大型分布式C++框架《二:大包处理过程》
本来这一篇是打算写包头在分布式平台中的具体变换过程的。其实文章已经写好了。但是想了这个应该是不能随便发表的。毕竟如果知道了一个包的具体每个字节的意义。能伪造包来攻击系统。其次来介绍一个包的具体变换过程意义不大。在每个分布式系统的里。包的扭转应该是个有不同。我们着重的应该是一种思想。一种共性。而不是个体的具体实现。
这里打算就介绍下大包的处理。其实这个更多的是介绍了下TCP切包。跟分布式没啥关系。。。。 不过这也算是系统的一部分
下面介绍下一个大包的具体处理过程
一、发送请求并分析
1)首先我们在客户端发送一个超过1M 的包给客户端处理,结果是服务端只收了一次recv就拒绝了
2)为了更清晰 我们用tcpdump来抓包处理
注意由于是在本机上发送包接收包。所以走的是回路。即网卡lo 而不是eth0.抓包的时候 需要抓lo 否则看不到数据
[root@localhost git]# tcpdump -i lo port 53101 -w ./target.cap
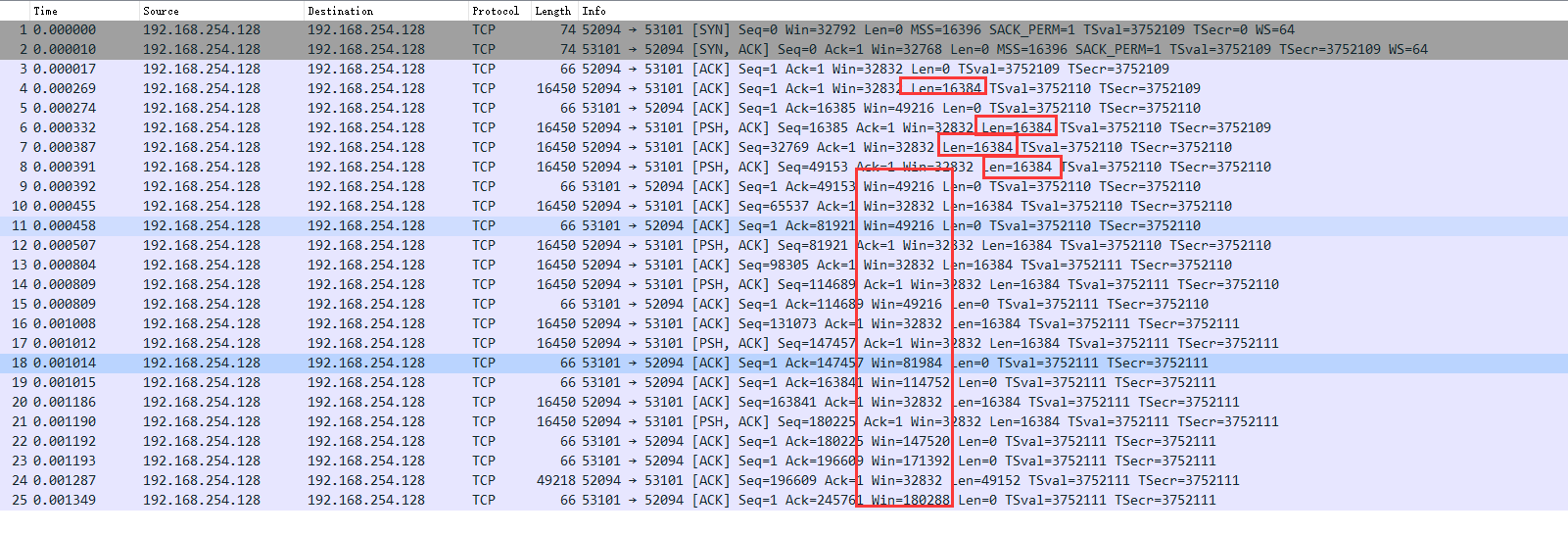
拿到数据以后放到wireshark里分析

a)为什么最大协商是16396 而实际收了16384个字节
可以看到协商的mss最大传输单元为16396
但是显示netio revc只收到了16384个字节。
所以实际是16396-12 = 16384
所以neito一次收到的是16384个字节。
注意这里的测试环境是本机回路。
如果是在公网上。
一次TCP能承载的最大数据包 应该是 1448(1500MTU-20 IP包头 -20TCP包头 -12时间戳)
(具体且包的原理请看下面)
能revc的数据跟TCP的接收缓冲队列有关。
b)为什么本机就只收了一次 mss ?
sysctl -a | grep net.ipv4.tcp_wmem
net.ipv4.tcp_wmem = 4096 16384 81920
第二个值是send默认发送缓冲区字节的个数
所以send一次 16384个字节 然后mss的大小刚好协商的是16396。 所以就被recv一次收到了。
正常在公网下。send 的16384个字节会被TCP切成11个包发到netio。
TCP会在接受端组包。但是不一定会一下都收到这11个包。可能就收到5个 然后组包给recv来处理。然后继续循环recv。还收下面的6个包.组包给recv
所以netio会根据缓冲队列已经网路情况 recv到部分字节或者全部的16384个字节。
这里如果send的数据大于 16384 个字节。那么就是循环上面的步骤 .
c)为什么服务端拿到一次recv就之间关闭请求了。
因为我们服务端允许客户端传来的请求必须小于1M.所以拿到一次recv以后。就可以解析包头。发现客户端到底需要发送多少个字节。
超过1M 我们认为就是非法包。直接拒绝并关闭客户端连接。
二、接下来我们来分析一个服务端能处理的大包
1、我们发送一个262360 个字节包给服务端
2、这里注意下epoll收包的写法
当recv完一个包的时候。如果正确。就会回到最开始的while循环然后继续监听 epoll。然后会触发E_TCP_CONN事件。
看如下图。收完一个recv就会跳到while。继续epoll wait 来收下一包。反复如此直到收完一个完整的包
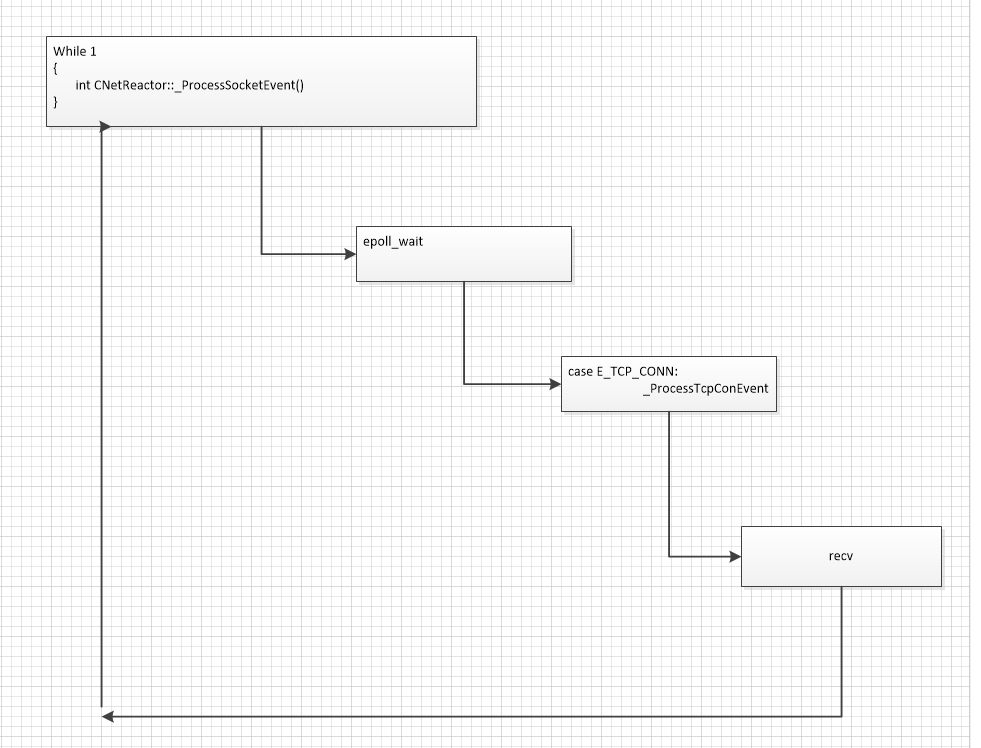
注意早期的写法是这样的。直接在while循环里收recv。 这是在阻塞机制下的写法。
我们用到epoll. 可以不用阻塞在recv 可以等待事件触发读取。
可以自己比对下
while(1)
{
cnt = (int)recv(m_socket, pBuf,RECVSIZE, 0);
if( cnt >0 )
{
//正常处理数据
}
else
{
if((cnt<0) &&(errno == EAGAIN||errno == EWOULDBLOCK||errno == EINTR))
{
continue;//继续接收数据
}
break;//跳出接收循环
}
}
3、结果以及分析
最后收到的结果如下 收了11次。总共262360个字节 m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072 m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072 m_iRecvBufLen:32768 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072 m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072 m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072 m_iRecvBufLen:65536 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072 m_iRecvBufLen:32768 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072 m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072 m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072 m_iRecvBufLen:16384 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072 m_iRecvBufLen:16602 sizeof(m_achRecvBuf):131072 TPT_RECV_BUF_LEN:131072
我们看到每次发送的length都是16384 但是由于滑动窗口win。时大时小。发送的速度。不一样。导致recv一次能收到的数据也是不一样的
收到这些包。把他们组成一个完整的包。即发送端发过来的262360的包
开始跳到int CNetioApp::OnRecv(int iTcpHandle,char* pBuffer,uint32_t nBufLen)处理
后面就是常规逻辑了。丢到container的请求消息队列。
然后container处理完丢到netio的回包队列。
最后netio拿到包返回给前端
这里最后总结:
1、这里对分布式平台来说。会有一个专门收包的进程。只负责收包和转发。本身没有业务处理。它收到包以后会打上时间戳或者其他一些基本信息。然后把包丢给其他业务进程处理。然后等包回来了在把处理完后的包返回给前端。如果需要请求的服务不再本机。会有另一个转发器。把请求包发送大分布式中的其他服务处理。这里先说下大概的功能。后面会单独开篇介绍我们的netio。
2、收包并不是一次全收完才可以处理。一般一次recv以后。拿到固定包头信息就可以来判断包的一些基本状态。可以分析是不是系统想要的包、允许的包
3、理解下TCP的一些基本原理。
a)假如我们在TCP层用更大的数据量来打包会有什么结果呢?
答案是降低了传输效率。
答案是降低了传输效率。
分片最大的坏处就是降低了传输性能,本来一次可以搞定的事情,分成多次搞定,所以在网络层更高一层(就是传输层)的实现中往往会对此加以注意!
这个就是在以太网上,TCP不发大包,反而发送1448小包的原因。只要这个值TCP才能对链路进行效能最高的利用。
这个就是在以太网上,TCP不发大包,反而发送1448小包的原因。只要这个值TCP才能对链路进行效能最高的利用。
所以TCP在发包的时候已经切好大小刚好的包。不需要IP层再去切包
b)简单来说 滑动窗口是用来控制发送速度的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号