K-means聚类
1.随机产生k个分类特征的中心点
2.计算数据点到中心点的距离
3.数据点到哪个中心点最近就分到哪个类
4.迭代:更新中心点位置,重新计算距离并分配类别,直到总体距离最小
load fisheriris
figure;
speciesNum=grp2idx(species);
gscatter(meas(:,3),meas(:,4),speciesNum,['r','g','b']);
xlabel('花瓣长度');
ylabel('花瓣宽度');
title('真实标记');
set(gca,'fontsize',12);
set(gca,'fontweight','bold');
data=[meas(:,3),meas(:,4)];
K=3;
%5此重复的全局最优解
[idx,cen]=kmeans(data,K,'Distance','sqeuclidean','Replicates',5,'Display','Final');
%调整标号
dist=sum(cen.^2,2);
[dump,sortind]=sort(dist,'ascend');
newidx=zeros(size(idx));
for i=1:K
newidx(idx==i)=find(sortind==i);
end
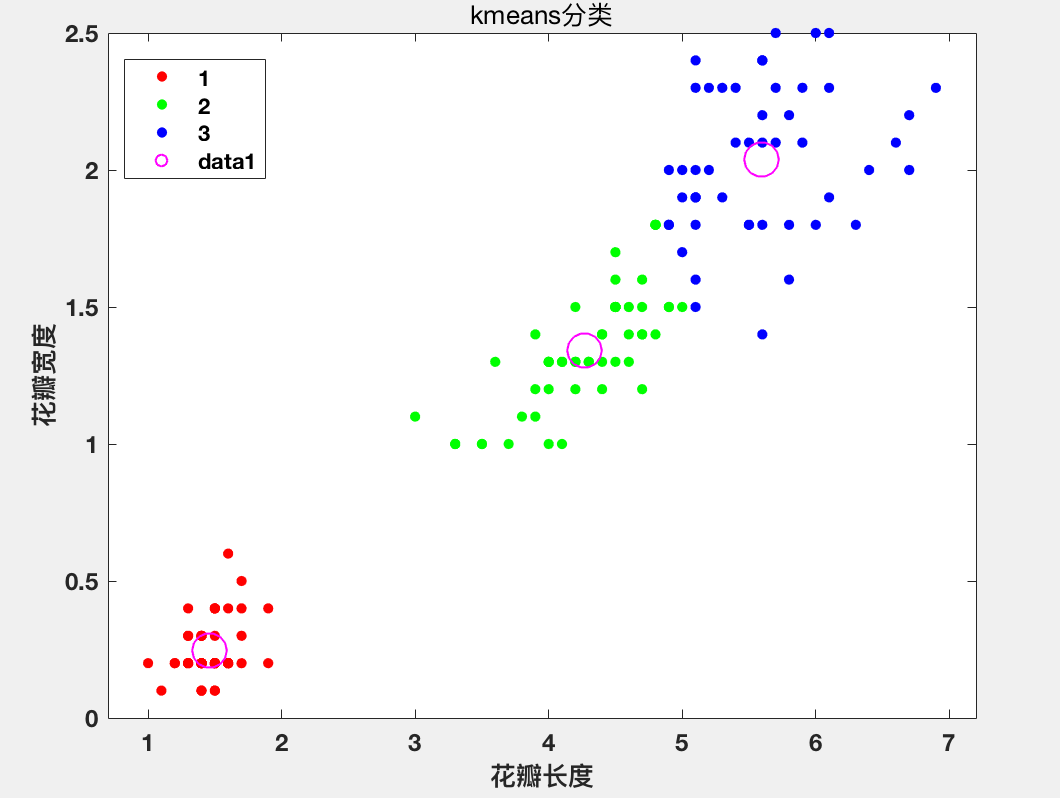
%花瓣长度和花瓣宽度散点图(kmeans分类)
figure;
gscatter(data(:,1),data(:,2),newidx,['r','g','b']);
hold on
scatter(cen(:,1),cen(:,2),300,'m');
hold off
xlabel('花瓣长度');
ylabel('花瓣宽度');
title('kmeans分类');
set(gca,'fontsize',12);
set(gca,'fontweight','bold');