

SmartNIC 与普通的NIC 有哪些显著性差异?
http://xilinx.eetrend.com/content/2020/100054808.html
judy 在 周六, 10/10/2020 - 11:35 提交
作者:Scott Schweitzer,来源:Xilinx赛灵思官微
普通 NIC 定位于高效迁移服务器的网络数据包,通常包括不同程度的为优化性能而设计的传统卸载。SmartNIC 整合了多方面的附加计算资源,但是这些架构就像雪花一样各不相同,因此,我们将深入研究规模最大、最受欢迎的供应商所提供的几种方法。
普通网络接口卡(NIC)是围绕单独的专用集成电路(ASIC)构建的,该集成电路被设计成以太网控制器。例如,迈络思的 ConnectX® 系列、博通的 NetXtreme® 系列或赛灵思的 XtremeScale® 系列。通常,这些芯片会围绕第二个设计目标进行进一步优化;例如,ConnectX 系列也支持 Infiniband,而 XtremeScale 则专注于 Linux 内核旁路。这些控制器的功能非常出色,它们代表了业界最出色的控制器,但它们不能算是 SmartNIC。
在本文中,我们将 SmartNIC 定义为一个允许附加软件的 NIC,而这些附加软件可以在购买后的某个时刻被加载到 NIC 中,用于添加新功能或支持其他功能。就像您购买了一部智能手机,然后从该供应商的应用商店下载并安装应用一样。
若要将 NIC 变为 SmartNIC,能够加载并运行代码,需要其配备额外的计算能力和板载存储器,而这些功能是普通 NIC 所不具备的。SmartNIC 的应用大多数都是从基本的以太网控制器开始,要么在芯片上作为固件,要么在适配器上作为单独的芯片。
以下三种方法均有助于提升计算能力,使得普通的 NIC 变得智能:
- Arm CPU 核集成,有人称其为集群,有些人则称其为“网格”或“块”
- 定制网络处理器采用的流处理核(FPC),通常是 P4
- 现场可编程门阵列(FPGA),可编程逻辑
许多 SmartNIC 通常使用一个或多个 Arm CPU 核来管理 NIC 中的控制平面。有些甚至允许将修改过的 Linux 内核加载到一个或多个核心中。这些 Arm CPU 核通常负责将代码加载到其他处理元件中,收集统计信息和日志并监测 SmartNIC 的运行状况和配置。它们不会接触任何网络数据包,且通常会在“带外”运行,这就意味着它们无法通过“常规”网络接口或 PCIe 命令进行访问。此外,他们只应通过先前受保护的接口接受经过正式签署的固件包。除了架构草图以外,我们不会在下面调用这些控制平面的 Arm CPU 核,因为它们需要管道,而且它们本身通常不会为 SmartNIC 提供的特性集增加价值。
为了理解 SmartNIC 与普通 NIC 的不同之处,我们需要深入了解全球四大 NIC 公司以及两家初创企业推出的 SmartNIC 产品,看看他们做出了哪些改进。入选的六家公司分别是英特尔、博通、英伟达(前身为迈络思)、赛灵思、Netronome 和 Pensando。此外,我们还将对目前被称为 Fungible 的隐形项目提出一些见解。
说到芯片公司,大家都会想到英特尔,因为它是全球规模最大的芯片公司。十多年来,英特尔一直保持着不间断的高性能 10GbE 以太网控制器产品线。他们的 XL710 平台已经出货数百万台,是众多数据中心服务器的必备产品。对于其新款 N3000,英特尔 SmartNIC 的电路板采用五块芯片。
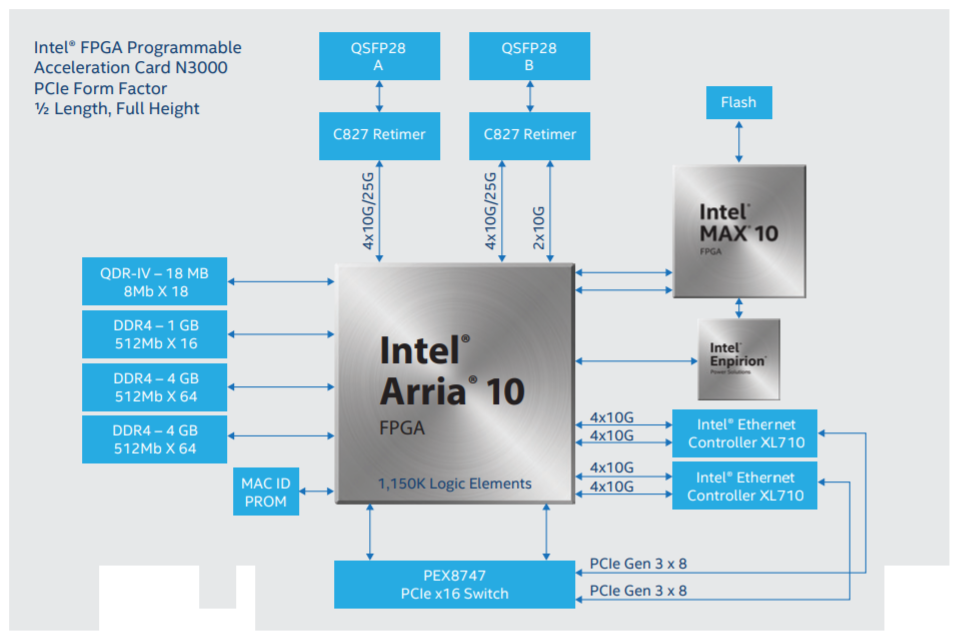
这种方法成本很高,因为大多数厂商都在努力完成单芯片设计。英特尔还将一对 XL710 以太网控制器和一个使用 48 通道的第三代 PEX8747 PCIe 交换芯片的 Arria 10 FPGA 融合在一起。每个 XL710 有 8 个通道,Arria 有 16 个通道,PCIe 插槽有 16 个通道。第五块芯片是用于管理 FPGA 的 MAX 10® FPGA 基板管理控制器(BMC),就像在其他 SmartNIC 上使用 Arm 核心来处理控制平面管理一样。该电路板有两个直接连接到 FPGA 的 QSFP28 端口。然后 8 条 10G 通道将 FPGA 留给每个 XL710。这是一种典型的 bump-in-the-wire 架构,它使 FPGA 能够在数据包被传递到 XL710 之前处理数据包。
使用现成的以太网控制器和 FPGA 构建 NIC 并不是什么新鲜事。早在 2012 年,Solarflare Communications 就在 NIC 的两个 QSFP 端口与其以太网控制器之间放置了一个 FPGA,用于创建其应用加载引擎( AOE )平台。这是上述英特尔 N3000 设计的先驱,它帮助 Solarflare 为金融客户提供了令人印象深刻的即时交易结果,耗时仅为 350 纳秒。8 年后的今天,该记录为 24.2 纳秒。英特尔的方法支持 FPGA 在 XL710 之前进行数据包处理。
英特尔的 FPGA 具有 115 万个可编程逻辑单元和两个 4GB 的 DDR4 存储器组,这为它处理以下 SmartNIC 任务提供了充足的空间:
- 虚拟宽带网络网关(vBNG)
- 层级服务质量(HQoS)
- 数据包分类、监控、调度和成形
- 虚拟化演进分组核心(vEPC)
- 5G 新一代核心网络(NGCN)
- 互联网协议安全(IPSec)
- IPv6 分段路由(SRv6)
- 矢量数据包处理(VPP)
- 虚拟无线电接入网(vRAN)
尽管英特尔已将上述工作负载用于其 N3000 平台,但目前还不清楚他们是否已交付所有必要的软件来卸载该 SmartNIC 上的每个应用。SmartNIC 的消费者会发现,软件才是症结所在,所有这些公司在硬件方面都很出色,但是软件交付又完全是另一回事。
SmartNIC 领域中另一家杰出的 FPGA 供应商是赛灵思,它是上世纪 80 年代中期首家实现 FPGA 商业化的公司。现如今,赛灵思已经是 FPGA 领域的霸主,英特尔则被远远地甩在后面。赛灵思于 2019 年秋季收购了 Solarflare Communications,自 2012 年以来,Solarflare 一直在为电子交易构建基于 ASIC 和 FPGA 的 NIC。来自英国剑桥的 SolarFarre 工程团队是赛灵思 Alveo U25 SmartNIC 的研发主力,如图所示。赛灵思的成功得益于 Solarflare 工程团队在这个市场中将近十年的经验积累。

Alveo U25 将双 SFP28 端口直接连接到 Zynq 系列芯片。Zynq 实际上是一种片上系统(SoC),因为它不仅包括 FPGA,还包括用于数据包处理的四核 Arm A53。然后,Zynq 通过第三代 PCIe 提供的 8 个通道直接连接到主机服务器,或是通过 SerDes 连接到 X2 以太网控制器芯片,后者也可以通过第三代 PCIe 8 个通道连接到主机。这种方法使得 Zynq 能够在数据包被传递到 X2 芯片之前对其进行处理,或者完全绕过 X2 芯片。此外,U25 还包括 6GB 的 DDR4 存储器,可以通过运行在该芯片上的程序访问 Zynq 的 FPGA 和 Arm 核心。FPGA 具有 52 万个逻辑单元,是英特尔提供的逻辑单元数的一半,但是提供的四核 Arm 足以弥补减少的可用门数。
赛灵思将 U25 推向市场,最初是为了满足那些需要开放虚拟交换机(OvS) 卸载功能的客户。赛灵思已经宣布,在不久的将来将增加 IPSec、机器学习(ML)、深度包检测(DPI)、视频转码和分析的卸载数量。赛灵思大概是 SmartNIC 领域中发展最为全面的企业。两年前,在收购 Solarflare 的准备阶段,赛灵思与 Solarflare 作为合作伙伴在 OCP 峰会上公开展示了 X2 控制器逻辑作为软 NIC 在更大型 FPGA 中的运行情况。
如同英特尔一样,赛灵思也拥有数条可盈利的计算芯片产品线,如 Kintex、Virtex、Zynq 和 Versal。Kintex 和 Virtex 都是纯 FPGA,该系列中某些型号采用的逻辑单元数量巨大,大约有近 300 万个,几乎是英特尔在其 N3000 中使用数量的三倍。此外,赛灵思还通过硅中介层创造了奇迹,并在 Virtex 芯片上分层放置了高达 16GB 的高带宽存储器(HBM)。所有四条芯片生产线的其他芯片也采用了这项技术。Zynq 是他们的 SoC 芯片系列,包括 FPGA 可编程逻辑、四核 Arm、实时 Arm 核心、DDR 控制器以及用于以太网和 PCI Express 的连接逻辑。
Versal 超越了 SoC,成为一个基于七纳米芯片技术的自适应计算加速平台(ACAP)。ACAP 通过添加数百个人工智能(AI)核心和数字信号处理(DSP)引擎来扩展 Zynq 架构。AI 核心在某种程度上是新器件,但它们在本质上属于单精度计算引擎。最终,赛灵思将把其公开展示的 SoftNIC 与 Versal 结合起来,使其成为 SmartNIC 平台中的佼佼者。
博通是以太网 NIC 控制器商品市场上无可争议的领导者。因此,当他们装配 Stingray SmartNIC 并加入竞争时,博通采用了单芯片方法。与其他竞争对手的众多芯片板相比,单芯片 SmartNIC 解决方案的板级生产成本始终保持在较低水平。博通以 NetXtreme E 系列控制器的逻辑为基础,设计了位于 Stingray 核心的 NetXtreme-S BCM58800 芯片。然后,他们在集群配置中部署了主频为 3Ghz 的 8 个 Arm v8 A72 核心。
接下来,他们加入了一些逻辑,以高达 90 千兆/秒的速度卸载加密,同时卸载擦除编码和 RAID 等存储处理。最后,博通还采用了具有神秘色彩的 TruFlow® 技术。这是一个可配置的流加速器,用于将常见的网络流过程转移到硬件中;我们相信使用 P4 语言会取得很好的效果。这有助于释放 Arm 核心,从而专注于流程和数据包级别上的更多可编程任务。
从发布的内容来看,TruFlow 能够在硬件中分担像 Open vSwitch(OvS)这样的任务。此外,博通还声称 TruFlow 在硬件中实现了众多经典的软件定义网络(SDN)概念,例如分类、匹配和操作。因此,Stingray 配备了两个可编程组件,即 TruFlow 和一个由四个 3Ghz 双核 Arm v8 A72 复合体组成的集群。了解到他们所提供产品的复杂性后,博通为 SmartNIC 应用开发和存储控制器开发提供了 Stingray 开发套件。这确实出乎大家的意料。
英伟达在图形处理单元(GPU)领域是公认的领导者,GPU 已经成为高性能计算(HPC)领域的首选加速器。今年年初,英伟达最终以 70 亿美元的价格完成了对迈络思的收购。为了占领 HPC 市场,英伟达选择了领先的无限带宽技术互联供应商,以便为 HPC 客户提供完整的解决方案。这与克雷过去的做法非常相似。英伟达最近还收购了 Cumulus Networks,后者是开源以太网交换机操作系统的领导者。软件一直是迈络思的弱点,而英伟达显然很早就意识到了这一点。关于 SmartNIC,英伟达还通过收购迈络思得到了一个意外惊喜。
迈络思是最早进入 SmartNIC 领域的公司之一,但这是通过收购实现的。他们当前的 Bluefield 2 解决方案是在 2015 年通过收购 EZchip 收购 Tilera 而完成构建的。Tilera 拥有首个申请知识产权的高度并行 SmartNIC 实现方案,它是从更早的 MIT 研究项目逐步发展起来的。Tilera 将处理核心作为芯片上的块进行排列,每个核心都有一条高速总线连接到周围的四个核心。他们的旗舰产品早在 2013 年就可支持多达 72 个 MIPS 核心、内存控制器、加密模块、PCIe 块和 mPipe,这是通过 SFP 和连接器连接到多个 MAC 的一组通道。

迈络思通过用 Arm 替换核心并将 mPipe 换成 ConnectX 逻辑来推进这一进程。当前的核心数量为 8 个 Arm v8 A72 核心,但它们被排列成由 4 个双核心 Arm 构成的群集。这种方法与博通的 Stingray 十分类似,它们不仅使用相同的核心,而且速度相同,但是它缺少 Broadcom 架构的核心组成部分,即并行 P4 处理器。P4 是每家公司的目标,只不过并不是每家公司都对此公开表明。下面提到的博通、赛灵思和 Pensando 都很关注 P4。这也是 Cumulus Networks 的用武之地,他们在 P4 编程方面有着丰富的经验。因此,为了向未来的 Bluefield 产品系列提供前端服务,英伟达设计了 P4 数据包处理引擎也就不足为奇了。
最新的 SmartNIC 初创企业是 Pensando,由思科前首席执行官 John Chambers 创立。John 带领他的梦之队(六名前思科员工)创办了这家公司。这些人的公司过去都曾被思科收购。考虑到他们的声誉和以往的经验,人们普遍认为 Pensando 正在向一些主要客户证明他们的技术是可行的,然后他们会将其打包卖给思科。思科拥有一些通用的 NIC 技术,但它不是 SmartNIC 级别的,Pensando 显然是想填补这一空白。
Pensando 最初提供两种产品,但最近又降为单一产品,即分布式服务卡 DSC-25,这听起来甚至像是思科产品的名称。它像是一款单一的 P4 处理器芯片,带有用于一些辅助处理的 Arm,数据表声称这两种处理器都可支持高达 4GB 的板载存储器。该处理器称为 Capri,它是带有多个并行级的 P4 可编程单元;但确切的并行处理程度尚不清楚,因为数据包性能、时延和抖动尚未公布。由于缓存未命中而导致的指令内存提取会影响所有指标的性能,所以 Pensando 妥善管控 P4 应用,将它们保留在 Capri 缓存中。其他被称为服务处理卸载(Service Processing Offloads)的计算单元则负责处理加密、存储流程和其他任务。
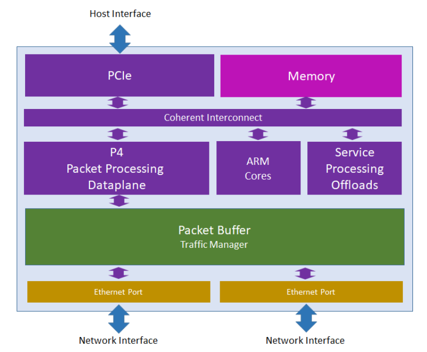
Pensando 声称 Capri 能够提供线速性能。Fungible 是颇具潜力的后起之秀。在获得了近 3 亿美元的三轮融资(其中 2 亿美元来自去年的 C 轮软银集团愿景基金)后,他们宣布即将推出一款新产品。目前,他们有 180 名员工,没有产品,没有收入,也没有可见客户。Fungible 声称将生产数据处理单元(DPU),但实际的架构和组成尚不明朗。他们提供了下面所示的图片,但如同架构图不具备重要意义一样没有突出重点。
很多文章都提到他们的产品将在今年夏天发布,因此我想提醒大家关注这家公司。他们的创始人之一兼首席架构师是曾在 Chelsio Communications 积累了 10 年经验的资深人士,专门从事以存储为中心的以太网 NIC 方面的研究。此外,他们的软件和固件工程副总裁也曾在 Chelsio 任职,而且他的工作经验有 13 年之久。因此,尽管 Chelsio 过去的核心产品是 ASIC,但如今从头开始生产一款领先的 SmartNIC 以太网控制器 ASIC 很容易就会消耗掉他们超过 5000 万美元的宝贵资本。
有人推测,他们将采取阻力最小的方法来获得收益,并利用 FPGA 平台开发他们的初始产品,同时将特有的 ASIC 设计加载到该平台。随后,他们可以在开始追求客户和收益的同时推出设计方案。将设计加载到 FPGA 中有助于 Fungible 轻松地修复设计缺陷,并可以根据客户要求快速改善。如今,FPGA 的应用越来越广泛,我们已经开始看到像 RISC-V 这样成熟的处理器架构被加载到这些平台上。
那么,SmartNIC 与普通的 NIC 有哪些显著性差异?计算能力、存储器以及最重要的软件设计都是为了减轻主机 CPU 的负担,以完成更高级的网络处理任务 SmartNIC 将推动计算能力逐渐扩展到网络边缘,从而释放服务器 CPU 的算力,重点关注复杂的业务关键型处理任务。研究表明,在高度虚拟化的环境中,网络可以消耗主机 CPU 周期的多达 30% 来处理 OvS 事务等任务。试想一下,在 SmartNIC 中能够完成存储功能、加密、深度包检测和复杂路由吗?这可能会将通常花费在处理这些工作负载上的大部分 CPU 周期传递回主机 CPU。
为了保持领先地位,Pensando 和 Fungible 这样的新兴公司将继续向 SmartNIC 市场注入创新特性和功能。与此同时,像赛灵思、英特尔、博通和英伟达这样的技术领先者也开始着手改进基础计算核心和专用 P4 处理引擎。SmartNIC 市场正在升温,而这只是从 GPU 技术开始兴起的加速器浪潮的边缘领域,但它将改变计算技术的发展方向。
作者介绍:
姓名:Scott Schweitzer
职位:赛灵思技术布道者
个人简介:
自从当年通过 TRS-80 计算机入门编程的世界,Scott 便成为了一名忠实的科技信徒。他曾为 IBM、NEC、Solarflare 以及现在的赛灵思编写过产品级的软件产品,构建过硬件产品,并担任过程序管理职务。在从事单插槽计算平台工作 20 年后,Scott 于 2003 年加入 NEC,管理其新推出的英特尔安腾(Itanium)多核 64 位超级计算服务器。自此,他一直都在该领域继续深耕。
2005 年,Scott 开始重点研究超级计算与超高性能联网聚类这两大领域。随着 10GbE 的普及,他推出了广受欢迎的 10GbE.net 博客。在 2017 年市场风云变幻之际,Scott 将 10GbE.net 打造成了一个每月拥有数千次页面浏览量的技术传播博客,同时还附带一个播客。Scott 在赛灵思的职责是与合作伙伴一起探寻新的加速机遇并定义创新解决方案。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通