


ElasticSearch Logstash Kibana
集群搭建
集群搭建需要注意的几个配置点。
1 修改每个进程最大同时打开文件数太小和用户最大线程。修改/etc/security/limits.conf文件,增加配置,用户退出后重新登录生效。
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
2 修改虚拟内存最大值 /etc/sysctl.conf 增加
vm.max_map_count=262144
3 修改ES中JVM占用内存,默认的太大。ES配置文件config/jvm.options
-Xms512m
-Xmx512m
4 修改ES配置文件


cluster.name : es
#配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
node.name : n1
#节点名,默认随机指定一个name列表中名字,该列表在es的jar包中config文件夹里name.txt文件中
node.master : true
#指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。
node.data : true
#指定该节点是否存储索引数据,默认为true。
network.host : 0.0.0.0
#本机地址
transport.tcp.port : 9001
#设置节点间交互的tcp端口,默认是9300。
http.port : 8001
#设置对外服务的http端口,默认为9200。
transport.tcp.compress : true
#设置是否压缩tcp传输时的数据,默认为false,不压缩。
http.max_content_length : 100mb
#设置内容的最大容量,默认100mb
discovery.zen.ping.unicast.hosts : ["0.0.0.0:9001","0.0.0.0:9002","0.0.0.0:9003"]
#设置新节点被启动时能够发现的主节点列表(主要用于不同网段机器连接)
discovery.zen.minimum_master_nodes: 2
#master候选节点数量/2+1
#master候选节点
cluster.initial_master_nodes: ["n1","n2","n3"]
#如果使用head插件,需要增加这个。
http.cors.enabled: true
http.cors.allow-origin: "*"
5 安装IK分词器
https://github.com/medcl/elasticsearch-analysis-ik
将解压好的目录命名位IK放到ES的plugins下。
6 安装head插件
下载head需要先安装node环境。这里给出一篇博客。
https://www.cnblogs.com/xiaojianfeng/p/9435507.html
7 启动Es不能使用root用户,需要创建一个Linux用户。启动脚本再 bin 下。
bin/elasticsearch -d 其中 -d 为后台启动。
故障转移
在一个ES集群中创建一个索引指定了主分片和副本分片后。如果集群节点挂掉后,ES会动态的做故障转移。
将挂掉的节点上的分片,分配给其他节点上。直到该节点恢复,才会将分片重新分配。
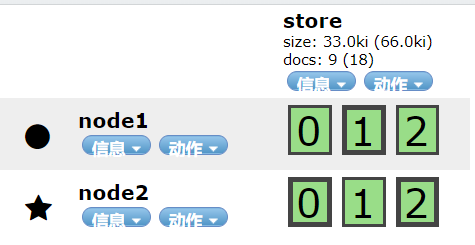
下图store索引,主分片数量三个,每个有一个副本分片,总共六个。

当node3节点挂掉后。经过短暂的ES检查到节点丢失。

短暂的调整后,ES会将node3的节点分配到其他两个节点上。
极限扩容
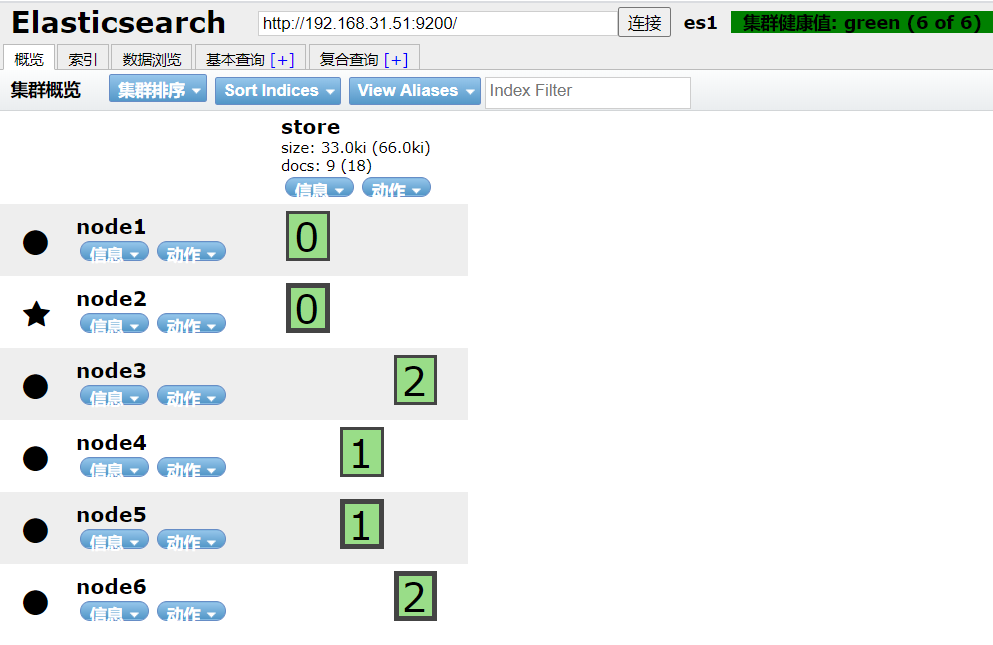
索引库一旦创建,主分片数量不可更改。例如上图的store索引库,三个主分片,每个主分片一个副本。
但随着业务的增加,一台服务上放置多个分片势必导致读写慢,ES写操作只能在主分片上操作,而读
操作可以在主分片或者副本分片操作。所以我们需要对索引库进行扩容。就是增加服务器。这次的目标是
在扩展3台服务器,总共6台做到每台服务器上只放置一个分片。这个操作只需要对ES集群增加节点即可。
增加副本
上边说过,当索引建立后,主分片不可增加。那么业务量庞大时,做到极限扩容,显然已经
到达了阈值。像上边那样,已经是一台服务器放一个分片了。接下来我们要做的操作是增加
副本分片。下图为使用springBoot JPA的方式创建了主分片和副本分片都是一的索引。
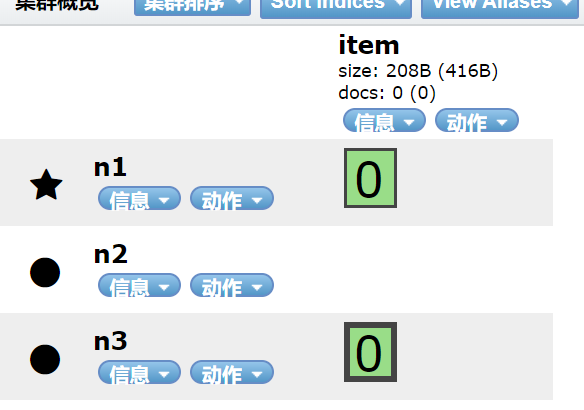
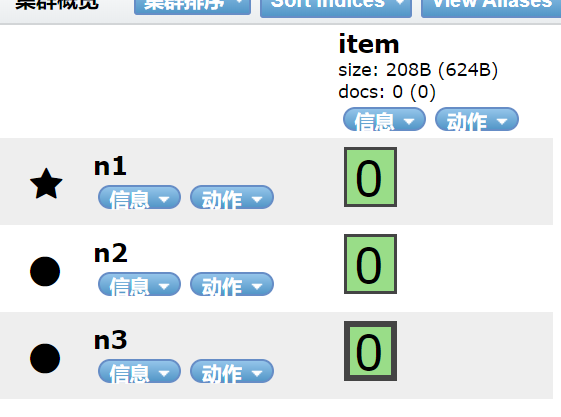
可以看到 n2这个节点完全没有用到。接下来我们通过 rest 的方式,对索引的副本分片进行更改。

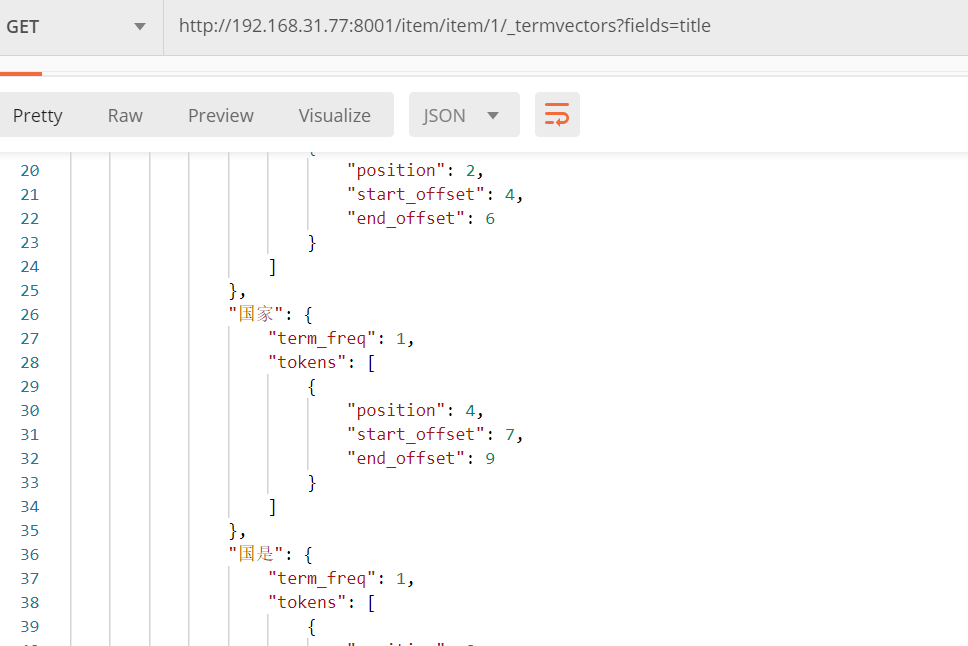
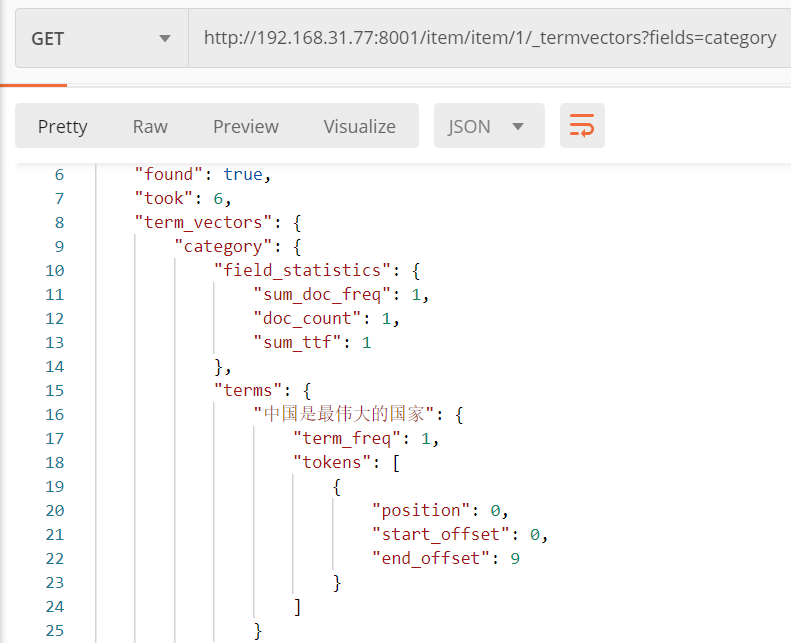
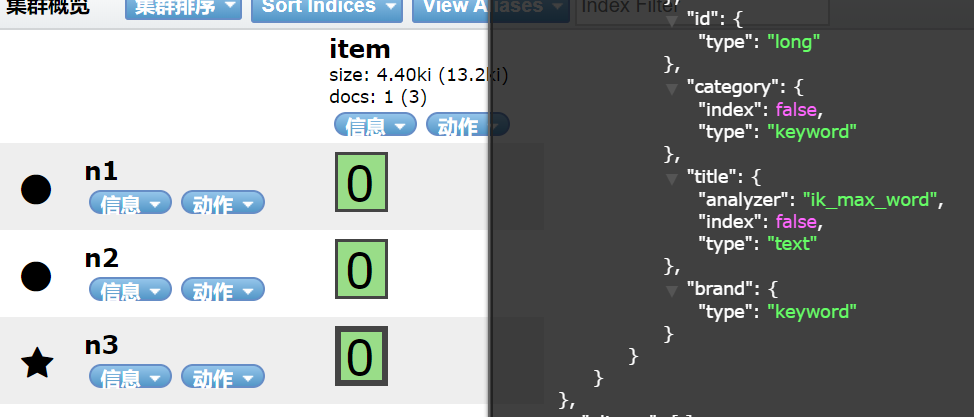
FieldType.Text和FieldType.Keyword
定义文档时会选择字段类型。如果是字符串类型,我们则要考虑是否对改字段进行分词。
如果分词就会创建索引。Text则会对字符串进行分词并索引。Keyword则不会对字符串
分词,但是会创建索引。以下索引Item只有title字段是text类型。其他是keyword类型。

index
表示字段是否索引,上边我们说过对于字符串类型,无论是Keywork还是Text都会对字段进行
索引。index属性为false则表示该属性不创建索引。即使此字符串是Text类型。
LogStash
从这个地址下载LogStash https://artifacts.elastic.co/downloads/logstash 注意LogStash版本要和Elasticsearch一致。
logStash主要作用从一个输入源读数据,然后将数据存到Elasticsearch 输入源可以是数据库,文件,APP应用等。
注意事项
1 修改config/jvm.config文件
-Xms256m
-Xmx256m
2 启动脚本再 bin 目录下 bin/logstash -e 'input{ stdin{} } output{ stdout{} }' 这种方式直接将配置放到启动脚本后,但是如果过长就不好看了,可以放到配置文件步骤3.
3 修改启动配置文件
config/ 下创建一个 xx.config 即可。
LogStash配置文件主要配置输入源,和输出目的地。格式如下
input{
tcp{
port => 1111
codec => "json"
}
}
output{
elasticsearch{
hosts => ["10.0.98.76:9200"]
index => "testapp"
}
}
input表示输入,output表示输出。可以有多个输入源,也可以有多个输出源。以上则是监听服务端口,然后输出到Elasticsearch
步骤2的 stdin{} stdout{} 为控制台输入输出。如果有多个输入源,这个语法也支持 if 判断,根据输入源的 type 判断输入到哪里。
以下是一个常用配置。需要注意的是,如果输入源是 file 则该文件必须是 .log 结尾。同时要设置 start_position 属性,该属性规定了Logstash从文件的什么
位置开始读取,如果是 beginning 则表示从文件第一行开始读。注意Logstash会一行一行的读,遇到换行符则代表一行。 end 表示会从文件尾部读取,也就是
如果你指定的文件里已经有内容,Logstash只会读取新增的日志。但是,如果这个文件曾经被Logstash读取过,则Logstash会对文件有标记,标记曾经读到哪一行
也就是说,start_position只对第一次读的文件生效。
4 启动时指定配置文件 logstash -f config/logstash-sample.conf
nohup bin/logstash -f config/logstash-sample.conf & 后台启动
输入源如果是 tcp 则需要指定 codec 为json
input{
#stdin{}
file{
path => "/home/elk/logStash/logstash-7.8.0/config/test1.log"
type => "test1"
start_position => "beginning"
}
file{
path => "/home/elk/logStash/logstash-7.8.0/config/test2.log"
type => "test2"
start_position => "beginning"
}
tcp{
host => "192.168.31.77"
port => 1111
codec => json
type => "app"
}
}
output{
if [type] == "test1"{
elasticsearch{
hosts => ["192.168.31.77:8003"]
index => "log1"
}
}
if [type] == "test2"{
elasticsearch{
hosts => ["192.168.31.77:8003"]
index => "log2"
}
}
if [type] == "app"{
elasticsearch{
hosts => ["192.168.31.77:8003"]
index => "applog"
}
}
#stdout{
#codec => json
#}
}
下面代码片段为 springboot中将日志输入到 tcp
1 根据使用的日志框架导入相应的包,我这里用的logback
<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>4.11</version> </dependency>
2 配置logback,关于logback的配置规则可以参考我上一篇博客。
<appender name="logstashshow" class="net.logstash.logback.appender.LogstashTcpSocketAppender"> <destination>127.0.0.1:1111</destination> <encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"></encoder> </appender> <logger name="com.dfsn.cloud.consumer" level="INFO" additivity="false"> <appender-ref ref="logstashshow"></appender-ref> </logger>
当应用启动后,会额外的启动一个端口,将日志输入到该端口,Logstash监听该端口,接收日志。最后给出一个Logback官方地址,所有的配置都可以找到。
https://www.elastic.co/guide/en/logstash/current/index.html

Kibana
Kibana是一个视图app,对Elasticsearch中的日志,做分析查看。
Kibana只需要修改config配置文件下的kibana.yml文件即可。
server.port: 5601
server.host: "192.168.31.77"
elasticsearch.hosts: ["http://192.168.31.77:8001"]
kibana.index: ".kibana"
默认的 Kibana 也不支持 root 用户启动,可以设置 --allow-root 忽略检查。
kibana --allow-root
nohup bin/kibana --allow-root &
截至目前我对Kibana运用的也十分生疏,给出一个博客吧。
https://blog.csdn.net/qq_18769269/article/details/80843810
