

RDMA 在数据中心的可靠传输
https://zhuanlan.zhihu.com/p/257228128?utm_source=wechat_session&utm_medium=social&s_r=0
背景
高带宽、低延迟是目前数据中心应用的基本需求。NVM(Non-Volatile Memory)和 RDMA(Remote Direct Memory Access)可以称得上加速数据中心应用的两架马车,分别从存储和网络方面满足高带宽、低延迟的需求。
TCP/IP 只适用于中等带宽需求且延迟不敏感的应用,不同层级间的数据拷贝和协议栈本身复杂性(现代网卡已经支持部分功能卸载,例如 TSO、CSO、LRO 等,但并不彻底)为 TCP/IP 应用引入了大量延迟。RDMA 通过 Memory Region 机制使得网卡能够直接读写用户态的内存数据,避免了数据拷贝和上下文切换;并将网络协议栈从软件实现 offload 到网卡硬件实现,极大降低了 CPU 开销。随着 RoCEv2(RDMA over Converged Ethernet v2)技术的成熟,RDMA 可以部署在数据中心已有的网络设施上,RDMA 成为数据中心高速网络通信的主流方案。
在大规模数据中心中部署 RoCEv2,首先面临的问题是如何保证 RDMA 的可靠传输。
可靠传输
可靠传输是传输层对上层应用的承诺,上层几乎不需要担心丢包或者重传的问题(只需要配置重试次数和超时时间)。可靠传输的核心是如何应对网络丢包。
为什么会发生丢包?
当发送方发包速率超过了接收方的处理能力时,数据包开始在接收方的接收队列中积压,如果积压情况持续没有缓解直到接收队列满载,接收方只能选择将之后接收到的数据包丢弃。这里的接收方可能是数据包的最终接收者或者中间经过的交换机、路由器。

为什么需要可靠传输?
可靠传输是数据中心应用稳定低延迟的保证。一旦发生丢包,传输层通常会惩罚性地乘性减慢(Multiplicative-decrease)发送速率,并重传丢弃的数据包,用户会感受到突发的性能降级。
以下原因导致了丢包在数据中心网络中很容易发生:
- 普通交换机的浅缓冲区特性。由于成本原因,数据中心交换机的缓冲区一般都不大(几 MB 到数十 MB)。这些缓冲区被所有端口共享 [8],以便实现统计意义的多路复用。
- 许多分布式应用都遵循 Partition/Aggregate 这种通信模式 [4]。一个请求可能分散到多个工作节点进行处理,每个节点处理数据集的一部分。处理完毕后,所有的工作节点几乎同时地把结果汇聚到同一个节点做数据整合。这是典型多打一的场景(又称为 Incast),汇聚节点所在的端口很容易出现积压。
- 多路径负载不均衡。当网络拓扑中存在多条可达路径时,RoCEv2 通过 ECMP(Equal-cost multi-path) 为每个 Flow 选择合适的路由。ECMP 没有感知拥塞情况的能力,Flow 可能被分配到拥塞程度已经十分严重的路径,引起拥塞加剧和丢包。
丢包对 RDMA 造成大幅性能下降,这是由 RDMA 的重传机制决定的。
RDMA 的重传机制实现在网卡内部,功能比较简单。如下图,RDMA 接收方网卡对于每个成功接收到的数据包,都会回复一个 ACK 包。如下图中,PSN(Packet Sequence Number)为 2 的数据包在发送的过程中被丢弃,接收方接收到 PSN 为 3 的数据包时发现 PSN 不连续,会回复一个 PSN 2 的 NACK(Not ACK)给发送方,丢弃后续接收到的数据包(PSN 3 ~ 5)。发送方需要重发 PSN 2 之后的所有数据包,导致大幅性能下降。一般我们称这种方式为 Go-back-N 重传方式,即重传丢弃的数据包 N 之后的所有数据包(Mellanox CX-6 系列网卡已经支持选择性重传,但存在一些限制[16])。而 TCP 的重传则只需要重传丢失的单个数据包,丢包带来的性能负面影响比 RDMA 小得多。

因此 RDMA 要求 L2 层或者 L3 层网络是无损的。利用流量控制可以防止收发双方速率不匹配导致的丢包问题。
流量控制和它带来的问题
流控的原理是,接收方在预测到将要丢包之前通知发送方停止发包。下面介绍几种流控算法的演变。
Global Pause
Global Pause 是 1997 年在 IEEE 802.3x 定义的第一种以太网流控机制,工作在 L2 层。
其工作原理是,接收方发现接收队列深度超过某个阈值时,向发送方发送 XOFF Pause Frame,发送方接收到后就停止一切发送操作,直到收到接收方发来的 XON 控制消息或者超时。
Global Pause 无法对流量进行区分,对于上层应用一些高优先级的流量也会被暂停。
PFC(Priority Flow Control)
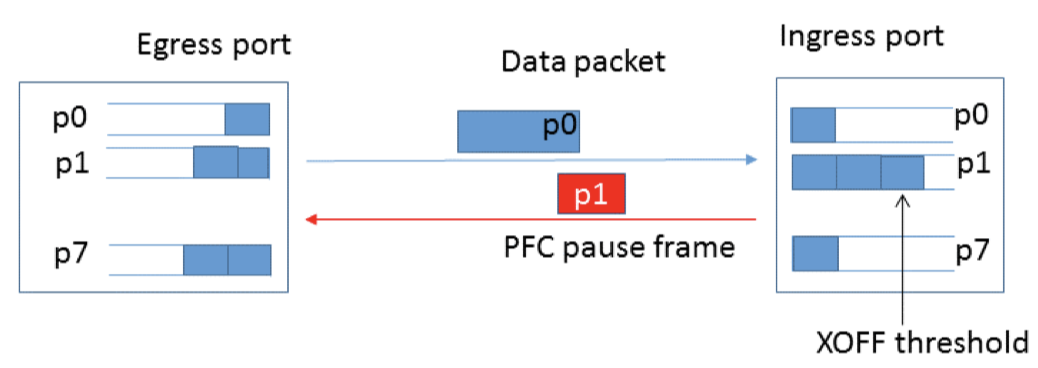
为了解决 Global Pause 不区分流量类型的问题,IEEE 802.1Qbb 定义的 PFC 提出了对网络流量按照优先级 0 - 7 分类。
如上图,对于每个通信实体,有逻辑上的 Egress 端口和 Ingress 端口,分别对应出口和入口流量。每个端口都有 8 个队列,对应优先级 0 - 7,不同优先级的数据包会缓存在不同队列中。
在通信过程中,接收方发现 p1 队列深度超过 XOFF 阈值,意味着数据包积压,接收方发送一个 p1 优先级的 PFC Pause Frame 给发送方。Pause Frame 会包含了每个优先级需要暂停发送的时间。发送方将暂停 p1 优先级数据包的发送,直到收到对方发过来恢复控制帧。
按照优先级字段在数据包中的存放位置,可以将 PFC 分成两类。
基于 PCP 的 PFC

在 IEEE 802.1Qbb 最初的规定,类别 CoS (Class of Service)保存在 L2 层 VLAN Tag 的 PCP(Priority Code Point,3 bits)字段上。
基于 DSCP 的 PFC

然而,VLAN 在某些生产环境可能带来不便,例如有的生产环境需要使用 PXE 方式安装部署系统,而 PXE 启动时候是没有 VLAN 配置的。RoCEv2 包含了 IP 头部,因此可以考虑将优先级保存在 IP 头部的 DSCP 字段。Microsoft 于 2016 年提出了基于 DSCP 的 PFC [1]。 目前大部分厂商的交换机和 RoCE 网卡都已经支持基于 DSCP 的 PFC。
PFC 的问题
在实际部署中 PFC 性能不佳,会导致不公平问题和 Head-of-Line 堵塞问题。
不公平问题

如上图 a),交换机上两个流入端口有数据流向同一个流出端口:Ingress 1 携带 Flow 1,Ingress 2 携带 Flow 2 和 3。
图 b) 触发了 PFC Pause,Ingress 1 和 2 同时暂停发送。
图 c) Egress 1 队列空闲,通知 Ingress 1 和 2 恢复发送。
图 d) 由于 Ingress 1 和 2 是同时暂停和恢复的,Flow 2 和 3 需要竞争 Ingress 2,导致 Flow 1 始终能够获得比 Flow 2 或 3 更高的带宽,出现了不同 Flow 带宽分配不公平。
Head-of-Line 堵塞问题

如上图 a),Flow 1 和 Flow 2 从同一个 Ingress 1 流向不同的 Egress 1 和 2。
图 b),Egress 1 触发了 PFC Pause,Ingress 1 暂停发送。Flow 2 并不需要经过 Egress 1,却受其影响也被暂停了。
如何解决 PFC 问题
PFC 问题本质的原因是,Pause 机制运行在「端口 + 优先级」这个级别,不能细化到每一个 Flow,而粗暴地将整个发送端口停下来了。如果能够动态地调整每个 Flow 的发送速率,保持端口的队列深度比较稳定,那么就不会触发 PFC Pause 了。因此,基于 Flow 的拥塞控制算法出现了。
拥塞控制
拥塞控制与 PFC 有两个明显区别:
- 拥塞控制根据拥塞程度动态调节发送速率,而 PFC 会让发送端口完全停下;
- 拥塞控制一般会由接收方将拥塞情况通知到真正的发送方,而 PFC 只会通知前一跳。
后者意味着拥塞控制能够实现在 Flow 级别:当接收方发现拥塞发生,将会在拥塞通知消息中携带 Flow 标识,通知到发送方。发送方可以据此调节该 Flow 的发送速率。在 RoCE 的语境中,Flow 可以通过一对 RDMA QP(Queue Pairs)来标识。
拥塞控制是一个自适应调节过程,依赖于一个好的拥塞检测方法。
拥塞检测
检测拥塞的方式大致可以归为三类:基于丢包检测、基于 ECN 的检测和基于 RTT 的检测。
基于丢包检测
基于丢包检测的原理很显然,丢包是拥塞持续得不到缓解的最终结果。TCP 经典的 Tahoe 算法和 CUBIC 算法 [19],都是基于丢包来做检测的。上文提到,丢包对于 RDMA 的性能影响要比 TCP 大得多,如果等到已经丢包再进行控制成本就太高了,因此 RDMA 不能采用这种方式。
基于 ECN 检测
ECN(Explicit Congestion Notification)是 IP 头部 Differentiated Services 字段的后两位,用于指示是否发生了拥塞。它的四种取值的含义如下:
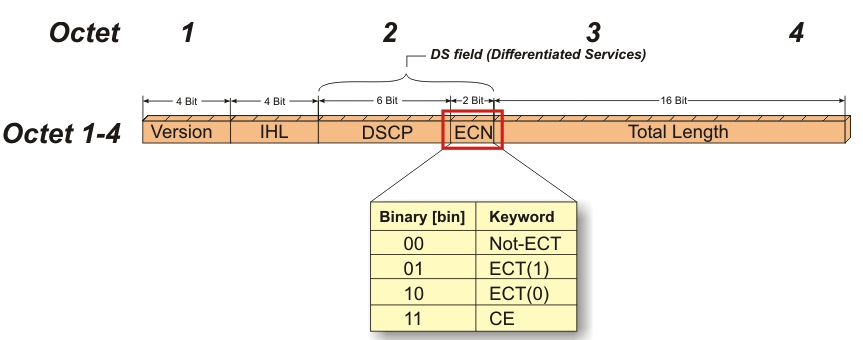
| 00 | Non ECN-Capable Transport | 表示发送方不支持 ECN |
| 01 | ECN Capable Transport | 表示发送方支持 ECN |
| 10 | ECN Capable Transport | 同上 |
| 11 | Congestion Encountered | 表示发生了拥塞 |
部署 ECN 功能一般需要交换机同时开启 RED。如果通信双方都支持 ECN(ECN 为 01 或者 10),当拥塞出现时,交换机会更新报文的 ECN 为 11(Congestion Encountered),再转发给下一跳。接收方可以根据 ECN 标志向发送方汇报拥塞情况,调节发送速率。
RED,即 Random Early Drop,是交换机处理拥塞的一种手段。交换机监控当前的队列深度,当队列接近满了,会开始随机地丢掉一些包。丢弃包的概率与当前队列深度正相关。随机丢弃带来的好处是,对于不同的流显得更公平,发送的包越多,那么被丢弃的概率也越大。
当 RED 和 ECN 同时开启,拥塞发生时交换机不再随机丢包,而是随机为报文设置 ECN。
基于 RTT 检测
RTT(Round-Trip Time)是发送方将数据包发送出去,到接收到对端的确认包之间的时间间隔。RTT 能够反映端到端的网络延迟,如果发生拥塞,数据包会在接收队列中排队等待,RTT 也会相应较高。而 ECN 只能够反映超过队列阈值的包数量,无法精确量化延迟。
RTT 可以选择在软件层或者硬件层做统计。一般网卡接收到数据包后,通过中断通知上层,由操作系统调度中断处理收包事件。中断和调度都将引入一些误差。因此,更精确地统计最好由硬件完成,当网卡接收到包时,网卡立即回复一个 ACK 包,发送方可以根据它的到达时间计算 RTT。
需要注意的是,ACK 回复包如果受到其他流量影响遇到拥塞,那么 RTT 计算会有偏差。可以为 ACK 回复包设置更高优先级。或者保证收发两端网卡的时钟基本上同步,然后在回复包加上时间戳信息。另外,网络路径的切换也会带来一些延迟的变化。
下面介绍 RDMA 下分别基于 ECN 和 RTT 检测的两种主流控制算法。
控制算法
DCQCN(ECN 检测)
DCQCN(Data Center Quantized Congestion Notification)是 2015 年由 Microsoft 和 Mellanox 提出的 RoCEv2 的拥塞控制算法 [2]。其设计基于 QCN(Quantized Congestion Notification)[3] 和 DCTCP(Data Center TCP)[4]。
QCN 是 802.1Qau 定义的 L2 层拥塞控制算法,通过统计单位时间窗口接收到的 CNM(Congestion Notification Message)数量来量化拥塞程度。QCN 根据 MAC 地址和 Flow ID(发送端分配)识别一个 Flow,发生拥塞时接收端发送 CNM 给发送端,而发送端根据量化拥塞程度动态调节该 Flow 的发送速率。如果网络流量跨路由,报文的 MAC 地址将发生变化,接收端无法知道真正的发送端 MAC 地址,拥塞信息也就无法抵达发送端了,因此 QCN 不适用于跨路由的网络。
DCTCP 由网络界大佬 Mohammad Alizadeh 提出,主要改善数据中心小流量被大流量抢占的问题。接收方对于每个打上 ECN 标记的包,都会回复一个 ECN-ECHO 的 ACK,发送方可以根据它来量化拥塞程度,按比例调节拥塞窗口。与普通 TCP 不同的是,TCP 遇到拥塞直接将拥塞窗口(更准确的是拥塞门限值)减小一半。
DCQCN 把 QCN 拓展到 IP 网络,以便用于 RoCEv2,主要功能实现在 RDMA 网卡中,中间交换机只需要支持 RED/ECN。DCQCN 可以划分为三个部分:

拥塞点算法
中间交换机检查当前拥塞情况,当队列深度超过阈值时,通过 RED/ECN 标记报文,然后转发给下一跳。
通知点算法
由接收方网卡完成,主要是把拥塞信息通知到发送方。RoCEv2 新增了 CNP(Congestion Notification Packets)控制报文用于拥塞通知。接收方网卡检查每个接收包的 ECN 标志,如果 CN 被设置,那么发送 CNP 给发送方。为了减少性能开销,每 50 us 只发送一个 CNP(DCTCP 是每个包都回复一个)。
响应点算法
由发送方网卡完成,负责调节发送速率避免拥塞。在每个周期窗口,发送方网卡更新拥塞程度参数(取值为 0 ~ 1),更新的依据是:
- 如果收到拥塞通知,增加拥塞参数

- 否则,逐渐减少拥塞参数

然后根据拥塞程度参数调节发送速率(Rt 为目标速率,Rc 为当前速率),
- 如果收到拥塞通知,降低速率(最多降低到原来的一半):

- 否则(与 QCN 一样)
- 快速恢复(持续没收到拥塞通知的前五个周期,每个周期为每发出 150 KB 报文或者 10 ms),向上一次遇到拥塞的速率 Rt 靠近:

- 主动恢复(快速恢复后,每个周期为 50 个报文或者 5 ms),探测可用带宽(可能超过 Rt):
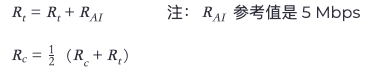
其中拥塞点算法依赖于交换机的已有的 RED/ECN 功能。而通知点和响应点算法需要在 RDMA 网卡实现,包括收发 CNP 报文、发送端需要增加对于每个 Flow 的计时器和字节计数器。目前 Mellanox 的网卡已经支持 DCQCN。
Timely(RTT 检测)
Timely 与 DCQCN 同年出现 SIGCOMM 会议上,由 Google 提出,旨在提供一种通用的拥塞控制方法,而不仅限于 RoCE [5]。它是数据中心网络第一个基于延迟的拥塞控制算法。
Timely 算法主要包括三个部分,它们都运行在发送方。算法不涉及中间交换机的处理,但要求接收方网卡对于每一个接收包回复一个 ACK。
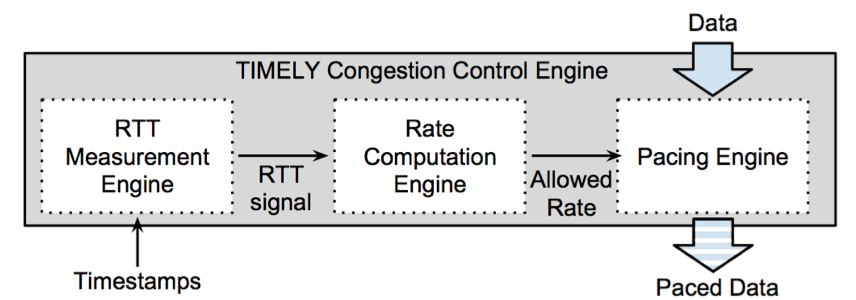
RTT 统计模块

Timely 中将 RTT 定义为数据包在网络中传播时间与在队列中等待时间之和。下面的公式中,发送的时间戳由发送方软件层记录;完成的时间戳为发送方接收到接收方网卡返回的 ACK 时间戳。由于一个大包可能被拆分成多个,同时数据包从网卡发送出去有传输时延,因此还需要减去这部分时间。
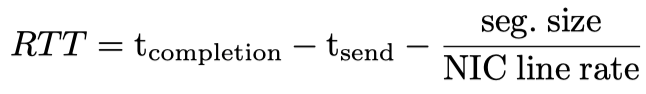
速率计算模块
对于每一个发包结束事件,速率计算模块从 RTT 统计模块得到该包的 RTT,然后输出一个期望的发送速率。
Timely 并没有根据 RTT 的绝对值来衡量拥塞情况,而是通过 RTT 的梯度变化来捕捉延迟变化:当 RTT 上升时,表明拥塞愈发严重;反之,拥塞正在减轻。这种方式对于延迟更加敏感,有利于满足应用低延迟需求。

速率计算的算法如上图,首先计算 RTT 梯度变化。计算连续两个 RTT 的差值,并与历史值做平滑化过滤掉突发抖动带来的偏差,然后再与 minimum RTT(可以取值为估计的网络传播往返时间)做归一化,得到 RTT 梯度变化率。然后确定期望的发送速率:

- 如果新的 RTT 低于 Tlow,那么采用和性增长(Additive Increment)探测可用带宽,提高发送速率。流量刚启动时,RTT 可能会突然增长,这时候不应该视为拥塞加重。
- 如果新的 RTT 高于 Thigh,那么采用乘性减少(Multiplicative Decrement)减少发送速率。如果 RTT 持续维持在高水平,但梯度几乎没有变化,就需要这个机制防止拥塞。
- 根据 RTT 梯度变化率计算,
- 如果 RTT 梯度变化率不为正,说明拥塞减轻,那么通过和性增长提高发送速率。如果连续五次 RTT 梯度变化率都不为正,那么增长步长相应提高。
- 如果 RTT 梯度变化率为正,说明拥塞加重,那么通过乘性减少方式降低发送速率。
速率控制模块
Timely 在软件层增加了一个调度器。当应用需要发送数据包时,不会将发送请求提交给网卡,而是先交给调度器。根据前一模块得到的期望发送速率,调度器将注入发包延迟,把能够放行的数据包交给网卡发送,将需要延迟发送的数据包加入等待队列中,在未来发送。
算法对比
DCQCN 作者随后于 2016 年在文章 [6] 中,通过流体模型和仿真测试证明 Timely 将 RTT 作为唯一衡量标准,难以同时兼顾公平性和延迟上限;而 DCQCN 却可以做到。感兴趣的同学可以了解一下。
下面从检测方式、不同通信组件行为、速率调整方式、适用场景等角度对比 DCQCN 和 Timely 两种拥塞控制算法,同时也把经典的 TCP Tahoe 流控作为参考。DCQCN 和 Timely 没有采用基于窗口的调整方式,主要是窗口方式可能出现突发的流量带来较大延迟,同时实现起来也比基于速率的方式复杂。
<table data-draft-node="block" data-draft-type="table" data-size="normal" data-row-style="normal">
在生产中,一般需要调节 DCQCN 和 Timely 的参数,使得它们在 PFC 生效之前先被触发。但 PFC 仍然是必要的配置,因为无论是 DCQCN 还是 Timely,RDMA 网卡在开始传输时都是以线速发送而不是慢启动探测,需要借助于 PFC 防止拥塞和丢包严重化。
DCQCN 的实现主要在网卡,是 RDMA 目前推荐的拥塞控制方案。
讨论:流控是否有必要?
总结一下,RDMA 对于丢包十分敏感,需要 PFC 流控防止丢包发生。PFC 流控有不公平和 Head-of-Line 堵塞问题,需要借助拥塞控制缓解它对网络性能带来的负面影响。但是,流控和拥塞控制有许多参数需要配置,默认参数无法适应所有场景,在我们的部署中就发现需要进行繁琐的调参过程。
回过头来,我们思考一下 RDMA 是否可以没有 PFC 流控呢?
网卡改进
RDMA 网卡低效的 Go-back-N 重传方式导致其依赖于 PFC。沿着这一思路,Timely 的作者于 2018 年提出新的 RDMA 网卡设计 IRN(Improved RoCE NIC)[7]。其灵感来源于 iWARP,在设计哲学上却与 iWARP 有本质差别:iWARP 力求完整地将 TCP/IP 协议栈在网卡内部实现一遍,虽然可以高效应对丢包问题,但是其臃肿而复杂的实现导致其性能低下,在市场上表现弱于 RoCE;IRN 则是在 RoCEv2 之上做加法,只考虑加入最小的功能来去除对 PFC 的依赖。
IRN 主要从两方面改进 RoCE 网卡:
1)增强丢包恢复机制
类似于 TCP,接收方不丢弃乱序包,发送方只选择性重传丢失的数据包。当接收方接收到一个乱序包,接收方会回复一个 NACK,携带当前接收到的包序列号和期望收到的包序列号。发送方根据它就知道哪些包丢失了,哪些包已经被成功接收。
网卡作为发送方时,通过维护一个位图记录发送的包是否收到了确认,如果接收到 NACK 或者发送超时,那么就会重传丢失或者超时的数据包。
网卡作为接收方时,需要处理接收到的乱序包。假设我们限制每个 Flow 最多同时发送 100 个标准 MTU 大小(1 KB)大小的包,为了支持 1000 个 Flow,网卡需要至少 100 MB 内存缓存乱序的包。而网卡内部一般只有几 MB 的内存。IRN 提出不缓存接收到的乱序包,而是直接 DMA 写到用户的内存中。在这种设计下,需要解决以下问题:
- 首包问题。对于一个 RDMA Write 操作,可能被拆分成多个 MTU 大小的包,只有第一个包包含 RETH(RDMA Extented Transport Header)携带远端的地址信息,如果第一个包在其他包之后被接收,其他包将无法知道 DMA 的目的地址。因此,IRN 要求为每个包都有 RETH 信息的拷贝。
- WQE(Work Queue Entry)匹配问题。熟悉 RDMA 编程 API 的同学知道,应用通过构造一个 WQE 发起 RDMA 操作,WQE 记录了操作的描述信息。RDMA 的内部实现假定了每次接收到完整的数据包,对应的就是下一个待处理的 WQE。乱序推翻了这一假设。IRN 要求每个 WQE 有自己的序列号,同时报文头部需要携带序列号信息,用于两者匹配。
- 尾包问题。RDMA 网卡在处理最后一个包时,一般会对包序列号加一,同时产生一个 CQE(Completion Queue Entry)用于通知上层 RDMA 操作完成。在乱序场景中,只有当同一个操作的所有包都完成传输,才能向上通知完成事件。IRN 需要额外的状态来跟踪每个包是否是最后一个完成传输的包。
- 覆盖写问题。假如同一片内存区域发生了两次 RDMA 写操作,第一次写操作发生了丢包,第二次写先到达,第一次写经过重传后到达,就可能出现旧数据将新数据覆盖。IRN 需要上层应用自己处理这一问题。
2)网卡内实现基于 BDP(Bandwidth Delay Product)的流量控制
Bandwidth 一般是通信双方网卡支持的速率上限,Delay 是网络包在网络信道中的传播时间,因此 BDP 反映的是端到端的最大通信能力。文中计算 BDP 时 Delay 采用的是其网络最长路径的传播时延估算值,这样才能保证在最长路径中,网络带宽始终是满载的。
将每个 Flow 发送中的流量限制在一个 BDP 内,一方面可以减少网卡需要维护每个包状态的数量,另一方面也降低了中间交换机出现缓冲区溢出的可能性。我们来简单计算一下:一个 25GbE 两层网络架构,跨 ToR 交换机两个节点间的 RTT 大概是 6us,BDP 为 19 KB(即 25 * 1000 * 1000 * 1000 * 6 / 1000 / 1000 / 8 B);而 Mellanox Spectrum 交换机的动态缓冲区大小为 12 MB,因此可以容忍大约 640 路 Incast。这样,在一般场景下丢包会很少出现,也就可以去掉 PFC 的配置了。
这种方式可能存在的缺陷是:
- 如果多个 Flow 同时经过同一路径,即便限制每个 Flow 流量在 BDP 内,在中间路径交换机上仍旧会开始排队积压,乃至出现丢包。一种可能的优化方式是动态地调整 BDP 限制值。
- 它要求整张网络中没有其他一些不守规矩的流量。换句话说,它要求网络中的所有流量都限制在 BDP 内。
- BDP 的取值可能影响性能。如果设置地过小,那么带宽可能无法跑满;设置地过大,可能容易引起拥塞。
总结一下,选择性重传实际上在 TCP 早已支持,但在 RDMA 中实现却是困难重重,这主要是因为 RDMA 零拷贝的设计以及 RDMA 网卡内部资源受限。IRN 目前并没有完整实现,带来的更多是对于未来 RDMA 网卡设计的思考。
应用约束
针对小包传输为主的业务,拥塞导致丢包发生的几率非常小,PFC 就没有那么必要了。基于这一思想,Anuj Kalia 提出了 FaSST(Fast, Scalable and Simple Distributed Transactions)[17](OSDI 2016),一个基于不可靠的 RDMA 数据报传输模式设计的分布式事务系统。FaSST 中的 RPC 大小一般是 256 字节。由于丢包很少发生,FaSST 直接重启 FaSST 进程,处理方式比较粗暴。
Anuj Kalia 后续在 NSDI 2019 又提出了 eRPC [8],旨在提供数据中心的一个通用的高性能 RPC 库,大家不再需要为了高性能将 RDMA 网络模块和业务逻辑耦合在一起实现。eRPC 主要的设计要点有,
- 为了减少拥塞,IRN 在网卡内部实现基于 BDP 的流量控制,eRPC 则是在应用层实现。eRPC 为每一个 RPC 会话分配可用的发送额度 credits,其值小于 BDP 与 MTU 的商。RPC 客户端每次发送一个请求都需要花费一个 credit,服务端确认接收后归还一个 credit。如果 credits 耗尽,客户端的请求将进入队列。eRPC 默认的 credits 额度为 8。可以想象到 credits 值的选择将影响到单个会话和多个会话的带宽和延迟。
- 在 RDMA 数据报传输模式下,网卡不会处理丢包或者乱序包。eRPC 会丢弃所有的乱序包,然后客户端以 Go-back-N 方式重传丢包序列号之后的所有请求。eRPC 认为丢包是非常罕见的,因此并没有在丢包处理上做太多优化。
FaSST 和 eRPC 都是基于不可靠的 RDMA 数据报传输模式,不再需要 PFC,适合丢包很少的业务场景。对于像分布式存储这样的业务就不适合了。可见,针对具体业务场景进行选型也是 RDMA 系统设计的重点。
展望
流控和拥塞控制技术是网络领域的基本问题,对于 RDMA 这种新型网络也不例外。DCQCN 的出现使得 RDMA 在数据中心真正落地,可以想象未来将会有更多的 RDMA 应用。简单总结一下 RDMA 应用和研究的现状。
如何用好 RDMA 本身的研究,如 [13, 14]。这已经比较成熟,前人总结了许多经验:
- 如何使用 Memory Region 管理内存?
- 如何选择 RDMA Verbs?
- 编程基于事件驱动还是轮询?
- 如何减少 MMIO 或者 DMA 操作提高性能?
- 如何避免网卡的 Cache Miss?
- 如何利用好网卡的多队列和多处理器并发?
流控和拥塞控制。PFC 和 DCQCN 的配置对于大规模数据中心带来不小挑战,参数配置会极大影响性能。基于 SDN 由中央控制器负责调度整张网络的流量是一个比较 promising 的方向。另外,基于机器学习的拥塞控制算法也有不少研究。
网卡架构的新设计。目前 RDMA 网卡已经支持包括 NVMe over Fabric、EC、OvS、VXLAN/NVGRE 等多种功能卸载。对于 IRN 提出的乱序接收问题,Mellanox ConnectX-5 网卡已经支持乱序数据存放,但需要用户层自己检测乱序。相信 RDMA 与 SRIOV、NVM、Multi-Path、容器等技术的结合中会对网卡设计带来更多的需求。
RDMA 在容器中的应用。SRIOV 可以将 RDMA 网卡的虚拟功能分配给容器使用,但是容器迁移时需要重新配置,不够轻便。最近有一些研究希望在软件层面实现 RDMA 在容器中的隔离,将 RDMA 控制路径(如创建 QP,注册 MR,创建 GID 等)交给软件层实现,例如 FreeFlow(NSDI 2019)和 MasQ(SIGCOMM 2020)。另外,vDPA [18] 允许 VM 或者 容器通过标准的 VirtIO 控制和数据接口与网卡 VF 交互,目前已经在 RedHat 支持,在未来可能替代 SRIOV,vDPA 与 RDMA 结合也是一个有意思的话题。
RDMA 与新型存储结合。目前基于 RDMA 的网络存储协议发展比较成熟,包括 NFS over RDMA、iSER、NVMe over Fabric 等,许多存储厂商已经支持。对于新型的 NVM,FileMR(NSDI 2020)提出了如何将 RDMA 和 NVM 之间重叠的部分(命名、权限管理、内存管理等)去掉,提高效率。
如果你也对 RDMA 技术感兴趣,也欢迎加入我们。
参考文献
[1] RDMA over Commodity Ethernet at Scale
[2] Congestion Control for Large-Scale RDMA Deployments
[3] Data Center Transport Mechanisms: Congestion Control Theory and IEEE Standardization
[5] TIMELY: RTT-based Congestion Control for the Datacenter
[6] ECN or Delay: Lessons Learnt from Analysis of DCQCN and TIMELY
[7] Revisiting Network Support for RDMA
[8] Datacenter RPCs can be General and Fast
[9] Traffic Control for RDMA-Enabled Data Center Networks- A Survey
[10] White Paper: RoCE in the Data Center
[11] RDMA in Data Centers: Looking Back and Looking Forward
[12] 数据中心网络的流量控制:研究现状与趋势
[13] Minimizing the Hidden Cost of RDMA
[14] Design Guidelines for High Performance RDMA Systems
[15] Intro to Congestion Control
[16] ConnectX-6 Dx Adapter Cards Firmware Release Notes
[17] FaSST: Fast, Scalable and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs
[18] Achieving network wirespeed in an open standard manner: introducing vDPA
作者介绍
Jiewei,SmartX 研发工程师。SmartX 拥有国内最顶尖的分布式存储和超融合架构研发团队,是国内超融合领域的技术领导者。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2020-08-16 Create a cursor from hardcoded array instead of DB