grep用法小结
用法
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] -e PATTERN ... [FILE...]
grep [OPTIONS] -f FILE ... [FILE...]
grep在文件中查找匹配正则表达式的内容,默认打印出匹配的一行
选项
-E 支持扩展正则表达式
-F 把PATTERN解析成简单的字符串,而不是正则表达式
-G 只支持基础正则表达式,这是默认选项
-P 支持perl正则表达式
使用文件grp.txt为演示
$ cat grp.txt
{"id":1, "username": "jack", "email": "459874@qq.com"}
{"res":[2,1,5,7]}
baidu in beijing
didi in beijing
ali in hangzhou
tencent in shenzhen
huawei in shenzhen
-e PATTERN, 使用-e选项可以匹配多个条件

-f FILE, 从文件中获取PATTERN
-i 忽略大小写
-v 反向匹配,只选择未匹配的

-w 匹配整个单词
-x 匹配整行

可以看到 -x 选项和 grep '^h.*en$' grp.txt 等价
-c 不打印结果,只打印匹配到的行数
--color 匹配到的表达式高亮显示
-L 打印出未匹配的文件列表
-l 打印出匹配的文件列表
-m 指定最大匹配行数

-o 只打印匹配到的字符串,而不是打印一整行

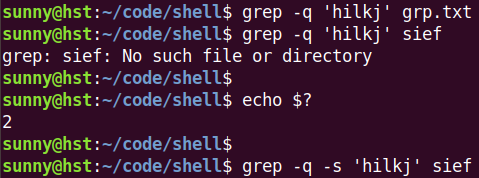
-q 不打印结果,但是我们可以根据$?来判断是否有匹配到,在脚本中常用
-s 不打印错误结果(文件不存在、不可读文件)
-b 打印本行在文件中的字节偏移量
-H 打印匹配的文件名。当有多个文件匹配到的时候,这个是默认选项
-h 不打印文件名
-n 输出行号
--label 显示输入的时候用到,让标准输入STDIN的显示像从文件中读取的一样

-T 输出按照tab缩进
-Z 在文件名后输出 zero byte, 也就是啥都不输出

-A NUM 在匹配行后面再输出 NUM 行内容
-B NUM 在匹配行前面再输出 NUM 行内容
-C NUM 在匹配行前后各输出 NUM 行内容
--exclude=GLOB
--exclude-from=FILE
--exclude-dir=GLOB
这三个是跳过文件或目录
--include=GLOB 只处理匹配 GLOB 的文件
