经典分治算法
RT,主要介绍一些经典的分治算法
CDQ 分治
经典人类智慧算法。
三维偏序问题
三维偏序是 CDQ 分治的一个经典应用,搭配树状数组可以在
我们可以先按照
定义
-
-
-
求解
重复上述过程,递归边界是
根据定义很好解释。我们发现可以下手优化的地方主要在第三部分,按照暴力做法,对于第三部分,我们枚举所有
我们发现,对于任何
我们定义两个指针
我们思考平时解决二维偏序问题主要依靠排序和树状数组,利用树状数组限制第二维,而此时我们也可以在三维偏序中使用树状数组来限制第三维。具体做法,
时间复杂度:CDQ 分治 一般是子问题的时间复杂度乘上
同时,还存在几个小问题。
-
CDQ 分治的一个特点是:在每次分治求解一个小区间时,不会涉及该区间外的部分,仅仅与当前小区间长度有关,所以在使用完树状数组后,不可以暴力清空,而应该还原原本的过程,以保证时间复杂度。
-
对于重复元素之间有贡献的,CDQ 分治无法直接解决,一个技巧是可以将元素离散化再求解。
-
CDQ 分治的分治过程类似并归排序,所以在将序列按照
贴出核心代码:
void merge(int l,int mid,int r){
int i=l,j=mid+1,t=l;
while(i<=mid||j<=r){
if(j>r||(i<=mid&&cmp2(q[i],q[j])))book[t++]=q[i++];//cmp2指按b[i]排序
else book[t++]=q[j++];
}
for(int i=l;i<=r;i++)q[i]=book[i];
return;
}//并归排序
void solve(int l,int r){
if(l==r)return;//递归边界,直接返回
int mid=(l+r)>>1,t=l;
solve(l,mid),solve(mid+1,r);//分治求解
for(int i=mid+1;i<=r;i++){//指针扫描
while(q[t].y<=q[i].y&&t<=mid)add(q[t].z,q[t].cnt),t++;//移动指针的同时,注意指针移动的范围,q[t].cnt指离散化前这种元素的数量
q[i].ans+=ask(q[i].z);//更新答案
}
for(int i=l;i<t;i++)add(q[i].z,-q[i].cnt);//还原现场,注意是 i<t,以免多减
return merge(l,mid,r),void();//并归排序
}
整体二分
没学不会。
点分治
点分治(又称淀粉质),通常用于统计树上路径。先看一道典题。
Tree
本题要求统计路径长度不超过
我们先选一个树中的节点
-
经过点
-
整条路径在
我们发现这种路径很适合分治统计,很简单的就可以设计出分治算法的雏形。
-
首先先选择树中一点
-
接着将
注意在代码中的实现删除一般会打上标记,且在后续的统计中不会经过打了标记的节点。
我们先探讨第一步,给定一棵树,给定其根节点
-
-
我们遍历整棵树,求出树中每个节点
下面给出一种目前比较受欢迎的做法。
我们先不考虑
接下来做的就是要减去不合法的路径,设
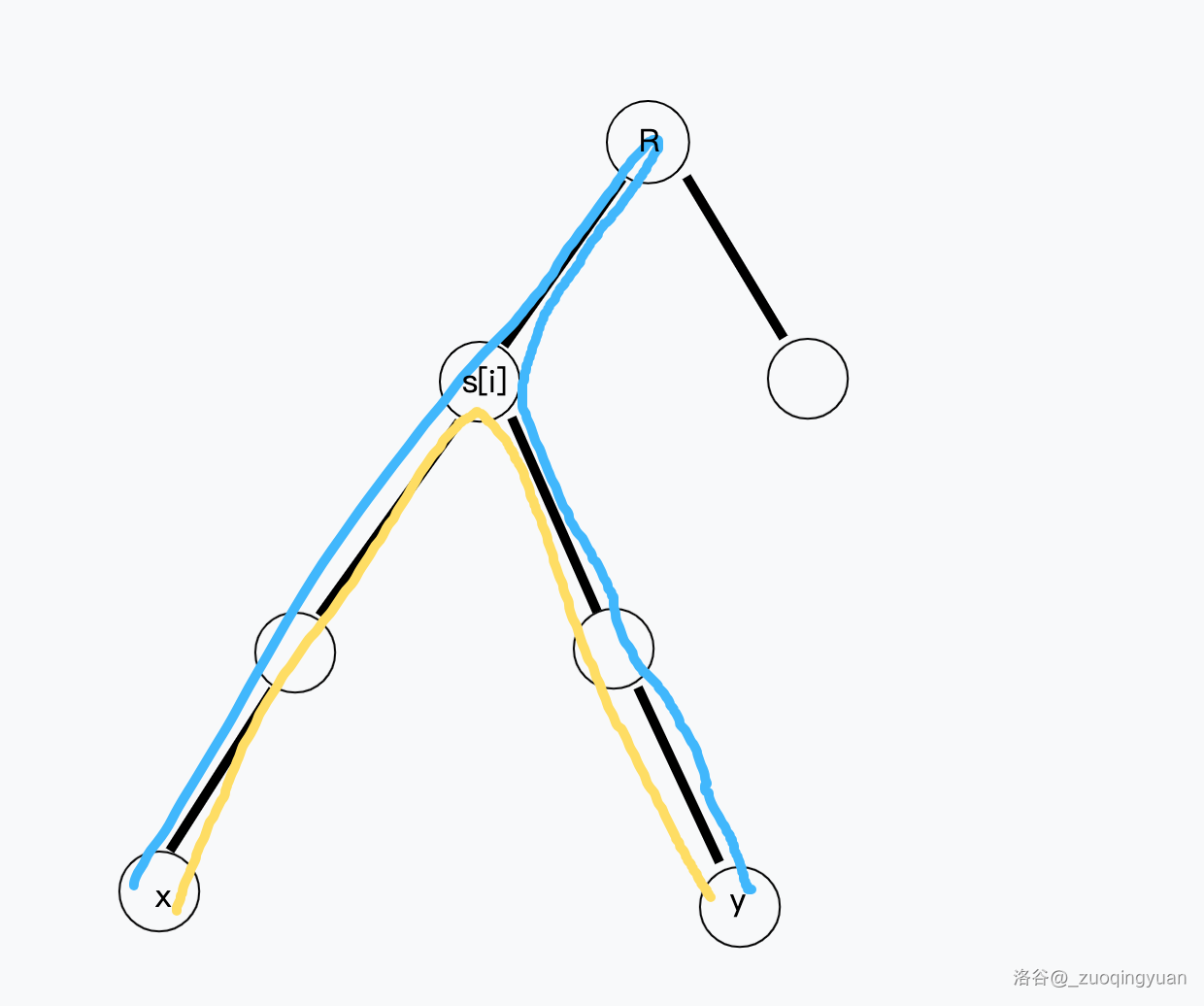
如上图,我们发现,统计中类似蓝色路径(所要求的不合法路径)的数量其实就是统计中类似黄色路径的数量,唯一不同的是蓝色路径统计的是在
这种做法基于容斥原理,优势是易拓展,可以延伸到三维限制的统计中。劣势是时间复杂度稍差,理论上常数翻倍,实际时间上影响并不是很大。可以对比这一份和这一份的差异,前者是其他做法,没有用到容斥原理。
注意在执行
在统计完第二类路径后,我们将节点
假设我们在执行完
对于这个问题,我们可以选择子树的重心作为树的分治点,树重心有一个很好性质,就是删除重心后,原本的树分裂形成的新的树大小均不超过原树的一半,这相当于把分治的规模对半砍了一刀。
画出分治时的递归树,对于递归树中同一层深度分治函数所执行的
搞定了这个,我们就完美的把这个问题解决了。
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N=4e4+10;
int n,idx,ver[N],to[2*N],nxt[2*N],val[2*N],k,siz[N],maxn[N],root,vis[N],cnt,b[N],ans,a[N];
void add(int x,int y,int z){
to[++idx]=y,nxt[idx]=ver[x],ver[x]=idx,val[idx]=z;
}
int dfs_root(int x,int fa,int sum){
siz[x]=1,maxn[x]=0;
for(int i=ver[x];i;i=nxt[i]){
if(vis[to[i]]||to[i]==fa)continue;
siz[x]+=(siz[to[i]]=dfs_root(to[i],x,sum));
maxn[x]=max(maxn[x],siz[to[i]]);
}
maxn[x]=max(maxn[x],sum-siz[x]);
if(maxn[x]<maxn[root])root=x;
return siz[x];
}//找树的重心
void dfs_dis(int x,int fa,int from,int len){
a[++cnt]=len;
for(int i=ver[x];i;i=nxt[i]){
if(vis[to[i]]||to[i]==fa)continue;
dfs_dis(to[i],x,from,len+val[i]);
}
}//获得每个节点的信息
int calc(int u,int dist){
a[cnt=1]=dist;//初始化以u为端点
for(int i=ver[u];i;i=nxt[i]){
if(vis[to[i]])continue;
dfs_dis(to[i],u,to[i],dist+val[i]);
}
sort(a+1,a+1+cnt);
int l=1,r=cnt,sum=0;
while(l<r){
while(a[l]+a[r]>k&&l<r)r--;
sum+=(r-l),l++;
}
return sum;
}
void solve(int u){
vis[u]=1;
ans+=calc(u,0);
for(int i=ver[u];i;i=nxt[i]){
if(vis[to[i]])continue;
ans-=calc(to[i],val[i]);//容斥
root=0,dfs_root(to[i],u,siz[to[i]]);//递归分治
solve(root);
}
return;
}
int main(){
scanf("%d",&n);
for(int i=1,u,v,w;i<n;i++){
scanf("%d %d %d",&u,&v,&w);
add(u,v,w),add(v,u,w);
}
scanf("%d",&k);
maxn[0]=N;//注意初始化
dfs_root(1,-1,n);
solve(root);
printf("%d\n",ans);
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现