

7——Refactoring a Monolith into Microservices
https://www.nginx.com/blog/refactoring-a-monolith-into-microservices/
This is the seventh and final article in my series about building applications with microservices. The first article introduces the Microservice Architecture pattern and discusses the benefits and drawbacks of using microservices. The following articles discuss different aspects of the microservice architecture: using an API Gateway, inter-process communication, service discovery, event-driven data management, and deploying microservices. In this article, we look at strategies for migrating a monolithic application to microservices.
I hope that this series of articles has given you a good understanding of the microservice architecture, its benefits and drawbacks, and when to use it. Perhaps the microservice architecture is a good fit for your organization. However, there is fairly good chance you are working on a large, complex monolithic application. Your daily experience of developing and deploying your application is slow and painful. Microservices seem like a distant nirvana. Fortunately, there are strategies that you can use to escape from the monolithic hell. In this article, I describe how to incrementally refactor a monolithic application into a set of microservices.
Editor’s note – This seven-part series of articles is now complete:
- Introduction to Microservices
- Building Microservices: Using an API Gateway
- Building Microservices: Inter-Process Communication in a Microservices Architecture
- Service Discovery in a Microservices Architecture
- Event-Driven Data Management for Microservices
- Choosing a Microservices Deployment Strategy
- Refactoring a Monolith into Microservices (this article)
Overview of Refactoring to Microservices
The process of transforming a monolithic application into microservices is a form of application modernization. That is something that developers have been doing for decades. As a result, there are some ideas that we can reuse when refactoring an application into microservices.
One strategy to not use is the “Big Bang” rewrite. That is when you focus all of your development efforts on building a new microservices-based application from scratch. Although it sounds appealing, it is extremely risky and will likely end in failure. As Martin Fowler reportedly said, “the only thing a Big Bang rewrite guarantees is a Big Bang!”
Instead of a Big Bang rewrite, you should incrementally refactor your monolithic application. You gradually build a new application consisting of microservices, and run it in conjunction with your monolithic application. Over time, the amount of functionality implemented by the monolithic application shrinks until either it disappears entirely or it becomes just another microservice. This strategy is akin to servicing your car while driving down the highway at 70 mph – challenging, but far less risky than attempting a Big Bang rewrite.
Martin Fowler refers to this application modernization strategy as the Strangler Application. The name comes from the strangler vine (a.k.a. strangler fig) that is found in rainforests. A strangler vine grows around a tree in order to reach the sunlight above the forest canopy. Sometimes, the tree dies, leaving a tree-shaped vine. Application modernization follows the same pattern. We will build a new application consisting of microservices around the legacy application, which will eventually die.

Let’s look at different strategies for doing this.
Strategy 1 – Stop Digging
The Law of Holes says that whenever you are in a hole you should stop digging. This is great advice to follow when your monolithic application has become unmanageable. In other words, you should stop making the monolith bigger. This means that when you are implementing new functionality you should not add more code to the monolith. Instead, the big idea with this strategy is to put that new code in a standalone microservice. The following diagram shows the system architecture after applying this approach.
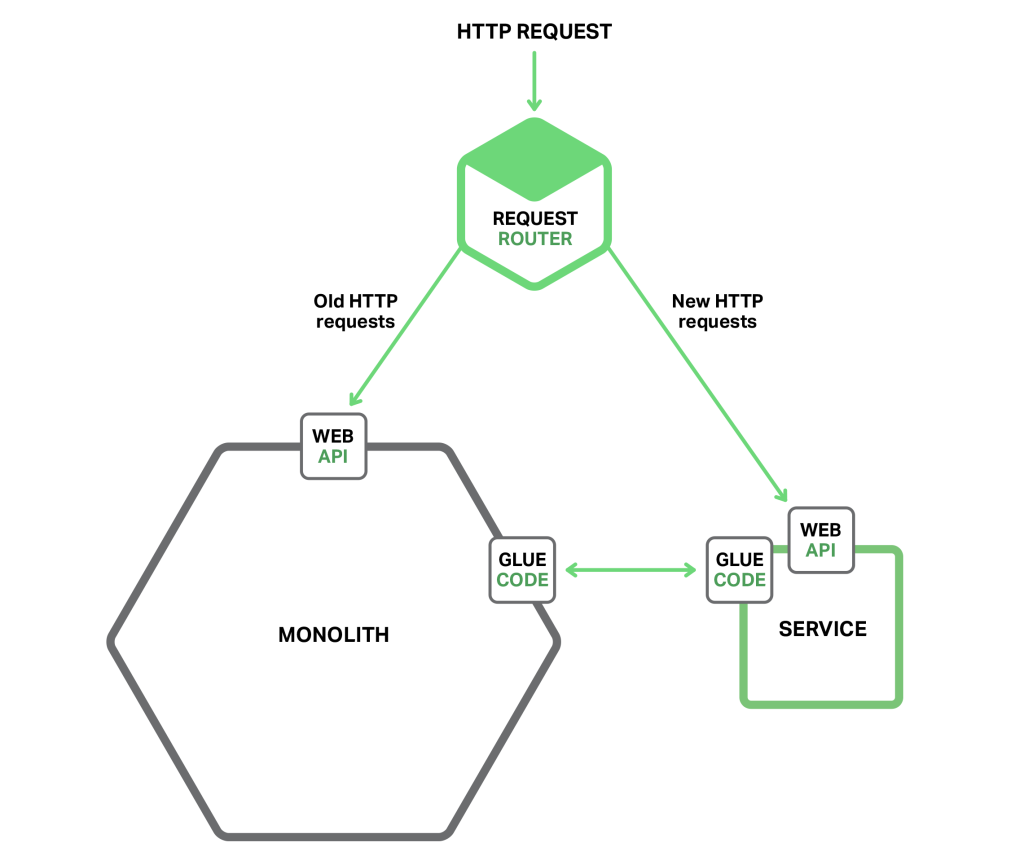
As well as the new service and the legacy monolith, there are two other components. The first is a request router, which handles incoming (HTTP) requests. It is similar to the API gateway described in an earlier article. The router sends requests corresponding to new functionality to the new service. It routes legacy requests to the monolith.
The other component is the glue code, which integrates the service with the monolith. A service rarely exists in isolation and often needs to access data owned by the monolith. The glue code, which resides in either the monolith, the service, or both, is responsible for the data integration. The service uses the glue code to read and write data owned by the monolith.
There are three strategies that a service can use to access the monolith’s data:
- Invoke a remote API provided by the monolith
- Access the monolith’s database directly
- Maintain its own copy of the data, which is synchronized with the monolith’s database
The glue code is sometimes called an anti-corruption layer. That is because the glue code prevents the service, which has its own pristine domain model, from being polluted by concepts from the legacy monolith’s domain model. The glue code translates between the two different models. The term anti-corruption layer first appeared in the must-read book Domain Driven Design by Eric Evans and was then refined in a white paper. Developing an anti-corruption layer can be a non-trivial undertaking. But it is essential to create one if you want to grow your way out of monolithic hell.
Implementing new functionality as a lightweight service has a couple of benefits. It prevents the monolith from becoming even more unmanageable. The service can be developed, deployed, and scaled independently of the monolith. You experience the benefits of the microservice architecture for each new service that you create.
However, this approach does nothing to address the problems with the monolith. To fix those problems you need to break up the monolith. Let’s look at strategies for doing that.
Strategy 2 – Split Frontend and Backend
A strategy that shrinks the monolithic application is to split the presentation layer from the business logic and data access layers. A typical enterprise application consists of at least three different types of components:
- Presentation layer – Components that handle HTTP requests and implement either a (REST) API or an HTML-based web UI. In an application that has a sophisticated user interface, the presentation tier is often a substantial body of code
- Business logic layer – Components that are the core of the application and implement the business rules
- Data-access layer – Components that access infrastructure components such as databases and message brokers
There is usually a clean separation between the presentation logic on one side and the business and data-access logic on the other. The business tier has a coarse-grained API consisting of one or more facades, which encapsulate business-logic components. This API is a natural seam along which you can split the monolith into two smaller applications. One application contains the presentation layer. The other application contains the business and data access logic. After the split, the presentation logic application makes remote calls to the business logic application. Thee following diagram shows the architecture before and after the refactoring.

Splitting a monolith in this way has two main benefits. It enables you to develop, deploy, and scale the two applications independently of one another. In particular, it allows the presentation-layer developers to iterate rapidly on the user interface and easily perform A/B testing, for example. Another benefit of this approach is that it exposes a remote API that can be called by the microservices that you develop.
This strategy, however, is only a partial solution. It is very likely that one or both of the applications will be an unmanageable monolith. You need to use the third strategy to eliminate the remaining monolith or monoliths.
Strategy 3 – Extract Services
The third refactoring strategy is to turn existing modules within the monolith into standalone microservices. Each time you extract a module and turn it into a service, the monolith shrinks. Once you have converted enough modules, the monolith will cease to be a problem. Either it disappears entirely or it becomes small enough that it is just another service.
Prioritizing Which Modules to Convert into Services
A large, complex monolithic application consists of tens or hundreds of modules, all of which are candidates for extraction. Figuring out which modules to convert first is often challenging. A good approach is to start with a few modules that are easy to extract. This will give you experience with microservices in general and the extraction process in particular. After that you should extract those modules that will give you the greatest benefit.
Converting a module into a service is typically time consuming. You want to rank modules by the benefit you will receive. It is usually beneficial to extract modules that change frequently. Once you have converted a module into a service, you can develop and deploy it independently of the monolith, which will accelerate development.
It is also beneficial to extract modules that have resource requirements significantly different from those of the rest of the monolith. It is useful, for example, to turn a module that has an in-memory database into a service, which can then be deployed on hosts with large amounts of memory. Similarly, it can be worthwhile to extract modules that implement computationally expensive algorithms, since the service can then be deployed on hosts with lots of CPUs. By turning modules with particular resource requirements into services, you can make your application much easier to scale.
When figuring out which modules to extract, it is useful to look for existing coarse-grained boundaries (a.k.a seams). They make it easier and cheaper to turn modules into services. An example of such a boundary is a module that only communicates with the rest of the application via asynchronous messages. It can be relatively cheap and easy to turn that module into a microservice.
How to Extract a Module
The first step of extracting a module is to define a coarse-grained interface between the module and the monolith. It is mostly likely a bidirectional API, since the monolith will need data owned by the service and vice versa. It is often challenging to implement such an API because of the tangled dependencies and fine-grained interaction patterns between the module and the rest of the application. Business logic implemented using the Domain Model pattern is especially challenging to refactor because of numerous associations between domain model classes. You will often need to make significant code changes to break these dependencies. The following diagram shows the refactoring.
Once you implement the coarse-grained interface, you then turn the module into a free-standing service. To do that, you must write code to enable the monolith and the service to communicate through an API that uses an inter-process communication (IPC) mechanism. The following diagram shows the architecture before, during, and after the refactoring.

In this example, Module Z is the candidate module to extract. Its components are used by Module X and it uses Module Y. The first refactoring step is to define a pair of coarse-grained APIs. The first interface is an inbound interface that is used by Module X to invoke Module Z. The second is an outbound interface used by Module Z to invoke Module Y.
The second refactoring step turns the module into a standalone service. The inbound and outbound interfaces are implemented by code that uses an IPC mechanism. You will most likely need to build the service by combining Module Z with a Microservice Chassis framework that handles cross-cutting concerns such as service discovery.
Once you have extracted a module, you have yet another service that can be developed, deployed, and scaled independently of the monolith and any other services. You can even rewrite the service from scratch; in this case, the API code that integrates the service with the monolith becomes an anti-corruption layer that translates between the two domain models. Each time you extract a service, you take another step in the direction of microservices. Over time, the monolith will shrink and you will have an increasing number of microservices.
Summary
The process of migrating an existing application into microservices is a form of application modernization. You should not move to microservices by rewriting your application from scratch. Instead, you should incrementally refactor your application into a set of microservices. There are three strategies you can use: implement new functionality as microservices; split the presentation components from the business and data access components; and convert existing modules in the monolith into services. Over time the number of microservices will grow, and the agility and velocity of your development team will increase.
Editor’s note – This seven-part series of articles is now complete:
- Introduction to Microservices
- Building Microservices: Using an API Gateway
- Building Microservices: Inter-Process Communication in a Microservices Architecture
- Service Discovery in a Microservices Architecture
- Event-Driven Data Management for Microservices
- Choosing a Microservices Deployment Strategy
- Refactoring a Monolith into Microservices (this article)
Guest blogger Chris Richardson is the founder of the original CloudFoundry.com, an early Java PaaS (Platform as a Service) for Amazon EC2. He now consults with organizations to improve how they develop and deploy applications. He also blogs regularly about microservices at http://microservices.io



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通