

Xilinx ACAP介绍
https://zhuanlan.zhihu.com/p/68321181
引言
随着机器学习算法的研究,其变得越来越复杂和多样性。计算密集性对计算资源和存储以及带宽提出了更高的要求,复杂性更要求硬件要有很好的灵活性。CPU是一个标量处理单元,对于处理过程复杂的算法很灵活,比如决策树和大量的图像或者机器学习算法。GPU和DSP集成了大量的运算单元,能够并行处理大量计算,但是功耗较大。FPGA具有并行计算优点,以及灵活的可编程特性,但是在处理计算密集的过程时,依然受到存储和带宽限制,而且FPGA开发过程时间较长。Xilinx的ACAP将这三者结合起来,目标是能够解决计算密集和带宽瓶颈以及开发周期问题。本篇在网络上能搜索到的信息的基础上,对ACAP的架构进行一个简单的介绍,因为保密原因不能介绍内部文件对其描述,所以特此声明。
1. 功能介绍
ACAP是Xilinx推出的一种革命性异构计算架构。它将标量计算,可编程逻辑还有矢量计算结合在一起,充分利用各自的优势,不仅仅增强了针对各种机器学习算法的适用性,也提高了计算密度和存储带宽。其中AI engine和NoC是新颖的设计,FPGA和CPU的结合早在zynq系列中已经应用。AI engine优点类似于GPU的结构,由多个DSP和BRAM以及DMA等构成,可以处理创新的超长指令字和单指令,多个数据指令。AI engine之间相互互联,可以提供高达100Tb/s的存储带宽。NoC是一种片上网络,实现CPU,FPGA,AI engine之间的互联。CPU是采用的双核arm cortex-A72,与赛灵思上一代A53核相比,每核单线程相比性能提高了2倍。FPGA部分保留了原有设计,其内部的存储器可以用于多层级cache。
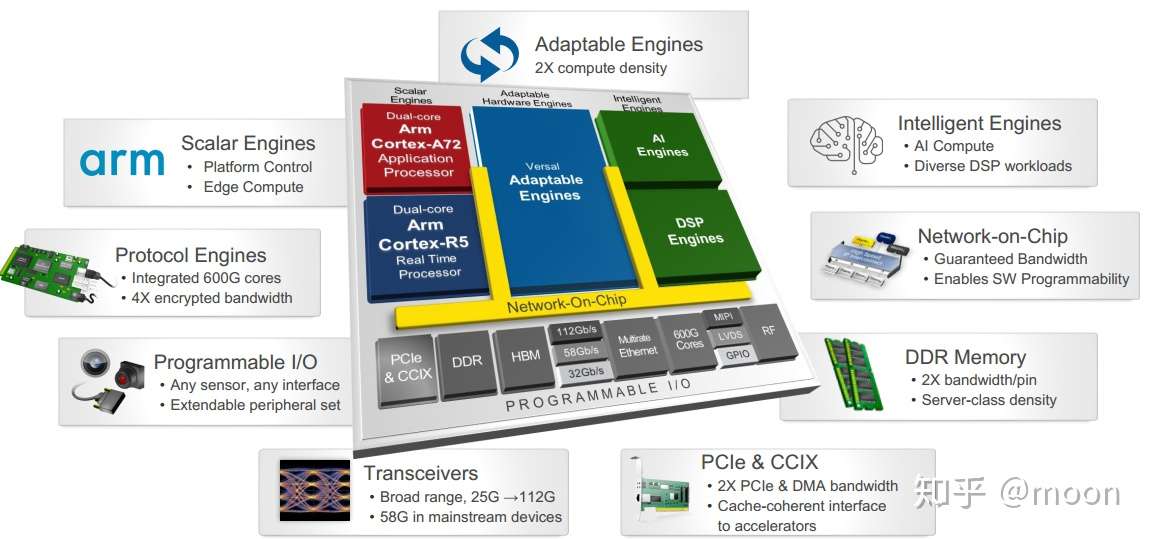 图1.1 ACAP结构
图1.1 ACAP结构
Xilinx自适应加速平台(ACAP)结合了矢量、标量、自适应硬件单元,提供了三大引人注目的优势:
1 软件可编程特性;
2 异构加速
3 灵活应变能力
2. AI engine结构
一个AI engine是一个小型运算单元,其由用于计算的DSP,指令控制单元,搬运数据的DMA引擎,局部存储单元等组成。每个相邻AI engine之间存在cascade的连线,以及memory的连接,可以实现级联的运算以及存储转运。比如多个AI engine之间可以级联,实现矩阵运算。计算数据向前传递到下一个AI engine进行进一步累加或者其他运算。
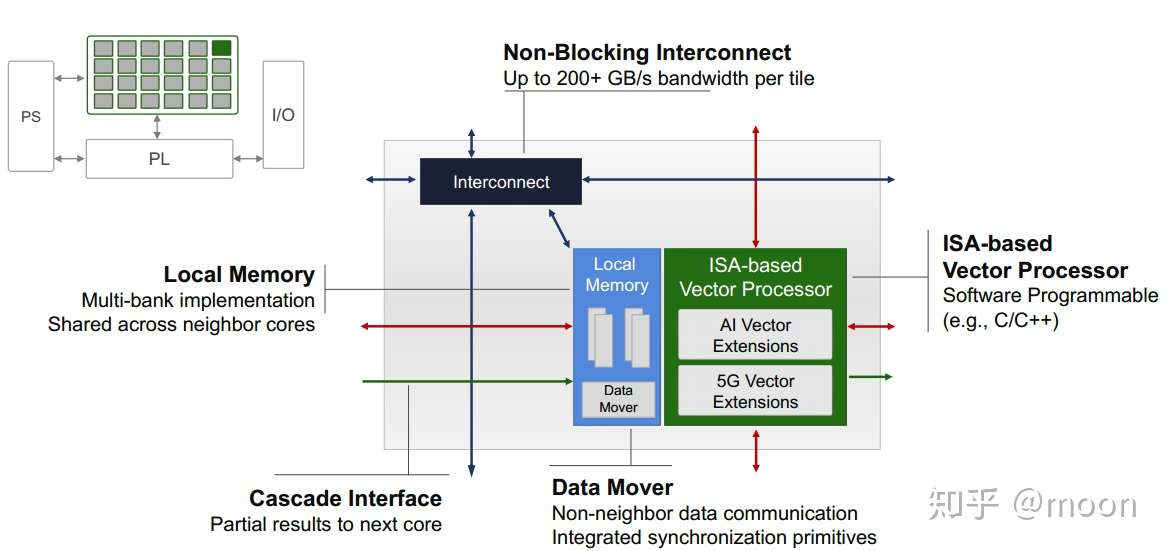 图2.1 AI engine架构
图2.1 AI engine架构
大量的AI engine排列成阵列结构,走线之间通过switch结构进行数据交换。连接方式有三种,一种是不同AI engine的存储之间可以连接,不同计算核心(AI core)形成cascade连接,还有AI core和存储之间的连接。这些连接为计算任务提供了更高的灵活性。
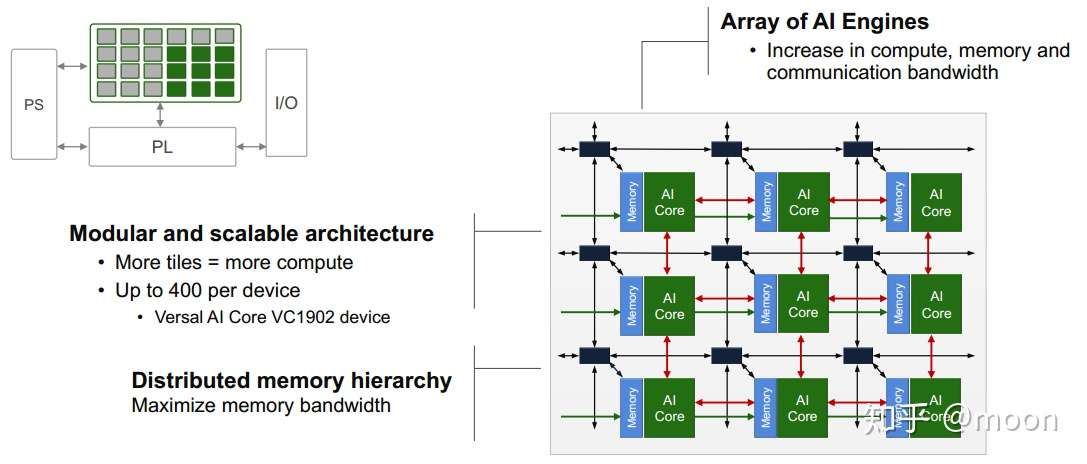 图2.2 AI engine之间的连接AI engine的计算单元相当于一个CPU结构,有32bit的RISC指令的标量计算单元。还有集成了多个DSP的用于处理矢量运算的矢量单元,其可以处理512bit的矢量运算,支持8bit,16bit以及32bit浮点运算。包含两个load和一个save单元用于数据传递。还有一个指令控制单元,可以解析超长指令字和精简指令字。局部存储有32KB大小。
图2.2 AI engine之间的连接AI engine的计算单元相当于一个CPU结构,有32bit的RISC指令的标量计算单元。还有集成了多个DSP的用于处理矢量运算的矢量单元,其可以处理512bit的矢量运算,支持8bit,16bit以及32bit浮点运算。包含两个load和一个save单元用于数据传递。还有一个指令控制单元,可以解析超长指令字和精简指令字。局部存储有32KB大小。
AI engine的计算单元相当于一个CPU结构,有32bit的RISC指令的标量计算单元。还有集成了多个DSP的用于处理矢量运算的矢量单元,其可以处理512bit的矢量运算,支持8bit,16bit以及32bit浮点运算。包含两个load和一个save单元用于数据传递。还有一个指令控制单元,可以解析超长指令字和精简指令字。局部存储有32KB大小。
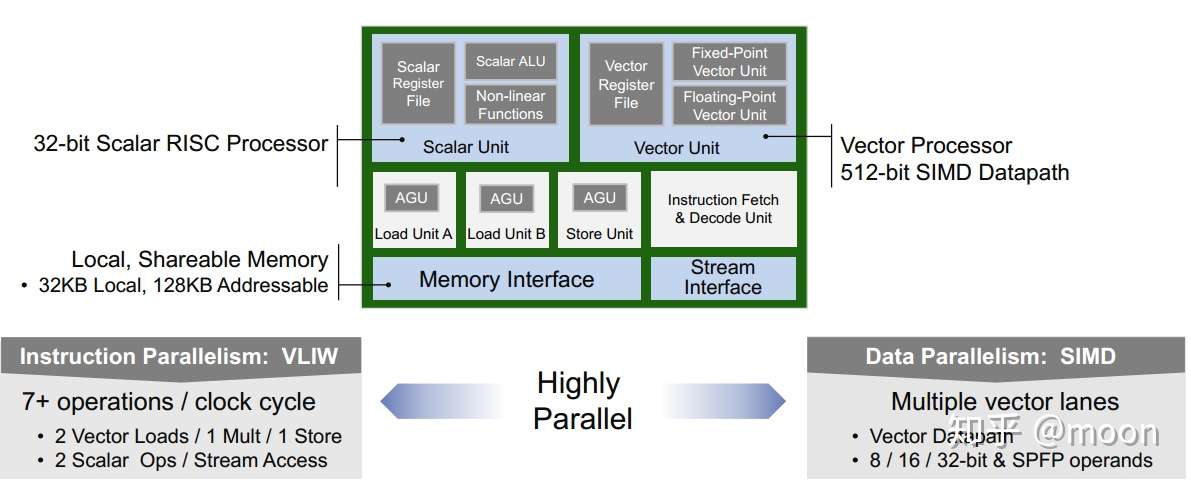 图2.3 AI core结构
图2.3 AI core结构
3. HBM和NoC
HBM和NoC是为了解决存储和带宽瓶颈问题提出的新型结构,比较通俗的理解就是把DRAM直接放到片上来,一是解决了PCB布线对引脚的限制以及对时钟频率的限制,因为放到片上后,HBM和FPGA之间的连线宽度就很小,就可以支持更多引脚连接,目前一个HBM有1024个数据引脚。三星的HBM最大带宽可以达到307GB/s,是GDDR5的10倍,xilinx的U50有两块HBM2,可以提供460GB/s带宽。HBM的使用可以为计算提供较高的带宽,对于像RNN,MLP(多层感知机)这样arithmetic intensity(每byte数据可以支持多少次运算)很大的运算来说,可以大大缓解带宽瓶颈。因为在RNN和MLP中,大量的权重数据仅仅用一次就要更新。这不像CNN,权重会被一幅feature map运算多次。数据共享次数小,就造成了带宽需求高。
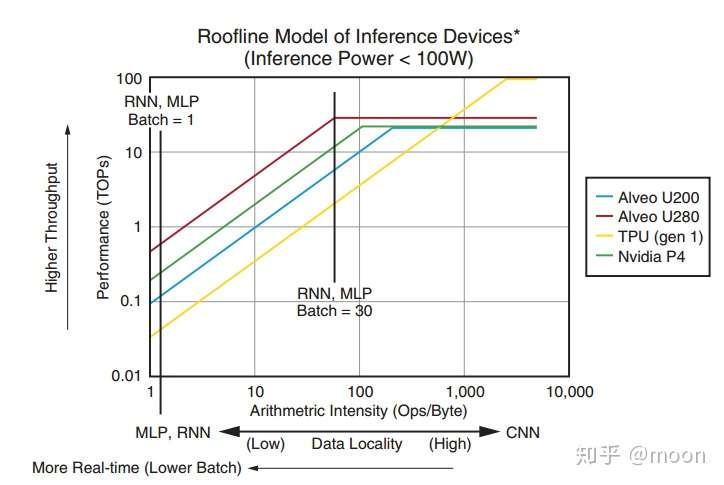 图3.1 不同器件的roofline
图3.1 不同器件的roofline
上图是不同器件的roofline对比,使用了HBM的Alveo在针对RNN和MLP有更好的表现。
NoC 有助于每个硬件组件和软 IP 模块间轻松地相互访问,或通过存储器映射接口访问软件。它提供了一个标准化的、可扩展的硬件框架,使异构引擎和接口逻辑之间能够进行高效通信,总带宽为1Tb/s。
总结
本篇对xilinx的ACAP结构做了简单介绍,这个系列的器件确实是很大的一个改进。其支持软件编程,相信可以更加易用和灵活。不禁让我们做FPGA的担心,越来越软件化,我们将何去何从?



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2020-08-21 How to install the NVIDIA drivers on Fedora 32