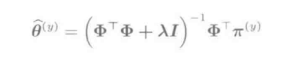机器学习算法之概率分类法
对模型给予概率进行分类的手法称为概率分类法。给予概率是指对于模式X所对应的类别y的后验概率(y|x)进行学习。其所属类别为后验概率达到最大值时所对应的类别。

基于概率的模式识别的算法除了可以避免错误分类,还具有一个优势。就是的对多分类通常会有一个号的效果。
一、Logistic回归
首先,来看一下最基本也是最常见的概率分类算法-----logistc回归。
1、Logistic的最大似然估计
Logistic回归,使用线性对数函数对分类后验概率p(y|x)记性模型化。
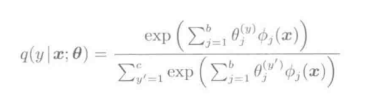
分母是满足概率总和为1 条件约束的正则化项。参数θ有bc维。
Logistic回归模型的学习,通过对数似然维最大时的最大似然估计进行求解。

Logistic回归的学习模型由下式的最优化问题定义:
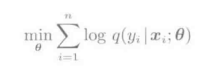
上述的目标函数对于参数θ时可以微分的,所以可以使用梯度下降法来求最大似然那估计的解。
下面是使用概率梯度下降法的Logistic回归学习算法的伪代码

2、使用Logistic损失最小化学习来解释
以2分类问题进行说明
y ∈{+1,-1},q(y=+1 | x;θ)+q(y= -1|x;θ) =1
Logistic的参数由2b个降到b个
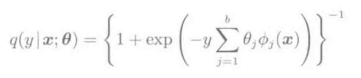
这个模型的对数似然最大化的准则
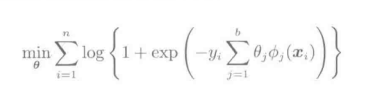
可以改写为上述形式。根据关于参数的线性模型
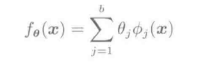
的间隔m = f(x)y,可知上式与Logistic损失
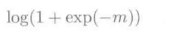
的Logistic损失最小化学习是等价的。
二、最小二乘概率分类
最小二乘分类是在平方误差的准则下,与Logistic回归具有相同学习的算法。
最小二乘分类器的线性模型:
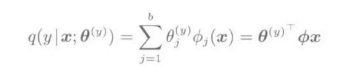
与Logistic模型不同的是,这个模型只依赖于与各个类别y对应的参数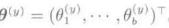 。然后,对于这个模型进行学习,使下式的平方误差最小。
。然后,对于这个模型进行学习,使下式的平方误差最小。
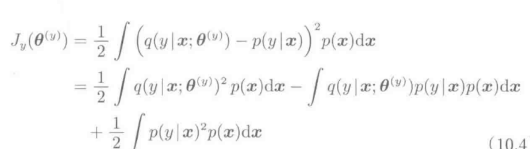
上式第二项中
p(y|x)p(x)利用贝叶斯公式进行变换。
p(y|x)p(x) = p(xy) = p(x|y)p(y)
 分别表示与p(x)和p(x|y)相关的数学期望值。这些期望值一般无法直接计算。而是用样本的平均值来进行近似。
分别表示与p(x)和p(x|y)相关的数学期望值。这些期望值一般无法直接计算。而是用样本的平均值来进行近似。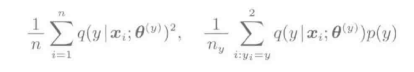
再加入l2正则化项,将最小平方误差公式记为:
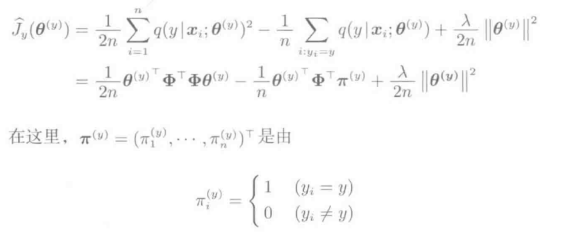
对其求偏导数并置为0,得到θ的解