

RoCE与iWARP的竞争分析
https://zhuanlan.zhihu.com/p/374068044
远程直接内存访问(RDMA)提供从一台计算机的内存到另一台计算机的内存的直接访问,而不涉及任何一台计算机的操作系统。这项技术可以实现高吞吐量、低延迟的网络,同时降低CPU利用率,这在大规模并行计算集群中尤其有用。
RDMA over Converged Ethernet(RoCE)是以太网中最常用的RDMA技术,在世界上一些最大的“超大规模”数据中心大规模部署。RoCE是唯一一个基于以太网的行业标准RDMA解决方案,具有多供应商生态系统,提供网络网卡,并在标准的第2层和第3层以太网交换机上运行。相关技术在包括IBTA、IEEE和IETF在内的行业组织中是已经被标准化了的。
Mellanox Technologies是第一家实施新标准的公司,其ConnectX-3 Pro及以后的所有产品系列都实现了RoCE协议的完全卸载。这些解决方案提供高达100Gb/s的线速吞吐量和市场领先的延迟,同时尽可能降低CPU和内存利用率。因此,ConnectX网卡系列已部署在各种关键业务员、对延迟敏感的数据中心中。
RoCE相对于iWARP的优势
iWARP是另一种RDMA产品,它更复杂,无法达到与基于RoCE的解决方案相同的性能水平。iWARP使用复杂的层混合,包括DDP(直接数据放置)、MPA(Marker-PDU-Aligned framing)和单独的RDMA协议(RDMAP)通过TCP/IP提供RDMA服务。这种复杂的体系结构是将RDMA应用到现有软件传输框架中的一种考虑不周的尝试。不幸的是,这种折衷导致 iWARP无法实现RoCE能够实现的三个关键好处:高吞吐量、低延迟和低CPU利用率。
除了复杂性和性能缺点之外,只有一家供应商(Chelsio)在其当前产品上支持iWARP,而且该技术还没有被市场很好地采用。英特尔此前从2009年开始在其10GbE NIC中支持iWARP,但在当时任何较新的NIC中都不支持iWARP。在最新的以太网速度为25、50和100Gb/s时,不支持iWARP。
iWARP的设计是为了在现有的TCP传输上工作,本质上是为了修补现有的LAN/WAN网络。以太网数据链路提供尽力而为的服务,依靠TCP层提供可靠的服务。为了支持现有的IP网络,包括广域网,需要覆盖更多关于拥塞处理、扩展和错误处理的边界条件,这导致RDMA和相关传输操作的硬件卸载效率低下。
另一方面,RoCE是专门为以太网构建的RDMA传输协议,而不是作为在现有TCP/IP协议之上使用的补丁。
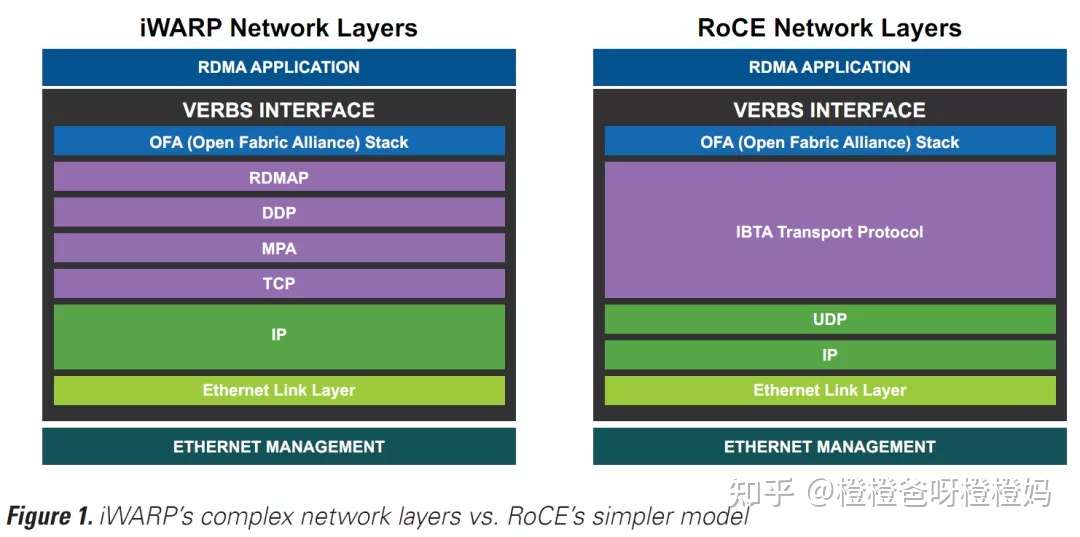
因为TCP是基于连接的,所以它必须使用可靠的传输。因此,iWARP只支持可靠的连接传输服务,这也意味着它不是一个适合多播的平台。RoCE提供多种传输服务,包括可靠连接、不可靠数据报等,并支持用户级多播功能。
iWARP流量也不能在网络中被轻松管理和优化,从而导致部署效率低下。它不提供一种方法来检测传输层上或传输层下的RDMA流量,例如在fabric本身中。iWARP共享TCP的端口空间使得使用流管理变得不可能,因为单独的端口无法识别消息是否携带RDMA或传统TCP。iWARP与传统TCP通信共享协议编号空间,因此需要上下文(状态)来确定数据包是iWARP。通常,此上下文可能不适合NIC的片上存储器,这会导致更复杂的情况,因此流量解复用的时间更长。这种情况也发生在fabric的交换机和路由器中,因为它们没有可用的状态。
相反,通过查看数据包的UDP目标端口字段,就可以将数据包标识为RoCE。如果该值与IANA为RoCE分配的端口匹配,则数据包为RoCE。这种无状态流量标识允许在聚合NIC实现中快速、早期地解复用流量,并支持交换机或 iWARP监视和访问控制列表(ACL)等功能,以改进流量分析和管理。
同样,由于iWARP与传统的TCP协议栈共享端口空间,因此它也面临着与OS协议栈集成的挑战。另一方面,RoCE提供了完整的OS协议栈集成。
这些挑战限制了iWARP产品的成本效益和可部署性,尤其是与RoCE的兼容性。
RoCE在包封装中包括IP和UDP报头,这意味着RoCE可以跨L2和L3网络使用。这将使3层路由功能,可将RDMA引入具有多个子网的网络。
“弹性RoCE”支持在有损网络上运行RoCE,而这些fabric不支持流控制或优先级流控制。RoCE的先进硬件机制在有损网络上提供的RDMA性能与无损网络相当。
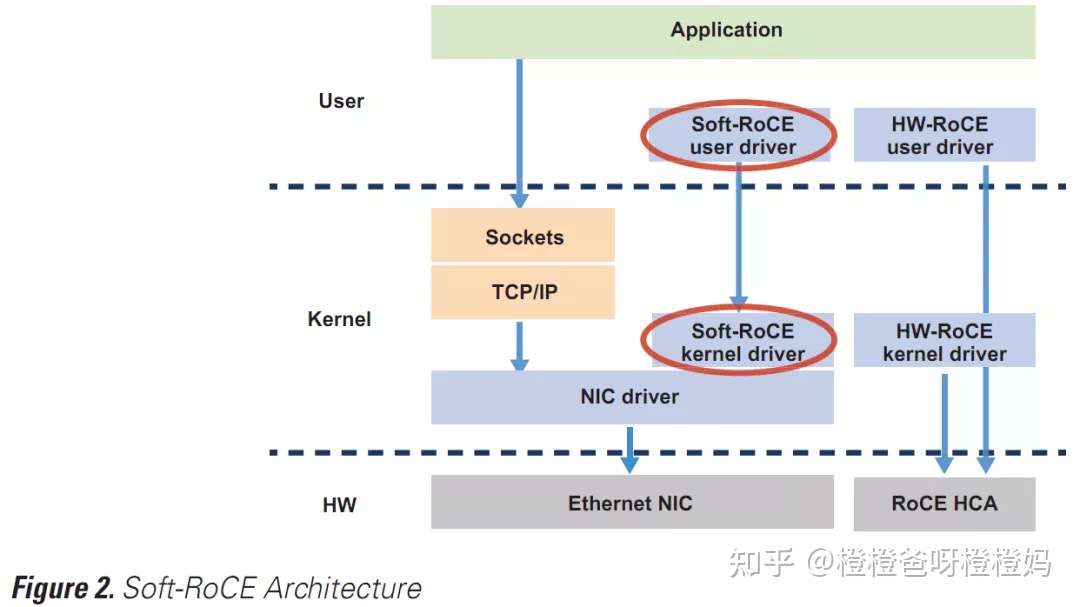
最后,通过部署软ROCE(图2),通过软件实现ROCE,ROCE可以扩展到硬件上不支持ROCE的设备。这使得在数据中心利用RoCE的优势具有更大的灵活性。
性能和基准示例
EDC对延迟敏感的应用程序(如用于实时数据分析的Hadoop)是Web2.0和大数据提供商竞争力的基石。这样的平台可以从Mellanox的ConnectX-3 Pro中获益,因为它的RoCE解决方案在以太网上提供极低的延迟,同时可以扩展到每秒处理数百万条消息。
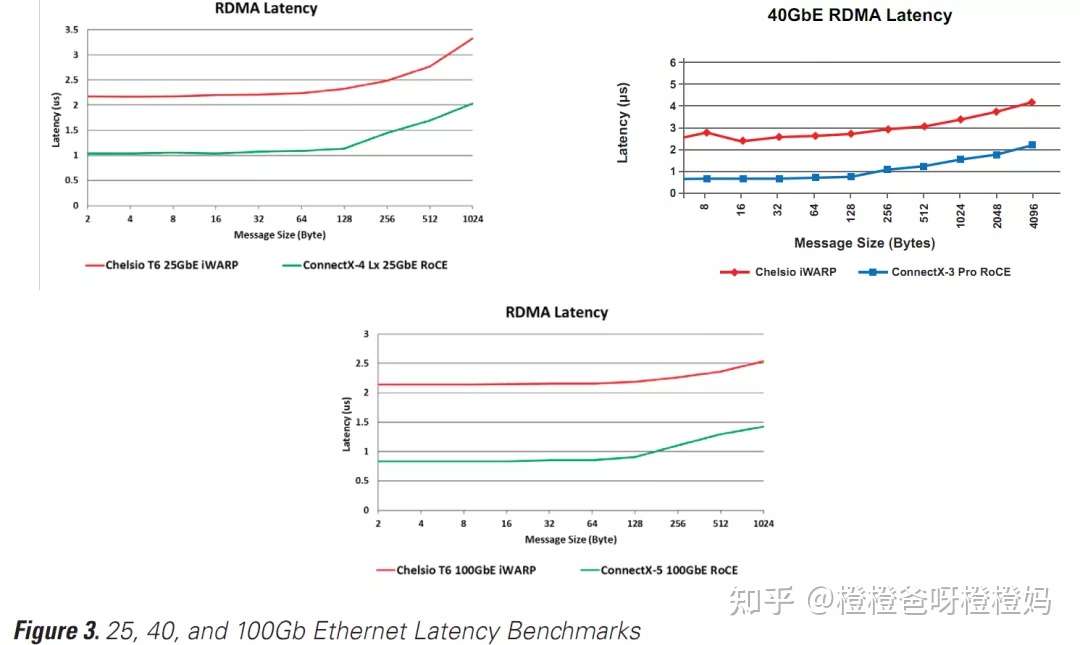
对比Chelsio在25、40和100Gb以太网iWARP上运行的T5和T6消息传递应用程序与带有RoCE的ConnectX-3 Pro的性能的基准测试表明,RoCE始终比iWARP更快地传递消息(图3)。
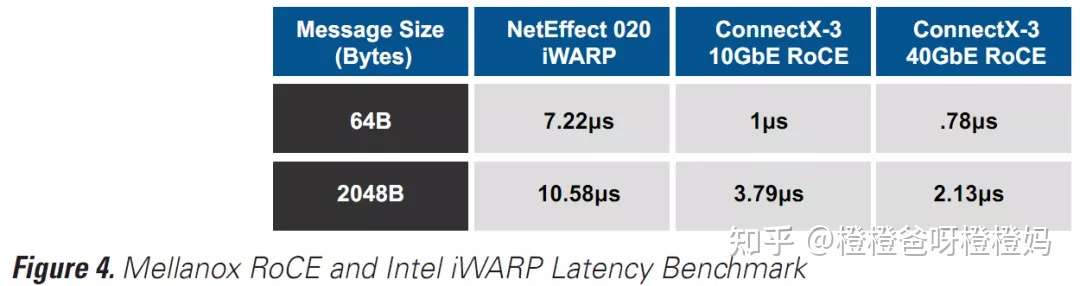
当用英特尔的NetEffect 020 iWARP测试ConnectX-3的RoCE延迟时,结果更令人印象深刻。在10Gb时,使用64B消息大小的RoCE,RoCE提高了86%,2048B消息大小的RoCE提高了64%(图4)。
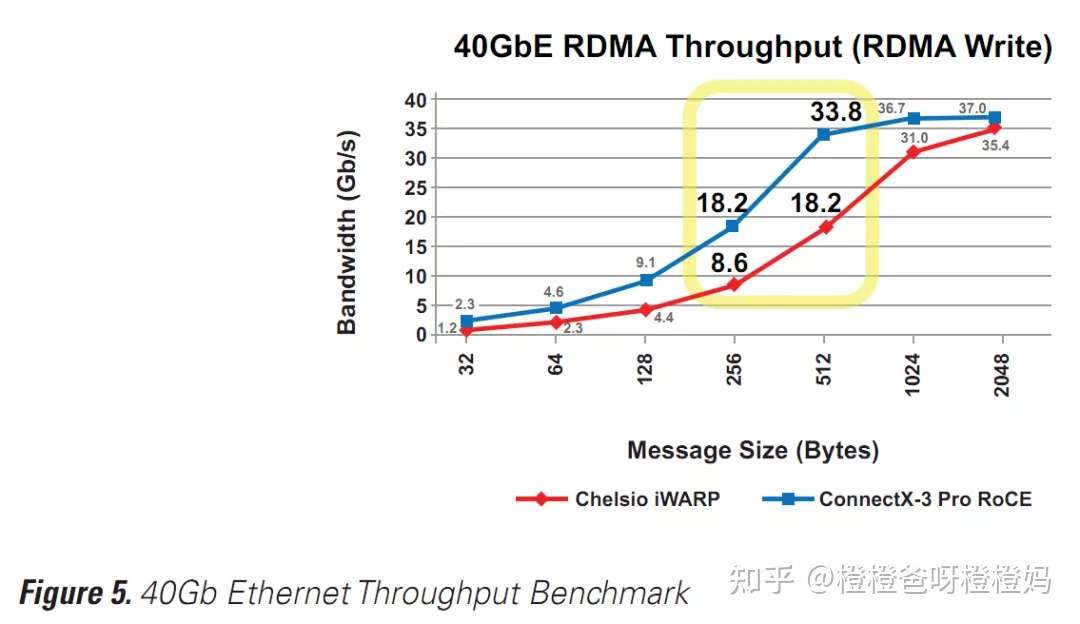
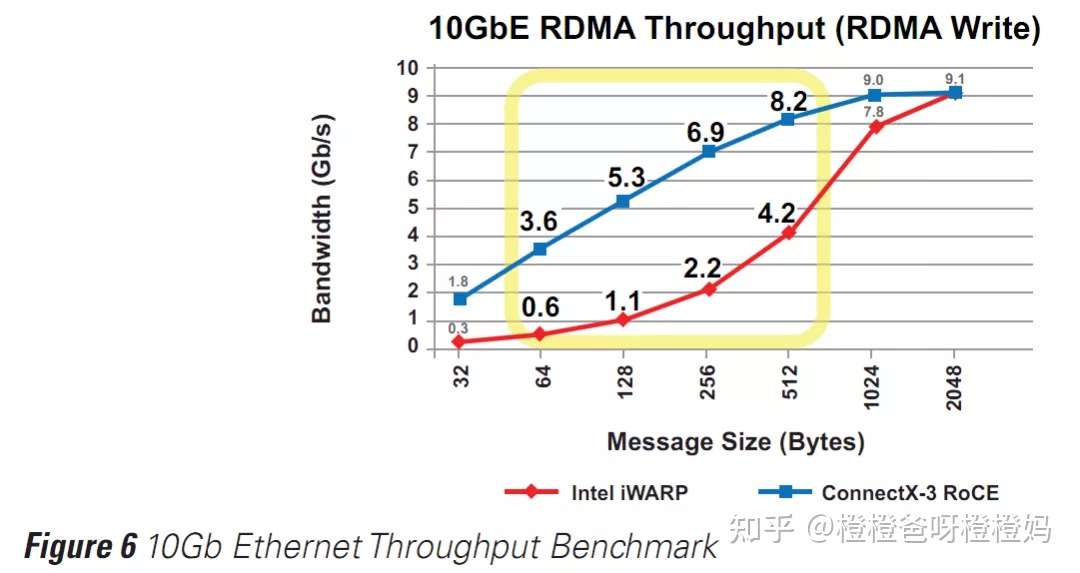
同时,在ConnectX-3 Pro上使用40Gb的RoCE时,吞吐量比在Chelsio T5上使用iWARP高2倍以上(图5),比在Intel上使用10Gb的iWARP高5倍(图6)。
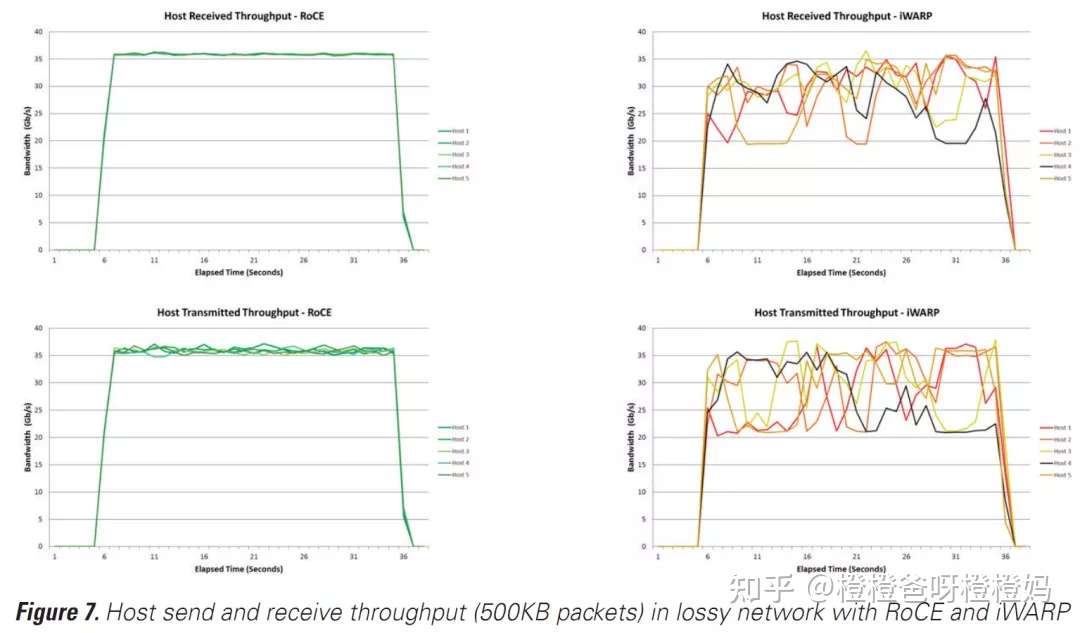
无论是在无损网络还是有损网络上使用RoCE,都保持了性能优势(图7)。有了弹性RoCE,Mellanox可以在有损环境中提供一致的、顶级的拥塞控制性能。
虚拟化的最佳性能
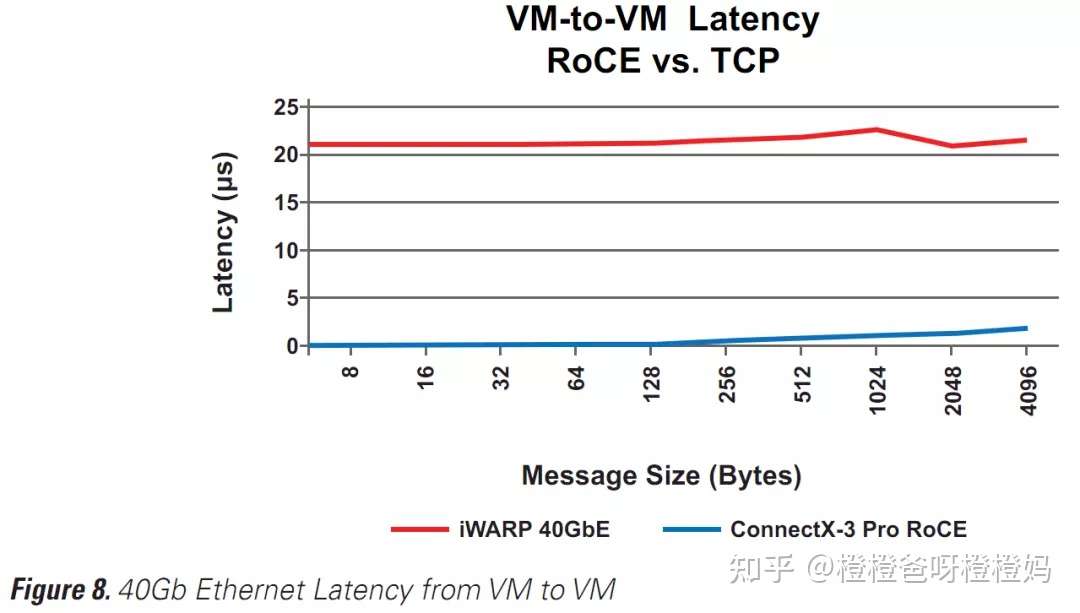
RoCE的另一个优势是它能够在SR-IOV上运行,从而使RoCE在虚拟化环境中具有最低延迟、最低CPU利用率和最大吞吐量的优异性能。RoCE已经证明,它可以在虚拟机之间提供少于1us的延迟,同时随着虚拟环境的扩展保持一致的吞吐量。Chelsio的iWARP不在SR-IOV中的多个虚拟机上运行,而是依赖TCP进行虚拟机到虚拟机的通信。延迟的差异是惊人的(图8)。
总结
RoCE简化了传输协议;它绕过了TCP协议栈来实现真正的、可伸缩的RDMA操作,从而获得更高的ROI。RoCE是一个标准协议,它是专门为数据中心流量而构建的,考虑了延迟、性能和CPU利用率。它在虚拟化环境中表现特别好。
当网络通过以太网运行时,RoCE提供了比iWARP更好的解决方案。对于追求最高性能的企业数据中心来说,RoCE显然是一个选择,尤其是当涉及到对数据敏感的应用程序时。
此外,RoCE目前部署在数十个数据中心,拥有多达数十万个节点,而iWARP在该领域几乎不存在。简单地说,RoCE是通过以太网部署RDMA的显然方式。
参考文献:Motti Beck, Gilad Shainer, "RoCE vs. iWARP Competitive Analysis Brief",Mellanox Technologies,2017.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2020-08-21 How to install the NVIDIA drivers on Fedora 32