

设计一个SmartNIC
https://www.cnblogs.com/shaohef/p/12227496.html
smartnic 是一个网络接口卡(网络适配器),使用其自己的板载处理器(ASIC, FPGA, SOC),卸载HOST CPU的网络处理功能。smartNIC可以执行加密/解密,防火墙,TCP / IP和HTTP处理的任意组合。 SmartNIC非常适合于高流量的Web服务器。
虚拟化场景常见的smartnic是进行ovs的功能卸载。实现方式是virtIO(1.1 new video and pdf)的硬件化(目前是SRIOV,后期可能会由SIOV取代)。
如果不是虚拟化的开发人员,没有参与过XEN,QEMU/KVM,或者cloud-hypersor等项目的开发,也没有进行过相关代码的走读,也没有关系。但是最好需要阅读以下几篇文章,这几篇文件虽然没有特别深入的介绍实现细节,但是非常系统的从原理和架构上进行了简明扼要的总览描述(请按循序阅读)。
1. Introduction to virtio-networking and vhost-net (总览,适合想了解初步原理)
2. Deep dive into Virtio-networking and vhost-net (深入,适合对技术感兴趣)
3. How vhost-user came into being: Virtio-networking and DPDK (总览)
4. A journey to the vhost-users realm (深入)
5. Achieving network wirespeed in an open standard manner: introducing vDPA (总览)
6. How deep does the vDPA rabbit hole go? (深入)
附加几篇动手文章:
1. Hands on vhost-net: Do. Or do not. There is no try
2. Hands on vhost-user: A warm welcome to DPDK
3. vDPA hands on: The proof is in the pudding
ovs的卸载分三种方式:
1. vDPA for on-prem
virtual data plane acceleration.
a virtio dataplane going directly from the NIC to the container while using a translation layer between the NICs control plane and the virtio control plane
2. Virtio full HW offloading (e.g. for Alibaba bare metal servers)
3. Mediator layers for public cloud
In the case of AWS since the ENA interface (see details in the AWS section) does not support virtio data plane/control plane, both planes need to pass through a translation layer.
硬件设计
vDPA的设计,硬件数据流向如下
SFP -> retimer(phy, line side) -> FPGA/ASIC/SOC -> PCI -> host
1. SFP
可以选型QSFP28(100G) QSFP56(200G)
2. retimer, TI, Intel 都有相应的产品。
比如intel的C827。
retimer 主要功能是Serializer/Deserializer (SerDes), 实现物理层数据高速串行化的一个器件。主要功能包括一个时钟数据恢复(CDR)协议,CDR没有单独的时钟信号,而是把时钟嵌入在数据中,即CDR接收器将相位锁定在数据信号本身以获取时钟。其实CDR 获取时钟有多种方式,如基于锁相环的时钟恢复电路、基于过采样技术的时钟恢复电路等。
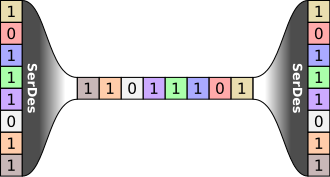
并行 串行(通常是差分的形式) 并行
3. FPGA, intel 和xilinx。
比如intel A10以上的FPGA。提供了很多基础的IP core, 比如 S10。
有各种参考设计。
逻辑设计
<How to Design SmartNICs Using FPGAs to Increase Server Compute Capacity> 这篇文章介绍了逻辑开发的各个模块,但每个模块的介绍并不详细。

采用intel的FPGA,intel提供了各种IP core, 例如Avalon
Intel Stratix 10 Avalon -MM硬IP PCIe 设计实例用户指南
Intel Stratix 10 Avalon -MM接口 PCI Express 解决方案用户指南
使用户把精力放在主要业务,ovs的硬件化即可。
采用xilinx的产品,也提供了一套开发环境(Versal)。
熟悉ovs的原理,进行相关的逻辑上设计。 intel的santos做过一个介绍,给出了一个ovs FPGA设计的框图。
熟悉ovs的设计是非常重要的。请参考
- Research Papers
-
《The Design and Implementation of Open vSwitch》 需要重点看,这是有关ovs设计的论文, 讨论了流表的设计,这是fpga硬件设计需要了解的 原理。相应的slide 和video. 论文很长,快速了解,可以参考 ovs源码阅读--流表查询原理 和 Open vSwitch流表查找分析。
- 《Extending Networking into the Virtualization Layer》
-
- Presentations
- Documentation
- Interviews
- video
- Conference from 2014 to latest 2019
- OVS-DPDK (快速版)
樱桃的smarnic设计

A Typical Flow and HQoS Acc. Reference Design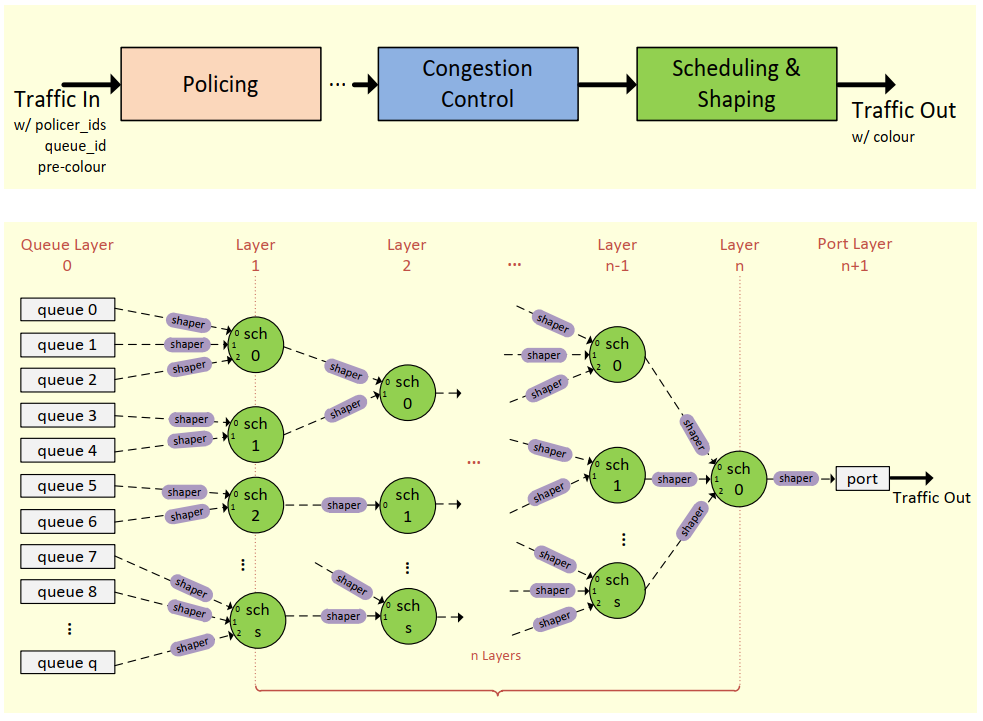
HQoS Acceleration
► Capacity
Policing
Congestion Control
Scheduling and Shaping
► Queuing
Flow match for Queue ID
Queue ID in Metadata
Thousands of Queue Number
► Configuration
Follow Rte_tm API
Testpmd and Example APP
微软的smartnic
微软有篇演讲介绍《SmartNIC:Accelerating Azure’s Network with FPGAs on OCS servers》介绍他们在Azure云上的使用场景。
微软也有一片论文介绍了介绍了smartnic的设计, 包括FPGA流表的设计。
微软的这个论文写的很好,介绍了他们指定方案的前后过程。微软很早是bing搜索(几千个网络节点集群)中使用了FPGA,但是没有在数据中心作为NIC中使用,随后他们做了大量的论证。
他们提出了4种方案ASIC,SOC,FPGA,burn CPU等, 按8个指标维度进行对比。
- 不耗费主机的CPU(Don’t burn host CPU cores)
- 保持VFP(微软的可编程vSwitch)的SDN可编程性
- 实现SRIOV硬件的延迟,吞吐量和利用率
- 与时俱进,支持新的SDN工作负载和原语
- 向整个fleet推出新功能(Rollout new functionality to the entire fleet)
- 提供高的单连接性能
- 可以扩展到100GbE +
- 保持可维修性
作为第一条,因为CPU是有成本的:
物理核心(2个超线程)的价格为 900,以及$ 4500(在我们的数据中心中,服务器通常可以使用3到5年)。
最终选在了FPGA作为方案,并且回答了采用FPGA的一些质疑:
1. FPGA是不是比ASIC大?
2-3倍的大小。对于大量增加的可编程性和可配置性,是合理的。
其实FPGA中,占比最大的部分是硬逻辑,等同于ASIC的逻辑。 同样ASIC中,也需要额外的逻辑来适应不同用户的不同需求,也导致增大了面积。
2. FPGA是不是很贵
不能泄露供应商的价格。
但是有两家供应商,而且微软的规模可以摊销不可回收的工程成本,硅的成本则由硅面积和产量决定。
由于FPGA的规则结构,其成品率通常很好。
最大的比例还是CPU,闪存和DRAM,量大。
3. FPGA很难编程?
微软的网络团队,都不在逻辑领域开发,对此也有质疑。
只有真正考虑有效流水线设计并对其进行布局,才能达到令人难以置信的性能。
所以专业的开发人员,但是任何时候,也不过5人参与项目。
开发团队,基础架构,仿真功能和工具的投资是必不可少的,但是其中大部分可以在不同团队之间共享。
使用软件开发方法(例如敏捷开发)而不是硬件(例如瀑布)模型。 FPGA的灵活性使我们能够以比其他任何类型的硬件设计都更快的时间间隔进行编码,部署,学习和修改。
4. FPGA可以超大规模部署吗?
不容易,随着时间推移,经验积累,解决的很多问题。
5. 代码会被vendor locked in吗?
主要是SystemVerilog写的,就有vendor特有的细节,但是都可以移植。
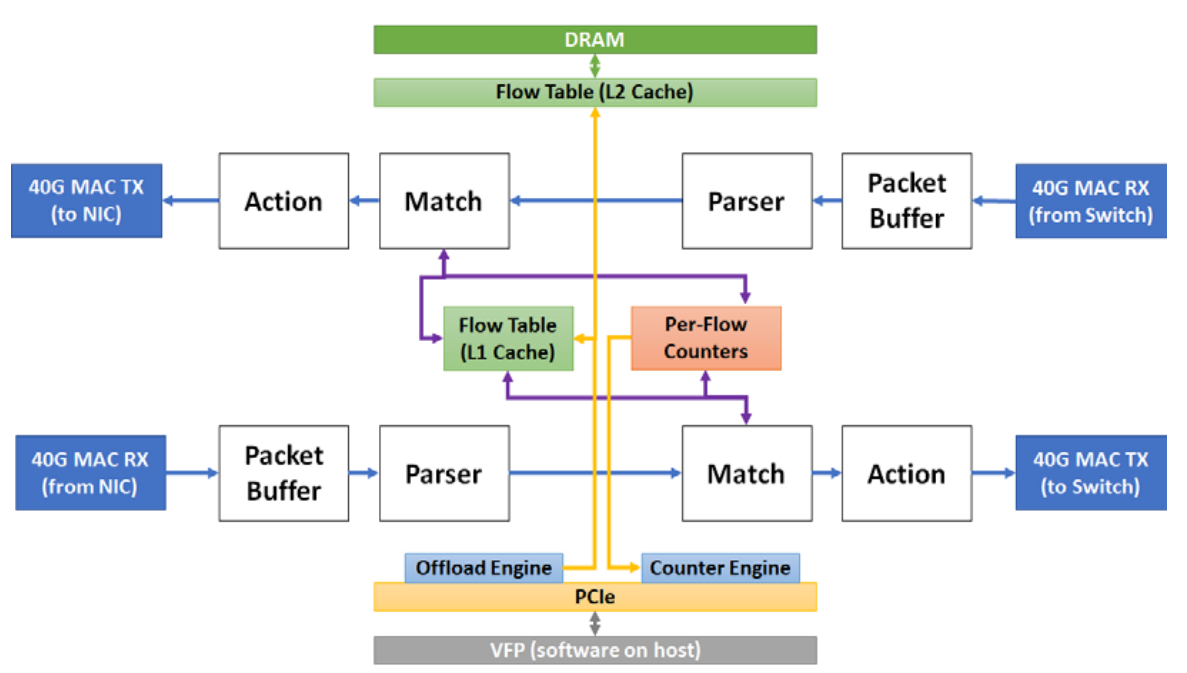
smartnic 架构
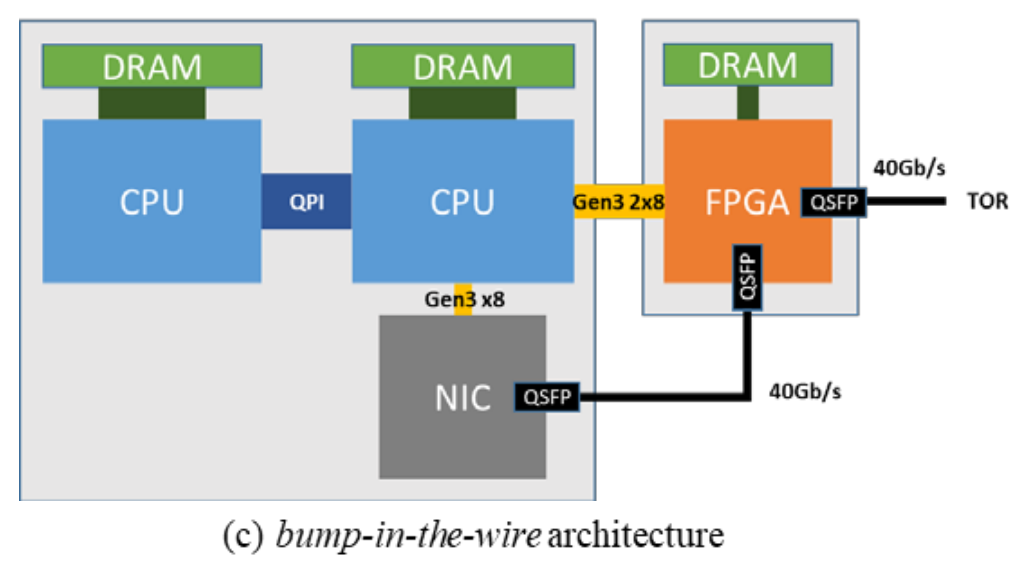
第一代smarnic,smartnic和TOR之间有网线(图中看,应该是光纤)链接,smartnic和host上的nic也是网线连接。
第二代实现了SRIOV,取消了和host nic上的网线连接。
控制平面有hypervisor来实现, 数据平面有FPGA实现。
hypervisor有一个特殊的vPort, 对于异常flow,通常是第一个flow,会通过vPort进入VFP,VFP会创建流表,对于入包,直接forward给VM,对于出包,会重新送回smartnic.
VFP也会监控,并终止链接。FPGA如果发现TCP 包的SYN, RST or FIN 标志被设置了,也会把包复制一份发给vPort,然后VFP会跟踪这个包的状态, 并删除刘表中的规则。
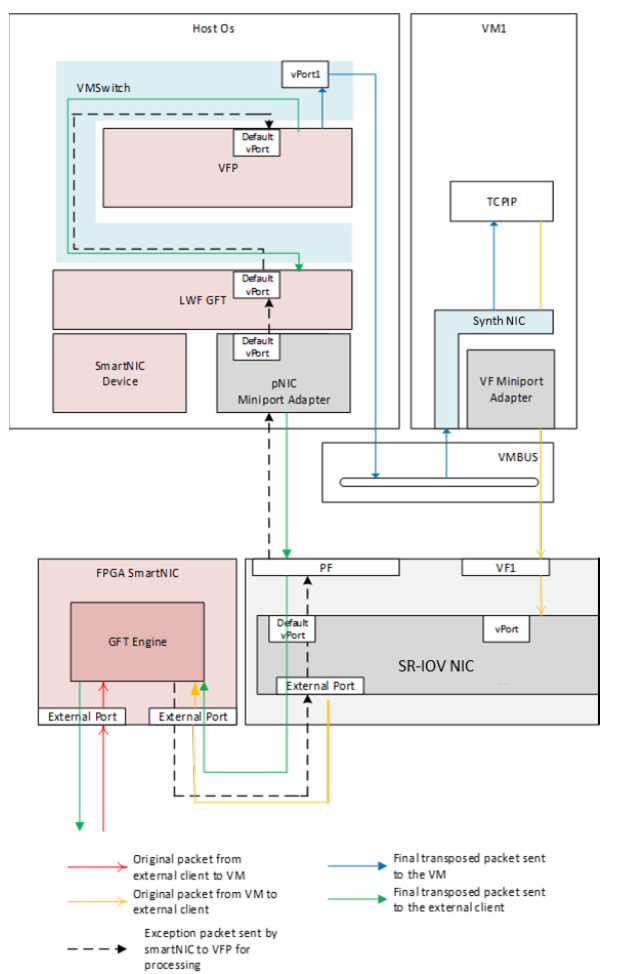
Generic Flow Tables (GFT)
阿里的MOC设计
这是阿里的论文, 具体的分析,后面会补充。
论文的第三章开始介绍设计。
设计要求
首先设计要满足一下要求
• Multi-tenancy (多租户)
• Security (安全)
• Interoperability (互操作性)
• Performance (性能)
• Cost efficiency (成本效益)
系统概述
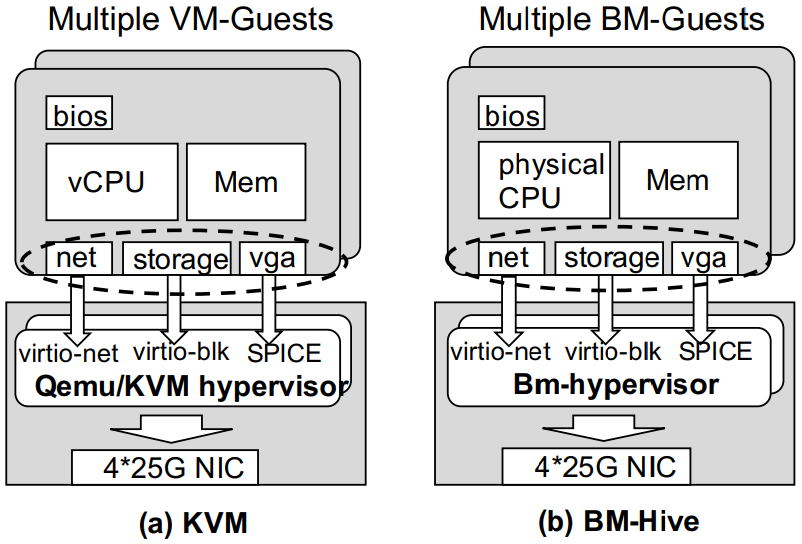
bare metal 与KVM整个架构基本相同。
通过Bm-hypervisor来管理BM guest,同时提供了BM guest的virtio后端。
可以无缝的接入到现存的cloud基础设施架构中。
bare metal与KVM架构有些区别
不需要虚拟化 CPU, memory, buses
为了更好的隔离后端virtio资源,一个Bm-hypervisor 对应一个BM guest。Bm-hypervisor在guest的外部,而vm-hypervisor在guest的下面。
Bm-hypervisor更安全,通过virtio接口间接与BM guest交互,而VM-hypervisor通过虚拟组件和hypercall直接暴露给VM。
通过打开PCI的电源来给 计算主板上电启动BM guest。
计算主板上电后,会启动FirmWare(BIOS,可以看成一台PC),然后加载boot loader,加载内核。
boot loader和内核其实是存在remote storage上,通过virtio-blk接口访问。
所以firmware做了加强,支持virtio来访问网络和存储,以加载kernel。
系统架构
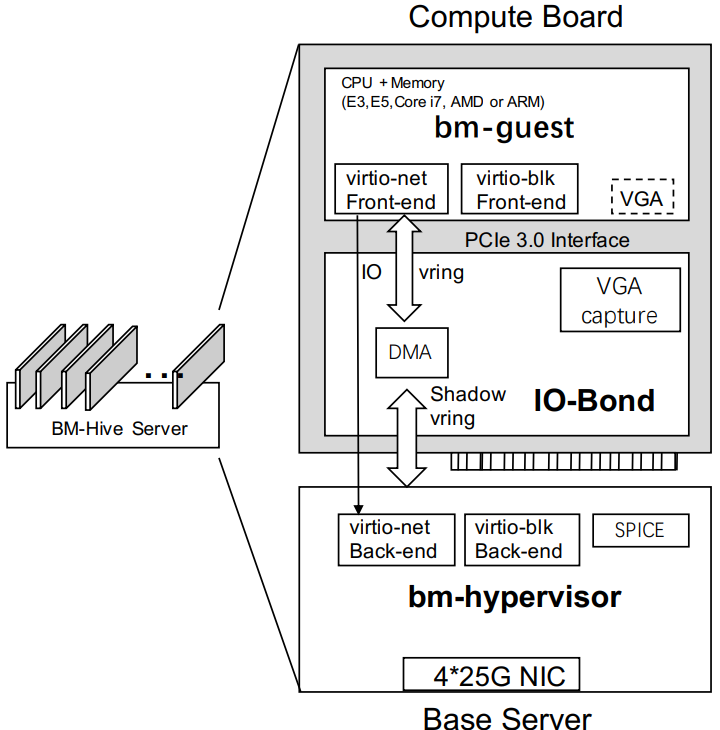
每个baremetal sever是由base server和几个计算主板(可以是E3,E5, i7, Atom或者AMD/ARM的CPU)组成。其实在股票交易中i7/i9单线程性能比Xeon好。
base server 是一个简化的E5 server。每个计算主板就是一个PCI板卡插在base server上。包含的CPU,memory,总线和IO-bond.
IO-bond 通过FPGA实现(可以ASIC化),是base和计算主板的PCI总线接口(是不是像intel的VCA卡),可以认为是virtio后端设备的代理(或者桥接)。
负责前后端的配置和控制平面的转发。而数据平面通过DMA引擎来传输。
IO-bond的可扩展性极高。可以些许修改就能支持其他新的VIRTIO设备。
IO-Bond
最主要的设计。
IO-bond的前端
通过FPGA的逻辑,模拟了PCI的接口(比如配置空间,BAR0, BAR1, PCIe Cap)。
前后端没法共享物理内存(CXL/CCIX总线不行吗?这个值得思考),数据层面的交互,IO-Bond没法通过ring buffer来实现。
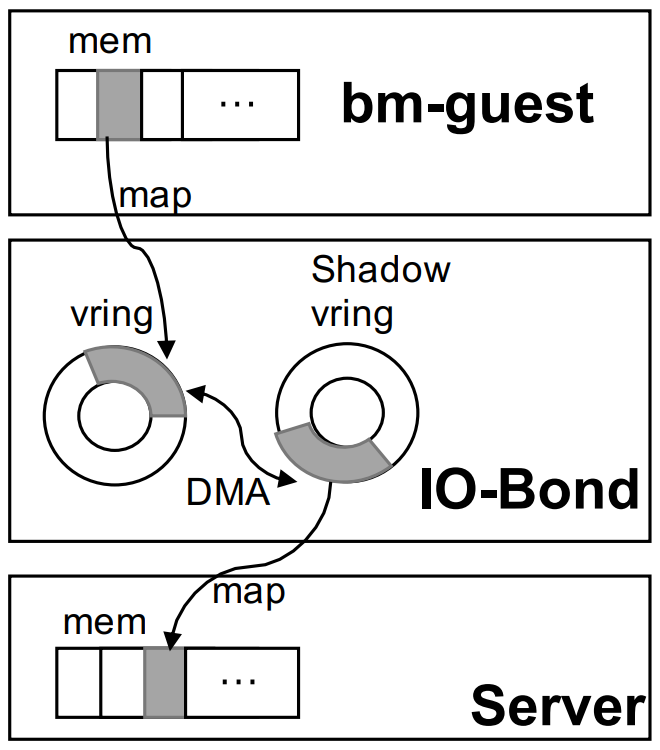
增加了一个影子vring.
IO-bond的后端

用户空间的Vhost-user通过PMD模式和物理NIC通信。
IO-BOND实现
前端是硬件,后端是软件。

Bm-guest 与IO-BOND
通过写virtio notification寄存器的notify IO-BOND
IO-BOND通过MSI中断通知RX数据的到来。
后端与IO-BOND
没有中断机制。
通过一个专门的线程 pull IO mailbox 和 影子 vring head/tail 寄存器
DMA在IO-BOND中,可以达到50GB。做数据拷贝。对于DMA来说,计算主板就是个设备。
-------------------------------------(软件)
樱桃软件设计
整个软件栈如下:
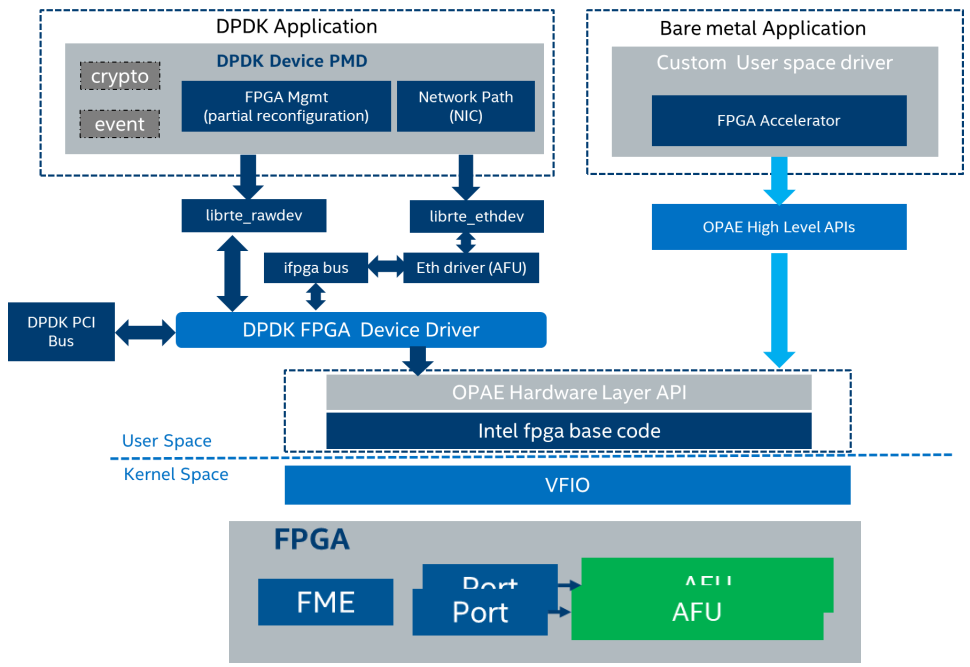
Linux kernel 解决方案
1. redhat propose mdev(v1/v2/v3/v4/v5/v6/v7 maillist), and it is denied.
更详细的请看介绍:
- VDPA: VHOST-MDEV AS NEW VHOST PROTOCOL TRANSPORT (CUNMING(Steve) LIANG, Intel)
- vhost: introduce mdev based hardware vhost backend
DPDK的实现
更多DPDK请参考 《DPDK documentation》,包括vDPA Device Drivers

FVL是一个智能网卡芯片,比如intel的xl710/810,这里可以忽略。
我们来关心FPGA的部分:
► AFU PMDs provide data plane control path
Binding FPGA Port to I40e PF
Implement HQoS and Flow Acceleration
Follow librte_ethdev API
qemu 使能 Vhost-user with OVS/DPDK as backend (软硬件virtIO区别不大)
qemu和 Vhost-User通过fd通知共享内存。控制层面实现。vring的偏移都是针对这个内存的首地址。
cloud 使能smartnic
k8s vDPA实现
(参考 Making high performance networking applications work on hybrid clouds):
系列文章介绍k8s相关的smartnic网络
Breaking cloud native network performance barriers(solution overview)
Making high performance networking applications work on hybrid clouds (solution overview)
Virtio-networking: first series finale and plans for 2020(series recap)

通过device plugin 实现资源的管理。 具体实现请参考 Breaking cloud native network performance barriers
通过CNI(intel 实现了一个 Multus-CNI a container network interface (CNI) plugin)实现网络功能的管理。CIN SIG 定义了CRD标准 Kubernetes Network Custom Resource Definition De-facto Standard。
Openstack 实现
Openstack 开发还在进行种,估计很快就出来了...
openstack很早之前,只知道smartnic的概念的时候, 就跟team的讨论,ovs会以什么样的方式暴露给用户呢?
当时认为有两种方式:
1. PCI 设备透传方式
我们会在cyborg中增加一个driver,用来discover和管理smartnic的virtio的nic
初步代码如下,主要是获取virtio PCI设备的topo来获取整体资源情况:
 View Code
View Code
cyborg中会有一个专门的smartnic driver, 将nic资源上报给数据库,包括cyborg 和placement的数据库, 在openstack中有一个资源管理的数据库API(placement),用来做调度使用。
网络管理单元,例如neutron可以创建一个PCI passthrough的port, 交给VM使用(VM需要想cyborg申请一个pci vf设备)。
该流程还是很复杂的,需要综合了解linux 内核,硬件,虚拟化,还有cloud编排等各种综合知识。
此外,尤其动态烧写本身特别复杂, 因为功能会动态改变,这会做大量的工作。 其实在网络产品中,很多硬件都会动态改变功能,比如DDP, AVF等(AVF更多详见SDNLAB)。
2. vDPA方式
通过VM和HOST之间的共享内存,实现virtio 数据层面的加速。
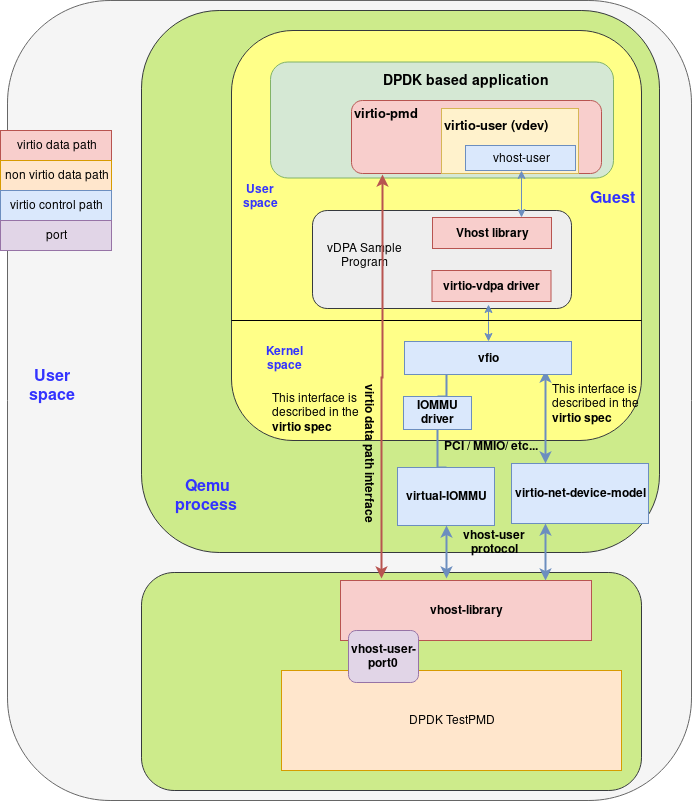
详细操作,见qemu wiki
这个主要的工作,就是把原来对ovs软件支持的部分,改成对smartnic的ovs支持, 主要是neutron的工作。
3. 其他功能
此外,ovs也可以提供其他的硬件卸载功能,比如tunnel的卸载,这个可以vDPA或者PCI passthrough组合工作,但是这两个功能是正交的。
REF:
PCIE Address Translation Services
Boosting the NFV datapath with RHEL OpenStack Platform
对于非ovs的开发者,想快速了解OVS流表:
FPGA Pool from Miscrosoft (UTK(University of Tennessee, Knoxville 田纳西大学)的网站上一个PPT, 改PPT是来自 RIKEN R-CCS (日本首要的高性能计算研究中心,也是超级计算机Fugaku的所在地)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通