深入理解计算机系统(3.1)---走进汇编的世界
引言
本系列拖了蛮久了,主要是因为LZ写的时候其实刚看到第二章,因此这一段时间快速看了下第三章,并花了点时间沉淀了一下,这才耽误了下来。
本文是3.X系列的第一篇,也是汇编世界的开篇。LZ一直在想如何能让这一系列稍微变得有趣一些,因为第二章实在是太枯燥了,连LZ都觉得无聊至极,不过LZ竟然鬼使神差的把课后题做了不少。汇编这一部分相对而言会好很多,尽管它依然不是我们熟悉的编程语言,但是终归还是语言,而不再是我们几乎不打交道的0和1。
为何要学习汇编语言
对于大部分猿友来说,平时写的都是一些高级程序设计语言,是计算机领域的诸多大神,经过几层的封装才让我们享有了这样的待遇。这样一来,我们在平时的开发过程中,可以省去很多底层的麻烦。试想一下,倘若在你写一个方法的时候,你还需要去操心哪些变量需要放在寄存器,哪些变量放在主存,放在寄存器的话又该放在哪一个里面,放在主存的话又该放在那个内存区域等等这一类底层的问题,以及还要去记各种各样的寄存器名称和它们的作用等等诸如此类的事,你是否会崩溃呢。
因此这不难看出,高级语言给我们带来了很多便捷,但是事情总不是十全十美的,这样所带来的便捷也同时引来了一些问题。这是因为我们看到的代码,在实际执行它们的时候,可能已经面目全非了,所以很多时候会造成一些莫名其妙的问题发生。
举一个小例子,LZ曾经在群里问过类似的问题,这次LZ写一个小程序,各位学过Java的猿友来看看这个程序的结果。
public class Main
{
public static void main(String[] args)
{
Integer a = 127;
Integer b = 127;
Integer c = 128;
Integer d = 128;
System.out.println(a == b);
System.out.println(c == d);
}
}
相信有不少人看不出来这个程序的问题在哪,觉得应该输出两个true就对了。可是这个程序的结果却是一个true和一个false,如果哪位猿友不信的话可以自己试一下。至于原因是什么,各位有兴趣的可以去研究下Java的自动拆装箱,另外再看一下Integer对象的valueOf方法缓存的范围,答案就会自动揭晓。
产生这个问题的根本原因,其实还是因为编译器给开发者蒙上了一层迷雾,导致一些开发人员只知其然,而不知其所以然,他们根本不清楚自己写出来的程序,实际上到底是如何运行的。这样的一层迷雾注定会降低开发者的水平,所以为了提高自己,我们有必要揭开这层迷雾。对于C/C++的开发者来讲,揭开这层迷雾其实就是了解汇编语言的过程。
汇编语言对于C/C++程序猿来讲,就像class文件对于Java程序猿是一样的,因为它们都是编译器处理后的产物,我们可以从下图当中简单的了解一下两者的关联。
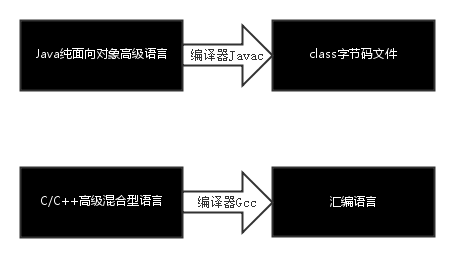
这个图中应该看起来还算比较清晰,其实LZ说了这么多,只是想说一件事,那就是了解汇编语言的知识,对我们平时的开发有着不可忽视的好处,尤其是对于从事C/C++的开发者来说,好处更是无穷无尽的。
可能会有猿友觉得,LZ是一个靠Java吃饭的家伙,了解汇编语言是不是有点多此一举了,毕竟Java语言离汇编还是有点太远了吧。毕竟Java要先编译成class文件,然后交给虚拟机的执行引擎,而虚拟机的执行引擎则是由C/C++来实现的,C/C++又需要经过预处理和GCC编译器的编译才能最终成为汇编语言。这猛地一看,Java确实离汇编语言太远了。
可是LZ想说的是,无论你处于什么样的一个岗位当中,只要你做的事是指挥计算机帮助你完成一些事情,那么你就必须了解计算机如何帮你完成这些事情,否则你就只会指挥,而不会懂得如何去做。不知道如何去做的后果就是,你不会知道如何才能做的更好,反映到现实当中,就是你不知道如何写出更好的程序。这点其实不难理解,试想一下,你都不知道你的程序实际上是如何运行的,你又怎么可能知道怎么写是更好的呢。
初次体会汇编
在编译一段C语言程序的过程中,其实做了很多步骤,比如预编译处理、编译处理、汇编处理以及链接处理。我们要了解的汇编语言,就是在编译处理后的产物。因此我们可以在GCC的编译器当中加入一些参数来控制它只生成汇编语言,而不进行汇编处理和链接处理。
我们看下面这一段简单的C语言代码,假设为sum.c。
int simple(int *xp,int y){
int t = *xp+y;
*xp=t;
return t;
}
我们使用GCC编译器加-S参数来编译这段代码,最终我们可以得到一个sum.s的文件,我们使用cat来查看一下这个文件。
.file "sum.c"
.text
.globl simple
.type simple, @function
simple:
pushl %ebp
movl %esp, %ebp
subl $16, %esp
movl 8(%ebp), %eax//这一步是从主存取变量xp
movl (%eax), %eax//取*xp的值
addl 12(%ebp), %eax//计算*xp+y,并存到%eax寄存器
movl %eax, -4(%ebp)//将*xp+y赋给变量t
movl 8(%ebp), %eax//再取xp
movl -4(%ebp), %edx//取t
movl %edx, (%eax)//执行t->*xp
movl -4(%ebp), %eax//将t放入%eax准备返回
leave
ret
.size simple, .-simple
.ident "GCC: (Ubuntu 4.4.3-4ubuntu5.1) 4.4.3"
.section .note.GNU-stack,"",@progbits
这里我们主要看一下汇编语言是如何描述我们的计算过程的,因此LZ只是简单的加了几个注释,来大致描述下上面的程序的计算过程。其中需要说明的是,以%开头的为寄存器,有小括号的为主存。
熟悉GCC的猿友们应该知道,我们可以控制编译器的优化级别,因此我们使用另外一种方式来编译一下sum.c,我们在-S的基础上再加一个-O1的参数。之后使用cat打开sum.s文件。
.file "sum.c"
.text
.globl simple
.type simple, @function
simple:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %edx//取xp
movl 12(%ebp), %eax//取y
addl (%edx), %eax//计算*xp+y并存到%eax寄存器,准备返回
movl %eax, (%edx)//将*xp+y存入*xp
popl %ebp
ret
.size simple, .-simple
.ident "GCC: (Ubuntu 4.4.3-4ubuntu5.1) 4.4.3"
.section .note.GNU-stack,"",@progbits
可以很明显的看出,汇编指令的数目急剧减少,这里LZ也加入了简单的注释。从LZ简单的注释中可以看出,这里的优化主要是去掉了变量t的存在,因此减少了指令数。
如果哪位猿友实在看不明白这两段汇编语言的含义,可以暂且忽略,这里LZ只是让各位体验一下汇编语言的格式,以及亲自接触一下汇编语言,我们的目的并不是搞清楚它的意义。相信经过3.X的系列讲解,各位猿友再回来看这两段汇编代码时,应该会很轻松的看出其中的意义。
文章小结
这一章拖的时间有点久,主要是因为LZ作为一个Java开发人员来讲,对汇编语言的学习有些许难度,毕竟LZ并不擅长C/C++。还有一个原因,则是由于LZ希望尽量的搞清楚来龙去脉,以免误导某些猿友。
当然了,就算如此,LZ也不敢保证现在对3.X的内容已经了如指掌,因此如果文中有任何与各位猿友的理解不一致的地方,希望各位猿友尽管提出。不仅可以避免误导看博文的猿友,还可以帮助LZ纠正错误的认识。
好了,本文的主要目的就是将各位猿友拉近汇编的世界,因此就只是简单的介绍了一下。接下来,我们将深入的讨论寄存器、数据格式以及一些汇编指令。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号