
Kubernetes——Kubernetese调度器概述
Kubernetese调度器概述
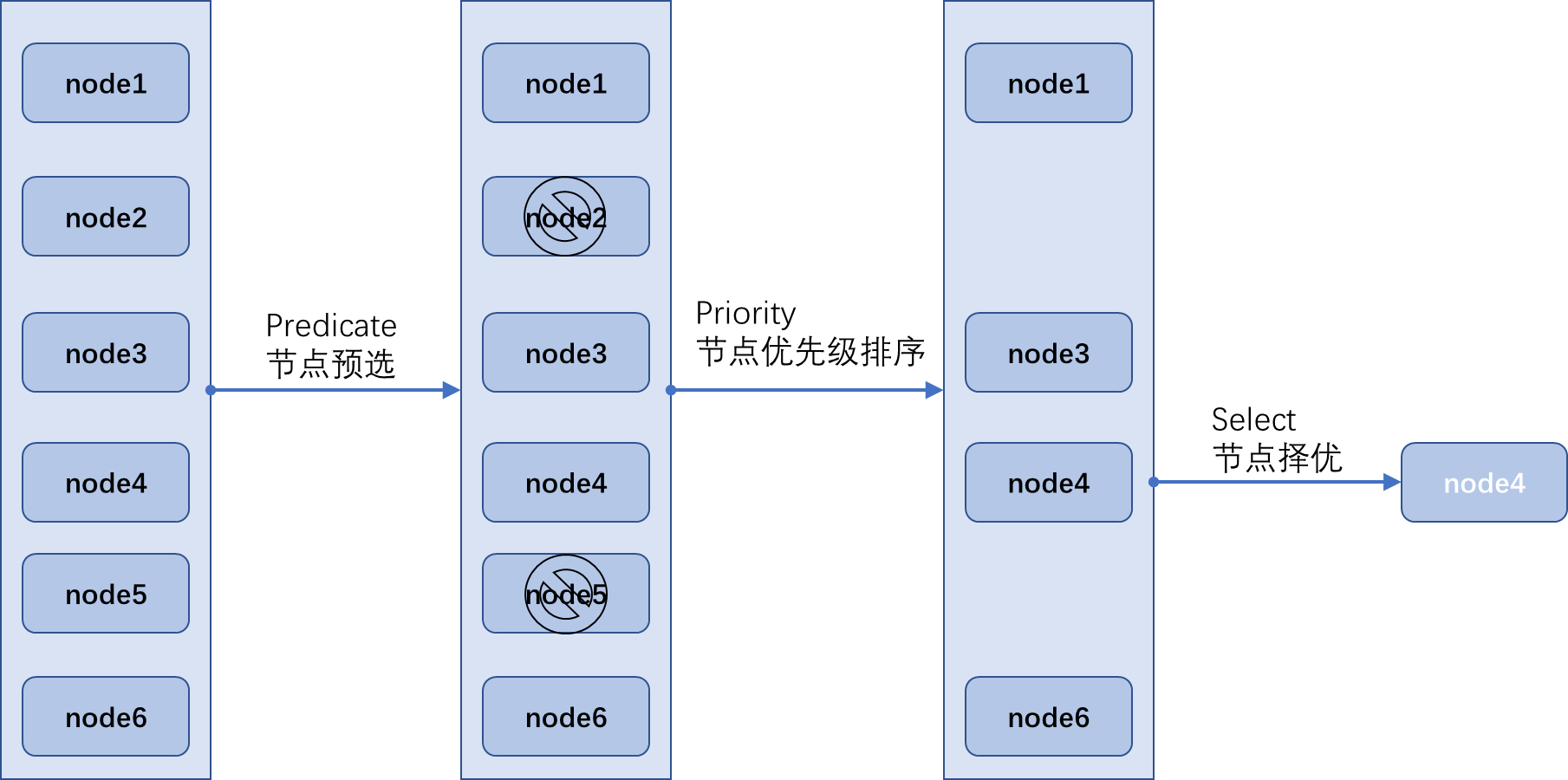
API Server 接受客户端提交 Pod 对象创建请求后的操作过程中,有一个重要的步骤是由调度器程序(kube-scheduler)从当前集群中选择一个可用的最佳节点来接收并运行它,通常是默认的调度器(default-scheduler)负责执行此类任务。对于每个待创建的 Pod 对象来说,调度过程通常分为三个阶段—— 预选、优选和选定三个步骤,以筛选执行任务的最佳节点。
Kubernetes 系统的核心任务在于创建客户端请求创建的 Pod 对象并确保其以期望的状态运行。创建 Pod 对象时,调度器 scheduler 负责为每一个未经调度的 Pod 资源、基于一系列的规则集从集群中挑选一个合适的节点来运行它,因此它也可以称作 Pod 调度器。调度过程中,调度器不会修改 Pod 资源,而是从中读取数据,并根据配置的策略挑选出最适合的节点 ,而后通过API 调用将 Pod 绑定至挑选出的节点之上以完成调度过程。
Kubernetes 内建了适合绝大多数场景中 Pod 资源调度需求的默认调度器,它支持同时使用算法基于原生及可定制的工具来选出集群中最适合运行当前 Pod 资源的一个节点,其核心目标是: 基于资源可用性将 Pod 资源公平地分布于集群节点之上。
目前,平台提供的默认调度也称为 "通用调度器",它通过三个步骤完成调度操作:
- 阶段预选(Predicate):基于一系列预选规则(如 PodFirstResource 和 MatchNode-Selector 等)对每个节点进行检查,将那些不符合条件的节点过滤掉从而完成节点预选。
- 节点优先选择排序(Priority):对预选出的节点进行优先级排序,以便选出最适合运行 Pod 对象的节点。
- 节点择优(Slect):从优先级排序结果中挑选出优先级最高的节点运行 Pod 对象,当此类节点多余一个时,则从中随机选择一个。
有些特殊的Pod资源需要运行在特定的节点之上,或者说对某类节点有着特殊偏好(如那些有着SSD、GPU等特殊硬件的节点),以便更好地匹配容器应用的运行需求。另外,有的 Pod 资源与其他Pod 资源存在着特定的关联性,它们运行于同一节点以便能够实现更高效的协同效果等。 此种场景可通过组合节点标签,以及 Pod 标签或标签选择器等来激活特定的预选策略以完成高级调度,如MatchlnterPodAffinity、 MatchNodeSelector 和 PodToleratesNodeTaints 等预选策略,它们用于为用户提供自定义 Pod 亲和性或反亲和性、节点亲和性以及基于污点及容忍度的调度机制。不过,未激活特定的预选策略时,Pod资源对节点便没有特殊偏好,相关的预选策略无法在节点预选过程中真正发挥作用。
一、常用的预选策略
简单来说,预选策略就是节点过滤器,例如节点标签必须能够匹配到 Pod 资源的标签选择器(由 MatchNodeSelector 实现的规则),以及 Pod 容器的资源请求量不能大于节点上剩余的可分配资源(由 PodFitsResources 实现的规则 )等。 执行预选操作时,调度器将对每个节点基于配置使用的预选策略以特定次序逐一筛查,并根据一票否决制进行节点淘汰。 若预选后不存在任何一个满足条件的节点,则Pod被置于 Pending 状态,直到至少有一个节点可用为止。
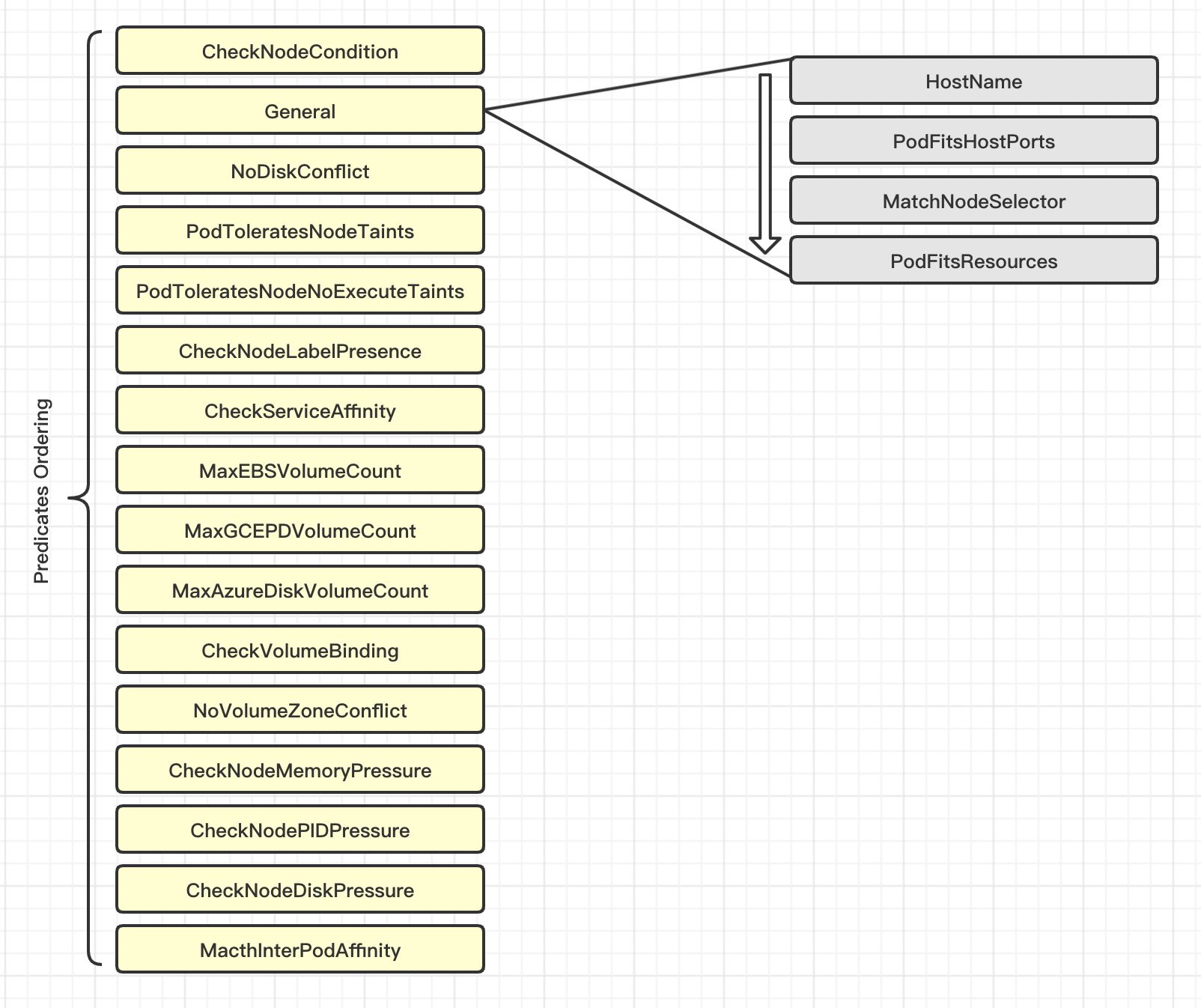
- CheckNodeCondition:检查是否可以在节点报告磁盘、网络不可用或未准备好的情况下将
Pod对象调度其上。 - HostName:如果
Pod对象拥有spec.hostname属性,则检查节点名称字符串是否和该属性值匹配。 - PodFitsHostPorts:如果
Pod对象定义了ports.hostPort属性,则检查Pod指定的端口是否已经被节点上的其他容器或服务占用。 - MatchNodeSelector:如果
Pod对象定义了spec.nodeSelector属性,则检查节点标签是否和该属性匹配。 - NoDiskConflict:检查
Pod对象请求的存储卷在该节点上可用。 - PodFitsResources:检查节点上的资源(CPU、内存)可用性是否满足
Pod对象的运行需求。 - PodToleratesNodeTaints:如果
Pod对象中定义了spec.tolerations属性,则需要检查该属性值是否可以接纳节点定义的污点(taints)。 - PodToleratesNodeNoExecuteTaints:如果
Pod对象定义了spec.tolerations属性,检查该属性是否接纳节点的NoExecute类型的污点。 - CheckNodeLabelPresence:仅检查节点上指定的所有标签的存在性,要检查的标签以及其可否存在取决于用户的定义。
- CheckServiceAffinity:根据当前
Pod对象所属的Service已有其他Pod对象所运行的节点调度,目前是将相同的Service的Pod对象放在同一个或同一类节点上。 - MaxEBSVolumeCount:检查节点上是否已挂载
EBS存储卷数量是否超过了设置的最大值,默认值:39 - MaxGCEPDVolumeCount:检查节点上已挂载的
GCE PD存储卷是否超过了设置的最大值,默认值:16 - MaxAzureDiskVolumeCount:检查节点上已挂载的
Azure Disk存储卷数量是否超过了设置的最大值,默认值:16 - CheckVolumeBinding:检查节点上已绑定和未绑定的
PVC是否满足Pod对象的存储卷需求。 - NoVolumeZoneConflct:在给定了区域限制的前提下,检查在该节点上部署
Pod对象是否存在存储卷冲突。 - CheckNodeMemoryPressure:在给定了节点已经上报了存在内存资源压力过大的状态,则需要检查该
Pod是否可以调度到该节点上。 - CheckNodePIDPressure:如果给定的节点已经报告了存在
PID资源压力过大的状态,则需要检查该Pod是否可以调度到该节点上。 - CheckNodeDiskPressure:如果给定的节点存在磁盘资源压力过大,则检查该
Pod对象是否可以调度到该节点上。 - MatchInterPodAffinity:检查给定的节点能否可以满足
Pod对象的亲和性和反亲和性条件,用来实现Pod亲和性调度或反亲和性调度。
- CheckNodeCondition:检查是否可以在节点报告磁盘、网络不可用或未准备好的情况下将
如上的各预选策略中,CheckNodeLabelPresence和CheckServiceAffinity可以接受特定的配置参数以便在预选过程中融合用户自定义的调度逻辑,这类策略也可称为可配置策略,而余下那些不可接受配置参数的策略也统一称为静态策略。另外,NoDiskConflict、 PodToleratesNodeNoExecuteTaints、 CheckNodeLabelPresence和CheckServiceAffinity没有包含在默认的预选策略中 。
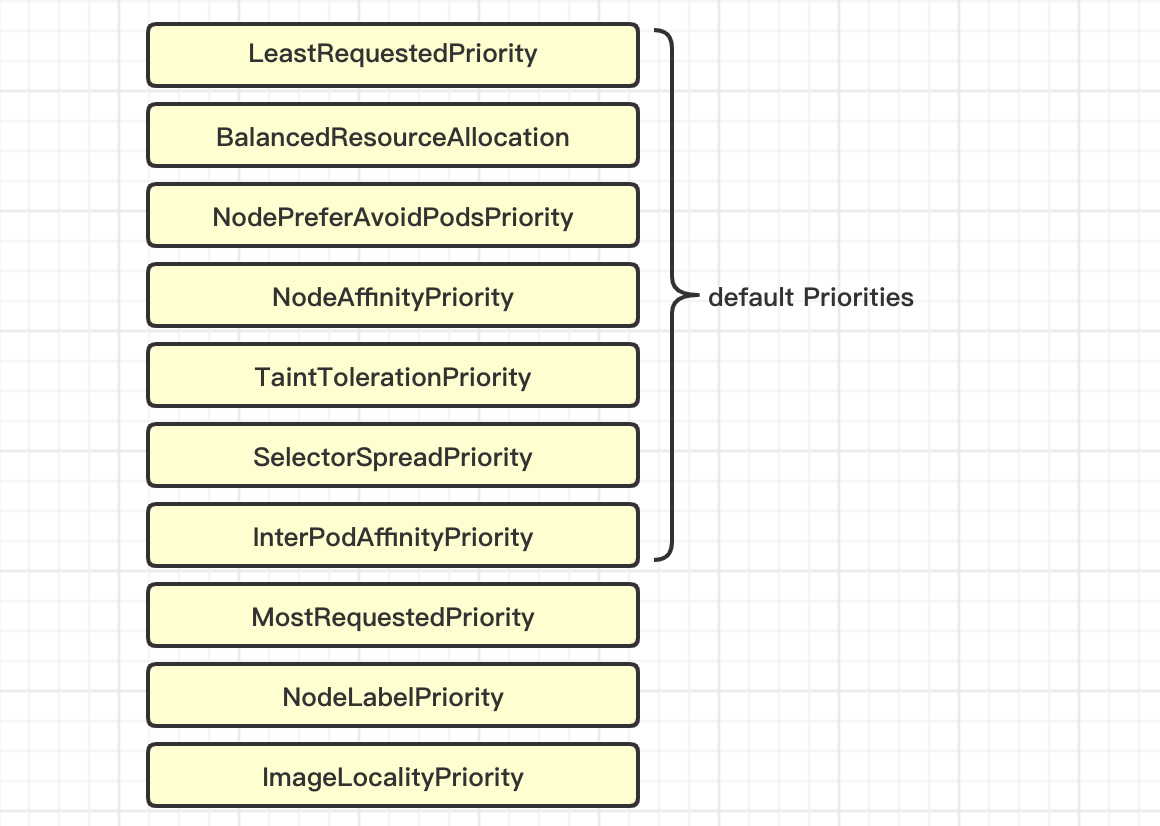
二、常用的优选函数
预选策略筛选并生成一个节点列表后即进入第二阶段的优选过程。在这个过程中,调度器向每个通过预选的节点传递一系列的优选函数(如 BalancedResourceAllocation 和 TaintTolerationPriority 等)来计算其优先级分值 ,优先级分值介于0到10之间,其中0表示不适用,10表示最适合托管该Pod对象。
另外,调度器还支持为每个优选函数指定一个简单的由正数值表示的权重,进行节点优先级分值的计算时,它首先将每个优选函数的计算得分乘 以其权重(大多数优先级的默认权重为 1 ),然后将所有优选函数的得分相加从而得出节点的最终优先级分值。 权重属性赋予了管理员定义优选函数倾向性的能力。 下面是每个节点的最终优先级得分的计算公式:
finalScoreNode = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) + ......
下面是各优选函数的相关说明:
- LeastRequestedPriority:由节点空闲资源与节点总容量的比值计算而来,即由
CPU或内存资源的总容量减去节点上已有Pod对象需求的容量总和,再减去当前要创建的Pod对象的需求容量得到的结果除以总容量。CPU和内存具有相同的权重,资源空闲比例越高的节点得分就越高,其计算公式为:(cpu((capacity - sum(r巳quested)) * IO/capacity) + memory(( capacity sum( requested)) * I O/capacity))/2。 - BalancedResourceAllocation:以
CPU和内存资源占用率的相近程序作为评估标准, 二者越接近的节点权重越高 。 该优选级函数不能单独使用,它需要与LeastRequestedPriority组合使用来平衡优化节点资源的使用状况,以选择那些在部署当前Pod资源后系统资源更为均衡的节点 。 - NodePreferAvoidPodsPriority:此优选级函数权限默认为
10000,它将根据节点是否设置了注解信息来计算其优选级。 计算方式是:给定的节点无此注解信息时,其得分为10乘以权重10000;存在此注解信息时,对于那些由ReplicationController或ReplicaSet控制器管控的Pod对象的得分为0,其他Pod对象会被忽略(得最高分)。 - NodeAffinityPriority:基于节点亲和性调度偏好进行优先级评估,它将根据
Pod资源中的nodeSelector对给定节点进行匹配度检查,成功匹配到的条目越多则节点得分越高。不过,其评估过程使用首选而非强制型的PreferredDuringSchedulinglgnoredDuringExecuti on标签选择器。 - TaintTolerationPriority:基于
Pod资源对节点的污点容忍调度偏好进行其优先级的评估,它将Pod对象的tolerations列表与节点的污点进行匹配度检查,成功匹配的条目越 多, 则节点得分越低。 - SelectorSpreadPriority:首先查找与当前
Pod对象匹配的Service、ReplicationController、ReplicaSet ( RS )和StatefulSet,而后查找与这些选择器匹配的现存Pod对象及其所在的节点,则运行此类Pod对象越少的节点得分将越高。 简单来说,如其名称所示,此优选函数会尽量将同一标签选择器匹配到的Pod资源分散到不同的节点上运行。 - InterPodAffinityPriority:遍历
Pod对象的亲和性条目,并将那些能够匹配到给定节点的条目的权重相加,结果值越大的节点得分越高。 - MostRequestedPriority:与优选函数
LeastRequestedPriority的评估节点得分的方法相似,不同的是,资源占用比例越大的节点,其得分越高 。 - NodeLabelPriority:根据节点是否拥有特定的标签来评估其得分,而无论其值为何。需要其存在时,拥有相应标签的节点将获得优先级,否则,不具有相应标签的节点将获得优先级。
- ImageLocalityPriority:基于给定节点上拥有的运行当前
Pod对象中的容器所依赖到的镜像文件来计算节点得分,不具有Pod依赖到的任何镜像文件的节点其得分为0,而拥有相应镜像文件的各节点中,所拥有的被依赖到的镜像文件其体积之和越大则节点得分越高。
- LeastRequestedPriority:由节点空闲资源与节点总容量的比值计算而来,即由
Kubernetes的默认调度器以预选、优选、选定机制完成将每个新的Pod资源绑定至为其选出的目标节点上。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号