数据结构与算法之美 - 王争
1
基础知识就像是一座大楼的地基,它决定了我们的技术高度。而要想快速做出点事情,前提条件一定是基础能力过硬,“内功”要到位。(内功:操作系统、计算机网络、编译原理)
学习数据结构和算法,并不是为了死记硬背几个知识点。我们的目的是建立时间复杂度、空间复杂度意识,写出高质量的代码,能够设计基础架构,提升编程技能,训练逻辑思维,积攒人生经验,以此获得工作回报,实现你的价值,完善你的人生。
掌握了数据结构与算法,你看待问题的深度,解决问题的角度就会完全不一样。
2
从广义上讲,数据结构就是一组数据的存储结构。算法就是操作数据的一组方法
图书馆储藏书籍你肯定见过吧?为了方便查找,图书管理员一般会将书籍分门别类进行“存储”。按照一定规律编号,就是书籍这种“数据”的存储结构
从狭义上讲,是指某些著名的数据结构和算法,比如队列、栈、
堆、二分查找、动态规划等。我们可以直接拿来用,可以高效地帮助我们解决很多实际的开发问题
数据结构是为算法服务的,算法要作用在特定的数据结构之上。
数据结构是静态的,它只是组织数据的一种方式。如果不在它的基础上操作、构建算法,孤立存在的数据结构就是没用的
要学习数据结构与算法,首先要掌握一个数据结构与算法中最重要的概念——复杂度分析
数据结构和算法解决的是如何更省、更快地存储和处理数据的问题,因此,我们就需要一个考量效率和资源消耗的方法,这就是复杂度分析方法
20个最常用的、 最基础数据结构与算法,不管是应付面试还是工作需要,只要集中精力逐一攻克这20个知识点就足够了
这里面有:
10个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树;
10个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
掌握了这些基础的数据结构和算法,再学更加复杂的数据结构和算法,就会非常容易、非常快
在学习数据结构和算法的过程中,你也要注意,不要只是死记硬背,不要为了学习而学习, 而是要学习它的“来历”“自身的特点”“适合解决的问题”以及“实际的应用场景”
学习数据结构和算法的过程,是非常好的思维训练的过程,所以,千万不要被动地记忆,要多辩证地思考,多问为什么。如果你一直这么坚持做,你会发现,等你学完之后,写代码的时候就会不由自主地考虑到很多性能方面的事情,时间复杂度、空间复杂度非常高的垃圾代码出现的次数就会越来越少。你的编程内功就真正得到了修炼。
学习技巧
1.每周花 1~2 个小时的时间,集中把这周的三节内容 涉及的数据结构和算法,全都自己写出来,用代码实现一遍
2.学习的目的还是掌握,然后应用
3.找到几个人一起学习,一块儿讨论切磋,有问题及时寻求老师答疑
4.我们在枯燥的学习过程中,也可以给自己设立一个切实可行的目标
5.知识需要沉淀,不要想试图一下子掌握所有,学习知识的过程 是反复迭代、不断沉淀的过程
3.如何分析、统计算法的执行效率和资源消耗?
执行效率是算法一个非常重要的考量指标
我们需要一个不用具体的测试数据来测试,就可以粗略地估计算法的执行效率的方 法。这就是我们今天要讲的时间、空间复杂度分析方法
大 O 复杂度表示法
算法的执行效率,粗略地讲,就是算法代码执行的时间。
这里有段非常简单的代码,求 1,2,3...n 的累加和。现在,我就带你一块来估算一下这段代码的执行时间,假设每行代码执行的时间都一样,为 unit_time
int cal(int n) {
int sum = 0;
int i = 1;
for (; i <= n; ++i) {
sum = sum + i;
}
return sum;
}
第 2、3 行代码分别需要 1 个 unit_time 的执行时间,第 4、5 行都运行了 n 遍,所以需要 2n * unit_time 的执行时间,所以这段代码总的执行时间就是 (2n+2) * unit_time。
可以看出来,所有代码的执行时间 T(n) 与每行代码的执行次数成正比
按照这个分析思路,我们再来看这段代码。
int cal(int n) {
int sum = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum = sum + i * j;
}
}
}
第 2、3、4 行代码,每行都需要 1 个 unit_time 的执行时间,第 5、6 行代码循环执行了 n 遍,需要 2n * unit_time 的执行时间,第 7、8 行代码循环执行了遍,所以需要
- unit_time 的执行时间。所以,整段代码总的执行时间 T(n) = (+2n+3)*unit_time
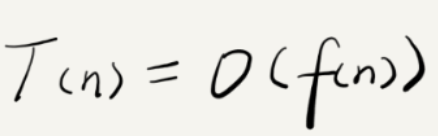
总结
T(n) 表示代码执行的时间;
n表示数据规模的大小;
f(n)表示每行代码执行的次数总和
因为这是一个公式,所以用 f(n) 来表示。
公式中的 O,表示代码的执行时间 T(n) 与 f(n) 表达式成正比。
T(n) = O(2n+2),T(n) = O(+2n+3) 这就是大O时间复杂度表示法。大O时间复杂度表示代码执行时间随数据规模增长的变化趋势,也叫作渐进时间复杂度,简称时间复杂度
当 n 很大时,公式中的低阶、常量、系数三部分都可以忽略。我们只需要记录一个最大量级就可以了,如果用大 O 表示法表示刚讲的那两段代码的时间复杂度,就可以记为:T(n) = O(n); T(n) = O()。
时间复杂度分析
1. 只关注循环执行次数最多的一段代码
大 O 这种复杂度表示方法只是表示一种变化趋势,我们在分析一个算法、一段代码的时间复杂度的时候,也只关注循环执行次数最多的那一段代码就可以了。这段核心代码执行次数的 n 的量级,就是整段要分析代码的时间复杂度。
举一个例子:
int cal(int n) {
int sum = 0;
int i = 1;
for (; i <= n; ++i) {
sum = sum + i;
}
return sum;
}
其中第 2、3 行代码都是常量级的执行时间,与 n 的大小无关,所以对于复杂度并没有影响。循环执行次数最多的是第 4、5 行代码,所以这块代码要重点分析。前面我们也讲过, 这两行代码被执行了 n 次,所以总的时间复杂度就是 O(n)。
2. 加法法则:总复杂度等于量级最大的那段代码的复杂度
举例:

这个代码分为三部分,分别是求 sum_1、sum_2、sum_3。我们可以分别分析每一部分的时间复杂度,然后把它们放到一块儿,再取一个量级最大的作为整段代码的复杂度。
第一段的时间复杂度是多少呢?这段代码循环执行了 100 次,所以是一个常量的执行时 间,跟 n 的规模无关。
这里我要再强调一下,即便这段代码循环 10000 次、100000 次,只要是一个已知的数, 跟 n 无关,照样也是常量级的执行时间。当 n 无限大的时候,就可以忽略。尽管对代码的 执行时间会有很大影响,但是回到时间复杂度的概念来说,它表示的是一个算法执行效率与 数据规模增长的变化趋势,所以不管常量的执行时间多大,我们都可以忽略掉。因为它本身 对增长趋势并没有影响。
那第二段代码和第三段代码的时间复杂度是多少呢?答案是 O(n) 和 O(n2),你应该能容易 就分析出来,我就不啰嗦了。
综合这三段代码的时间复杂度,我们取其中最大的量级。所以,整段代码的时间复杂度就为 O(n2)。也就是说:总的时间复杂度就等于量级最大的那段代码的时间复杂度。那我们将这 个规律抽象成公式就是:
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)+T2(n)=max(O(f(n)), O(g(n))) =O(max(f(n), g(n))).
3. 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)T2(n)=O(f(n))O(g(n))=O(f(n)*g(n)).

我们单独看 cal() 函数。假设 f() 只是一个普通的操作,那第 4~6 行的时间复杂度就是, T1(n) = O(n)。但 f() 函数本身不是一个简单的操作,它的时间复杂度是 T2(n) = O(n),所 以,整个 cal() 函数的时间复杂度就是,T(n) = T1(n) * T2(n) = O(n*n) = O()。
我刚刚讲了三种复杂度的分析技巧。不过,你并不用刻意去记忆。实际上,复杂度分析这个
东西关键在于“熟练”。你只要多看案例,多分析,就能做到“无招胜有招”。
几种常见时间复杂度实例分析
虽然代码千差万别,但是常见的复杂度量级并不多。我稍微总结了一下,这些复杂度量级几乎涵盖了你今后可以接触的所有代码的复杂度量级。

对于刚罗列的复杂度量级,我们可以粗略地分为两类,多项式量级和非多项式量级。其中, 非多项式量级只有两个:O(2n) 和 O(n!),非多项式时间复杂度的算法其实是非常低效的算法。
我们主要来看几种常见的多项式时间复杂度
1. O(1)
O(1) 只是常量级时间复杂度的一种表示方法,并不是指只执行 了一行代码。比如这段代码,即便有 3 行,它的时间复杂度也是 O(1),而不是 O(3)。

一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)
2. O(logn)、O(nlogn)
对数阶时间复杂度非常常见,同时也是最难分析的一种时间复杂度。我通过一个例子来说明一下。

则 x = 所以,这段代码的时间复杂度就 是 O(log2n)。

这段代码的时间复杂度为 O(log_3n)
实际上,不管是以 2 为底、以 3 为底,还是以 10 为底,我们可以把所有对数阶的时间复 杂度都记为 O()。为什么呢?
我们知道,对数之间是可以互相转换的, 就等于 * ,所以 O() = O(C * ),其中 C= 是一个常量。基于我们前面的一个理论:在采用大 O 标记复 杂度的时候,可以忽略系数,即 O(Cf(n)) = O(f(n))。所以,O(log2n) 就等于 O(log3n)。 因此,在对数阶时间复杂度的表示方法里,我们忽略对数的“底”,统一表示为 O(logn)
如果一段代码的时间复杂度是 O(logn),我们循环执行 n 遍,时间复杂度就是 O(nlogn) 了。而且,O(nlogn) 也是一种非常常见的算法时间复杂度。比如,归并排序、快速排序的时间复杂度都是 O(nlogn)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话