一、nova介绍:

















-
客户(可以是 OpenStack 最终用户,也可以是其他程序)向 API(nova-api)发送请求:“帮我创建一个虚机”
-
API 对请求做一些必要处理后,向 Messaging(RabbitMQ)发送了一条消息:“让 Scheduler 创建一个虚机”
-
Scheduler(nova-scheduler)从 Messaging 获取到 API 发给它的消息,然后执行调度算法,从若干计算节点中选出节点 A
-
Scheduler 向 Messaging 发送了一条消息:“在计算节点 A 上创建这个虚机”
-
计算节点 A 的 Compute(nova-compute)从 Messaging 中获取到 Scheduler 发给它的消息,然后在本节点的 Hypervisor 上启动虚机。
-
在虚机创建的过程中,Compute 如果需要查询或更新数据库信息,会通过 Messaging 向 Conductor(nova-conductor)发送消息,Conductor 负责数据库访问。

1、界面或命令行通过RESTful API向keystone获取认证信息。
2、keystone通过用户请求认证信息,并生成auth-token返回给对应的认证请求。
3、界面或命令行通过RESTful API向nova-api发送一个boot instance的请求(携带auth-token)。
4、nova-api接受请求后向keystone发送认证请求,查看token是否为有效用户和token。
5、keystone验证token是否有效,如有效则返回有效的认证和对应的角色(注:有些操作需要有角色权限才能操作)。
6、通过认证后nova-api和数据库通讯。
7、初始化新建虚拟机的数据库记录。
8、nova-api通过rpc.call向nova-scheduler请求是否有创建虚拟机的资源(Host ID)。
9、nova-scheduler进程侦听消息队列,获取nova-api的请求。
10、nova-scheduler通过查询nova数据库中计算资源的情况,并通过调度算法计算符合虚拟机创建需要的主机。
11、对于有符合虚拟机创建的主机,nova-scheduler更新数据库中虚拟机对应的物理主机信息。
12、nova-scheduler通过rpc.cast向nova-compute发送对应的创建虚拟机请求的消息。
13、nova-compute会从对应的消息队列中获取创建虚拟机请求的消息。
14、nova-compute通过rpc.call向nova-conductor请求获取虚拟机消息。(Flavor)
15、nova-conductor从消息队队列中拿到nova-compute请求消息。
16、nova-conductor根据消息查询虚拟机对应的信息。
17、nova-conductor从数据库中获得虚拟机对应信息。
18、nova-conductor把虚拟机信息通过消息的方式发送到消息队列中。
19、nova-compute从对应的消息队列中获取虚拟机信息消息。
20、nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求glance-api获取创建虚拟机所需要镜像。
21、glance-api向keystone认证token是否有效,并返回验证结果。
22、token验证通过,nova-compute获得虚拟机镜像信息(URL)。
23、nova-compute通过keystone的RESTfull API拿到认证k的token,并通过HTTP请求neutron-server获取创建虚拟机所需要的网络信息。
24、neutron-server向keystone认证token是否有效,并返回验证结果。
25、token验证通过,nova-compute获得虚拟机网络信息。
26、nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求cinder-api获取创建虚拟机所需要的持久化存储信息。
27、cinder-api向keystone认证token是否有效,并返回验证结果。
28、token验证通过,nova-compute获得虚拟机持久化存储信息。
29、nova-compute根据instance的信息调用配置的虚拟化驱动来创建虚拟机。
1、控制节点上操作查看计算节点,删除node1
|
1
2
|
openstack host listnova service-list |
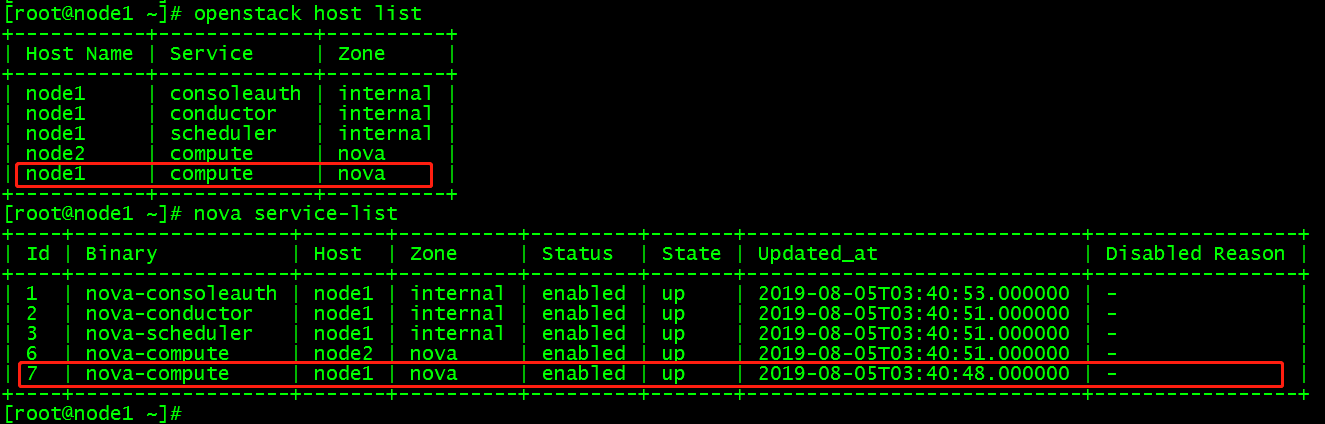
2、将node1上的计算服务设置为down,然后disabled
|
1
2
|
systemctl stop openstack-nova-computenova service-list |

|
1
2
|
nova service-disable node1 nova-computenova service-list |

3、在数据库里清理(nova库)
(1)参看现在数据库状态
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
[root@node1 ~]# mysql -u root -pEnter password:Welcome to the MariaDB monitor. Commands end with ; or \g.Your MariaDB connection id is 90Server version: 10.1.20-MariaDB MariaDB ServerCopyright (c) 2000, 2016, Oracle, MariaDB Corporation Ab and others.Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.MariaDB [(none)]> use nova;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedMariaDB [nova]> select host from nova.services;+---------+| host |+---------+| 0.0.0.0 || 0.0.0.0 || node1 || node1 || node1 || node1 || node2 |+---------+7 rows in set (0.00 sec)MariaDB [nova]> select hypervisor_hostname from compute_nodes;+---------------------+| hypervisor_hostname |+---------------------+| node1 || node2 |+---------------------+2 rows in set (0.00 sec) |
(2)删除数据库中的node1节点信息
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
MariaDB [nova]> delete from nova.services where host="node1";Query OK, 4 rows affected (0.01 sec)MariaDB [nova]> delete from compute_nodes where hypervisor_hostname="node1";Query OK, 1 row affected (0.00 sec)MariaDB [nova]>MariaDB [nova]>MariaDB [nova]>MariaDB [nova]> select host from nova.services;+---------+| host |+---------+| 0.0.0.0 || 0.0.0.0 || node2 |+---------+3 rows in set (0.00 sec)MariaDB [nova]> select hypervisor_hostname from compute_nodes;+---------------------+| hypervisor_hostname |+---------------------+| node2 |+---------------------+1 row in set (0.00 sec)MariaDB [nova]> |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号