

【Linux 内核网络协议栈源码剖析】系统网络协议栈初始化及数据传输通道建立过程
本文先大致阐述系统协议栈初始化过程,然后剖析数据包的接收和发送通道过程,在文章最后着重梳理其过程及通道结构区别。
源码版本:Linux kernel 1.2.13;工具:Source Insight 3.5
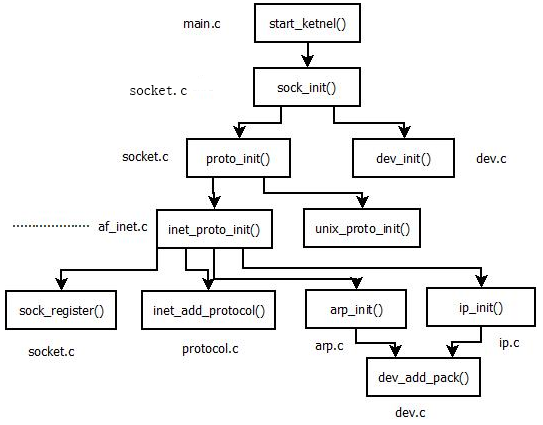
下图为网络协议栈初始化程序流程框架
本篇幅将根据上图来介绍系统网络协议栈的初始化过程。
先从init/main.c 文件出发,在执行了一系列涉及到具体处理器架构初始化代码之后,最终将进入到 init/main.c 中的start_kernel 函数执行。该函数内部将调用各个初始化程序,我们这里只关注网络栈的初始化过程:系统网络栈初始化总入口函数即为sock_init
函数,网络栈的初始化将从该函数出发完成。
sock_init 函数定义在 net/socket.c 中,其调用:
1> proto_init 函数:进行协议实现模块初始化;
2> dev_init 函数:进行网络设备驱动层模块初始化;
3> 初始化专门用于网络处理的下半部分执行函数:net_bh,并使能;
4> 将由变量pops指向的域操作函数集合(如INET域,UNIX域)数组清零,在此后的网络栈初始化中会对其进行正确的初始化。
前面的学习我们了解到,不同的域对应不同的域操作函数。
//系统网络栈初始化
void sock_init(void)
{
int i;
printk("Swansea University Computer Society NET3.019\n");
/*
* Initialize all address (protocol) families.
*/
//pops指向的域操作函数集合(如INET域,UNIX域等)数组清零,
//此后的网络栈初始化中会对其进行正确的初始化
for (i = 0; i < NPROTO; ++i) pops[i] = NULL;
/*
* Initialize the protocols module.
*/
//协议实现模块初始化
proto_init();
#ifdef CONFIG_NET
/*
* Initialize the DEV module.
*/
//网络设备驱动层模块初始化
dev_init();
/*
* And the bottom half handler
*/
//初始化专门用于网络处理的下本部分执行函数:net_bh,并使能。
bh_base[NET_BH].routine= net_bh;
enable_bh(NET_BH);
#endif
}好,接下来看看 proto_init 函数,该函数定义在 net/socket.c 中,其主要完成一下工作:
遍历由 protocols 全局变量(net/protocols.c)指向的域初始化函数集,进行各域的初始化。INET域就初始化为 inet_proto_init,其将在 proto_init 函数被调用以进行 INET 的初始化,UNIX 域的初始化函数为 unix_proto_init。当然还涉及其余域的初始化。
//协议实现模块初始化
void proto_init(void)
{
extern struct net_proto protocols[]; /* Network protocols */
struct net_proto *pro;
/* Kick all configured protocols. */
//遍历由protocols全局变量指向的域初始化函数集,
//进行各域的初始化
pro = protocols;
while (pro->name != NULL)
{
(*pro->init_func)(pro);
pro++;
}
/* We're all done... */
}dev_init 函数则是对系统中存在的所有网络设备进行初始化操作,其实际上是由具体硬件驱动程序进行初始化,函数实现是内部调用 device 结构中 init 字段指向的函数完成各自特定硬件设备的初始化工作,如果初始化失败,该设备将从系统设备列表中(dev_base指向)删除。
/*
* Initialize the DEV module. At boot time this walks the device list and
* unhooks any devices that fail to initialise (normally hardware not
* present) and leaves us with a valid list of present and active devices.
*
* The PCMCIA code may need to change this a little, and add a pair
* of register_inet_device() unregister_inet_device() calls. This will be
* needed for ethernet as modules support.
*/
void dev_init(void)
{
struct device *dev, *dev2;
/*
* Add the devices.
* If the call to dev->init fails, the dev is removed
* from the chain disconnecting the device until the
* next reboot.
*/
dev2 = NULL;
for (dev = dev_base; dev != NULL; dev=dev->next)
{
if (dev->init && dev->init(dev))
{
/*
* It failed to come up. Unhook it.
*/
if (dev2 == NULL)
dev_base = dev->next;
else
dev2->next = dev->next;
}
else
{
dev2 = dev;
}
}
}回到proto_init 函数,前面说到该函数的功能是进行各域的初始化。这里我们着重介绍INET域的初始化。
初始化INET域,则是通过调用 inet_proto_init 函数来实现的,参见注释(net/inet/af_inet.c)
/*
* Called by socket.c on kernel startup.
*/
//INET域初始化
void inet_proto_init(struct net_proto *pro)
{
struct inet_protocol *p;
int i;
printk("Swansea University Computer Society TCP/IP for NET3.019\n");
/*
* Tell SOCKET that we are alive...
*/
//注册一个域操作集
(void) sock_register(inet_proto_ops.family, &inet_proto_ops);
seq_offset = CURRENT_TIME*250;
/*
* Add all the protocols.
*/
//初始化INET下所有协议类型
//这些变量都是proto结构体类型,不同协议有对应的proto变量
//proto结构体内包含操作函数集,套接字散列表,以及使用标志字段等
for(i = 0; i < SOCK_ARRAY_SIZE; i++)
{
tcp_prot.sock_array[i] = NULL;
udp_prot.sock_array[i] = NULL;
raw_prot.sock_array[i] = NULL;
}
tcp_prot.inuse = 0;
tcp_prot.highestinuse = 0;
udp_prot.inuse = 0;
udp_prot.highestinuse = 0;
raw_prot.inuse = 0;
raw_prot.highestinuse = 0;
printk("IP Protocols: ");
//下面进行传输层和网络层之间的衔接:网络层处理函数结果本层的处理后,将查询inet_protos数组,
//匹配合适的传输层协议,调用其对应inet_protocol结构中注册的接收函数
//具体是通过将由inet_protocol_base全局变量指向的inet_protocol结构队列中的元素
//散列到inet_protos哈希表中,从而被网络层使用。该操作通过调用inet_add_protocol函数实现
for(p = inet_protocol_base; p != NULL;)
{
struct inet_protocol *tmp = (struct inet_protocol *) p->next;
inet_add_protocol(p);
printk("%s%s",p->name,tmp?", ":"\n");
p = tmp;
}
/*
* Set the ARP module up
*/
//ARP协议初始化函数
arp_init();
/*
* Set the IP module up
*/
//IP协议初始化函数
ip_init();
}上面的 inet_add_protocol 函数进行传输层和网络层之间的衔接,将由 inet_protocol_base 指向的链表中 inet_protocol 结构插入到由 inet_protos 表示的数组中,从而被网络层使用。
void inet_add_protocol(struct inet_protocol *prot)
{
unsigned char hash;
struct inet_protocol *p2;
hash = prot->protocol & (MAX_INET_PROTOS - 1);
prot ->next = inet_protos[hash];
inet_protos[hash] = prot;
prot->copy = 0;
/* Set the copy bit if we need to. */
p2 = (struct inet_protocol *) prot->next;
while(p2 != NULL) {
if (p2->protocol == prot->protocol) {
prot->copy = 1;
break;
}
p2 = (struct inet_protocol *) prot->next;
}
}在 inet_proto_init 函数内部我们还可以看到,该函数最后调用了 arp_init 函数和 ip_init 函数分别进行ARP 协议初始化函数和IP协议初始化函数。
arp_init 函数:
//ARP协议初始化函数
//ARP协议是网络层协议,为了从链路层接收数据包,其必须定义个packet_type结构
void arp_init (void)
{
/* Register the packet type */
arp_packet_type.type=htons(ETH_P_ARP);
//向链路层模块注册
dev_add_pack(&arp_packet_type);
/* Start with the regular checks for expired arp entries. */
//添加定时器
add_timer(&arp_timer);
/* Register for device down reports */
//注册时间通知句柄函数,监听网络设备状态变化事件
register_netdevice_notifier(&arp_dev_notifier);
}该函数主要完成注册工作,同时注册事件通知句柄函数,监听网络设备状态变化事件,从而对ARP缓存进行及时更新,以维护ARP缓存内容的有效性。
ip_init 函数同样完成该协议接收函数对链路层的注册,同时由于路由表项与网络设备绑定的原因,也必须注册网络设备变化事件监听函数对此类事件进行监听。
/*
* IP registers the packet type and then calls the subprotocol initialisers
*/
//IP初始化函数
void ip_init(void)
{
ip_packet_type.type=htons(ETH_P_IP);
//将IP协议对应的packet_type插入到ptype_base指向的队列中,完成对下层的注册
dev_add_pack(&ip_packet_type);
/* So we flush routes when a device is downed */
//注册网络接收设备时间处理函数
register_netdevice_notifier(&ip_rt_notifier);
/* ip_raw_init();
ip_packet_init();
ip_tcp_init();
ip_udp_init();*/
}看到没,arp_init 函数和 ip_init 函数内部都调用了 dev_add_pack 函数向链路层模块注册。
将协议对应的packet_type插入到ptype_base指向的队列中,完成对下层的注册
/*
* Add a protocol ID to the list. Now that the input handler is
* smarter we can dispense with all the messy stuff that used to be
* here.
*/
void dev_add_pack(struct packet_type *pt)
{
if(pt->type==htons(ETH_P_ALL))
dev_nit++;
pt->next = ptype_base;
ptype_base = pt;
}至此,网络栈初始化工作全部完成,经过 inet_proto_init,arp_init,ip_init 函数的执行,系统完成了由下而上的各层接口之间的衔接。
1> 链路层和网络层经过 ptype_base 指向的 packet_type 结构队列进行衔接,每个packet_type 结构表示一个网络层协议,结构中定义有网络层协议号及其接收函数,链路层模块将根据链路层首部中标识的网络层协议号在队列中进行查找,从而调用对应的接收函数将数据包上传给网络层协议进行处理。
2> 网络层和传输层通过inet_protos散列表进行衔接,表中每个表项指向一个inet_protocol结构队列,每个inet_protocol结构表示一个传输层协议,结构中定义有传输层协议号及其接收函数,网络层模块将根据网络层协议首部中标识的传输层协议号在inet_protos表中进行匹配查询,从而得到传输层协议对应的inet_protocol结构,调用该结构中注册的接收函数,将数据包上传给传输层进行处理。
inet_protocol 结构和 packet_type 结构的作用是类似的,都是作为两层之间的衔接只用,只不过 inet_protocol 结构用于传输层和网络层之间,而 packet_type 结构用于网络层和链路层之间。
综上所述,我们得到网络栈自下而上的数据包传输通道(接收),如下:
- 硬件监听物理传输介质,进行数据的接收,当完全接收一个数据包后,产生中断(这个过程完全由网络设备硬件负责);
- 中断产生后,系统调用驱动程序注册的中断处理程序进行数据接收,一般在接收过程中,我们完成数据从硬件缓冲区到内核缓冲区的复制,将其封装为内核特定结构(sk_buff结构),最后调用链路层提供的接口函数netif_rx(net/inet/dev.c),将数据包由驱动层传递到链路层(netif_rx是驱动程序调用,将接收到的数据包缓存与backlog队列中);
- 网络下半部分执行函数 net_bh,从backlog队列中取数据包,在进行完本层相关处理后,遍历ptype_base 指向的网络层协议队列,进行协议号的匹配,找到协议号匹配的packet_type 结构,调用结构中接收函数,完成数据包从链路层到网络层的传递。对于ARP协议,是调用 p_rcv函数,IP协议则是 ip_rcv函数;
- 假设数据包是用的是IP协议,那么从链路层传递到网络层时,将进入 ip_rcv 总入口函数,ip_rcv 完成本层处理后,以本层首部(IP首部)中标识的传输层协议号为散列值,对 inet_protos 散列表进行匹配查询,以寻找到核实的 inet_protocol 结构,进而调用结构中接收函数,完成数据包从网络层到传输层的传递。udp协议则调用 udp_rcv函数,tcp 则调用 tcp_rcv函数(前面有源码介绍),等;
- 假定数据包使用的是tcp传输层协议,那么此时将进入 tcp_rcv函数。所有使用tcp协议的套接字对应sock结构都被挂入tcp_prot全局变量表示的proto结构的 sock_array 数组(实际是个散列表)中,采用以本地端口号为索引的插入方式,所以当tcp_rcv函数接收到一个数据包,在完成必要的检查和处理后,其将以tcp协议首部中目的端口号为索引,在sock_array中得到正确的sock结构队列,在辅之以其他条件遍历该队列进行对应sock结构的查询,以得到匹配的sock结构,然后将数据包挂入该sock结构中的缓存队列中(sock结构中receive_queue字段指向),从而完成数据包的最终接收。
- 当用户需要读取数据时,其首先根据文件描述符得到对应的节点(inode结构表示),由节点得到对应的socket结构(作为inode结构中union类型字段存在),进而得到对应的sock结构,之后从sock结构的receive_queue指向的队列中取数据包,将数据包中的数据拷贝到用户缓冲区,从而完成数据的读取。
在如今Linux最新版本中,虽然网络栈实现代码作了很大的改变,但这个通道基本未变。
ok,前面介绍的倾向于上层协议向下层协议的衔接工作,即注重于数据包接收通道的创建工作,那么数据包发送通道是如何创建的:那就是下层向上层提供发送接口函数供上层直接进行调用。实际上这部分前面博文已经介绍过了(网络栈数据包发送)
这里再简单叙述一下:驱动程序通过hard_start_xmit函数指针向链路层提供发送函数,链路层提供dev_queue_xmit发送函数供网络层调用,而网络层提供ip_queue_xmit 函数供传输层调用。其中hard_start_xmit函数指针是根据不同的网络设备动态赋值。
另外,这些函数如dev_queue_xmit、ip_queue_xmit 并未采用任何向上层模块注册的方式工作,换句话说,它们都是作为上层模块的已知函数,当上层调用下层发送数据包函数时,直接调用对应函数即可(硬编码的含义)。
当应用层调用write函数开始,我们会先后经历sock_write、inet_write、tcp_write,只有到达tcp_write函数时,才进行数据的真正处理。
- tcp_write 函数完成数据的封装:将数据从用户缓冲区复制到内核缓冲区中,并封装在sk_buff结构中,根据网络的拥塞情况,此时可能出现两种情况:一不经过sock结构的write_queue队列直接被发送出去,二数据包暂时缓存在write_queue队列中,稍后发送,作为传输层协议而言,其将调用ip_queue_xmit函数将数据包发往下层–网络层进行处理;
- ip_queue_xmit 函数继续对数据帧进行完善后,调用dev_queue_xmit函数将数据包送往链路层进行处理,同时将数据包缓存与sock结构的send_head队列,目的在于tcp协议需要保证可靠性数据传输,一旦出现数据包的丢失,将启动数据包重传机制,重新发送send_head队列中数据包,另外,数据包在传递给ip_queue_xmit函数时,已经从write_queue队列中删除,所以不会出现一个数据包同时存在于这两个队列中。
这两个队列中的数据包的区别在于:write_queue队列中数据包是从用户层接收的新数据包,尚未进行发送,而send_head队列中数据包是tcp协议为了保证可靠性数据传输而缓存的已经发送出去的数据包。对于网络层而言,其将直接调用dev_queue_xmit函数进行发送; - dev_queue_xmit 函数完成其本层的处理后,调用发送设备device结构的hard_start_xmit指针指向的具体硬件数据发送函数,该函数首先将数据从内核缓冲区复制到网卡设备的硬件缓冲区,操作具体的硬件相关寄存器,由硬件完成最终的发送工作。
以上大致就是系统网络协议栈初始化过程及发送通道和接收通道的建立过程了。
我们最后再捋一捋发送通道和接收通道的区别:
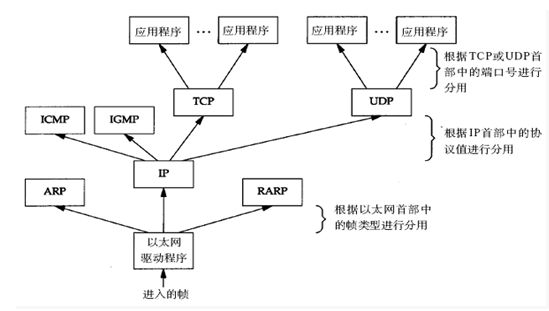
先看下图(显示的目的主机接收到数据包然后到达应用程序的过程,反过来就是从应用程序发送到目的主机物理层网卡设备的过程):
细看这个这个结构,是不是很像一棵倒立的树,如果正立这各结构,这就是成了一棵标准树的结构,每个树节点只有一个父节点,父节点可以有多个子节点。
但这跟网络栈传输数据包有啥关联呢?
ok,我们先看数据包的接收过程(物理层->应用层),从上图,以及结合前面的接收通道分析,由下往上,相当于一棵树从根节点出发到某个叶子节点,中间的某个节点可能有多个子节点,我们就得选择其中一个节点作为途径向下走,同理,协议栈也是这样。
看图,进入的帧经过以太网驱动程序,出现了三条通道,此时就需要证据帧首部中的类型选择走哪个通道(如IP),到了IP层,又出现了四条通道,此时又得根据IP首部中的传输层协议号进行选择,到了传输层就可通过端口号定位到对应应用程序了。所以由下往上有一个根据对应类型进行选择通道的过程;
反过来,数据包的发送则不需要这么麻烦了,因为任意一个子节点都只会有一个父节点,应用程序发送的数据就已经知道是属于哪个协议了,直接进入对应协议的传输层,然后层层往下,不需要一个通道选择的过程了。
较为牵强的白话表述,就是一棵树,从根节点到叶子节点有多条路径,但从叶子节点到根节点是唯一路径。
参考资料《Linux内核网络栈源代码情景分析》



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通