

数据库的简单知识
列类型
在创建数据表的时候,指定的列所能存储的数据类型
create table news(
列名称 列类型
);
1.数值型 1Byte=8Bit (一个字节=8位) 插入值的引号可以省略
tinyint 微整型,占1个字节,范围-128~127
smallint 小整型,占2个字节,范围-32768~32767
int 整型,占4个字节,范围-2147483648~2147483647
bigint 大整形,占8个字节
float 单精度浮点型,占4个字节,以牺牲小数点后的位数为代价,存储的数字越大,精度越低
double 双精度浮点型,占8个字节,以牺牲小数点后的位数为代价,存储的数字越大,精度越低
decimal(M,D) 定点小数,小数点不会发生变化,M代表总的有效位数,D代表小数点后的有效位数
boolean 布尔型,只有两个值,分别是true和false,代表真和假;常用于存储只有两个值的数据;
|
true和false是关键字,使用的时候不能加引号;
boolean在使用的时候会自动转换为tinyint,true转为1,false转为0;也可以直接插入1或者0
|
2.日期时间型 插入值必须加引号
date 日期型 '2022-10-20'
time 时间型 '15:29:48'
datetime 日期时间型 '2022-10-20 15:29:48'
3.字符串型 插入值必须加引号
varchar(M) 变长字符串,不会产生空间浪费,数据操作速度相对慢,常用于存储变化长度的数据,例如:文章标题、详情、姓名... M最大值是65535
char(M) 定长字符串,可能产生空间浪费,数据操作速度相对快,常用于存储固定长度的数据,例如:手机号码、身份证号... M最大值是255
text(M) 大型变长字符串,M最大值是2G
列约束
在插入数据的时候,可以对插入的值进行验证,只有符合条件才允许插入,例如:编号不允许重复、性别只能是男或者女、成绩范围必须在0~100之间...
create table t1(
lid int 列约束
);
1.主键约束 —— primary key
声明了主键约束列上,不允许插入重复的值,一个表中只能有一个主键约束,通常加在编号列,还可以加快数据的查询速度
|
null:空,表示一个暂时无法确定的值,例如:暂时无法确定商品的上架时间,价格;暂时无法确定一个员工的手机号码...
是一个关键字,使用的时候不能加引号
|
主键约束的列禁止插入null
2.非空约束 —— not null
声明了非空约束的列,禁止插入null
1.唯一约束 —— unique
声明了唯一约束的列不允许插入重复的值,允许插入null,甚至多个null;一个表中可以使用多个唯一约束
2.默认值约束
插入数据的时候,如果不提供值,就会使用默认值
(1)设置默认值
使用default 关键字设置默认值
(2)应用默认值
给特定的列提供值,没有出现的列自动应用默认值
insert into 数据表(列名称...) values(值...);
insert into 数据表 values(值,... default...);哪个列要使用默认值,直接赋值为default即可。
3.检查约束 —— check
也称为自定义约束,是程序员指定的约束条件
create table student(
score tinyint check(score>=0 and score<=100)
);
mysql 不支持检查约束; 认为会严重影响数据的插入速度。后期都是通过JS来完成
4.外键约束
声明了外键约束列,插入的值必须在另一个表的主键列出现过;
外键列要和对应的主键列两者的类型要一致
foreign key(外键列) references 另一个表(主键列)
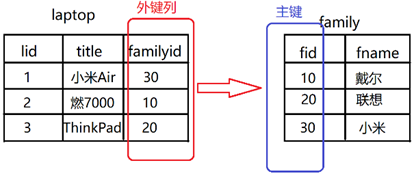
自增列
auto_increment:自动增长,声明了自增列,只需要赋值为null,会自动的获取最大值然后加1插入。
注意事项:
必须添加在整数形式的主键列
允许手动赋值
简单查询
1.查询特定的列
示例:查询出所有员工的编号和姓名
select eid,ename from emp;
2.查询所有的列
select eid,ename,sex,birthday,salary,deptid from emp;
select * from emp;
3.给列起别名
示例:查询出所有员工的编号和姓名,使用一个字母作为别名
select eid as a, ename as b from emp;
select eid a, ename b from emp;
|
as 用来设置别名
as关键字可以省略,保留空格即可
|
4.显示不同的记录
示例:查询出都有哪些性别的员工
select distinct sex from emp; #可以去除重复
|
distinct 不同的,有区别
|
5.查询时执行计算
示例:查询出所有员工的姓名及其年薪
select ename,salary * 12 from emp;
练习:假设每个员工的工资增长2000,年终奖是30000,查询出所有员工的姓名及其年薪,使用一个字母作为别名
select ename a, (salary+2000)*12+30000 b from emp;
6.查询结果排序
示例:查询出所有的部门,结果按照部门编号升序排列
select * from deptid order by did asc; #ascendant 升序的
示例:查询出所有的部门,结果按照部门编号降序排列
select * from deptid order by did desc; #descendant 降序的
练习:查询出所有员工,结果按照工资降序排列
select * from emp order by salary desc;
练习:查询出所有员工,结果按照年龄从大到小排列
select * from emp order by birthday asc;
练习:查询出所有员工,结果按照姓名升序排列
select * from emp order by ename asc;
|
按照字符串排列,会按照首个字符的Unicode编码排列
|
示例:查询出所有员工,结果按照工资降序排列,如果工资相同按照姓名排列
select * from emp order by salary desc,ename asc;
练习:查询出所有员工,结果要求女员工显示在前,如果性别相同按照年龄从大到小排列
select * from emp order by sex,birthday;
|
不加排序规则,默认是按照升序排列
|
7.条件查询
示例:查询出编号为5的员工
select * from emp where eid=5;
练习:查询出姓名为king的员工
select * from emp where ename='king';
练习:查询出10号的员工有哪些
select * from emp where deptid=10;
示例:查询出编号不在10号部门有哪些
select * from emp where deptid != 10;
|
> < >= <= = !=
|
示例:查询出没有明确部门的员工有哪些(部门编号为null)
select * from emp where deptid is null;
查询出有明确部门的员工有哪些(部门编号不为null)
select * from emp where deptid is not null;
|
and 或 && 两个条件都满足
|
|
or 或 || 两个条件只需要满足其中一个
|
示例:查询出工资在8000以上的男员工有哪些
select * from emp where salary > 8000 and sex =1;
select * from emp where salary > 8000 && sex =1;
示例:查询出1993年以后出生或者1990年之前出生的员工
select * from emp where birthday>'1993-12-31' or birthday < '1990-1-1';
select * from emp where birthday>'1993-12-31' || birthday < '1990-1-1';
示例:查询出20号部门或者30号部门的员工
select * from emp where deptid=20 or deptid=30;
select * from emp where deptid in (20,30);
示例:查询出不在20号部门并且也不在30号部门的员工
select * from emp where deptid !=20 or deptid !=30;
select * from emp where deptid not in (20,30);
8.模糊条件查询
示例:查询出姓名中含有字母e的员工有哪些
select * from emp where ename like '%e%';
示例:查询出姓名中以e结尾的员工有哪些
select * from emp where ename like '%e';
示例:查询出姓名中倒数第2个字符是e的员工有哪些
select * from emp where ename like '%e_';
% 表示匹配任意个字符 >= 0
- 表示匹配任意一个字符 =1
以上两个匹配的符号必须结合like关键字使用
9.分页查询
查询的结果中有太多的数据,一次显示不完可以做成分页
需要有两个已知条件:当前的页码、每页的数据量
|
开始查询的值 = (当前的页码-1)* 每页的数据量
|
select * from emp limit 开始查询的值,每页的数据量;
示例:假设每页显示5条数据,查询出前4页的数据
第1页:select * from emp limit 0,5;
第2页:select * from emp limit 5,5;
第3页:select * from emp limit 10,5;
第4页:select * from emp limit 15,5;
|
注意事项:
limit 后开始查询的值,不能写运算,只能写某一个值
limit 后的两个值必须是数值型,不能加引号
|
复杂查询
1.聚合查询/分组查询
示例:查询出所有员工的数量
select count(*) from emp;
练习:使用员工的编号列查询数量
select count(eid) from emp; #推荐使用主键列
练习:使用员工的编号列查询数量
select count(deptid) from emp; #null不会计算在内
|
函数:是一个功能体,需要提供若干数据,返回结果
聚合函数
count() / sum() / avg() / max() / min()
数量 总和 平均 最大 最小
|
聚合查询:
示例:查询出所有男员工的工资总和
select sum(salary) from emp where sex=1;
示例:查询出20号部门的平均工资
select avg(salary) from emp where deptid=20;
示例:查询出女员工的最高工资
select max(salary) from emp where sex=0;
示例:查询出年龄最大的员工的生日
select min(birthday) from emp;
分组查询:
| 通常分组查询只用于查询聚合函数和分组条件 |
示例:查询出男女员工的数量、工资总和、平均工资
select count(eid),sum(salary),avg(salary) from emp group by sex;
示例:查询出各部门的员工数量,最高工资,最低工资
select count(eid),max(salary),min(salary),deptid from emp group by deptid;
| year() 获取日期中的年份 |
示例:select year('2022-5-7');
示例:查询出1990年出生的员工有哪些
select * from emp where year(birthday)=1990;
示例:查询出所有员工姓名和出生的年份
select ename,year(birthday) from emp;
2.子查询
| 多个SQL命令的组合,把一个SQL命令的查询结果作为另一个的条件使用 |
示例:查询出年龄最小的员工
步骤1:年龄最小的员工生日是哪一天
select max(birthday) from emp;
步骤2:通过这一天找到对应的员工
select * from emp where birthday='1995-12=03';
综合:
select * from emp where birthday=(select max(birthday) from emp);
示例:查询出比tom工资高的员工有哪些
步骤1:查询出tom的工资 —— 6000
select salary from emp where ename='tom';
步骤2:查询工资高于6000的员工
select * from emp where salary > 6000;
综合:
select * from emp where salary>(select salary from emp where ename='tom');
示例:查询出和tao 同一个部门的员工
select *from emp where deptid = (select deptid from emp where ename='tao') and ename!='tao';
示例:查询出和tom同一年出生的员工
select * from emp where year(birthday) = (select year(birthday) from emp where ename='tom') and ename!='tom';
3.多表查询
查询的列分布在多个表中,前提是表之间是建立了关联
示例:查询出所有员工的姓名及其部门名称
select ename,dname from emp,dept where deptid=did;
为了防止多个表列名称相同,可以在列名称前加表名称
select emp.ename,dept.dname from emp,dept where emp.deptid=dept.did;
(1)内连接
select ename,dname from emp inner join dept on deptid=did; 和之前的结果是一样的,没用
(2)左外连接
select ename,dname from emp left outer join dept on deptid=did; 显示所有的员工
(3)右外连接
select ename,dname from emp right outer join dept on deptid=did;
左外连接和右外连接的 outer 关键字可以省略
(4)全连接
同时显示所有的员工和所有的部门
full join on
mysql 不支持全连接
联合 union all 联合后,不合并相同记录
union 联合后,合并相同记录
| 解决全连接:将左外连接和右外连接两组进行联合,联合后合并相同记录 |
(select ename,dname from emp left outer join dept on deptid=did) union all (select ename,dname from emp right outer join dept on deptid=did);
(select ename,dname from emp left outer join dept on deptid=did) union (select ename,dname from emp right outer join dept on deptid=did);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号