
Go从入门到精通——变量声明周期——变量能够使用的代码范围(堆、栈和变量逃逸)
变量能够使用的代码范围(堆、栈和变量逃逸)
讨论变量声明周期之前,先来了解下计算机组成里两个非常重要的概念:堆和栈。
1、什么是栈?
栈(stack)是一种拥有特殊规则的线性表数据结构。
1.1、概念
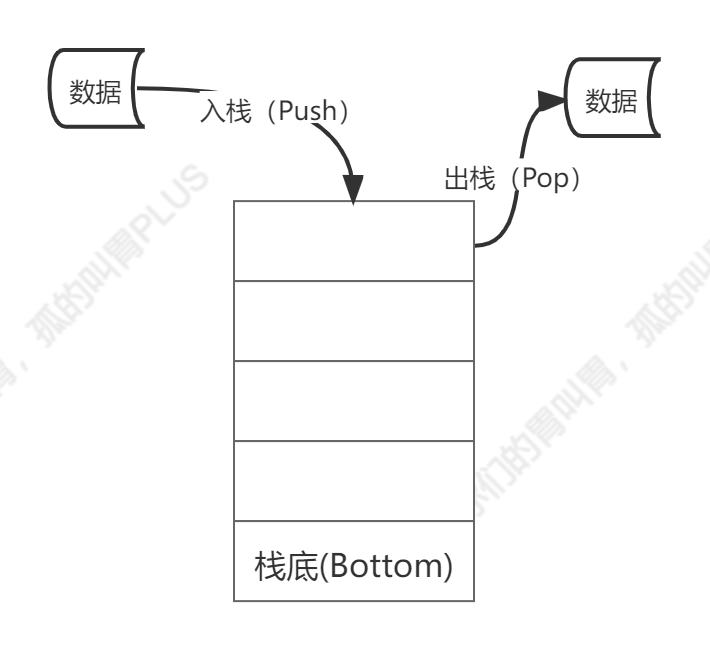
栈只允许往线性表的一端放入数据,之后在这一端取出数据,按照后进先出(LIFO,Last In First Out)的顺序。
往栈中放入元素的过程叫入栈。入栈会增加栈的元素数量,最后放入的元素总是位于栈的顶部,最先放入的元素总是位于栈的底部。
从栈中取出元素时,只能从栈顶部取出。取出元素后,栈的数量会变少。最先放入的元素总是最后被取出,最后放入的元素总是最先被取出。不允许从栈底获取数据,也不允许对栈成员(除栈顶外的成员)进行任何查看和修改操作。
1.2、变量和栈有什么关系?
栈可用于内存分配,栈的分配和回收速度非常快。Go 语言默认情况下会将 变量/函数 分配在栈上,当退出或者结束时,出栈会释放内存,整个分配内存的过程通过栈的分配和回收都会非常的快。
2、什么是堆?
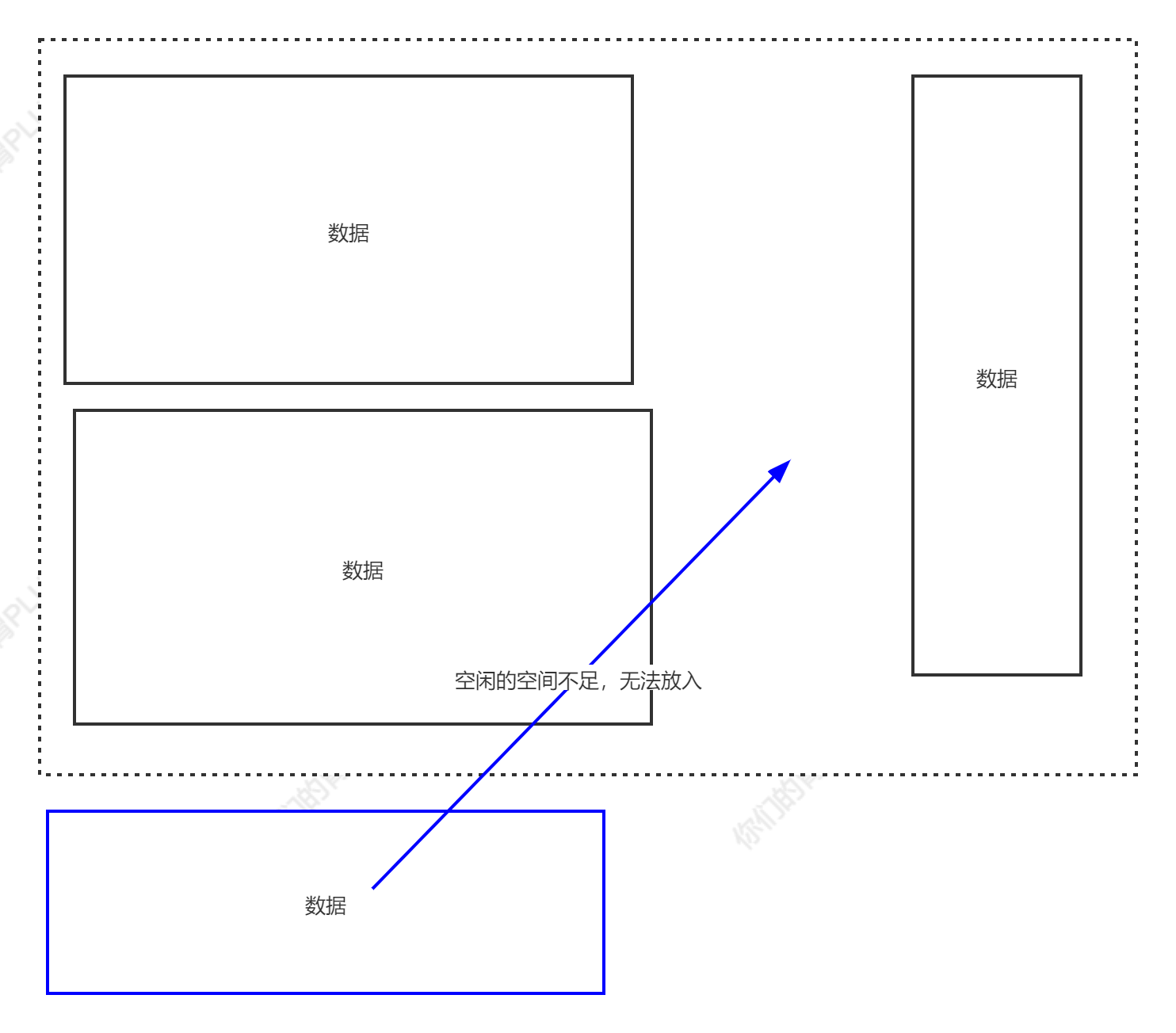
堆在内存分配中类似往一个房间里摆放各种家具,家具的尺寸有大有小。分配内存时,需要找一块足够装下家具的空间再摆放家具。经过反复摆放和腾空家具后,房间里的空间会变得乱七八糟,此时再往空间里摆放家具会存在虽然有足够的空间,但各空间分布在不同的区域,无法有一段连续的空间来摆放家具的问题。此时内存分配器就需要对这些空间进行调整优化。
堆分配内存和栈分配内存相比,堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片。
3、变量逃逸(Escape Analysis)——自动决定变量分配方式,提高运行效率
堆和栈都有各自优缺点,该怎么在编程中处理这个问题呢?
在 C/C++ 语言中,需要开发者自己学习如何进行内存分配,选用怎样的内存分配方式来适应不同的算法需求。比如,函数局部变量尽量使用栈,全局变量、结构体成员使用堆内存分配等。程序员不得不花费很多时间在不同的项目中学习、记忆这些概念并加以实践和使用。
Go 语言将这个过程整合到编译器中,命名为 "变量逃逸分析"。这个技术由编译器分析代码的特征和代码生命周期,决定应该是堆还是使用栈进行内存分配,即 Go 程序员使用了 Go 语言完成了整个工程也不会感受到这个过程。
Go 程序变量会携带有一组校验数据,用来证明它的整个生命周期是否在运行时完全可知。如果变量通过了这些校验,它就可以在栈上分配。否则就说它 "逃逸" 了,必须在堆上分配。
能引起变量逃逸到堆上的典型情况:
- 在方法内把局部变量指针返回。局部变量原本应该在栈中分配,在栈中回收。但是由于返回时被外部引用,因此其生命周期大于栈,则溢出。
- 发送指针或带有指针的值到 channel 中。 在编译时,是没有办法知道哪个 goroutine 会在 channel 上接收数据。所以编译器没法知道变量什么时候才会被释放。
- 在一个切片上存储指针或带指针的值。 一个典型的例子就是 []*string 。这会导致切片的内容逃逸。尽管其后面的数组可能是在栈上分配的,但其引用的值一定是在堆上。
- slice 的背后数组被重新分配了,因为 append 时可能会超出其容量( cap )。 slice 初始化的地方在编译时是可以知道的,它最开始会在栈上分配。如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配。
- 在 interface 类型上调用方法。 在 interface 类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道。想像一个 io.Reader 类型的变量 r , 调用 r.Read(b) 会使得 r 的值和切片b 的背后存储都逃逸掉,所以会在堆上分配。
编译器觉得变量应该分配在堆和栈的原则是:
- 变量是否被取地址。
- 变量是否发生逃逸。
3.1、逃逸分析
package main
import (
"fmt"
)
//本函数测试入口参数和返回值情况
func dummy(b int) int {
//声明一个 c 赋值进入参数并返回
var c int
c = b //C = 0
return c
}
//空函数,什么也不做
func void(){
}
func main(){
//声明 a 变量并打印
var a int
//调用 void() 函数
void()
//打印 a 变量的值和 dummy()函数返回
fmt.Println(a,dummy(0)) // 这里的a值应该是 int 的零值,等于0。
}
代码说明如下:
- 第 8 行,dummy()函数需要传入一个int参数,返回一个int返回值,测试函数参数和返回值分析情况。
- 第 11 行,声明 c 变量,这里演示函数临时变量通过函数返回值返回后的情况。
- 第 16 行,这是一个空函数,测试没有任何参数函数的分析情况。
- 第 23 行,在 main() 中声明 a 变量,测试 main() 中变量的分析情况。
- 第 26 行,调用 void() 函数,没有返回值,测试 void() 调用后的分析情况。
- 第 29 行,打印 a 和 dummy(0)的返回值,测试函数返回值没有变量接收时的分析情况。
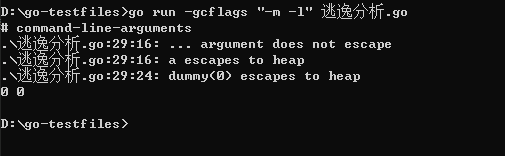
运行命令:go run -gcflags "-m -l" 逃逸分析.go
代码输出,如下图:
程序运行结果分析如下:
- 通过 ".\逃逸分析.go:29:16: ... argument does not escape" => 这句提示是默认的,可以忽略。
- 通过 ".\逃逸分析.go:29:16: a escapes to heap" => 代码输出,可以得到 "a 变量没有发生逃逸,只在方法存在时存在,方法结束时会被收回。"。查看源代码第 29 行:fmt.Println(a,dummy(0)) 和 第 23 行 var a int ,可确认是这样的。
- 通过 ".\逃逸分析.go:29:24: dummy(0) escapes to heap" => 代码输出,可以得到 "dummy(0)的调用逃逸到堆"。查看源代码第 29 行:fmt.Println(a,dummy(0)),由于 dummy() 函数会返回一个整型值,这个值被 fmt.Println 使用后还是会在其声明后继续在 main() 函数中存在。
3.2、取地址发生逃逸
举个例子,使用结构体做数据,了解在堆上分配的情况,代码如下:
package main
import (
"fmt"
)
// 声明空结构体测试结构体逃逸情况
type Data struct {
}
func dummy() *Data {
// 实例化 C 为 Data 类型
var c Data
return &c
}
func main(){
fmt.Println(dummy())
}
代码说明如下:
- 第 7 行,声明了一个空结构体做结构体逃逸分析。
- 第 12 行,将 dummy() 函数的返回值修改为 *Data 指针类型。
- 第 16 行,取函数局部变量 c 的地址并返回。Go 语言的特性允许这样做。
- 第 21 行,打印 dummy() 函数的返回值。
执行逃逸分析:
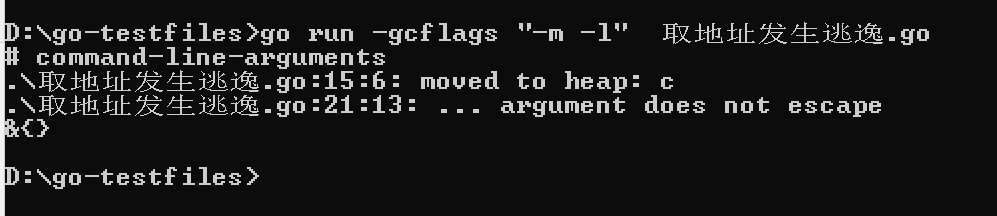
- 通过 ".\取地址发生逃逸.go:15:6: moved to heap: c" => 可以得到 "将 c 移动堆中",通过源码第 15 行 "var c Data",Data 是指针类型,可以得出发生变量逃逸,Go 语言最终选择将 c 的 Data 结构分配在堆上,然后由垃圾回收期去回收 c 的内存。
- 通过 ".\取地址发生逃逸.go:21:13: ... argument does not escape" = > 这句提示是默认的,可以忽略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号