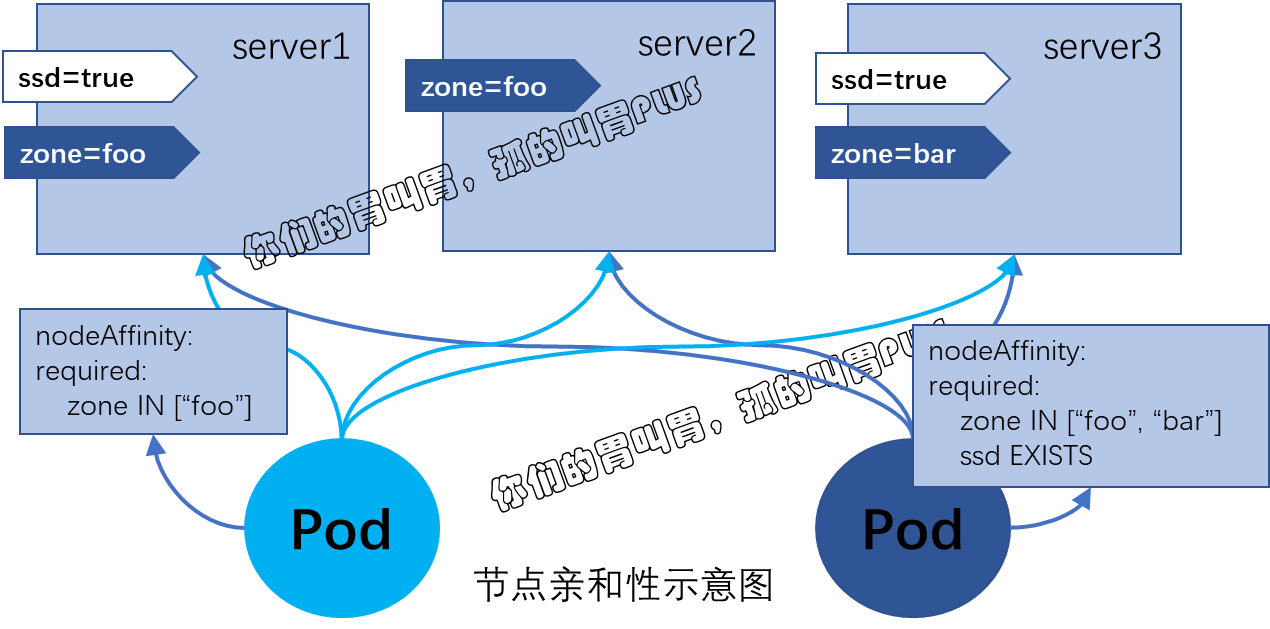
一、节点硬亲和性
为 Pod 对象使用 nodeSelector 属性可以基于节点标签匹配的方式将 Pod 对象强制调度至某一类特定的节点之上。不过它仅能基于简单的等值关系定义标签选择器,而 nodeAffinity 中支持使用 matchExpressions 属性构建更为复杂的标签选择机制。
例如,下面的配置清单示例(required-nodeAffinty-pod.yaml)中定义的 Pod 对象,其使用节点应亲和规则可将当前 Pod 对象调度至拥有 zone 标签且其值为 foo 的节点之上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | apiVersion: v1kind: Podmetadata: name: with-required-nodeaffinityspec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - {key: zone, operator: In, values: ["foo"]} containers: - name: nginx image: nginx |
将上面配置清单中定义的资源创建于集群中,由其状态信息可知它处于 Pending 阶段,这是由于强制型的节点亲和性和限制场景中不存在能够满足匹配条件的节点所致。
1 2 3 4 5 | # kubectl apply -f required-nodeAffinity-pod.yaml pod/with-required-nodeaffinity created# kubectl get pods with-required-nodeaffinity NAME READY STATUS RESTARTS AGEwith-required-nodeaffinity 0/1 Pending 0 8s |
“kubectl describe” 命令显示的资源详细信息 Event 字段中也给出了具体的原因:
1 2 3 4 5 6 | # kubectl describe pods with-required-nodeaffinity...Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector. |
接下来,我们为各个节点设置节点标签,这也是设置节点亲和性的前提之一:
1 2 3 4 5 6 | # kubectl label node k8s-node-01 zone=foonode/k8s-node-01 labeled# kubectl label node k8s-node-02 zone=foonode/k8s-node-02 labeled# kubectl label node k8s-node-03 zone=barnode/k8s-node-03 labeled |
设置完成后,Pod 对象 with-required-nodeaffinity 的详细信息事件中已然出现成功调度至 k8s-node-01 节点信息,具体如下所示:
1 2 3 4 5 6 7 | # kubectl describe pods with-required-nodeaffinity...Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector. Normal Scheduled <unknown> default-scheduler Successfully assigned default/with-required-nodeaffinity to k8s-node-01 |
在定义节点亲和性时,requiredDuringSchedulinglgnoredDuringExecution 字段的值是一个对象列表,用于定义节点硬亲和性,它可由一到多个 nodeSelectorTerm 定义的对象组成, 彼此间为“逻辑或”的关系,进行匹配度检查时,在多个 nodeSelectorTerm 之间只要满足其中之一即可。nodeSelectorTerm 用于定义节点选择器条目,其值为对象列表,它可由一个或多个 matchExpressions 对象定义的匹配规则组成,多个规则彼此之间为“逻辑与”的关系, 这就意味着某节点的标签需要完全匹配同一个 nodeSelectorTerm 下所有的 matchExpression 对象定义的规则才算成功通过节点选择器条目的检查。而 matchExmpressions 又可由一到多个标签选择器组成,多个标签选择器彼此间为“逻辑与”的关系 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | apiVersion: v1kind: Podmetadata: name: with-required-nodeaffinity-2spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - {key: zone, operator: In, values: ["foo", "bar"]} - {key: ssd, operator: Exists, values: []} containers: - name: nginx image: nginx |
构建标签选择器表达式中支持使用操作符有 In、Notln、 Exists、DoesNotExist、Lt 和 Gt 等:
-
- In:label的值在某个列表中。
- NotIn:label的值不在某个列表中。
- Gt:label的值大于某个值。
- Lt:label的值小于某个值。
- Exists:某个label存在。
- DoesNotExist:某个label不存在。
另外,调度器在调度 Pod 资源时,节点亲和性(MatchNodeSelector)仅是其节点预选策略中遵循的预选机制之一,其他配置使用的预选策略依然正常参与节点预选过程。 例如将上面资源配置清单示例中定义的Pod对象容器修改为如下内容并进行测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | apiVersion: v1kind: Podmetadata: name: with-required-nodeaffinity-3spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - {key: zone, operator: In, values: ["foo", "bar"]} - {key: ssd, operator: Exists, values: []} containers: - name: nginx image: nginx resources: requests: cpu: 6 memory: 20Gi |
在预选策略 PodFitsResources 根据节点资源可用性进行节点预选的过程中,它会获取给定节点的可分配资源量(资源问题减去已被运行于其上的各Pod对象的requests属性之和),去除那些无法容纳新Pod对象请求的资源量的节点,如果资源不够,同样会调度失败。
由上述操作过程可知,节点硬亲和性实现的功能与节点选择器 nodeSelector 相似, 但亲和性支持使用匹配表达式来挑选节点,这一点提供了灵活且强大的选择机制,因此可被理解为新一代的节点选择器。
二、节点软亲和性
节点软亲和性为节点选择机制提供了一种柔性控制逻辑,被调度的 Pod 对象不再是“必须”而是“应该”放置于某些特定节点之上,当条件不满足时它也能够接受被编排于其他不符合条件的节点之上。另外,它还为每种倾向性提供了weight 属性以便用户定义其优先级,取值范围是1 ~ 100,数字越大优先级越高。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | apiVersion: apps/v1kind: Deploymentmetadata: name: myapp-deploy-with-node-affinityspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: name: nginx labels: app: nginx spec: affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 60 preference: matchExpressions: - {key: zone, operator: In, values: ["foo"]} - weight: 30 preference: matchExpressions: - {key: ssd, operator: Exists, values: []} containers: - name: nginx image: nginx |
示例中,Pod 资源模板定义了节点亲和性以选择运行在拥有 zone=foo 和 ssd 标签(无论其值为何)的节点上,其中 zone=foo 是更为重要的倾向性规则,它的权重为 60,相比较来说,ssd 标签就没有那么关键了,它的权重为 30。
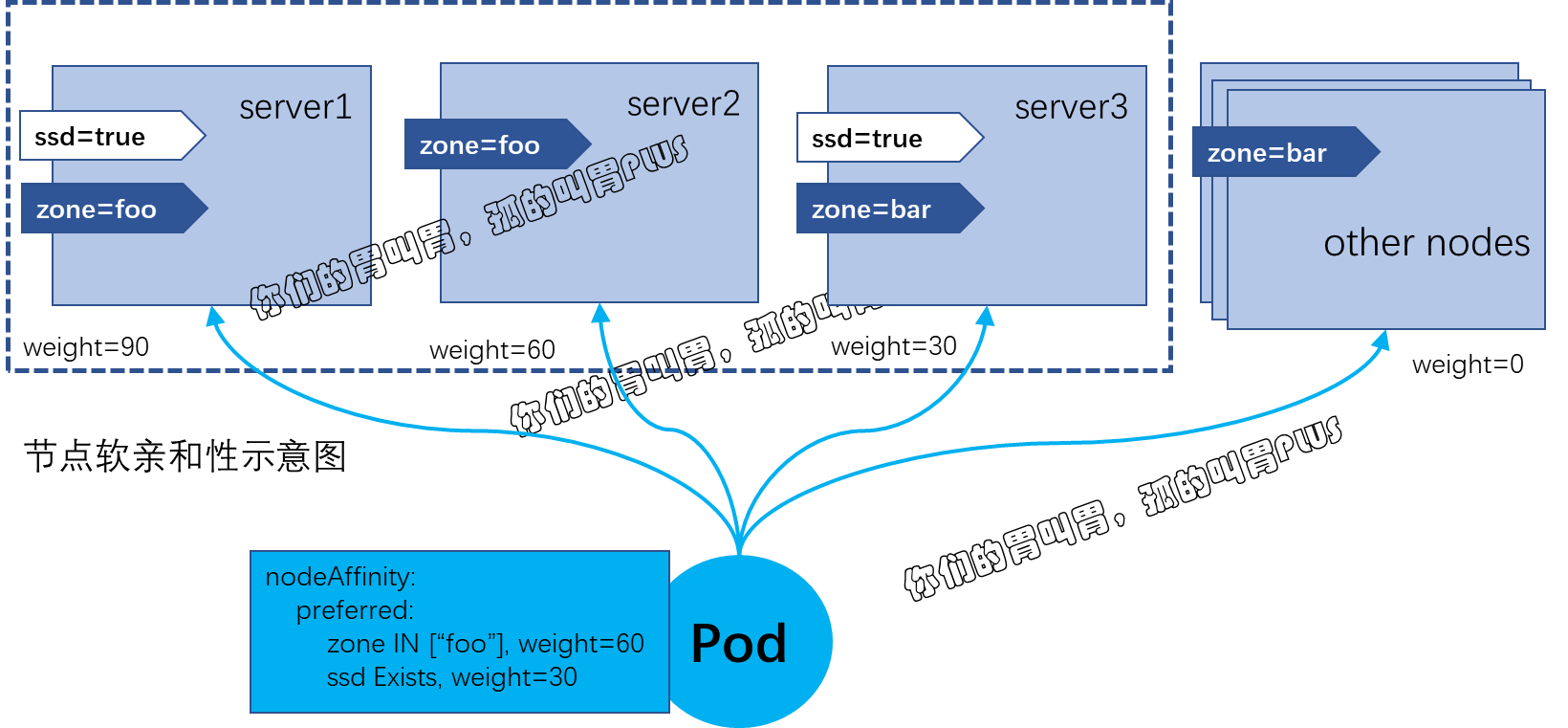
示例环境共有三个节点,相对于定义的节点亲和性规则来说,它们所拥有的倾向性权重分别如图所示。
在创建需要 3 个 Pod 对象的副本时,其运行效果为三个 Pod 对象被分散运行于集群中的三个节点之上,而非集中运行于某一个节点 。
之所以如此,是因为使用了节点软亲和性的预选方式,所有节点均能够通过调度器上 MatchNodeSelector 预选策略的筛选,因此,可用节点取决于其他预选策略的筛选结果。在第二阶段的优选过程中,除了 NodeAffinityPriority 优选函数之外,还有其他几个优选函数参与优先级评估,尤其是 SelectorSpreadPriority,它会将同一个 ReplicaSet 控制器管控的所有Pod对象分散到不同的节点上运行以抵御节点故障带来的风险。不过,这种节点亲和性的权重依然在发挥作用,如果把副本数量扩展至越过节点数很多,如15个, 那么它们将被调度器以接近节点亲和性权重比值90:60:30 的方式分置于相关的节点之上。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2021-07-06 云原生监控系统Prometheus——k8s集群中Prometheus-Operator安装Prometheus+Grafana
2021-07-06 云原生监控系统Prometheus——Prometheus入门