

Quagga Routing Suite
http://www.nongnu.org/quagga/docs/docs-info.html
Quagga
Quagga
Quagga is an advanced routing software packagethat provides a suite of TCP/IP based routing protocols. This is the Manualfor Quagga 1.2.0. Quagga is a fork of GNU Zebra.
Copyright © 1999-2005 Kunihiro Ishiguro, et al.
Permission is granted to make and distribute verbatim copies of thismanual provided the copyright notice and this permission notice arepreserved on all copies.
Permission is granted to copy and distribute modified versions of thismanual under the conditions for verbatim copying, provided that theentire resulting derived work is distributed under the terms of apermission notice identical to this one.
Permission is granted to copy and distribute translations of this manualinto another language, under the above conditions for modified versions,except that this permission notice may be stated in a translationapproved by Kunihiro Ishiguro.
| • Overview: | ||
| • Installation: | ||
| • Basic commands: | ||
| • Zebra: | ||
| • RIP: | ||
| • RIPng: | ||
| • OSPFv2: | ||
| • OSPFv3: | ||
| • ISIS: | ||
| • NHRP: | ||
| • BGP: | ||
| • Configuring Quagga as a Route Server: | ||
| • VTY shell: | ||
| • Filtering: | ||
| • Route Map: | ||
| • IPv6 Support: | ||
| • Kernel Interface: | ||
| • SNMP Support: | ||
| • Zebra Protocol: | ||
| • Packet Binary Dump Format: | ||
| • Command Index: | ||
| • VTY Key Index: | ||
| • Index: |
Table of Contents
- 1 Overview
- 2 Installation
- 3 Basic commands
- 4 Zebra
- 5 RIP
- 6 RIPng
- 7 OSPFv2
- 8 OSPFv3
- 9 ISIS
- 10 NHRP
- 11 BGP
- 11.1 Starting BGP
- 11.2 BGP router
- 11.3 BGP MED
- 11.4 BGP network
- 11.5 BGP Peer
- 11.6 BGP Peer Group
- 11.7 BGP Address Family
- 11.8 Autonomous System
- 11.9 BGP Communities Attribute
- 11.10 BGP Extended Communities Attribute
- 11.11 Displaying BGP Routes
- 11.12 Capability Negotiation
- 11.13 Route Reflector
- 11.14 Route Server
- 11.15 How to set up a 6-Bone connection
- 11.16 Dump BGP packets and table
- 11.17 BGP Configuration Examples
- 12 Configuring Quagga as a Route Server
- 13 VTY shell
- 14 Filtering
- 15 Route Map
- 16 IPv6 Support
- 17 Kernel Interface
- 18 SNMP Support
- Appendix A Zebra Protocol
- Appendix B Packet Binary Dump Format
- Command Index
- VTY Key Index
- Index
Next: Installation, Previous: Top, Up: Top [Contents][Index]
1 Overview
Quagga is a routing software package thatprovides TCP/IP based routing services with routing protocols support suchas RIPv1, RIPv2, RIPng, OSPFv2, OSPFv3, IS-IS, BGP-4, and BGP-4+ (see Supported RFCs). Quagga also supports special BGP Route Reflector and Route Serverbehavior. In addition to traditional IPv4 routing protocols, Quagga alsosupports IPv6 routing protocols. With SNMP daemon which supports SMUX and AgentXprotocol, Quagga provides routing protocol MIBs (see SNMP Support).
Quagga uses an advanced software architecture to provide you with a highquality, multi server routing engine. Quagga has an interactive userinterface for each routing protocol and supports common client commands. Due to this design, you can add new protocol daemons to Quagga easily. Youcan use Quagga library as your program’s client user interface.
Quagga is distributed under the GNU General Public License.
| • About Quagga: | Basic information about Quagga | |
| • System Architecture: | The Quagga system architecture | |
| • Supported Platforms: | Supported platforms and future plans | |
| • Supported RFCs: | Supported RFCs | |
| • How to get Quagga: | ||
| • Mailing List: | Mailing list information | |
| • Bug Reports: | Mail address for bug data |
Next: System Architecture, Up: Overview [Contents][Index]
1.1 About Quagga
Today, TCP/IP networks are covering all of the world. The Internet hasbeen deployed in many countries, companies, and to the home. When youconnect to the Internet your packet will pass many routers which have TCP/IProuting functionality.
A system with Quagga installed acts as a dedicated router. With Quagga,your machine exchanges routing information with other routers using routingprotocols. Quagga uses this information to update the kernel routing tableso that the right data goes to the right place. You can dynamically changethe configuration and you may view routing table information from the Quaggaterminal interface.
Adding to routing protocol support, Quagga can setup interface’s flags,interface’s address, static routes and so on. If you have a small network,or a stub network, or xDSL connection, configuring the Quagga routingsoftware is very easy. The only thing you have to do is to set up theinterfaces and put a few commands about static routes and/or default routes. If the network is rather large, or if the network structure changesfrequently, you will want to take advantage of Quagga’s dynamic routingprotocol support for protocols such as RIP, OSPF, IS-IS or BGP.
Traditionally, UNIX based router configuration is done byifconfig and
route commands. Status of routingtable is displayed by netstat utility. Almost of these commandswork only if the user has root privileges. Quagga has a different systemadministration method. There are two user modes in Quagga. One
is normalmode, the other is enable mode. Normal mode user can only view systemstatus, enable mode user can change system configuration. This UNIX accountindependent feature will be great help to the router administrator.
Currently, Quagga supports common unicast routing protocols, that is BGP,OSPF, RIP and IS-IS. Upcoming for MPLS support, an implementation of LDP iscurrently being prepared for merging. Implementations of BFD and PIM-SSM(IPv4) also exist, but are not actively being worked on.
The ultimate goal of the Quagga project is making a productive, quality, freeTCP/IP routing software package.
Next: Supported Platforms, Previous: About Quagga, Up: Overview [Contents][Index]
1.2 System Architecture
Traditional routing software is made as a one process program whichprovides all of the routing protocol functionalities. Quagga takes adifferent approach. It is made from a collection of several daemons thatwork together to build the routing table. There may be severalprotocol-specific routing daemons and zebra the kernel routing manager.
The ripd daemon handles the RIP protocol, whileospfd is a daemon which supports OSPF version 2.bgpd supports the BGP-4 protocol. For changing the kernelrouting table and for redistribution of routes between different
routingprotocols, there is a kernel routing table manager zebra daemon. It is easy to add a new routing protocol daemons to the entire routingsystem without affecting any other software. You need to run only theprotocol daemon associated with
routing protocols in use. Thus, user mayrun a specific daemon and send routing reports to a central routing console.
There is no need for these daemons to be running on the same machine. Youcan even run several same protocol daemons on the same machine. Thisarchitecture creates new possibilities for the routing system.
+----+ +----+ +-----+ +-----+
|bgpd| |ripd| |ospfd| |zebra|
+----+ +----+ +-----+ +-----+
|
+---------------------------|--+
| v |
| UNIX Kernel routing table |
| |
+------------------------------+
Quagga System Architecture
Multi-process architecture brings extensibility, modularity andmaintainability. At the same time it also brings many configuration filesand terminal interfaces. Each daemon has it’s own configuration file andterminal interface. When you configure a static
route, it must be done inzebra configuration file. When you configure BGP network it mustbe done in
bgpd configuration file. This can be a very annoyingthing. To resolve the problem, Quagga provides integrated user interfaceshell called
vtysh. vtysh connects to each daemon withUNIX domain socket and then works as a proxy for user input.
Quagga was planned to use multi-threaded mechanism when it runs with akernel that supports multi-threads. But at the moment, the thread librarywhich comes with
GNU/Linux or FreeBSD has some problems with runningreliable services such as routing software, so we don’t use threads at all. Instead we use the
select(2) system call for multiplexing theevents.
Next: Supported RFCs, Previous: System Architecture, Up: Overview [Contents][Index]
1.3 Supported Platforms
Currently Quagga supports GNU/Linux and BSD. Porting Quaggato other platforms is not too difficult as platform dependent code shouldmost be limited to the
zebra daemon. Protocol daemons are mostlyplatform independent. Please let us know when you find out Quagga runs on aplatform which is not listed below.
The list of officially supported platforms are listed below. Note thatQuagga may run correctly on other platforms, and may run with partialfunctionality on further platforms.
- GNU/Linux
- FreeBSD
- NetBSD
- OpenBSD
Versions of these platforms that are older than around 2 years from the pointof their original release (in case of GNU/Linux, this is since the kernel’srelease on kernel.org) may need some work. Similarly, the following platformsmay work with some effort:
- Solaris
- Mac OSX
Also note that, in particular regarding proprietary platforms, compilerand C library choice will affect Quagga. Only recent versions of thefollowing C compilers are well-tested:
- GNU’s GCC
- LLVM’s clang
- Intel’s ICC
Next: How to get Quagga, Previous: Supported Platforms, Up: Overview [Contents][Index]
1.4 Supported RFCs
Below is the list of currently supported RFC’s.
- RFC1058
-
Routing Information Protocol. C.L. Hedrick. Jun-01-1988.
- RF2082
-
RIP-2 MD5 Authentication. F. Baker, R. Atkinson. January 1997.
- RFC2453
-
RIP Version 2. G. Malkin. November 1998.
- RFC2080
-
RIPng for IPv6. G. Malkin, R. Minnear. January 1997.
- RFC2328
-
OSPF Version 2. J. Moy. April 1998.
- RFC2370
-
The OSPF Opaque LSA Option R. Coltun. July 1998.
- RFC3101
-
The OSPF Not-So-Stubby Area (NSSA) Option P. Murphy. January 2003.
- RFC2740
-
OSPF for IPv6. R. Coltun, D. Ferguson, J. Moy. December 1999.
- RFC1771
-
A Border Gateway Protocol 4 (BGP-4). Y. Rekhter & T. Li. March 1995.
- RFC1965
-
Autonomous System Confederations for BGP. P. Traina. June 1996.
- RFC1997
-
BGP Communities Attribute. R. Chandra, P. Traina & T. Li. August 1996.
- RFC2545
-
Use of BGP-4 Multiprotocol Extensions for IPv6 Inter-Domain Routing. P. Marques, F. Dupont. March 1999.
- RFC2796
-
BGP Route Reflection An alternative to full mesh IBGP. T. Bates & R. Chandrasekeran. June 1996.
- RFC2858
-
Multiprotocol Extensions for BGP-4. T. Bates, Y. Rekhter, R. Chandra, D. Katz. June 2000.
- RFC2842
-
Capabilities Advertisement with BGP-4. R. Chandra, J. Scudder. May 2000.
- RFC3137
-
OSPF Stub Router Advertisement, A. Retana, L. Nguyen, R. White, A. Zinin, D. McPherson. June 2001
When SNMP support is enabled, below RFC is also supported.
- RFC1227
-
SNMP MUX protocol and MIB. M.T. Rose. May-01-1991.
- RFC1657
-
Definitions of Managed Objects for the Fourth Version of theBorder Gateway Protocol (BGP-4) using SMIv2. S. Willis, J. Burruss,J. Chu, Editor. July 1994.
- RFC1724
-
RIP Version 2 MIB Extension. G. Malkin & F. Baker. November 1994.
- RFC1850
-
OSPF Version 2 Management Information Base. F. Baker, R. Coltun.November 1995.
- RFC2741
-
Agent Extensibility (AgentX) Protocol. M. Daniele, B. Wijnen. January 2000.
Next: Mailing List, Previous: Supported RFCs, Up: Overview [Contents][Index]
1.5 How to get Quagga
The official Quagga web-site is located at:
and contains further information, as well as links to additionalresources.
Quagga is a fork of GNU Zebra, whoseweb-site is located at:
Next: Bug Reports, Previous: How to get Quagga, Up: Overview [Contents][Index]
1.6 Mailing List
There is a mailing list for discussions about Quagga. If you have anycomments or suggestions to Quagga, please subscribe to:
http://lists.quagga.net/mailman/listinfo/quagga-users.
The Quagga site has further information onthe available mailing lists, see:
http://www.quagga.net/lists.php
Previous: Mailing List, Up: Overview [Contents][Index]
1.7 Bug Reports
If you think you have found a bug, please send a bug report to:
When you send a bug report, please be careful about the points below.
- Please note what kind of OS you are using. If you use the IPv6 stackplease note that as well.
- Please show us the results of
netstat -rnandifconfig -a.Information from zebra’s VTY commandshow ip routewill also behelpful. - Please send your configuration file with the report. If you specifyarguments to the configure script please note that too.
Bug reports are very important for us to improve the quality of Quagga.Quagga is still in the development stage, but please don’t hesitate tosend a bug report to http://bugzilla.quagga.net.
Next: Basic commands, Previous: Overview, Up: Top [Contents][Index]
2 Installation
There are three steps for installing the software: configuration,compilation, and installation.
The easiest way to get Quagga running is to issue the followingcommands:
% configure % make % make install
Next: Build the Software, Up: Installation [Contents][Index]
2.1 Configure the Software
Next: Least-Privilege support, Up: Configure the Software [Contents][Index]
2.1.1 The Configure script and its options
Quagga has an excellent configure script which automatically detects mosthost configurations. There are several additional configure options you canuse to turn off IPv6 support, to disable the compilation of specificdaemons, and to enable SNMP support.
- --disable-ipv6
-
Turn off IPv6 related features and daemons. Quagga configure scriptautomatically detects IPv6 stack. But sometimes you might want todisable IPv6 support of Quagga.
- --disable-zebra
-
Do not build zebra daemon.
- --disable-ripd
-
Do not build ripd.
- --disable-ripngd
-
Do not build ripngd.
- --disable-ospfd
-
Do not build ospfd.
- --disable-ospf6d
-
Do not build ospf6d.
- --disable-bgpd
-
Do not build bgpd.
- --disable-bgp-announce
-
Make
bgpdwhich does not make bgp announcements at all. Thisfeature is good for usingbgpdas a BGP announcement listener. - --enable-netlink
-
Force to enable GNU/Linux netlink interface. Quagga configurescript detects netlink interface by checking a header file. When the headerfile does not match to the current running kernel, configure script willnot turn on netlink support.
- --enable-snmp
-
Enable SNMP support. By default, SNMP support is disabled.
- --disable-opaque-lsa
-
Disable support for Opaque LSAs (RFC2370) in ospfd.
- --disable-ospfapi
-
Disable support for OSPF-API, an API to interface directly with ospfd.OSPF-API is enabled if –enable-opaque-lsa is set.
- --disable-ospfclient
-
Disable building of the example OSPF-API client.
- --disable-ospf-te
-
Disable support for OSPF Traffic Engineering Extension (RFC3630) thisrequires support for Opaque LSAs.
- --disable-ospf-ri
-
Disable support for OSPF Router Information (RFC4970 & RFC5088) thisrequires support for Opaque LSAs and Traffic Engineering.
- --enable-isisd
-
Build isisd.
- --enable-isis-topology
-
Enable IS-IS topology generator.
- --enable-isis-te
-
Enable Traffic Engineering Extension for ISIS (RFC5305)
- --enable-multipath=ARG
-
Enable support for Equal Cost Multipath. ARG is the maximum numberof ECMP paths to allow, set to 0 to allow unlimited number of paths.
- --disable-rtadv
-
Disable support IPV6 router advertisement in zebra.
- --enable-gcc-rdynamic
-
Pass the
-rdynamicoption to the linker driver. This is in mostcases neccessary for getting usable backtraces. This option defaults to onif the compiler is detected as gcc, but giving an explicit enable/disable issuggested. - --enable-backtrace
-
Controls backtrace support for the crash handlers. This is autodetected bydefault. Using the switch will enforce the requested behaviour, failing withan error if support is requested but not available. On BSD systems, thisneeds libexecinfo, while on glibc support for this is part of libc itself.
You may specify any combination of the above options to the configurescript. By default, the executables are placed in /usr/local/sbin and the configuration files in /usr/local/etc. The /usr/local/installation prefix and other directories may be changed using the following options to the configuration script.
- --prefix=prefix
-
Install architecture-independent files in prefix [/usr/local].
- --sysconfdir=dir
-
Look for configuration files in dir [prefix/etc]. Notethat sample configuration files will be installed here.
- --localstatedir=dir
-
Configure zebra to use dir for local state files, suchas pid files and unix sockets.
% ./configure --disable-ipv6
This command will configure zebra and the routing daemons.
Next: Linux notes, Previous: The Configure script and its options, Up: Configure the Software [Contents][Index]
2.1.2 Least-Privilege support
Additionally, you may configure zebra to drop its elevated privilegesshortly after startup and switch to another user. The configure script willautomatically try to configure this support. There are three configureoptions to control the behaviour of Quagga daemons.
- --enable-user=user
-
Switch to user ARG shortly after startup, and run as user ARGin normal operation.
- --enable-group=group
-
Switch real and effective group to group shortly afterstartup.
- --enable-vty-group=group
-
Create Unix Vty sockets (for use with vtysh) with group owndership set togroup. This allows one to create a seperate group which isrestricted to accessing only the Vty sockets, hence allowing one todelegate this group to individual users, or to run vtysh setgid tothis group.
The default user and group which will be configured is ’quagga’ if no useror group is specified. Note that this user or group requires write access tothe local state directory (see –localstatedir) and requires at least readaccess, and write access if you wish to allow daemons to write out theirconfiguration, to the configuration directory (see –sysconfdir).
On systems which have the ’libcap’ capabilities manipulation library(currently only linux), the quagga system will retain only minimalcapabilities required, further it will only raise these capabilities forbrief periods. On systems without libcap, quagga will run as the userspecified and only raise its uid back to uid 0 for brief periods.
Previous: Least-Privilege support, Up: Configure the Software [Contents][Index]
2.1.3 Linux Notes
There are several options available only to GNU/Linux systems:1. Ifyou use GNU/Linux, make sure that the current kernel configuration iswhat you want. Quagga will run with any kernel configuration but somerecommendations do exist.
- CONFIG_NETLINK
-
Kernel/User netlink socket. This is a brand new feature which enables anadvanced interface between the Linux kernel and zebra (see Kernel Interface).
- CONFIG_RTNETLINK
-
Routing messages.This makes it possible to receive netlink routing messages. If youspecify this option,
zebracan detect routing informationupdates directly from the kernel (see Kernel Interface). - CONFIG_IP_MULTICAST
-
IP: multicasting. This option should be specified when you use
ripd(see RIP) orospfd(see OSPFv2) because these protocols use multicast.
IPv6 support has been added in GNU/Linux kernel version 2.2. If youtry to use the Quagga IPv6 feature on a GNU/Linux kernel, pleasemake sure the following libraries have been installed. Please note thatthese libraries will not be needed when you uses GNU C library 2.1or upper.
inet6-apps-
The
inet6-appspackage includes basic IPv6 related libraries suchasinet_ntopandinet_pton. Some basic IPv6 programs suchasping,ftp, andinetdare alsoincluded. Theinet-appscan be found atftp://ftp.inner.net/pub/ipv6/. net-tools-
The
net-toolspackage provides an IPv6 enabled interface androuting utility. It containsifconfig,route,netstat, and other tools.net-toolsmay be found athttp://www.tazenda.demon.co.uk/phil/net-tools/.
Next: Install the Software, Previous: Configure the Software, Up: Installation [Contents][Index]
2.2 Build the Software
After configuring the software, you will need to compile it for yoursystem. Simply issue the command
make in the root of the sourcedirectory and the software will be compiled. If you have *any* problemsat this stage, be certain to send a bug report See
Bug Reports.
% ./configure . . . ./configure output . . . % make
Previous: Build the Software, Up: Installation [Contents][Index]
2.3 Install the Software
Installing the software to your system consists of copying the compiledprograms and supporting files to a standard location. After theinstallation process has completed, these files have been copiedfrom your work directory to /usr/local/bin, and /usr/local/etc.
To install the Quagga suite, issue the following command at your shellprompt:
make install.
% % make install %
Quagga daemons have their own terminal interface or VTY. Afterinstallation, you have to setup each beast’s port number to connect tothem. Please add the following entries to /etc/services.
zebrasrv 2600/tcp # zebra service zebra 2601/tcp # zebra vty ripd 2602/tcp # RIPd vty ripngd 2603/tcp # RIPngd vty ospfd 2604/tcp # OSPFd vty bgpd 2605/tcp # BGPd vty ospf6d 2606/tcp # OSPF6d vty ospfapi 2607/tcp # ospfapi isisd 2608/tcp # ISISd vty pimd 2611/tcp # PIMd vty nhrpd 2612/tcp # nhrpd vty
If you use a FreeBSD newer than 2.2.8, the above entries are alreadyadded to /etc/services so there is no need to add it. If youspecify a port number when starting the daemon, these entries may not beneeded.
You may need to make changes to the config files in/etc/quagga/*.conf. See Config Commands.
Next: Zebra, Previous: Installation, Up: Top [Contents][Index]
3 Basic commands
There are five routing daemons in use, and there is one manager daemon.These daemons may be located on separate machines from the managerdaemon. Each of these daemons will listen on a particular port forincoming VTY connections. The routing daemons are:
ripd,ripngd,ospfd,ospf6d,bgpdzebra
The following sections discuss commands common to all the routingdaemons.
| • Config Commands: | Commands used in config files | |
| • Terminal Mode Commands: | Common commands used in a VTY | |
| • Common Invocation Options: | Starting the daemons | |
| • Virtual Terminal Interfaces: | Interacting with the daemons |
Next: Terminal Mode Commands, Up: Basic commands [Contents][Index]
3.1 Config Commands
| • Basic Config Commands: | Some of the generic config commands | |
| • Sample Config File: | An example config file |
In a config file, you can write the debugging options, a vty’s password,routing daemon configurations, a log file name, and so forth. Thisinformation forms the initial command set for a routing beast as it isstarting.
Config files are generally found in:
- /etc/quagga/*.conf
Each of the daemons has its ownconfig file. For example, zebra’s default config file name is:
- /etc/quagga/zebra.conf
The daemon name plus .conf is the default config file name. Youcan specify a config file using the -f or --config-fileoptions when starting the daemon.
Next: Sample Config File, Up: Config Commands [Contents][Index]
3.1.1 Basic Config Commands
- Command: password password
-
Set password for vty interface. If there is no password, a vty won’taccept connections.
- Command: log trap level
- Command: no log trap
-
These commands are deprecated and are present only for historical compatibility.The log trap command sets the current logging level for all enabledlogging destinations, and it sets the default for all future logging commandsthat do not specify a level. The normal defaultlogging level is debugging. The
noform of the command resetsthe default level for future logging commands to debugging, but it doesnot change the logging level of existing logging destinations.
- Command: log stdout
- Command: log stdout level
- Command: no log stdout
-
Enable logging output to stdout. If the optional second argument specifying thelogging level is not present, the default logging level (typically debugging,but can be changed using the deprecated
log trapcommand) will be used.Thenoform of the command disables logging to stdout.Thelevelargument must have one of these values: emergencies, alerts, critical, errors, warnings, notifications, informational, or debugging. Note that the existing code logs its most important messageswith severityerrors.
- Command: log file filename
- Command: log file filename level
- Command: no log file
-
If you want to log into a file, please specify
filenameasin this example:log file /var/log/quagga/bgpd.log informational
If the optional second argument specifying thelogging level is not present, the default logging level (typically debugging,but can be changed using the deprecated
log trapcommand) will be used.Thenoform of the command disables logging to a file.Note: if you do not configure any file logging, and a daemon crashes dueto a signal or an assertion failure, it will attempt to save the crashinformation in a file named /var/tmp/quagga.<daemon name>.crashlog.For security reasons, this will not happen if the file exists already, soit is important to delete the file after reporting the crash information.
- Command: log syslog
- Command: log syslog level
- Command: no log syslog
-
Enable logging output to syslog.If the optional second argument specifying thelogging level is not present, the default logging level (typically debugging,but can be changed using the deprecated
log trapcommand) will be used.Thenoform of the command disables logging to syslog.
- Command: log monitor
- Command: log monitor level
- Command: no log monitor
-
Enable logging output to vty terminals that have enabled loggingusing the
terminal monitorcommand.By default, monitor logging is enabled at the debugging level, but thiscommand (or the deprecatedlog trapcommand) can be used to change the monitor logging level.If the optional second argument specifying thelogging level is not present, the default logging level (typically debugging,but can be changed using the deprecatedlog trapcommand) will be used.Thenoform of the command disables logging to terminal monitors.
- Command: log facility facility
- Command: no log facility
-
This command changes the facility used in syslog messages. The defaultfacility is
daemon. Thenoform of the command resetsthe facility to the defaultdaemonfacility.
- Command: log record-priority
- Command: no log record-priority
-
To include the severity in all messages logged to a file, to stdout, or toa terminal monitor (i.e. anything except syslog),use the
log record-priorityglobal configuration command.To disable this option, use thenoform of the command. By default,the severity level is not included in logged messages. Note: someversions of syslogd (including Solaris) can be configured to includethe facility and level in the messages emitted.
- Command: log timestamp precision <0-6>
- Command: no log timestamp precision
-
This command sets the precision of log message timestamps to thegiven number of digits after the decimal point. Currently,the value must be in the range 0 to 6 (i.e. the maximum precisionis microseconds).To restore the default behavior (1-second accuracy), use the
noform of the command, or set the precision explicitly to 0.log timestamp precision 3
In this example, the precision is set to provide timestamps withmillisecond accuracy.
- Command: log commands
-
This command enables the logging of all commands typed by a user toall enabled log destinations. The note that logging includes fullcommand lines, including passwords. Once set, command logging can onlybe turned off by restarting the daemon.
- Command: service terminal-length <0-512>
-
Set system wide line configuration. This configuration command appliesto all VTY interfaces.
- Line Command: exec-timeout minute
- Line Command: exec-timeout minute second
-
Set VTY connection timeout value. When only one argument is specifiedit is used for timeout value in minutes. Optional second argument isused for timeout value in seconds. Default timeout value is 10 minutes.When timeout value is zero, it means no timeout.
- Line Command: no exec-timeout
-
Do not perform timeout at all. This command is as same as
exec-timeout 0 0.
Previous: Basic Config Commands, Up: Config Commands [Contents][Index]
3.1.2 Sample Config File
Below is a sample configuration file for the zebra daemon.
! ! Zebra configuration file ! hostname Router password zebra enable password zebra ! log stdout ! !
’!’ and ’#’ are comment characters. If the first character of the wordis one of the comment characters then from the rest of the line forwardwill be ignored as a comment.
password zebra!password
If a comment character is not the first character of the word, it’s anormal character. So in the above example ’!’ will not be regarded as acomment and the password is set to ’zebra!password’.
Next: Common Invocation Options, Previous: Config Commands, Up: Basic commands [Contents][Index]
3.2 Terminal Mode Commands
- Command: configure terminal
-
Change to configuration mode. This command is the first step toconfiguration.
- Command: terminal length <0-512>
-
Set terminal display length to <0-512>. If length is 0, nodisplay control is performed.
- Command: show logging
-
Shows the current configuration of the logging system. This includesthe status of all logging destinations.
- Command: logmsg level message
-
Send a message to all logging destinations that are enabled for messagesof the given severity.
Next: Virtual Terminal Interfaces, Previous: Terminal Mode Commands, Up: Basic commands [Contents][Index]
3.3 Common Invocation Options
These options apply to all Quagga daemons.
- ‘-d’
- ‘--daemon’
-
Runs in daemon mode.
- ‘-f file’
- ‘--config_file=file’
-
Set configuration file name.
- ‘-h’
- ‘--help’
-
Display this help and exit.
- ‘-i file’
- ‘--pid_file=file’
-
Upon startup the process identifier of the daemon is written to a file,typically in /var/run. This file can be used by the init systemto implement commands such as
…/init.d/zebra status,…/init.d/zebra restartor…/init.d/zebrastop.The file name is an run-time option rather than a configure-time optionso that multiple routing daemons can be run simultaneously. This isuseful when using Quagga to implement a routing looking glass. Onemachine can be used to collect differing routing views from differingpoints in the network.
- ‘-A address’
- ‘--vty_addr=address’
-
Set the VTY local address to bind to. If set, the VTY socket will onlybe bound to this address.
- ‘-P port’
- ‘--vty_port=port’
-
Set the VTY TCP port number. If set to 0 then the TCP VTY sockets will notbe opened.
- ‘-u user’
- ‘--vty_addr=user’
-
Set the user and group to run as.
- ‘-v’
- ‘--version’
-
Print program version.
Previous: Common Invocation Options, Up: Basic commands [Contents][Index]
3.4 Virtual Terminal Interfaces
VTY – Virtual Terminal [aka TeletYpe] Interface is a command lineinterface (CLI) for user interaction with the routing daemon.
| • VTY Overview: | Basics about VTYs | |
| • VTY Modes: | View, Enable, and Other VTY modes | |
| • VTY CLI Commands: | Commands for movement, edition, and management |
Next: VTY Modes, Up: Virtual Terminal Interfaces [Contents][Index]
3.4.1 VTY Overview
VTY stands for Virtual TeletYpe interface. It means you can connect tothe daemon via the telnet protocol.
To enable a VTY interface, you have to setup a VTY password. If thereis no VTY password, one cannot connect to the VTY interface at all.
% telnet localhost 2601 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. Hello, this is Quagga (version 1.2.0) Copyright © 1999-2005 Kunihiro Ishiguro, et al. User Access Verification Password: XXXXX Router> ? enable Turn on privileged commands exit Exit current mode and down to previous mode help Description of the interactive help system list Print command list show Show running system information who Display who is on a vty Router> enable Password: XXXXX Router# configure terminal Router(config)# interface eth0 Router(config-if)# ip address 10.0.0.1/8 Router(config-if)# ^Z Router#
’?’ is very useful for looking up commands.
Next: VTY CLI Commands, Previous: VTY Overview, Up: Virtual Terminal Interfaces [Contents][Index]
3.4.2 VTY Modes
There are three basic VTY modes:
| • VTY View Mode: | Mode for read-only interaction | |
| • VTY Enable Mode: | Mode for read-write interaction | |
| • VTY Other Modes: | Special modes (tftp, etc) |
There are commands that may be restricted to specific VTY modes.
Next: VTY Enable Mode, Up: VTY Modes [Contents][Index]
3.4.2.1 VTY View Mode
This mode is for read-only access to the CLI. One may exit the mode byleaving the system, or by entering
enable mode.
Next: VTY Other Modes, Previous: VTY View Mode, Up: VTY Modes [Contents][Index]
3.4.2.2 VTY Enable Mode
This mode is for read-write access to the CLI. One may exit the mode byleaving the system, or by escaping to view mode.
Previous: VTY Enable Mode, Up: VTY Modes [Contents][Index]
3.4.2.3 VTY Other Modes
This page is for describing other modes.
Previous: VTY Modes, Up: Virtual Terminal Interfaces [Contents][Index]
3.4.3 VTY CLI Commands
Commands that you may use at the command-line are described in the followingthree subsubsections.
| • CLI Movement Commands: | Commands for moving the cursor about | |
| • CLI Editing Commands: | Commands for changing text | |
| • CLI Advanced Commands: | Other commands, session management and so on |
Next: CLI Editing Commands, Up: VTY CLI Commands [Contents][Index]
3.4.3.1 CLI Movement Commands
These commands are used for moving the CLI cursor. The C charactermeans press the Control Key.
- C-f
- RIGHT
-
Move forward one character.
- C-b
- LEFT
-
Move backward one character.
- M-f
-
Move forward one word.
- M-b
-
Move backward one word.
- C-a
-
Move to the beginning of the line.
- C-e
-
Move to the end of the line.
Next: CLI Advanced Commands, Previous: CLI Movement Commands, Up: VTY CLI Commands [Contents][Index]
3.4.3.2 CLI Editing Commands
These commands are used for editing text on a line. The Ccharacter means press the Control Key.
- C-h
- DEL
-
Delete the character before point.
- C-d
-
Delete the character after point.
- M-d
-
Forward kill word.
- C-w
-
Backward kill word.
- C-k
-
Kill to the end of the line.
- C-u
-
Kill line from the beginning, erasing input.
- C-t
-
Transpose character.
- C-v
-
Interpret following character literally. Do not treat it specially.This can be used to, e.g., type in a literal ? rather than dohelp completion.
Previous: CLI Editing Commands, Up: VTY CLI Commands [Contents][Index]
3.4.3.3 CLI Advanced Commands
There are several additional CLI commands for command line completions,insta-help, and VTY session management.
- C-c
-
Interrupt current input and moves to the next line.
- C-z
-
End current configuration session and move to top node.
- C-n
- DOWN
-
Move down to next line in the history buffer.
- C-p
- UP
-
Move up to previous line in the history buffer.
- TAB
-
Use command line completion by typing TAB.
- ?
-
You can use command line help by typing
helpat the beginning ofthe line. Typing ? at any point in the line will show possiblecompletions.To enter an actual ? character rather show completions, e.g. toenter into a regexp, use C-v ?.
Next: RIP, Previous: Basic commands, Up: Top [Contents][Index]
4 Zebra
zebra is an IP routing manager. It provides kernel routingtable updates, interface lookups, and redistribution of routes betweendifferent routing protocols.
| • Invoking zebra: | Running the program | |
| • Interface Commands: | Commands for zebra interfaces | |
| • Static Route Commands: | Commands for adding static routes | |
| • Multicast RIB Commands: | Commands for controlling MRIB behavior | |
| • zebra Route Filtering: | Commands for zebra route filtering | |
| • zebra FIB push interface: | Interface to optional FPM component | |
| • zebra Terminal Mode Commands: | Commands for zebra’s VTY |
Next: Interface Commands, Up: Zebra [Contents][Index]
4.1 Invoking zebra
Besides the common invocation options (see
Common Invocation Options), thezebra specific invocation options are listed below.
- ‘-b’
- ‘--batch’
-
Runs in batch mode.
zebraparses configuration file and terminatesimmediately. - ‘-k’
- ‘--keep_kernel’
-
When zebra starts up, don’t delete old self inserted routes.
- ‘-r’
- ‘--retain’
-
When program terminates, retain routes added by zebra.
Next: Static Route Commands, Previous: Invoking zebra, Up: Zebra [Contents][Index]
4.2 Interface Commands
Next: Link Parameters Commands, Up: Interface Commands [Contents][Index]
4.2.1 Standard Commands
- Interface Command: ip address address/prefix
- Interface Command: ipv6 address address/prefix
- Interface Command: no ip address address/prefix
- Interface Command: no ipv6 address address/prefix
-
Set the IPv4 or IPv6 address/prefix for the interface.
- Interface Command: ip address address/prefix secondary
- Interface Command: no ip address address/prefix secondary
-
Set the secondary flag for this address. This causes ospfd to not treat theaddress as a distinct subnet.
- Interface Command: multicast
- Interface Command: no multicast
-
Enable or disables multicast flag for the interface.
- Interface Command: bandwidth <1-10000000>
- Interface Command: no bandwidth <1-10000000>
-
Set bandwidth value of the interface in kilobits/sec. This is forcalculating OSPF cost. This command does not affect the actual deviceconfiguration.
- Interface Command: link-detect
- Interface Command: no link-detect
-
Enable/disable link-detect on platforms which support this. Currentlyonly Linux and Solaris, and only where network interface drivers support reportinglink-state via the IFF_RUNNING flag.
Previous: Standard Commands, Up: Interface Commands [Contents][Index]
4.2.2 Link Parameters Commands
- Interface Command: link-params
- Interface Command: no link-param
-
Enter into the link parameters sub node. At least ’enable’ must be set to activate the link parameters,and consequently Traffic Engineering on this interface. MPLS-TE must be enable at the OSPF (OSPF Traffic Engineering)or ISIS (ISIS Traffic Engineering) router level in complement to this.Disable link parameters for this interface.
Under link parameter statement, the following commands set the different TE values:
- link-params: metric <0-4294967295>
- link-params: max-bw bandwidth
- link-params: max-rsv-bw bandwidth
- link-params: unrsv-bw <0-7> bandwidth
- link-params: admin-grp bandwidth
-
These commands specifies the Traffic Engineering parameters of the interface in conformity to RFC3630 (OSPF)or RFC5305 (ISIS).There are respectively the TE Metric (different from the OSPF or ISIS metric), Maximum Bandwidth (interface speedby default), Maximum Reservable Bandwidth, Unreserved Bandwidth for each 0-7 priority and Admin Group (ISIS) orResource Class/Color (OSPF).
Note that bandwidth are specified in IEEE floating point format and express in Bytes/second.
- link-param: delay <0-16777215> [min <0-16777215> | max <0-16777215>]
- link-param: delay-variation <0-16777215>
- link-param: packet-loss percentage
- link-param: res-bw bandwidth
- link-param: ava-bw bandwidth
- link-param: use-bw bandwidth
-
These command specifies additionnal Traffic Engineering parameters of the interface in conformity todraft-ietf-ospf-te-metrics-extension-05.txt and draft-ietf-isis-te-metrics-extension-03.txt. There arerespectively the delay, jitter, loss, available bandwidth, reservable bandwidth and utilized bandwidth.
Note that bandwidth are specified in IEEE floating point format and express in Bytes/second.Delays and delay variation are express in micro-second (µs). Loss is specified in percentage rangingfrom 0 to 50.331642% by step of 0.000003.
- link-param: neighbor <A.B.C.D> as <0-65535>
- link-param: no neighbor
-
Specifies the remote ASBR IP address and Autonomous System (AS) number for InterASv2 link in OSPF (RFC5392).Note that this option is not yet supported for ISIS (RFC5316).
Next: Multicast RIB Commands, Previous: Interface Commands, Up: Zebra [Contents][Index]
4.3 Static Route Commands
Static routing is a very fundamental feature of routing technology. Itdefines static prefix and gateway.
- Command: ip route network gateway
-
network is destination prefix with format of A.B.C.D/M.gateway is gateway for the prefix. When gateway isA.B.C.D format. It is taken as a IPv4 address gateway. Otherwise itis treated as an interface name. If the interface name is null0 thenzebra installs a blackhole route.
ip route 10.0.0.0/8 10.0.0.2 ip route 10.0.0.0/8 ppp0 ip route 10.0.0.0/8 null0
First example defines 10.0.0.0/8 static route with gateway 10.0.0.2.Second one defines the same prefix but with gateway to interface ppp0. Thethird install a blackhole route.
- Command: ip route network netmask gateway
-
This is alternate version of above command. When network isA.B.C.D format, user must define netmask value with A.B.C.Dformat. gateway is same option as above command
ip route 10.0.0.0 255.0.0.0 10.0.0.2 ip route 10.0.0.0 255.0.0.0 ppp0 ip route 10.0.0.0 255.0.0.0 null0
These statements are equivalent to those in the previous example.
Multiple nexthop static route
ip route 10.0.0.1/32 10.0.0.2 ip route 10.0.0.1/32 10.0.0.3 ip route 10.0.0.1/32 eth0
If there is no route to 10.0.0.2 and 10.0.0.3, and interface eth0is reachable, then the last route is installed into the kernel.
If zebra has been compiled with multipath support, and both 10.0.0.2 and10.0.0.3 are reachable, zebra will install a multipath route via bothnexthops, if the platform supports this.
zebra> show ip route
S> 10.0.0.1/32 [1/0] via 10.0.0.2 inactive
via 10.0.0.3 inactive
* is directly connected, eth0
ip route 10.0.0.0/8 10.0.0.2 ip route 10.0.0.0/8 10.0.0.3 ip route 10.0.0.0/8 null0 255
This will install a multihop route via the specified next-hops if they arereachable, as well as a high-metric blackhole route, which can be useful toprevent traffic destined for a prefix to match less-specific routes (egdefault) should the specified gateways not be reachable. Eg:
zebra> show ip route 10.0.0.0/8
Routing entry for 10.0.0.0/8
Known via "static", distance 1, metric 0
10.0.0.2 inactive
10.0.0.3 inactive
Routing entry for 10.0.0.0/8
Known via "static", distance 255, metric 0
directly connected, Null0
- Command: ipv6 route network gateway
- Command: ipv6 route network gateway distance
-
These behave similarly to their ipv4 counterparts.
- Command: table tableno
-
Select the primary kernel routing table to be used. This only worksfor kernels supporting multiple routing tables (like GNU/Linux 2.2.xand later). After setting tableno with this command,static routes defined after this are added to the specified table.
Next: zebra Route Filtering, Previous: Static Route Commands, Up: Zebra [Contents][Index]
4.4 Multicast RIB Commands
The Multicast RIB provides a separate table of unicast destinations whichis used for Multicast Reverse Path Forwarding decisions. It is used witha multicast source’s IP address, hence contains not multicast groupaddresses but unicast addresses.
This table is fully separate from the default unicast table. However,RPF lookup can include the unicast table.
WARNING: RPF lookup results are non-responsive in this version of Quagga,i.e. multicast routing does not actively react to changes in underlyingunicast topology!
- Command: ip multicast rpf-lookup-mode mode
- Command: no ip multicast rpf-lookup-mode [mode]
-
mode sets the method used to perform RPF lookups. Supported modes:
- ‘urib-only’
-
Performs the lookup on the Unicast RIB. The Multicast RIB is never used.
- ‘mrib-only’
-
Performs the lookup on the Multicast RIB. The Unicast RIB is never used.
- ‘mrib-then-urib’
-
Tries to perform the lookup on the Multicast RIB. If any route is found,that route is used. Otherwise, the Unicast RIB is tried.
- ‘lower-distance’
-
Performs a lookup on the Multicast RIB and Unicast RIB each. The resultwith the lower administrative distance is used; if they’re equal, theMulticast RIB takes precedence.
- ‘longer-prefix’
-
Performs a lookup on the Multicast RIB and Unicast RIB each. The resultwith the longer prefix length is used; if they’re equal, theMulticast RIB takes precedence.
The
mrib-then-uribsetting is the default behavior if nothing isconfigured. If this is the desired behavior, it should be explicitlyconfigured to make the configuration immune against possible changes inwhat the default behavior is.WARNING: Unreachable routes do not receive special treatment and do notcause fallback to a second lookup.
- Command: show ip rpf addr
-
Performs a Multicast RPF lookup, as configured with
ip multicast rpf-lookup-mode mode. addr specifiesthe multicast source address to look up.> show ip rpf 192.0.2.1 Routing entry for 192.0.2.0/24 using Unicast RIB Known via "kernel", distance 0, metric 0, best * 198.51.100.1, via eth0
Indicates that a multicast source lookup for 192.0.2.1 would use anUnicast RIB entry for 192.0.2.0/24 with a gateway of 198.51.100.1.
- Command: show ip rpf
-
Prints the entire Multicast RIB. Note that this is independent of theconfigured RPF lookup mode, the Multicast RIB may be printed yet notused at all.
- Command: ip mroute prefix nexthop [distance]
- Command: no ip mroute prefix nexthop [distance]
-
Adds a static route entry to the Multicast RIB. This performs exactly asthe
ip routecommand, except that it inserts the route in theMulticast RIB instead of the Unicast RIB.
Next: zebra FIB push interface, Previous: Multicast RIB Commands, Up: Zebra [Contents][Index]
4.5 zebra Route Filtering
Zebra supports prefix-list and route-map to matchroutes received from other quagga components. Thepermit/deny facilities provided by these commandscan be used to filter which routes zebra will install in
the kernel.
- Command: ip protocol protocol route-map routemap
-
Apply a route-map filter to routes for the specified protocol. protocolcan be any or one ofsystem,kernel,connected,static,rip,ripng,ospf,ospf6,isis,bgp,hsls.
- Route Map: set src address
-
Within a route-map, set the preferred source address for matching routeswhen installing in the kernel.
The following creates a prefix-list that matches all addresses, a route-mapthat sets the preferred source address, and applies the route-map to allrip routes.
ip prefix-list ANY permit 0.0.0.0/0 le 32
route-map RM1 permit 10
match ip address prefix-list ANY
set src 10.0.0.1
ip protocol rip route-map RM1
Next: zebra Terminal Mode Commands, Previous: zebra Route Filtering, Up: Zebra [Contents][Index]
4.6 zebra FIB push interface
Zebra supports a ’FIB push’ interface that allows an externalcomponent to learn the forwarding information computed by the Quaggarouting suite.
In Quagga, the Routing Information Base (RIB) resides insidezebra. Routing protocols communicate their best routes to zebra, andzebra computes the best route across protocols for each prefix. Thislatter information makes up the Forwarding Information Base(FIB).
Zebra feeds the FIB to the kernel, which allows the IP stack inthe kernel to forward packets according to the routes computed byQuagga. The kernel FIB is updated in an OS-specific way. For example,the
netlink interface is used on Linux, and route sockets areused on FreeBSD.
The FIB push interface aims to provide a cross-platform mechanism tosupport scenarios where the router has a forwarding path that isdistinct from the kernel, commonly a hardware-based fast path. Inthese cases, the FIB needs to be maintained reliably in the fast pathas well. We refer to the component that programs the forwarding plane(directly or indirectly) as the Forwarding Plane Manager or FPM.
The FIB push interface comprises of a TCP connection between zebra andthe FPM. The connection is initiated by zebra – that is, the FPM actsas the TCP server.
The relevant zebra code kicks in when zebra is configured with the--enable-fpm flag. Zebra periodically attempts to connect tothe well-known FPM port. Once the connection is up, zebra startssending messages containing routes over the socket
to the FPM. Zebrasends a complete copy of the forwarding table to the FPM, includingroutes that it may have picked up from the kernel. The existinginteraction of zebra with the kernel remains unchanged – that is, thekernel continues to receive FIB updates
as before.
The encapsulation header for the messages exchanged with the FPM isdefined by the file fpm/fpm.h in the quagga tree. The routesthemselves are encoded in netlink or protobuf format, with netlinkbeing the default.
Protobuf is one of a number of new serialization formats wherein themessage schema is expressed in a purpose-built language. Code forencoding/decoding to/from the wire format is generated from theschema. Protobuf messages can be extended easily while maintainingbackward-compatibility with older code. Protobuf has the followingadvantages over netlink:
- Code for serialization/deserialization is generatedautomatically. This reduces the likelihood of bugs, allows third-partyprograms to be integrated quickly, and makes it easy to add fields.
- The message format is not tied to an OS (Linux), and can be evolvedindependently.
As mentioned before, zebra encodes routes sent to the FPM in netlinkformat by default. The format can be controlled via the--fpm_format command-line option to zebra, which currentlytakes the values
netlink and protobuf.
The zebra FPM interface uses replace semantics. That is, if a ’routeadd’ message for a prefix is followed by another ’route add’ message,the information in the second message is complete by itself, andreplaces the information sent in the first message.
If the connection to the FPM goes down for some reason, zebra sendsthe FPM a complete copy of the forwarding table(s) when it reconnects.
Previous: zebra FIB push interface, Up: Zebra [Contents][Index]
4.7 zebra Terminal Mode Commands
- Command: show ip route
-
Display current routes which zebra holds in its database.
Router# show ip route Codes: K - kernel route, C - connected, S - static, R - RIP, B - BGP * - FIB route. K* 0.0.0.0/0 203.181.89.241 S 0.0.0.0/0 203.181.89.1 C* 127.0.0.0/8 lo C* 203.181.89.240/28 eth0
- Command: show ipforward
-
Display whether the host’s IP forwarding function is enabled or not.Almost any UNIX kernel can be configured with IP forwarding disabled.If so, the box can’t work as a router.
- Command: show zebra fpm stats
-
Display statistics related to the zebra code that interacts with theoptional Forwarding Plane Manager (FPM) component.
- Command: clear zebra fpm stats
-
Reset statistics related to the zebra code that interacts with theoptional Forwarding Plane Manager (FPM) component.
5 RIP
RIP – Routing Information Protocol is widely deployed interior gatewayprotocol. RIP was developed in the 1970s at Xerox Labs as part of theXNS routing protocol. RIP is a distance-vector protocol and isbased on the Bellman-Ford algorithms. As a distance-vectorprotocol, RIP router send updates to its neighbors periodically, thusallowing the convergence to a known topology. In each update, thedistance to any given network will be broadcasted to its neighboringrouter.
ripd supports RIP version 2 as described in RFC2453 and RIPversion 1 as described in RFC1058.
Next: RIP Configuration, Up: RIP [Contents][Index]
5.1 Starting and Stopping ripd
The default configuration file name of ripd’s isripd.conf. When invocation
ripd searches directory/etc/quagga. If ripd.conf is not there nextsearch current directory.
RIP uses UDP port 520 to send and receive RIP packets. So the user must havethe capability to bind the port, generally this means that the user musthave superuser privileges. RIP protocol requires interface informationmaintained by
zebra daemon. So running zebrais mandatory to run
ripd. Thus minimum sequence for runningRIP is like below:
# zebra -d # ripd -d
Please note that zebra must be invoked before ripd.
To stop ripd. Please use kill `cat/var/run/ripd.pid`. Certain signals have special meaningss to
ripd.
- ‘SIGHUP’
-
Reload configuration file ripd.conf. All configurations arereseted. All routes learned so far are cleared and removed from routingtable.
- ‘SIGUSR1’
-
Rotate
ripdlogfile. - ‘SIGINT’
- ‘SIGTERM’
-
ripdsweeps all installed RIP routes then terminates properly.
ripd invocation options. Common options that can be specified(see
Common Invocation Options).
- ‘-r’
- ‘--retain’
-
When the program terminates, retain routes added by
ripd.
| • RIP netmask: |
5.1.1 RIP netmask
The netmask features of ripd support both version 1 and version 2 ofRIP. Version 1 of RIP originally contained no netmask information. InRIP version 1, network classes were originally used to determine thesize of the netmask. Class A networks
use 8 bits of mask, Class Bnetworks use 16 bits of masks, while Class C networks use 24 bits ofmask. Today, the most widely used method of a network mask is assignedto the packet on the basis of the interface that received the packet.Version 2 of RIP supports
a variable length subnet mask (VLSM). Byextending the subnet mask, the mask can be divided and reused. Eachsubnet can be used for different purposes such as large to middle sizeLANs and WAN links. Quagga
ripd does not support the non-sequentialnetmasks that are included in RIP Version 2.
In a case of similar information with the same prefix and metric, theold information will be suppressed. Ripd does not currently supportequal cost multipath routing.
Next: RIP Version Control, Previous: Starting and Stopping ripd, Up: RIP [Contents][Index]
5.2 RIP Configuration
- Command: router rip
-
The
router ripcommand is necessary to enable RIP. To disableRIP, use theno router ripcommand. RIP must be enabled beforecarrying out any of the RIP commands.
- RIP Command: network network
- RIP Command: no network network
-
Set the RIP enable interface by network. The interfaces whichhave addresses matching with network are enabled.
This group of commands either enables or disables RIP interfaces betweencertain numbers of a specified network address. For example, if thenetwork for 10.0.0.0/24 is RIP enabled, this would result in all theaddresses from 10.0.0.0 to 10.0.0.255 being enabled for RIP. The
nonetworkcommand will disable RIP for the specified network.
- RIP Command: network ifname
- RIP Command: no network ifname
-
Set a RIP enabled interface by ifname. Both the sending andreceiving of RIP packets will be enabled on the port specified in the
network ifnamecommand. Theno network ifnamecommand will disableRIP on the specified interface.
- RIP Command: neighbor a.b.c.d
- RIP Command: no neighbor a.b.c.d
-
Specify RIP neighbor. When a neighbor doesn’t understand multicast,this command is used to specify neighbors. In some cases, not allrouters will be able to understand multicasting, where packets are sentto a network or a group of addresses. In a situation where a neighborcannot process multicast packets, it is necessary to establish a directlink between routers. The neighbor command allows the networkadministrator to specify a router as a RIP neighbor. The
noneighbor a.b.c.dcommand will disable the RIP neighbor.
Below is very simple RIP configuration. Interface eth0 andinterface which address match to
10.0.0.0/8 are RIP enabled.
! router rip network 10.0.0.0/8 network eth0 !
Passive interface
- RIP command: passive-interface (IFNAME|default)
- RIP command: no passive-interface IFNAME
-
This command sets the specified interface to passive mode. On passive modeinterface, all receiving packets are processed as normal and ripd doesnot send either multicast or unicast RIP packets except to RIP neighborsspecified with
neighborcommand. The interface may be specifiedas default to make ripd default to passive on all interfaces.The default is to be passive on all interfaces.
RIP split-horizon
- Interface command: ip split-horizon
- Interface command: no ip split-horizon
-
Control split-horizon on the interface. Default is
ipsplit-horizon. If you don’t perform split-horizon on the interface,please specifyno ip split-horizon.
Next: How to Announce RIP route, Previous: RIP Configuration, Up: RIP [Contents][Index]
5.3 RIP Version Control
RIP can be configured to send either Version 1 or Version 2 packets.The default is to send RIPv2 while accepting both RIPv1 and RIPv2 (andreplying with packets of the appropriate version for REQUESTS /triggered updates). The version to receive and send can be specifiedglobally, and further overriden on a per-interface basis if needs befor send and receive seperately (see below).
It is important to note that RIPv1 can not be authenticated. Further,if RIPv1 is enabled then RIP will reply to REQUEST packets, sending thestate of its RIP routing table to any remote routers that ask ondemand. For a more detailed discussion on the security implications ofRIPv1 see RIP Authentication.
- RIP Command: version version
-
Set RIP version to accept for reads and send. versioncan be either ‘1” or ‘2”.
Disabling RIPv1 by specifying version 2 is STRONGLY encouraged,See RIP Authentication. This may become the default in a futurerelease.
Default: Send Version 2, and accept either version.
- Interface command: ip rip send version version
-
version can be ‘1’, ‘2’ or ‘1 2’.
This interface command overrides the global rip version setting, andselects which version of RIP to send packets with, for this interfacespecifically. Choice of RIP Version 1, RIP Version 2, or both versions. In the latter case, where ‘1 2’ is specified, packets will be bothbroadcast and multicast.
Default: Send packets according to the global version (version 2)
- Interface command: ip rip receive version version
-
version can be ‘1’, ‘2’ or ‘1 2’.
This interface command overrides the global rip version setting, andselects which versions of RIP packets will be accepted on thisinterface. Choice of RIP Version 1, RIP Version 2, or both.
Default: Accept packets according to the global setting (both 1 and 2).
Next: Filtering RIP Routes, Previous: RIP Version Control, Up: RIP [Contents][Index]
5.4 How to Announce RIP route
- RIP command: redistribute kernel
- RIP command: redistribute kernel metric <0-16>
- RIP command: redistribute kernel route-map route-map
- RIP command: no redistribute kernel
-
redistribute kernelredistributes routing information fromkernel route entries into the RIP tables.no redistribute kerneldisables the routes.
- RIP command: redistribute static
- RIP command: redistribute static metric <0-16>
- RIP command: redistribute static route-map route-map
- RIP command: no redistribute static
-
redistribute staticredistributes routing information fromstatic route entries into the RIP tables.no redistribute staticdisables the routes.
- RIP command: redistribute connected
- RIP command: redistribute connected metric <0-16>
- RIP command: redistribute connected route-map route-map
- RIP command: no redistribute connected
-
Redistribute connected routes into the RIP tables.
noredistribute connecteddisables the connected routes in the RIP tables.This command redistribute connected of the interface which RIP disabled.The connected route on RIP enabled interface is announced by default.
- RIP command: redistribute ospf
- RIP command: redistribute ospf metric <0-16>
- RIP command: redistribute ospf route-map route-map
- RIP command: no redistribute ospf
-
redistribute ospfredistributes routing information fromospf route entries into the RIP tables.no redistribute ospfdisables the routes.
- RIP command: redistribute bgp
- RIP command: redistribute bgp metric <0-16>
- RIP command: redistribute bgp route-map route-map
- RIP command: no redistribute bgp
-
redistribute bgpredistributes routing information frombgp route entries into the RIP tables.no redistribute bgpdisables the routes.
If you want to specify RIP only static routes:
- RIP command: route a.b.c.d/m
- RIP command: no route a.b.c.d/m
-
This command is specific to Quagga. The
routecommand makes a staticroute only inside RIP. This command should be used only by advancedusers who are particularly knowledgeable about the RIP protocol. Inmost cases, we recommend creating a static route in Quagga andredistributing it in RIP usingredistribute static.
Next: RIP Metric Manipulation, Previous: How to Announce RIP route, Up: RIP [Contents][Index]
5.5 Filtering RIP Routes
RIP routes can be filtered by a distribute-list.
- Command: distribute-list access_list direct ifname
-
You can apply access lists to the interface with a
distribute-listcommand. access_list is the access list name. direct is‘in’ or ‘out’. If direct is ‘in’ the access listis applied to input packets.The
distribute-listcommand can be used to filter the RIP path.distribute-listcan apply access-lists to a chosen interface.First, one should specify the access-list. Next, the name of theaccess-list is used in the distribute-list command. For example, in thefollowing configuration ‘eth0’ will permit only the paths thatmatch the route 10.0.0.0/8! router rip distribute-list private in eth0 ! access-list private permit 10 10.0.0.0/8 access-list private deny any !
distribute-list can be applied to both incoming and outgoing data.
- Command: distribute-list prefix prefix_list (in|out) ifname
-
You can apply prefix lists to the interface with a
distribute-listcommand. prefix_list is the prefix listname. Next is the direction of ‘in’ or ‘out’. Ifdirect is ‘in’ the access list is applied to input packets.
Next: RIP distance, Previous: Filtering RIP Routes, Up: RIP [Contents][Index]
5.6 RIP Metric Manipulation
RIP metric is a value for distance for the network. Usuallyripd increment the metric when the network information isreceived. Redistributed routes’ metric is set to 1.
- RIP command: default-metric <1-16>
- RIP command: no default-metric <1-16>
-
This command modifies the default metric value for redistributed routes. Thedefault value is 1. This command does not affect connected routeeven if it is redistributed by
redistribute connected. To modifyconnected route’s metric value, please useredistributeconnected metricorroute-map.offset-listalsoaffects connected routes.
Next: RIP route-map, Previous: RIP Metric Manipulation, Up: RIP [Contents][Index]
5.7 RIP distance
Distance value is used in zebra daemon. Default RIP distance is 120.
- RIP command: distance <1-255>
- RIP command: no distance <1-255>
-
Set default RIP distance to specified value.
- RIP command: distance <1-255> A.B.C.D/M
- RIP command: no distance <1-255> A.B.C.D/M
-
Set default RIP distance to specified value when the route’s source IPaddress matches the specified prefix.
- RIP command: distance <1-255> A.B.C.D/M access-list
- RIP command: no distance <1-255> A.B.C.D/M access-list
-
Set default RIP distance to specified value when the route’s source IPaddress matches the specified prefix and the specified access-list.
Next: RIP Authentication, Previous: RIP distance, Up: RIP [Contents][Index]
5.8 RIP route-map
Usage of ripd’s route-map support.
Optional argument route-map MAP_NAME can be added to each redistributestatement.
redistribute static [route-map MAP_NAME] redistribute connected [route-map MAP_NAME] .....
Cisco applies route-map _before_ routes will exported to rip route table. In current Quagga’s test implementation,
ripd applies route-mapafter routes are listed in the route table and before routes will beannounced to an interface (something like output filter). I think it is notso clear, but it is draft and it may be changed at future.
Route-map statement (see Route Map) is needed to use route-mapfunctionality.
- Route Map: match interface word
-
This command match to incoming interface. Notation of this match isdifferent from Cisco. Cisco uses a list of interfaces - NAME1 NAME2... NAMEN. Ripd allows only one name (maybe will change in thefuture). Next - Cisco means interface which includes next-hop ofroutes (it is somewhat similar to "ip next-hop" statement). Ripdmeans interface where this route will be sent. This difference isbecause "next-hop" of same routes which sends to different interfacesmust be different. Maybe it’d be better to made new matches - say"match interface-out NAME" or something like that.
- Route Map: match ip address word
- Route Map: match ip address prefix-list word
-
Match if route destination is permitted by access-list.
- Route Map: match ip next-hop word
- Route Map: match ip next-hop prefix-list word
-
Match if route next-hop (meaning next-hop listed in the rip route-tableas displayed by "show ip rip") is permitted by access-list.
- Route Map: match metric <0-4294967295>
-
This command match to the metric value of RIP updates. For otherprotocol compatibility metric range is shown as <0-4294967295>. Butfor RIP protocol only the value range <0-16> make sense.
- Route Map: set ip next-hop A.B.C.D
-
This command set next hop value in RIPv2 protocol. This command doesnot affect RIPv1 because there is no next hop field in the packet.
- Route Map: set metric <0-4294967295>
-
Set a metric for matched route when sending announcement. The metricvalue range is very large for compatibility with other protocols. ForRIP, valid metric values are from 1 to 16.
Next: RIP Timers, Previous: RIP route-map, Up: RIP [Contents][Index]
5.9 RIP Authentication
RIPv2 allows packets to be authenticated via either an insecure plaintext password, included with the packet, or via a more secure MD5 basedHMAC (keyed-Hashing for Message AuthentiCation),RIPv1
can not be authenticated at all, thus when authentication isconfigured ripd will discard routing updates received via RIPv1packets.
However, unless RIPv1 reception is disabled entirely, See
RIP Version Control, RIPv1 REQUEST packets which are received,which query the router for routing information, will still be honouredby
ripd, and ripd WILL reply to such packets. This allows
ripd to honour such REQUESTs (which sometimes is used by oldequipment and very simple devices to bootstrap their default route),while still providing security for route updates which are received.
In short: Enabling authentication prevents routes being updated byunauthenticated remote routers, but still can allow routes (I.e. theentire RIP routing table) to be queried remotely, potentially by anyoneon the internet, via RIPv1.
To prevent such unauthenticated querying of routes disable RIPv1,See RIP Version Control.
- Interface command: ip rip authentication mode md5
- Interface command: no ip rip authentication mode md5
-
Set the interface with RIPv2 MD5 authentication.
- Interface command: ip rip authentication mode text
- Interface command: no ip rip authentication mode text
-
Set the interface with RIPv2 simple password authentication.
- Interface command: ip rip authentication string string
- Interface command: no ip rip authentication string string
-
RIP version 2 has simple text authentication. This command setsauthentication string. The string must be shorter than 16 characters.
- Interface command: ip rip authentication key-chain key-chain
- Interface command: no ip rip authentication key-chain key-chain
-
Specifiy Keyed MD5 chain.
! key chain test key 1 key-string test ! interface eth1 ip rip authentication mode md5 ip rip authentication key-chain test !
Next: Show RIP Information, Previous: RIP Authentication, Up: RIP [Contents][Index]
5.10 RIP Timers
- RIP command: timers basic update timeout garbage
-
RIP protocol has several timers. User can configure those timers’ valuesby
timers basiccommand.The default settings for the timers are as follows:
- The update timer is 30 seconds. Every update timer seconds, the RIPprocess is awakened to send an unsolicited Response message containingthe complete routing table to all neighboring RIP routers.
- The timeout timer is 180 seconds. Upon expiration of the timeout, theroute is no longer valid; however, it is retained in the routing tablefor a short time so that neighbors can be notified that the route hasbeen dropped.
- The garbage collect timer is 120 seconds. Upon expiration of thegarbage-collection timer, the route is finally removed from the routingtable.
The
timers basiccommand allows the the default values of the timerslisted above to be changed.
- RIP command: no timers basic
-
The
no timers basiccommand will reset the timers to the defaultsettings listed above.
Next: RIP Debug Commands, Previous: RIP Timers, Up: RIP [Contents][Index]
5.11 Show RIP Information
To display RIP routes.
The command displays all RIP routes. For routes that are receivedthrough RIP, this command will display the time the packet was sent andthe tag information. This command will also display this informationfor routes redistributed into RIP.
- Command: show ip rip status
-
The command displays current RIP status. It includes RIP timer,filtering, version, RIP enabled interface and RIP peer inforation.
ripd> show ip rip status
Routing Protocol is "rip"
Sending updates every 30 seconds with +/-50%, next due in 35 seconds
Timeout after 180 seconds, garbage collect after 120 seconds
Outgoing update filter list for all interface is not set
Incoming update filter list for all interface is not set
Default redistribution metric is 1
Redistributing: kernel connected
Default version control: send version 2, receive version 2
Interface Send Recv
Routing for Networks:
eth0
eth1
1.1.1.1
203.181.89.241
Routing Information Sources:
Gateway BadPackets BadRoutes Distance Last Update
Previous: Show RIP Information, Up: RIP [Contents][Index]
5.12 RIP Debug Commands
Debug for RIP protocol.
debug rip will show RIP events. Sending and receivingpackets, timers, and changes in interfaces are events shown with
ripd.
debug rip packet will display detailed information about the RIPpackets. The origin and port number of the packet as well as a packetdump is shown.
This command will show the communication between ripd andzebra. The main information will include addition and deletion ofpaths to the kernel and the sending and receiving of interface information.
show debugging rip will show all information currently set for ripddebug.
6 RIPng
ripngd supports the RIPng protocol as described in RFC2080. It’s anIPv6 reincarnation of the RIP protocol.
| • Invoking ripngd: | ||
| • ripngd Configuration: | ||
| • ripngd Terminal Mode Commands: | ||
| • ripngd Filtering Commands: |
Next: ripngd Configuration, Up: RIPng [Contents][Index]
6.1 Invoking ripngd
There are no ripngd specific invocation options. Common optionscan be specified (see
Common Invocation Options).
Next: ripngd Terminal Mode Commands, Previous: Invoking ripngd, Up: RIPng [Contents][Index]
6.2 ripngd Configuration
Currently ripngd supports the following commands:
- Command: router zebra
-
This command is the default and does not appear in the configuration.With this statement, RIPng routes go to the
zebradaemon.
Next: ripngd Filtering Commands, Previous: ripngd Configuration, Up: RIPng [Contents][Index]
6.3 ripngd Terminal Mode Commands
Previous: ripngd Terminal Mode Commands, Up: RIPng [Contents][Index]
6.4 ripngd Filtering Commands
- Command: distribute-list access_list (in|out) ifname
-
You can apply an access-list to the interface using the
distribute-listcommand. access_list is an access-listname. direct is ‘in’ or ‘out’. If direct is‘in’, the access-list is applied only to incoming packets.distribute-list local-only out sit1
7 OSPFv2
OSPF (Open Shortest Path First) version 2 is a routing protocolwhich is described in RFC2328, OSPF Version 2. OSPF is anIGP (Interior Gateway Protocol). Compared with RIP,OSPF can provide scalable network support and fasterconvergence times. OSPF is widely used in large networks such asISP (Internet Service Provider) backbone and enterprisenetworks.
Next: Configuring ospfd, Up: OSPFv2 [Contents][Index]
7.1 OSPF Fundamentals
OSPF is, mostly, a link-state routing protocol. In contrastto distance-vector protocols, such as RIP orBGP, where routers describe available paths (i.e. routes) to each other, in link-state protocols routers insteaddescribe the state of their links to their immediate neighbouringrouters.
Each router describes their link-state information in a message knownas an LSA (Link State Advertisement), which is then propogatedthrough to all other routers in a link-state routing domain, by aprocess called flooding. Each router thus builds up anLSDB (Link State Database) of all the link-state messages. Fromthis collection of LSAs in the LSDB, each router can then calculate theshortest path to any other router, based on some common metric, byusing an algorithm such as Edgser Dijkstra’s SPF (Shortest Path First).
By describing connectivity of a network in this way, in terms ofrouters and links rather than in terms of the paths through a network,a link-state protocol can use less bandwidth and converge more quicklythan other protocols. A link-state protocol need distribute only onelink-state message throughout the link-state domain when a link on anysingle given router changes state, in order for all routers toreconverge on the best paths through the network. In contrast, distancevector protocols can require a progression of different path updatemessages from a series of different routers in order to converge.
The disadvantage to a link-state protocol is that the process ofcomputing the best paths can be relatively intensive when compared todistance-vector protocols, in which near to no computation need be doneother than (potentially) select between multiple routes. This overheadis mostly negligible for modern embedded CPUs, even for networks withthousands of nodes. The primary scaling overhead lies more in copingwith the ever greater frequency of LSA updates as the size of alink-state area increases, in managing the LSDB and requiredflooding.
This section aims to give a distilled, but accurate, description of themore important workings of OSPF which an administrator may needto know to be able best configure and trouble-shoot OSPF.
7.1.1 OSPF Mechanisms
OSPF defines a range of mechanisms, concerned with detecting,describing and propogating state through a network. These mechanismswill nearly all be covered in greater detail further on. They may bebroadly classed as:
- The Hello Protocol
-
The OSPF Hello protocol allows OSPF to quickly detect changes intwo-way reachability between routers on a link. OSPF can additionallyavail of other sources of reachability information, such as link-stateinformation provided by hardware, or through dedicated reachabilityprotocols such as BFD (Bi-directional Forwarding Detection).
OSPF also uses the Hello protocol to propagate certain state betweenrouters sharing a link, for example:
- Hello protocol configured state, such as the dead-interval.
- Router priority, for DR/BDR election.
- DR/BDR election results.
- Any optional capabilities supported by each router.
The Hello protocol is comparatively trivial and will not be explored ingreater detail than here.
- LSAs
-
At the heart of OSPF are LSA (Link StateAdvertisement) messages. Despite the name, some LSAs do not,strictly speaking, describe link-state information. CommonLSAs describe information such as:
- Routers, in terms of their links.
- Networks, in terms of attached routers.
- Routes, external to a link-state domain:
- External Routes
Routes entirely external to OSPF. Routers originating suchroutes are known as ASBR (Autonomous-System Border Router)routers.
- Summary Routes
Routes which summarise routing information relating to OSPF areasexternal to the OSPF link-state area at hand, originated byABR (Area Boundary Router) routers.
- External Routes
- LSA Flooding
-
OSPF defines several related mechanisms, used to manage synchronisation ofLSDBs between neighbours as neighbours form adjacencies andthe propogation, or flooding of new or updated LSAs.
See OSPF Flooding.
- Areas
-
OSPF provides for the protocol to be broken up into multiple smallerand independent link-state areas. Each area must be connected to acommon backbone area by an ABR (Area Boundary Router). TheseABR routers are responsible for summarising the link-staterouting information of an area into Summary LSAs, possibly in acondensed (i.e. aggregated) form, and then originating these summariesinto all other areas the ABR is connected to.
Note that only summaries and external routes are passed between areas.As these describe paths, rather than any router link-states,routing between areas hence is by distance-vector, notlink-state.
See OSPF Areas.
7.1.2 OSPF LSAs
LSAs are the core object in OSPF. Everything else in OSPFrevolves around detecting what to describe in LSAs, when to updatethem, how to flood them throughout a network and how to calculateroutes from them.
There are a variety of different LSAs, for purposes suchas describing actual link-state information, describing paths (i.e.routes), describing bandwidth usage of links for TE (Traffic Engineering) purposes, and even arbitrary databy way of Opaque LSAs.
7.1.2.1 LSA Header
All LSAs share a common header with the following information:
- Type
Different types of LSAs describe different things inOSPF. Types include:
- Router LSA
- Network LSA
- Network Summary LSA
- Router Summary LSA
- AS-External LSA
The specifics of the different types of LSA are examined below.
- Advertising Router
The Router ID of the router originating the LSA, see ospf router-id.
- LSA ID
The ID of the LSA, which is typically derived in some way from theinformation the LSA describes, e.g. a Router LSA uses the Router ID asthe LSA ID, a Network LSA will have the IP address of the DRas its LSA ID.
The combination of the Type, ID and Advertising Router ID must uniquelyidentify the LSA. There can however be multiple instances ofan LSA with the same Type, LSA ID and Advertising Router ID, seeLSA Sequence Number.
- Age
A number to allow stale LSAs to, eventually, be purged by routersfrom their LSDBs.
The value nominally is one of seconds. An age of 3600, i.e. 1 hour, iscalled the MaxAge. MaxAge LSAs are ignored in routingcalculations. LSAs must be periodically refreshed by their AdvertisingRouter before reaching MaxAge if they are to remain valid.
Routers may deliberately flood LSAs with the age artificially set to3600 to indicate an LSA is no longer valid. This is calledflushing of an LSA.
It is not abnormal to see stale LSAs in the LSDB, this can occur wherea router has shutdown without flushing its LSA(s), e.g. where it hasbecome disconnected from the network. Such LSAs do little harm.
- Sequence Number
A number used to distinguish newer instances of an LSA from older instances.
7.1.2.2 Link-State LSAs
Of all the various kinds of LSAs, just two types comprise theactual link-state part of OSPF, Router LSAs andNetwork LSAs. These LSA types are absolutely core to theprotocol.
Instances of these LSAs are specific to the link-state area in whichthey are originated. Routes calculated from these two LSA types arecalled intra-area routes.
- Router LSA
Each OSPF Router must originate a router LSA to describeitself. In it, the router lists each of its OSPF enabledinterfaces, for the given link-state area, in terms of:
- Cost
The output cost of that interface, scaled inversely to some commonly knownreference value, See auto-costreference-bandwidth.
- Link Type
- Transit Network
A link to a multi-access network, on which the router has at least oneFull adjacency with another router.
- PtP (Point-to-Point)
A link to a single remote router, with a Full adjacency. NoDR (Designated Router) is elected on such links; no networkLSA is originated for such a link.
- Stub
A link with no adjacent neighbours, or a host route.
- Transit Network
- Link ID and Data
These values depend on the Link Type:
Link Type Link ID Link Data Transit Link IP address of the DR Interface IP address Point-to-Point Router ID of the remote router Local interface IP address,or the ifindex (MIB-II interface index) for unnumbered links Stub IP address Subnet Mask
Links on a router may be listed multiple times in the Router LSA, e.g.a PtP interface on which OSPF is enabled must alwaysbe described by a Stub link in the Router LSA, in addition tobeing listed as PtP link in the Router LSA if the adjacencywith the remote router is Full.
Stub links may also be used as a way to describe links on which OSPF isnot spoken, known as passive interfaces, see passive-interface.
- Cost
- Network LSA
On multi-access links (e.g. ethernets, certain kinds of ATM and X.25configurations), routers elect a DR. The DR isresponsible for originating a Network LSA, which helps reducethe information needed to describe multi-access networks with multiplerouters attached. The DR also acts as a hub for the flooding ofLSAs on that link, thus reducing flooding overheads.
The contents of the Network LSA describes the:
- Subnet Mask
As the LSA ID of a Network LSA must be the IP address of theDR, the Subnet Mask together with the LSA ID givesyou the network address.
- Attached Routers
Each router fully-adjacent with the DR is listed in the LSA,by their Router-ID. This allows the corresponding Router LSAs to beeasily retrieved from the LSDB.
- Subnet Mask
Summary of Link State LSAs:
| LSA Type | LSA ID Describes | LSA Data Describes |
|---|---|---|
| Router LSA | The Router ID | The OSPF enabled links of the router, within a specific link-state area. |
| Network LSA | The IP address of the DR for the network | The Subnet Mask of the network, and the Router IDs of all routers on the network. |
With an LSDB composed of just these two types of LSA, it ispossible to construct a directed graph of the connectivity between allrouters and networks in a given OSPF link-state area. So, notsurprisingly, when OSPF routers build updated routing tables, the firststage of SPF calculation concerns itself only with these twoLSA types.
7.1.2.3 Link-State LSA Examples
The example below (see OSPF Link-State LSA Example) shows twoLSAs, both originated by the same router (Router ID192.168.0.49) and with the same LSA ID (192.168.0.49), but ofdifferent LSA types.
The first LSA being the router LSA describing 192.168.0.49’s links: 2 linksto multi-access networks with fully-adjacent neighbours (i.e. Transitlinks) and 1 being a Stub link (no adjacent neighbours).
The second LSA being a Network LSA, for which 192.168.0.49 is theDR, listing the Router IDs of 4 routers on that network whichare fully adjacent with 192.168.0.49.
# show ip ospf database router 192.168.0.49
OSPF Router with ID (192.168.0.53)
Router Link States (Area 0.0.0.0)
LS age: 38
Options: 0x2 : *|-|-|-|-|-|E|*
LS Flags: 0x6
Flags: 0x2 : ASBR
LS Type: router-LSA
Link State ID: 192.168.0.49
Advertising Router: 192.168.0.49
LS Seq Number: 80000f90
Checksum: 0x518b
Length: 60
Number of Links: 3
Link connected to: a Transit Network
(Link ID) Designated Router address: 192.168.1.3
(Link Data) Router Interface address: 192.168.1.3
Number of TOS metrics: 0
TOS 0 Metric: 10
Link connected to: a Transit Network
(Link ID) Designated Router address: 192.168.0.49
(Link Data) Router Interface address: 192.168.0.49
Number of TOS metrics: 0
TOS 0 Metric: 10
Link connected to: Stub Network
(Link ID) Net: 192.168.3.190
(Link Data) Network Mask: 255.255.255.255
Number of TOS metrics: 0
TOS 0 Metric: 39063
# show ip ospf database network 192.168.0.49
OSPF Router with ID (192.168.0.53)
Net Link States (Area 0.0.0.0)
LS age: 285
Options: 0x2 : *|-|-|-|-|-|E|*
LS Flags: 0x6
LS Type: network-LSA
Link State ID: 192.168.0.49 (address of Designated Router)
Advertising Router: 192.168.0.49
LS Seq Number: 80000074
Checksum: 0x0103
Length: 40
Network Mask: /29
Attached Router: 192.168.0.49
Attached Router: 192.168.0.52
Attached Router: 192.168.0.53
Attached Router: 192.168.0.54
Note that from one LSA, you can find the other. E.g. Given theNetwork-LSA you have a list of Router IDs on that network, from whichyou can then look up, in the local LSDB, the matching RouterLSA. From that Router-LSA you may (potentially) find links to otherTransit networks and Routers IDs which can be used to lookup thecorresponding Router or Network LSA. And in that fashion, one can findall the Routers and Networks reachable from that starting LSA.
Given the Router LSA instead, you have the IP address of theDR of any attached transit links. Network LSAs will have that IPas their LSA ID, so you can then look up that Network LSA and from thatfind all the attached routers on that link, leading potentially to morelinks and Network and Router LSAs, etc. etc.
From just the above two LSAs, one can already see thefollowing partial topology:
--------------------- Network: ......
| Designated Router IP: 192.168.1.3
|
IP: 192.168.1.3
(transit link)
(cost: 10)
Router ID: 192.168.0.49(stub)---------- IP: 192.168.3.190/32
(cost: 10) (cost: 39063)
(transit link)
IP: 192.168.0.49
|
|
------------------------------ Network: 192.168.0.48/29
| | | Designated Router IP: 192.168.0.49
| | |
| | Router ID: 192.168.0.54
| |
| Router ID: 192.168.0.53
|
Router ID: 192.168.0.52
Note the Router IDs, though they look like IP addresses and often areIP addresses, are not strictly speaking IP addresses, nor need they bereachable addresses (though, OSPF will calculate routes to Router IDs).
7.1.2.4 External LSAs
External, or "Type 5", LSAs describe routing information which isentirely external to OSPF, and is "injected" intoOSPF. Such routing information may have come from anotherrouting protocol, such as RIP or BGP, they may represent static routesor they may represent a default route.
An OSPF router which originates External LSAs is known as anASBR (AS Boundary Router). Unlike the link-state LSAs, andmost other LSAs, which are flooded only within the area inwhich they originate, External LSAs are flooded through-outthe OSPF network to all areas capable of carrying ExternalLSAs (see OSPF Areas).
Routes internal to OSPF (intra-area or inter-area) are always preferredover external routes.
The External LSA describes the following:
- IP Network number
The IP Network number of the route is described by the LSA IDfield.
- IP Network Mask
The body of the External LSA describes the IP Network Mask of theroute. This, together with the LSA ID, describes the prefixof the IP route concerned.
- Metric
The cost of the External Route. This cost may be an OSPF cost (alsoknown as a "Type 1" metric), i.e. equivalent to the normal OSPF costs,or an externally derived cost ("Type 2" metric) which is not comparableto OSPF costs and always considered larger than any OSPF cost. Wherethere are both Type 1 and 2 External routes for a route, the Type 1 isalways preferred.
- Forwarding Address
The address of the router to forward packets to for the route. This maybe, and usually is, left as 0 to specify that the ASBR originating theExternal LSA should be used. There must be an internal OSPFroute to the forwarding address, for the forwarding address to beuseable.
- Tag
An arbitrary 4-bytes of data, not interpreted by OSPF, which maycarry whatever information about the route which OSPF speakers desire.
7.1.2.5 AS External LSA Example
To illustrate, below is an example of an External LSA in theLSDB of an OSPF router. It describes a route to the IP prefixof 192.168.165.0/24, originated by the ASBR with Router-ID192.168.0.49. The metric of 20 is external to OSPF. The forwardingaddress is 0, so the route should forward to the originating ASBR ifselected.
# show ip ospf database external 192.168.165.0
LS age: 995
Options: 0x2 : *|-|-|-|-|-|E|*
LS Flags: 0x9
LS Type: AS-external-LSA
Link State ID: 192.168.165.0 (External Network Number)
Advertising Router: 192.168.0.49
LS Seq Number: 800001d8
Checksum: 0xea27
Length: 36
Network Mask: /24
Metric Type: 2 (Larger than any link state path)
TOS: 0
Metric: 20
Forward Address: 0.0.0.0
External Route Tag: 0
We can add this to our partial topology from above, which now lookslike:
--------------------- Network: ......
| Designated Router IP: 192.168.1.3
|
IP: 192.168.1.3 /---- External route: 192.168.165.0/24
(transit link) / Cost: 20 (External metric)
(cost: 10) /
Router ID: 192.168.0.49(stub)---------- IP: 192.168.3.190/32
(cost: 10) (cost: 39063)
(transit link)
IP: 192.168.0.49
|
|
------------------------------ Network: 192.168.0.48/29
| | | Designated Router IP: 192.168.0.49
| | |
| | Router ID: 192.168.0.54
| |
| Router ID: 192.168.0.53
|
Router ID: 192.168.0.52
7.1.2.6 Summary LSAs
Summary LSAs are created by ABRs to summarise the destinations available within one area to other areas. These LSAs may describe IP networks, potentially in aggregated form, or ASBR routers.
7.1.3 OSPF Flooding
7.1.4 OSPF Areas
Next: OSPF router, Previous: OSPF Fundamentals, Up: OSPFv2 [Contents][Index]
7.2 Configuring ospfd
There are no ospfd specific options. Common options can bespecified (see
Common Invocation Options) to ospfd.ospfd needs to acquire interface information fromzebra in order to function. Therefore
zebra must berunning before invoking ospfd. Also, if
zebra isrestarted then ospfd must be too.
Like other daemons, ospfd configuration is done in
OSPFspecific configuration file ospfd.conf.
Next: OSPF area, Previous: Configuring ospfd, Up: OSPFv2 [Contents][Index]
7.3 OSPF router
To start OSPF process you have to specify the OSPF router. As of thiswriting,
ospfd does not support multiple OSPF processes.
- Command: router ospf
- Command: no router ospf
-
Enable or disable the OSPF process.
ospfddoes not yetsupport multiple OSPF processes. So you can not specify an OSPF processnumber.
- OSPF Command: ospf router-id a.b.c.d
- OSPF Command: no ospf router-id
-
This sets the router-ID of the OSPF process. Therouter-ID may be an IP address of the router, but need not be - it canbe any arbitrary 32bit number. However it MUST be unique within theentire OSPF domain to the OSPF speaker - bad things will happen ifmultiple OSPF speakers are configured with the same router-ID! If oneis not specified then
ospfdwill obtain a router-IDautomatically fromzebra.
- OSPF Command: ospf abr-type type
- OSPF Command: no ospf abr-type type
-
type can be cisco|ibm|shortcut|standard. The "Cisco" and "IBM" typesare equivalent.
The OSPF standard for ABR behaviour does not allow an ABR to considerroutes through non-backbone areas when its links to the backbone aredown, even when there are other ABRs in attached non-backbone areaswhich still can reach the backbone - this restriction exists primarilyto ensure routing-loops are avoided.
With the "Cisco" or "IBM" ABR type, the default in this release ofQuagga, this restriction is lifted, allowing an ABR to considersummaries learnt from other ABRs through non-backbone areas, and henceroute via non-backbone areas as a last resort when, and only when,backbone links are down.
Note that areas with fully-adjacent virtual-links are considered to be"transit capable" and can always be used to route backbone traffic, andhence are unaffected by this setting (see OSPF virtual-link).
More information regarding the behaviour controlled by this command canbe found in RFC 3509, Alternative Implementations of OSPF AreaBorder Routers, and draft-ietf-ospf-shortcut-abr-02.txt.
Quote: "Though the definition of the ABR (Area Border Router)in the OSPF specification does not require a router with multipleattached areas to have a backbone connection, it is actuallynecessary to provide successful routing to the inter-area andexternal destinations. If this requirement is not met, all trafficdestined for the areas not connected to such an ABR or out of theOSPF domain, is dropped. This document describes alternative ABRbehaviors implemented in Cisco and IBM routers."
- OSPF Command: ospf rfc1583compatibility
- OSPF Command: no ospf rfc1583compatibility
-
RFC2328, the sucessor to RFC1583, suggests accordingto section G.2 (changes) in section 16.4 a change to the pathpreference algorithm that prevents possible routing loops that werepossible in the old version of OSPFv2. More specifically it demandsthat inter-area paths and intra-area backbone path are now of equal preferencebut still both preferred to external paths.
This command should NOT be set normally.
- OSPF Command: log-adjacency-changes [detail]
- OSPF Command: no log-adjacency-changes [detail]
-
Configures ospfd to log changes in adjacency. With the optionaldetail argument, all changes in adjacency status are shown. Without detail,only changes to full or regressions are shown.
- OSPF Command: passive-interface interface
- OSPF Command: no passive-interface interface
-
Do not speak OSPF interface on thegiven interface, but do advertise the interface as a stub link in therouter-LSA (Link State Advertisement) for this router. Thisallows one to advertise addresses on such connected interfaces withouthaving to originate AS-External/Type-5 LSAs (which have global floodingscope) - as would occur if connected addresses were redistributed intoOSPF (see Redistribute routes to OSPF). This is the only way toadvertise non-OSPF links into stub areas.
- OSPF Command: timers throttle spf delay initial-holdtime max-holdtime
- OSPF Command: no timers throttle spf
-
This command sets the initial delay, the initial-holdtimeand the maximum-holdtime between when SPF is calculated and theevent which triggered the calculation. The times are specified inmilliseconds and must be in the range of 0 to 600000 milliseconds.
The delay specifies the minimum amount of time to delay SPFcalculation (hence it affects how long SPF calculation is delayed afteran event which occurs outside of the holdtime of any previous SPFcalculation, and also serves as a minimum holdtime).
Consecutive SPF calculations will always be seperated by at least’hold-time’ milliseconds. The hold-time is adaptive and initially isset to the initial-holdtime configured with the above command.Events which occur within the holdtime of the previous SPF calculationwill cause the holdtime to be increased by initial-holdtime, boundedby the maximum-holdtime configured with this command. If the adaptivehold-time elapses without any SPF-triggering event occuring then the current holdtime is reset to the initial-holdtime. The currentholdtime can be viewed with show ip ospf, where it is expressed as a multiplier of the initial-holdtime.
router ospf timers throttle spf 200 400 10000
In this example, the delay is set to 200ms, the initialholdtime is set to 400ms and the maximum holdtime to 10s. Hencethere will always be at least 200ms between an event which requires SPFcalculation and the actual SPF calculation. Further consecutive SPFcalculations will always be seperated by between 400ms to 10s, thehold-time increasing by 400ms each time an SPF-triggering event occurswithin the hold-time of the previous SPF calculation.
This command supercedes the
timers spfcommand in previous Quaggareleases.
- OSPF Command: max-metric router-lsa [on-startup|on-shutdown] <5-86400>
- OSPF Command: max-metric router-lsa administrative
- OSPF Command: no max-metric router-lsa [on-startup|on-shutdown|administrative]
-
This enables RFC3137, OSPF Stub Router Advertisement support,where the OSPF process describes its transit links in its router-LSA ashaving infinite distance so that other routers will avoid calculatingtransit paths through the router while still being able to reachnetworks through the router.
This support may be enabled administratively (and indefinitely) orconditionally. Conditional enabling of max-metric router-lsas can befor a period of seconds after startup and/or for a period of secondsprior to shutdown.
Enabling this for a period after startup allows OSPF to converge fullyfirst without affecting any existing routes used by other routers,while still allowing any connected stub links and/or redistributedroutes to be reachable. Enabling this for a period of time in advanceof shutdown allows the router to gracefully excuse itself from the OSPFdomain.
Enabling this feature administratively allows for administrativeintervention for whatever reason, for an indefinite period of time.Note that if the configuration is written to file, this administrativeform of the stub-router command will also be written to file. If
ospfdis restarted later, the command will then take effectuntil manually deconfigured.Configured state of this feature as well as current status, such as thenumber of second remaining till on-startup or on-shutdown ends, can beviewed with the show ip ospf command.
- OSPF Command: auto-cost reference-bandwidth <1-4294967>
- OSPF Command: no auto-cost reference-bandwidth
-
This sets the referencebandwidth for cost calculations, where this bandwidth is consideredequivalent to an OSPF cost of 1, specified in Mbits/s. The default is100Mbit/s (i.e. a link of bandwidth 100Mbit/s or higher will have acost of 1. Cost of lower bandwidth links will be scaled with referenceto this cost).
This configuration setting MUST be consistent across all routers within theOSPF domain.
- OSPF Command: network a.b.c.d/m area a.b.c.d
- OSPF Command: network a.b.c.d/m area <0-4294967295>
- OSPF Command: no network a.b.c.d/m area a.b.c.d
- OSPF Command: no network a.b.c.d/m area <0-4294967295>
-
This command specifies the OSPF enabled interface(s). If the interface hasan address from range 192.168.1.0/24 then the command below enables ospfon this interface so router can provide network information to the otherospf routers via this interface.
router ospf network 192.168.1.0/24 area 0.0.0.0
Prefix length in interface must be equal or bigger (ie. smaller network) thanprefix length in network statement. For example statement above doesn’t enableospf on interface with address 192.168.1.1/23, but it does on interface withaddress 192.168.1.129/25.
Note that the behavior when there is a peer addressdefined on an interface changed after release 0.99.7.Currently, if a peer prefix has been configured,then we test whether the prefix in the network command containsthe destination prefix. Otherwise, we test whether the network command prefixcontains the local address prefix of the interface.
In some cases it may be more convenient to enable OSPF on a perinterface/subnet basis (see OSPF ip ospf area command).
Next: OSPF interface, Previous: OSPF router, Up: OSPFv2 [Contents][Index]
7.4 OSPF area
- OSPF Command: area a.b.c.d range a.b.c.d/m
- OSPF Command: area <0-4294967295> range a.b.c.d/m
- OSPF Command: no area a.b.c.d range a.b.c.d/m
- OSPF Command: no area <0-4294967295> range a.b.c.d/m
-
Summarize intra area paths from specified area into one Type-3 summary-LSAannounced to other areas. This command can be used only in ABR and ONLYrouter-LSAs (Type-1) and network-LSAs (Type-2) (ie. LSAs with scope area) canbe summarized. Type-5 AS-external-LSAs can’t be summarized - their scope is AS.Summarizing Type-7 AS-external-LSAs isn’t supported yet by Quagga.
router ospf network 192.168.1.0/24 area 0.0.0.0 network 10.0.0.0/8 area 0.0.0.10 area 0.0.0.10 range 10.0.0.0/8
With configuration above one Type-3 Summary-LSA with routing info 10.0.0.0/8 isannounced into backbone area if area 0.0.0.10 contains at least one intra-areanetwork (ie. described with router or network LSA) from this range.
- OSPF Command: area a.b.c.d range IPV4_PREFIX not-advertise
- OSPF Command: no area a.b.c.d range IPV4_PREFIX not-advertise
-
Instead of summarizing intra area paths filter them - ie. intra area paths from thisrange are not advertised into other areas.This command makes sense in ABR only.
- OSPF Command: area a.b.c.d range IPV4_PREFIX substitute IPV4_PREFIX
- OSPF Command: no area a.b.c.d range IPV4_PREFIX substitute IPV4_PREFIX
-
Substitute summarized prefix with another prefix.
router ospf network 192.168.1.0/24 area 0.0.0.0 network 10.0.0.0/8 area 0.0.0.10 area 0.0.0.10 range 10.0.0.0/8 substitute 11.0.0.0/8
One Type-3 summary-LSA with routing info 11.0.0.0/8 is announced into backbone area ifarea 0.0.0.10 contains at least one intra-area network (ie. described with router-LSA ornetwork-LSA) from range 10.0.0.0/8.This command makes sense in ABR only.
- OSPF Command: area a.b.c.d virtual-link a.b.c.d
- OSPF Command: area <0-4294967295> virtual-link a.b.c.d
- OSPF Command: no area a.b.c.d virtual-link a.b.c.d
- OSPF Command: no area <0-4294967295> virtual-link a.b.c.d
- OSPF Command: area a.b.c.d shortcut
- OSPF Command: area <0-4294967295> shortcut
- OSPF Command: no area a.b.c.d shortcut
- OSPF Command: no area <0-4294967295> shortcut
-
Configure the area as Shortcut capable. See RFC3509. This requiresthat the ’abr-type’ be set to ’shortcut’.
- OSPF Command: area a.b.c.d stub
- OSPF Command: area <0-4294967295> stub
- OSPF Command: no area a.b.c.d stub
- OSPF Command: no area <0-4294967295> stub
-
Configure the area to be a stub area. That is, an area where no routeroriginates routes external to OSPF and hence an area where all external routes are via the ABR(s). Hence, ABRs for such an area do not needto pass AS-External LSAs (type-5s) or ASBR-Summary LSAs (type-4) into thearea. They need only pass Network-Summary (type-3) LSAs into such an area,along with a default-route summary.
- OSPF Command: area a.b.c.d stub no-summary
- OSPF Command: area <0-4294967295> stub no-summary
- OSPF Command: no area a.b.c.d stub no-summary
- OSPF Command: no area <0-4294967295> stub no-summary
-
Prevents an
ospfdABR from injecting inter-area summaries into the specified stub area.
- OSPF Command: area a.b.c.d default-cost <0-16777215>
- OSPF Command: no area a.b.c.d default-cost <0-16777215>
-
Set the cost of default-summary LSAs announced to stubby areas.
- OSPF Command: area a.b.c.d export-list NAME
- OSPF Command: area <0-4294967295> export-list NAME
- OSPF Command: no area a.b.c.d export-list NAME
- OSPF Command: no area <0-4294967295> export-list NAME
-
Filter Type-3 summary-LSAs announced to other areas originated from intra-area paths from specified area.
router ospf network 192.168.1.0/24 area 0.0.0.0 network 10.0.0.0/8 area 0.0.0.10 area 0.0.0.10 export-list foo ! access-list foo permit 10.10.0.0/16 access-list foo deny any
With example above any intra-area paths from area 0.0.0.10 and from range10.10.0.0/16 (for example 10.10.1.0/24 and 10.10.2.128/30) are announced intoother areas as Type-3 summary-LSA’s, but any others (for example 10.11.0.0/16or 10.128.30.16/30) aren’t.
This command is only relevant if the router is an ABR for the specifiedarea.
- OSPF Command: area a.b.c.d import-list NAME
- OSPF Command: area <0-4294967295> import-list NAME
- OSPF Command: no area a.b.c.d import-list NAME
- OSPF Command: no area <0-4294967295> import-list NAME
-
Same as export-list, but it applies to paths announced into specified area asType-3 summary-LSAs.
- OSPF Command: area a.b.c.d filter-list prefix NAME in
- OSPF Command: area a.b.c.d filter-list prefix NAME out
- OSPF Command: area <0-4294967295> filter-list prefix NAME in
- OSPF Command: area <0-4294967295> filter-list prefix NAME out
- OSPF Command: no area a.b.c.d filter-list prefix NAME in
- OSPF Command: no area a.b.c.d filter-list prefix NAME out
- OSPF Command: no area <0-4294967295> filter-list prefix NAME in
- OSPF Command: no area <0-4294967295> filter-list prefix NAME out
-
Filtering Type-3 summary-LSAs to/from area using prefix lists. This commandmakes sense in ABR only.
- OSPF Command: area a.b.c.d authentication
- OSPF Command: area <0-4294967295> authentication
- OSPF Command: no area a.b.c.d authentication
- OSPF Command: no area <0-4294967295> authentication
-
Specify that simple password authentication should be used for the givenarea.
- OSPF Command: area a.b.c.d authentication message-digest
- OSPF Command: area <0-4294967295> authentication message-digest
-
Specify that OSPF packetsmust be authenticated with MD5 HMACs within the given area. Keyingmaterial must also be configured on a per-interface basis (see ip ospf message-digest-key).
MD5 authentication may also be configured on a per-interface basis(see ip ospf authentication message-digest). Such per-interfacesettings will override any per-area authentication setting.
Next: Redistribute routes to OSPF, Previous: OSPF area, Up: OSPFv2 [Contents][Index]
7.5 OSPF interface
- Interface Command: ip ospf area AREA [ADDR]
- Interface Command: no ip ospf area [ADDR]
-
Enable OSPF on the interface, optionally restricted to just the IP addressgiven by ADDR, putting it in the AREA area. Per interface areasettings take precedence to network commands (see OSPF network command).
If you have a lot of interfaces, and/or a lot of subnets, then enabling OSPFvia this command may result in a slight performance improvement.
- Interface Command: ip ospf authentication-key AUTH_KEY
- Interface Command: no ip ospf authentication-key
-
Set OSPF authentication key to a simple password. After setting AUTH_KEY,all OSPF packets are authenticated. AUTH_KEY has length up to 8 chars.
Simple text password authentication is insecure and deprecated in favour ofMD5 HMAC authentication (see ip ospf authentication message-digest).
- Interface Command: ip ospf authentication message-digest
-
Specify that MD5 HMACauthentication must be used on this interface. MD5 keying material mustalso be configured (see ip ospf message-digest-key). Overrides anyauthentication enabled on a per-area basis (see area authentication message-digest).
Note that OSPF MD5 authentication requires that time never go backwards(correct time is NOT important, only that it never goes backwards), evenacross resets, if ospfd is to be able to promptly reestabish adjacencieswith its neighbours after restarts/reboots. The host should have systemtime be set at boot from an external or non-volatile source (eg battery backed clock, NTP,etc.) or else the system clock should be periodically saved to non-volativestorage and restored at boot if MD5 authentication is to be expected to workreliably.
- Interface Command: ip ospf message-digest-key KEYID md5 KEY
- Interface Command: no ip ospf message-digest-key
-
Set OSPF authentication key to acryptographic password. The cryptographic algorithm is MD5.
KEYID identifies secret key used to create the message digest. This IDis part of the protocol and must be consistent across routers on alink.
KEY is the actual message digest key, of up to 16 chars (larger stringswill be truncated), and is associated with the given KEYID.
- Interface Command: ip ospf cost <1-65535>
- Interface Command: no ip ospf cost
-
Set link cost for the specified interface. The cost value is set to router-LSA’smetric field and used for SPF calculation.
- Interface Command: ip ospf dead-interval <1-65535>
- Interface Command: ip ospf dead-interval minimal hello-multiplier <2-20>
- Interface Command: no ip ospf dead-interval
-
Set number of seconds forRouterDeadInterval timer value used for Wait Timer and InactivityTimer. This value must be the same for all routers attached to acommon network. The default value is 40 seconds.
If ’minimal’ is specified instead, then the dead-interval is set to 1second and one must specify a hello-multiplier. The hello-multiplierspecifies how many Hellos to send per second, from 2 (every 500ms) to20 (every 50ms). Thus one can have 1s convergence time for OSPF. If this formis specified, then the hello-interval advertised in Hello packets is set to0 and the hello-interval on received Hello packets is not checked, thus the hello-multiplier need NOT be the same across multiple routers on a commonlink.
- Interface Command: ip ospf hello-interval <1-65535>
- Interface Command: no ip ospf hello-interval
-
Set number of seconds for HelloInterval timer value. Setting this value,Hello packet will be sent every timer value seconds on the specified interface.This value must be the same for all routers attached to a common network.The default value is 10 seconds.
This command has no effect if ip ospf dead-interval minimal is also specified for the interface.
- Interface Command: ip ospf network (broadcast|non-broadcast|point-to-multipoint|point-to-point)
- Interface Command: no ip ospf network
-
Set explicitly network type for specifed interface.
- Interface Command: ip ospf priority <0-255>
- Interface Command: no ip ospf priority
-
Set RouterPriority integer value. The router with the highest prioritywill be more eligible to become Designated Router. Setting the valueto 0, makes the router ineligible to become Designated Router. Thedefault value is 1.
- Interface Command: ip ospf retransmit-interval <1-65535>
- Interface Command: no ip ospf retransmit interval
-
Set number of seconds for RxmtInterval timer value. This value is usedwhen retransmitting Database Description and Link State Request packets.The default value is 5 seconds.
- Interface Command: ip ospf transmit-delay
- Interface Command: no ip ospf transmit-delay
-
Set number of seconds for InfTransDelay value. LSAs’ age should be incremented by this value when transmitting.The default value is 1 seconds.
Next: Showing OSPF information, Previous: OSPF interface, Up: OSPFv2 [Contents][Index]
7.6 Redistribute routes to OSPF
- OSPF Command: redistribute (kernel|connected|static|rip|bgp)
- OSPF Command: redistribute (kernel|connected|static|rip|bgp) route-map
- OSPF Command: redistribute (kernel|connected|static|rip|bgp) metric-type (1|2)
- OSPF Command: redistribute (kernel|connected|static|rip|bgp) metric-type (1|2) route-map word
- OSPF Command: redistribute (kernel|connected|static|rip|bgp) metric <0-16777214>
- OSPF Command: redistribute (kernel|connected|static|rip|bgp) metric <0-16777214> route-map word
- OSPF Command: redistribute (kernel|connected|static|rip|bgp) metric-type (1|2) metric <0-16777214>
- OSPF Command: redistribute (kernel|connected|static|rip|bgp) metric-type (1|2) metric <0-16777214> route-map word
- OSPF Command: no redistribute (kernel|connected|static|rip|bgp)
-
Redistribute routes of the specified protocolor kind into OSPF, with the metric type and metric set if specified,filtering the routes using the given route-map if specified.Redistributed routes may also be filtered with distribute-lists, seeospf distribute-list.
Redistributed routes are distributed as into OSPF as Type-5 ExternalLSAs into links to areas that accept external routes, Type-7 External LSAsfor NSSA areas and are not redistributed at all into Stub areas, whereexternal routes are not permitted.
Note that for connected routes, one may instead usepassive-interface, see OSPF passive-interface.
- OSPF Command: default-information originate
- OSPF Command: default-information originate metric <0-16777214>
- OSPF Command: default-information originate metric <0-16777214> metric-type (1|2)
- OSPF Command: default-information originate metric <0-16777214> metric-type (1|2) route-map word
- OSPF Command: default-information originate always
- OSPF Command: default-information originate always metric <0-16777214>
- OSPF Command: default-information originate always metric <0-16777214> metric-type (1|2)
- OSPF Command: default-information originate always metric <0-16777214> metric-type (1|2) route-map word
- OSPF Command: no default-information originate
-
Originate an AS-External (type-5) LSA describing a default route intoall external-routing capable areas, of the specified metric and metrictype. If the ’always’ keyword is given then the default is alwaysadvertised, even when there is no default present in the routing table.
- OSPF Command: distribute-list NAME out (kernel|connected|static|rip|ospf
- OSPF Command: no distribute-list NAME out (kernel|connected|static|rip|ospf
-
Apply the access-list filter, NAME, toredistributed routes of the given type before allowing the routes toredistributed into OSPF (see OSPF redistribute).
Next: Opaque LSA, Previous: Redistribute routes to OSPF, Up: OSPFv2 [Contents][Index]
7.7 Showing OSPF information
- Command: show ip ospf
-
Show information on a variety of general OSPF andarea state and configuration information.
- Command: show ip ospf interface [INTERFACE]
-
Show state and configuration of OSPF the specified interface, or allinterfaces if no interface is given.
- Command: show ip ospf neighbor
- Command: show ip ospf neighbor INTERFACE
- Command: show ip ospf neighbor detail
- Command: show ip ospf neighbor INTERFACE detail
- Command: show ip ospf database
- Command: show ip ospf database asbr-summary
- Command: show ip ospf database external
- Command: show ip ospf database network
- Command: show ip ospf database asbr-router
- Command: show ip ospf database summary
- Command: show ip ospf database … link-state-id
- Command: show ip ospf database … link-state-id adv-router adv-router
- Command: show ip ospf database … adv-router adv-router
- Command: show ip ospf database … link-state-id self-originate
- Command: show ip ospf database … self-originate
- Command: show ip ospf route
-
Show the OSPF routing table, as determined by the most recent SPF calculation.
Next: OSPF Traffic Engineering, Previous: Showing OSPF information, Up: OSPFv2 [Contents][Index]
7.8 Opaque LSA
- OSPF Command: ospf opaque-lsa
- OSPF Command: capability opaque
- OSPF Command: no ospf opaque-lsa
- OSPF Command: no capability opaque
-
ospfdsupport Opaque LSA (RFC2370) as fondment for MPLS Traffic Engineering LSA. Prior to used MPLS TE, opaque-lsa must be enable in the configuration file. Alternate command could be "mpls-te on" (OSPF Traffic Engineering).
- Command: show ip ospf database (opaque-link|opaque-area|opaque-external)
- Command: show ip ospf database (opaque-link|opaque-area|opaque-external) link-state-id
- Command: show ip ospf database (opaque-link|opaque-area|opaque-external) link-state-id adv-router adv-router
- Command: show ip ospf database (opaque-link|opaque-area|opaque-external) adv-router adv-router
- Command: show ip ospf database (opaque-link|opaque-area|opaque-external) link-state-id self-originate
- Command: show ip ospf database (opaque-link|opaque-area|opaque-external) self-originate
-
Show Opaque LSA from the database.
Next: Router Information, Previous: Opaque LSA, Up: OSPFv2 [Contents][Index]
7.9 Traffic Engineering
- OSPF Command: mpls-te router-address <A.B.C.D>
- OSPF Command: no mpls-te
-
Configure stable IP address for MPLS-TE. This IP address is then advertise in Opaque LSA Type-10 TLV=1 (TE)option 1 (Router-Address).
- OSPF Command: mpls-te inter-as area <area-id>|as
- OSPF Command: no mpls-te inter-as
-
Enable RFC5392 suuport - Inter-AS TE v2 - to flood Traffic Engineering parameters of Inter-AS link.2 modes are supported: AREA and AS; LSA are flood in AREA <area-id> with Opaque Type-10, respectively in AS with Opaque Type-11. In all case, Opaque-LSA TLV=6.
- Command: show ip ospf mpls-te interface
- Command: show ip ospf mpls-te interface interface
-
Show MPLS Traffic Engineering parameters for all or specified interface.
Next: Debugging OSPF, Previous: OSPF Traffic Engineering, Up: OSPFv2 [Contents][Index]
7.10 Router Information
- OSPF Command: router-info [as | area <A.B.C.D>]
- OSPF Command: no router-info
-
Enable Router Information (RFC4970) LSA advertisement with AS scope (default) or Area scope floodingwhen area is specified.
- OSPF Command: pce address <A.B.C.D>
- OSPF Command: no pce address
- OSPF Command: pce domain as <0-65535>
- OSPF Command: no pce domain as <0-65535>
- OSPF Command: pce neighbor as <0-65535>
- OSPF Command: no pce neighbor as <0-65535>
- OSPF Command: pce flag BITPATTERN
- OSPF Command: no pce flag
- OSPF Command: pce scope BITPATTERN
- OSPF Command: no pce scope
-
The commands are conform to RFC 5088 and allow OSPF router announce Path Compuatation Elemenent (PCE) capabilitiesthrough the Router Information (RI) LSA. Router Information must be enable prior to this. The command set/unsetrespectively the PCE IP adress, Autonomous System (AS) numbers of controlled domains, neighbor ASs, flag and scope.For flag and scope, please refer to RFC5088 for the BITPATTERN recognition. Multiple ’pce neighbor’ command couldbe specified in order to specify all PCE neighbours.
Next: OSPF Configuration Examples, Previous: Router Information, Up: OSPFv2 [Contents][Index]
7.11 Debugging OSPF
- Command: debug ospf packet (hello|dd|ls-request|ls-update|ls-ack|all) (send|recv) [detail]
- Command: no debug ospf packet (hello|dd|ls-request|ls-update|ls-ack|all) (send|recv) [detail]
-
Dump Packet for debugging
- Command: debug ospf ism
- Command: debug ospf ism (status|events|timers)
- Command: no debug ospf ism
- Command: no debug ospf ism (status|events|timers)
-
Show debug information of Interface State Machine
- Command: debug ospf nsm
- Command: debug ospf nsm (status|events|timers)
- Command: no debug ospf nsm
- Command: no debug ospf nsm (status|events|timers)
-
Show debug information of Network State Machine
- Command: debug ospf lsa
- Command: debug ospf lsa (generate|flooding|refresh)
- Command: no debug ospf lsa
- Command: no debug ospf lsa (generate|flooding|refresh)
-
Show debug detail of Link State messages
- Command: debug ospf te
- Command: no debug ospf te
-
Show debug information about Traffic Engineering LSA
- Command: debug ospf zebra
- Command: debug ospf zebra (interface|redistribute)
- Command: no debug ospf zebra
- Command: no debug ospf zebra (interface|redistribute)
-
Show debug information of ZEBRA API
Previous: Debugging OSPF, Up: OSPFv2 [Contents][Index]
7.12 OSPF Configuration Examples
A simple example, with MD5 authentication enabled:
! interface bge0 ip ospf authentication message-digest ip ospf message-digest-key 1 md5 ABCDEFGHIJK ! router ospf network 192.168.0.0/16 area 0.0.0.1 area 0.0.0.1 authentication message-digest
An ABR router, with MD5 authentication and performing summarisationof networks between the areas:
! password ABCDEF log file /var/log/quagga/ospfd.log service advanced-vty ! interface eth0 ip ospf authentication message-digest ip ospf message-digest-key 1 md5 ABCDEFGHIJK ! interface ppp0 ! interface br0 ip ospf authentication message-digest ip ospf message-digest-key 2 md5 XYZ12345 ! router ospf ospf router-id 192.168.0.1 redistribute connected passive interface ppp0 network 192.168.0.0/24 area 0.0.0.0 network 10.0.0.0/16 area 0.0.0.0 network 192.168.1.0/24 area 0.0.0.1 area 0.0.0.0 authentication message-digest area 0.0.0.0 range 10.0.0.0/16 area 0.0.0.0 range 192.168.0.0/24 area 0.0.0.1 authentication message-digest area 0.0.0.1 range 10.2.0.0/16 !
A Traffic Engineering configuration, with Inter-ASv2 support.
- First, the ’zebra.conf’ part:
hostname HOSTNAME password PASSWORD log file /var/log/zebra.log ! interface eth0 ip address 198.168.1.1/24 mpls-te on mpls-te link metric 10 mpls-te link max-bw 1.25e+06 mpls-te link max-rsv-bw 1.25e+06 mpls-te link unrsv-bw 0 1.25e+06 mpls-te link unrsv-bw 1 1.25e+06 mpls-te link unrsv-bw 2 1.25e+06 mpls-te link unrsv-bw 3 1.25e+06 mpls-te link unrsv-bw 4 1.25e+06 mpls-te link unrsv-bw 5 1.25e+06 mpls-te link unrsv-bw 6 1.25e+06 mpls-te link unrsv-bw 7 1.25e+06 mpls-te link rsc-clsclr 0xab ! interface eth1 ip address 192.168.2.1/24 mpls-te on mpls-te link metric 10 mpls-te link max-bw 1.25e+06 mpls-te link max-rsv-bw 1.25e+06 mpls-te link unrsv-bw 0 1.25e+06 mpls-te link unrsv-bw 1 1.25e+06 mpls-te link unrsv-bw 2 1.25e+06 mpls-te link unrsv-bw 3 1.25e+06 mpls-te link unrsv-bw 4 1.25e+06 mpls-te link unrsv-bw 5 1.25e+06 mpls-te link unrsv-bw 6 1.25e+06 mpls-te link unrsv-bw 7 1.25e+06 mpls-te link rsc-clsclr 0xab mpls-te neighbor 192.168.2.2 as 65000
- Then the ’ospfd.conf’ itself:
hostname HOSTNAME password PASSWORD log file /var/log/ospfd.log ! ! interface eth0 ip ospf hello-interval 60 ip ospf dead-interval 240 ! interface eth1 ip ospf hello-interval 60 ip ospf dead-interval 240 ! ! router ospf ospf router-id 192.168.1.1 network 192.168.0.0/16 area 1 ospf opaque-lsa mpls-te mpls-te router-address 192.168.1.1 mpls-te inter-as area 1 ! line vty
A router information example with PCE advsertisement:
! router ospf ospf router-id 192.168.1.1 network 192.168.0.0/16 area 1 capability opaque mpls-te mpls-te router-address 192.168.1.1 router-info area 0.0.0.1 pce address 192.168.1.1 pce flag 0x80 pce domain as 65400 pce neighbor as 65500 pce neighbor as 65200 pce scope 0x80 !
8 OSPFv3
ospf6d is a daemon support OSPF version 3 for IPv6 network.OSPF for IPv6 is described in RFC2740.
| • OSPF6 router: | ||
| • OSPF6 area: | ||
| • OSPF6 interface: | ||
| • Redistribute routes to OSPF6: | ||
| • Showing OSPF6 information: | ||
| • OSPF6 Configuration Examples: |
Next: OSPF6 area, Up: OSPFv3 [Contents][Index]
8.1 OSPF6 router
- OSPF6 Command: interface ifname area area
-
Bind interface to specified area, and start sending OSPF packets. area canbe specified as 0.
- OSPF6 Command: timers throttle spf delay initial-holdtime max-holdtime
- OSPF6 Command: no timers throttle spf
-
This command sets the initial delay, the initial-holdtimeand the maximum-holdtime between when SPF is calculated and theevent which triggered the calculation. The times are specified inmilliseconds and must be in the range of 0 to 600000 milliseconds.
The delay specifies the minimum amount of time to delay SPFcalculation (hence it affects how long SPF calculation is delayed afteran event which occurs outside of the holdtime of any previous SPFcalculation, and also serves as a minimum holdtime).
Consecutive SPF calculations will always be seperated by at least’hold-time’ milliseconds. The hold-time is adaptive and initially isset to the initial-holdtime configured with the above command.Events which occur within the holdtime of the previous SPF calculationwill cause the holdtime to be increased by initial-holdtime, boundedby the maximum-holdtime configured with this command. If the adaptivehold-time elapses without any SPF-triggering event occuring thenthe current holdtime is reset to the initial-holdtime.
router ospf6 timers throttle spf 200 400 10000
In this example, the delay is set to 200ms, the initialholdtime is set to 400ms and the maximum holdtime to 10s. Hencethere will always be at least 200ms between an event which requires SPFcalculation and the actual SPF calculation. Further consecutive SPFcalculations will always be seperated by between 400ms to 10s, thehold-time increasing by 400ms each time an SPF-triggering event occurswithin the hold-time of the previous SPF calculation.
- OSPF6 Command: auto-cost reference-bandwidth cost
- OSPF6 Command: no auto-cost reference-bandwidth
-
This sets the reference bandwidth for cost calculations, where thisbandwidth is considered equivalent to an OSPF cost of 1, specified inMbits/s. The default is 100Mbit/s (i.e. a link of bandwidth 100Mbit/sor higher will have a cost of 1. Cost of lower bandwidth links will bescaled with reference to this cost).
This configuration setting MUST be consistent across all routerswithin the OSPF domain.
Next: OSPF6 interface, Previous: OSPF6 router, Up: OSPFv3 [Contents][Index]
8.2 OSPF6 area
Area support for OSPFv3 is not yet implemented.
Next: Redistribute routes to OSPF6, Previous: OSPF6 area, Up: OSPFv3 [Contents][Index]
8.3 OSPF6 interface
- Interface Command: ipv6 ospf6 cost COST
-
Sets interface’s output cost. Default value depends on the interfacebandwidth and on the auto-cost reference bandwidth.
- Interface Command: ipv6 ospf6 hello-interval HELLOINTERVAL
-
Sets interface’s Hello Interval. Default 40
- Interface Command: ipv6 ospf6 dead-interval DEADINTERVAL
-
Sets interface’s Router Dead Interval. Default value is 40.
- Interface Command: ipv6 ospf6 retransmit-interval RETRANSMITINTERVAL
-
Sets interface’s Rxmt Interval. Default value is 5.
- Interface Command: ipv6 ospf6 priority PRIORITY
-
Sets interface’s Router Priority. Default value is 1.
- Interface Command: ipv6 ospf6 transmit-delay TRANSMITDELAY
-
Sets interface’s Inf-Trans-Delay. Default value is 1.
- Interface Command: ipv6 ospf6 network (broadcast|point-to-point)
-
Set explicitly network type for specifed interface.
Next: Showing OSPF6 information, Previous: OSPF6 interface, Up: OSPFv3 [Contents][Index]
8.4 Redistribute routes to OSPF6
- OSPF6 Command: redistribute static
- OSPF6 Command: redistribute connected
- OSPF6 Command: redistribute ripng
Next: OSPF6 Configuration Examples, Previous: Redistribute routes to OSPF6, Up: OSPFv3 [Contents][Index]
8.5 Showing OSPF6 information
- Command: show ipv6 ospf6 [INSTANCE_ID]
-
INSTANCE_ID is an optional OSPF instance ID. To see router ID and OSPFinstance ID, simply type "show ipv6 ospf6 <cr>".
- Command: show ipv6 ospf6 database
-
This command shows LSA database summary. You can specify the type of LSA.
Previous: Showing OSPF6 information, Up: OSPFv3 [Contents][Index]
8.6 OSPF6 Configuration Examples
Example of ospf6d configured on one interface and area:
interface eth0 ipv6 ospf6 instance-id 0 ! router ospf6 router-id 212.17.55.53 area 0.0.0.0 range 2001:770:105:2::/64 interface eth0 area 0.0.0.0 !
9 ISIS
ISIS (Intermediate System to Intermediate System) is a routing protocolwhich is described in ISO10589, RFC1195, RFC5308. ISIS is anIGP (Interior Gateway Protocol). Compared with RIP,ISIS can provide scalable network support and fasterconvergence times like OSPF. ISIS is widely used in large networks such asISP (Internet Service Provider) and carrier backbone networks.
| • Configuring isisd: | ||
| • ISIS router: | ||
| • ISIS Timer: | ||
| • ISIS region: | ||
| • ISIS interface: | ||
| • Showing ISIS information: | ||
| • ISIS Traffic Engineering: | ||
| • Debugging ISIS: | ||
| • ISIS Configuration Examples: |
Next: ISIS router, Up: ISIS [Contents][Index]
9.1 Configuring isisd
There are no isisd specific options. Common options can bespecified (see
Common Invocation Options) to isisd.isisd needs to acquire interface information fromzebra in order to function. Therefore
zebra must berunning before invoking isisd. Also, if
zebra isrestarted then isisd must be too.
Like other daemons, isisd configuration is done in
ISISspecific configuration file isisd.conf.
Next: ISIS Timer, Previous: Configuring isisd, Up: ISIS [Contents][Index]
9.2 ISIS router
To start ISIS process you have to specify the ISIS router. As of thiswriting,
isisd does not support multiple ISIS processes.
- Command: router isis WORD
- Command: no router isis WORD
-
Enable or disable the ISIS process by specifying the ISIS domain with ’WORD’.
isisddoes not yet support multiple ISIS processes but you must specifythe name of ISIS process. The ISIS process name ’WORD’ is then used for interface(see command ip router isis WORD).
- ISIS Command: net XX.XXXX. ... .XXX.XX
- ISIS Command: no net XX.XXXX. ... .XXX.XX
-
Set/Unset network entity title (NET) provided in ISO format.
- ISIS Command: hostname dynamic
- ISIS Command: no hostname dynamic
-
Enable support for dynamic hostname.
- ISIS Command: area-password [clear | md5] <password>
- ISIS Command: domain-password [clear | md5] <password>
- ISIS Command: no area-password
- ISIS Command: no domain-password
-
Configure the authentication password for an area, respectively a domain,as clear text or md5 one.
- ISIS Command: log-adjacency-changes
- ISIS Command: no log-adjacency-changes
-
Log changes in adjacency state.
- ISIS Command: metric-style [narrow | transition | wide]
- ISIS Command: no metric-style
-
Set old-style (ISO 10589) or new-style packet formats: - narrow Use old style of TLVs with narrow metric - transition Send and accept both styles of TLVs during transition - wide Use new style of TLVs to carry wider metric
- ISIS Command: set-overload-bit
- ISIS Command: no set-overload-bit
-
Set overload bit to avoid any transit traffic.
Next: ISIS region, Previous: ISIS router, Up: ISIS [Contents][Index]
9.3 ISIS Timer
- ISIS Command: lsp-gen-interval <1-120>
- ISIS Command: lsp-gen-interval [level-1 | level-2] <1-120>
- ISIS Command: no lsp-gen-interval
- ISIS Command: no lsp-gen-interval [level-1 | level-2]
-
Set minimum interval in seconds between regenerating same LSP,globally, for an area (level-1) or a domain (level-2).
- ISIS Command: lsp-refresh-interval <1-65235>
- ISIS Command: lsp-refresh-interval [level-1 | level-2] <1-65235>
- ISIS Command: no lsp-refresh-interval
- ISIS Command: no lsp-refresh-interval [level-1 | level-2]
-
Set LSP refresh interval in seconds, globally, for an area (level-1) or a domain (level-2).
- ISIS Command: lsp-refresh-interval <1-65235>
- ISIS Command: lsp-refresh-interval [level-1 | level-2] <1-65235>
- ISIS Command: no lsp-refresh-interval
- ISIS Command: no lsp-refresh-interval [level-1 | level-2]
-
Set LSP refresh interval in seconds, globally, for an area (level-1) or a domain (level-2).
- ISIS Command: max-lsp-lifetime <360-65535>
- ISIS Command: max-lsp-lifetime [level-1 | level-2] <360-65535>
- ISIS Command: no max-lsp-lifetime
- ISIS Command: no max-lsp-lifetime [level-1 | level-2]
-
Set LSP maximum LSP lifetime in seconds, globally, for an area (level-1) or a domain (level-2).
- ISIS Command: spf-interval <1-120>
- ISIS Command: spf-interval [level-1 | level-2] <1-120>
- ISIS Command: no spf-interval
- ISIS Command: no spf-interval [level-1 | level-2]
-
Set minimum interval between consecutive SPF calculations in seconds.
Next: ISIS interface, Previous: ISIS Timer, Up: ISIS [Contents][Index]
9.4 ISIS region
- ISIS Command: is-type [level-1 | level-1-2 | level-2-only]
- ISIS Command: no is-type
-
Define the ISIS router behavior: - level-1 Act as a station router only - level-1-2 Act as both a station router and an area router - level-2-only Act as an area router only
Next: Showing ISIS information, Previous: ISIS region, Up: ISIS [Contents][Index]
9.5 ISIS interface
- Interface Command: ip router isis WORD
- Interface Command: no ip router isis WORD
-
Activate ISIS adjacency on this interface. Note that the nameof ISIS instance must be the same as the one used to configure the ISIS process(see command router isis WORD).
- Interface Command: isis circuit-type [level-1 | level-1-2 | level-2]
- Interface Command: no isis circuit-type
-
Configure circuit type for interface: - level-1 Level-1 only adjacencies are formed - level-1-2 Level-1-2 adjacencies are formed - level-2-only Level-2 only adjacencies are formed
- Interface Command: isis csnp-interval <1-600>
- Interface Command: isis csnp-interval <1-600> [level-1 | level-2]
- Interface Command: no isis csnp-interval
- Interface Command: no isis csnp-interval [level-1 | level-2]
-
Set CSNP interval in seconds globally, for an area (level-1) or a domain (level-2).
- Interface Command: isis hello-interval <1-600>
- Interface Command: isis hello-interval <1-600> [level-1 | level-2]
- Interface Command: no isis hello-interval
- Interface Command: no isis hello-interval [level-1 | level-2]
-
Set Hello interval in seconds globally, for an area (level-1) or a domain (level-2).
- Interface Command: isis hello-multiplier <2-100>
- Interface Command: isis hello-multiplier <2-100> [level-1 | level-2]
- Interface Command: no isis hello-multiplier
- Interface Command: no isis hello-multiplier [level-1 | level-2]
-
Set multiplier for Hello holding time globally, for an area (level-1) or a domain (level-2).
- Interface Command: isis metric [<0-255> | <0-16777215>]
- Interface Command: isis metric [<0-255> | <0-16777215>] [level-1 | level-2]
- Interface Command: no isis metric
- Interface Command: no isis metric [level-1 | level-2]
-
Set default metric value globally, for an area (level-1) or a domain (level-2).Max value depend if metric support narrow or wide value (see command metric-style).
- Interface Command: isis network point-to-point
- Interface Command: no isis network point-to-point
-
Set network type to ’Point-to-Point’ (broadcast by default).
- Interface Command: isis passive
- Interface Command: no isis passive
-
Configure the passive mode for this interface.
- Interface Command: isis password [clear | md5] <password>
- Interface Command: no isis password
-
Configure the authentication password (clear or encoded text) for the interface.
- Interface Command: isis priority <0-127>
- Interface Command: isis priority <0-127> [level-1 | level-2]
- Interface Command: no isis priority
- Interface Command: no isis priority [level-1 | level-2]
-
Set priority for Designated Router election, globally, for the area (level-1)or the domain (level-2).
- Interface Command: isis psnp-interval <1-120>
- Interface Command: isis psnp-interval <1-120> [level-1 | level-2]
- Interface Command: no isis psnp-interval
- Interface Command: no isis psnp-interval [level-1 | level-2]
-
Set PSNP interval in seconds globally, for an area (level-1) or a domain (level-2).
Next: ISIS Traffic Engineering, Previous: ISIS interface, Up: ISIS [Contents][Index]
9.6 Showing ISIS information
- Command: show isis interface
- Command: show isis interface detail
- Command: show isis interface <interface name>
-
Show state and configuration of ISIS specified interface, or allinterfaces if no interface is given with or without details.
- Command: show isis neighbor
- Command: show isis neighbor <System Id>
- Command: show isis neighbor detail
-
Show state and information of ISIS specified neighbor, or allneighbors if no system id is given with or without details.
- Command: show isis database
- Command: show isis database [detail]
- Command: show isis database <LSP id> [detail]
- Command: show isis database detail <LSP id>
-
Show the ISIS database globally, for a specific LSP id without or with details.
- Command: show isis topology
- Command: show isis topology [level-1|level-2]
-
Show topology IS-IS paths to Intermediate Systems, globally,in area (level-1) or domain (level-2).
- Command: show ip route isis
-
Show the ISIS routing table, as determined by the most recent SPF calculation.
Next: Debugging ISIS, Previous: Showing ISIS information, Up: ISIS [Contents][Index]
9.7 Traffic Engineering
- ISIS Command: mpls-te router-address <A.B.C.D>
- ISIS Command: no mpls-te router-address
-
Configure stable IP address for MPLS-TE.
- Command: show isis mpls-te interface
- Command: show isis mpls-te interface interface
-
Show MPLS Traffic Engineering parameters for all or specified interface.
Next: ISIS Configuration Examples, Previous: ISIS Traffic Engineering, Up: ISIS [Contents][Index]
9.8 Debugging ISIS
- Command: debug isis checksum-errors
- Command: no debug isis checksum-errors
-
IS-IS LSP checksum errors.
- Command: debug isis protocol-errors
- Command: no debug isis protocol-errors
-
IS-IS LSP protocol errors.
- Command: debug isis spf-events
- Command: debug isis spf-statistics
- Command: debug isis spf-triggers
- Command: no debug isis spf-events
- Command: no debug isis spf-statistics
- Command: no debug isis spf-triggers
-
IS-IS Shortest Path First Events, Timing and Statistic Dataand triggering events.
Previous: Debugging ISIS, Up: ISIS [Contents][Index]
9.9 ISIS Configuration Examples
A simple example, with MD5 authentication enabled:
! interface eth0 ip router isis FOO isis network point-to-point isis circuit-type level-2-only ! router isis FOO net 47.0023.0000.0000.0000.0000.0000.0000.1900.0004.00 metric-style wide is-type level-2-only
A Traffic Engineering configuration, with Inter-ASv2 support.
- First, the ’zebra.conf’ part:
hostname HOSTNAME password PASSWORD log file /var/log/zebra.log ! interface eth0 ip address 10.2.2.2/24 mpls-te on mpls-te link metric 10 mpls-te link max-bw 1.25e+06 mpls-te link max-rsv-bw 1.25e+06 mpls-te link unrsv-bw 0 1.25e+06 mpls-te link unrsv-bw 1 1.25e+06 mpls-te link unrsv-bw 2 1.25e+06 mpls-te link unrsv-bw 3 1.25e+06 mpls-te link unrsv-bw 4 1.25e+06 mpls-te link unrsv-bw 5 1.25e+06 mpls-te link unrsv-bw 6 1.25e+06 mpls-te link unrsv-bw 7 1.25e+06 mpls-te link rsc-clsclr 0xab ! interface eth1 ip address 10.1.1.1/24 mpls-te on mpls-te link metric 10 mpls-te link max-bw 1.25e+06 mpls-te link max-rsv-bw 1.25e+06 mpls-te link unrsv-bw 0 1.25e+06 mpls-te link unrsv-bw 1 1.25e+06 mpls-te link unrsv-bw 2 1.25e+06 mpls-te link unrsv-bw 3 1.25e+06 mpls-te link unrsv-bw 4 1.25e+06 mpls-te link unrsv-bw 5 1.25e+06 mpls-te link unrsv-bw 6 1.25e+06 mpls-te link unrsv-bw 7 1.25e+06 mpls-te link rsc-clsclr 0xab mpls-te neighbor 10.1.1.2 as 65000
- Then the ’isisd.conf’ itself:
hostname HOSTNAME password PASSWORD log file /var/log/isisd.log ! ! interface eth0 ip router isis FOO ! interface eth1 ip router isis FOO ! ! router isis FOO isis net 47.0023.0000.0000.0000.0000.0000.0000.1900.0004.00 mpls-te on mpls-te router-address 10.1.1.1 ! line vty
10 NHRP
nhrpd is a daemon to support Next Hop Routing Protocol (NHRP).NHRP is described in RFC2332.
NHRP is used to improve the efficiency of routing computer networktraffic over Non-Broadcast, Multiple Access (NBMA) Networks. NHRP providesan ARP-like solution that allows a system to dynamically learn the NBMAaddress of the other systems that are part of that network, allowingthese systems to directly communicate without requiring traffic to usean intermediate hop.
Cisco Dynamic Multipoint VPN (DMVPN) is based on NHRP, and Quagga nrhpdimplements this scenario.
| • Routing Design: | ||
| • Configuring NHRP: | ||
| • Hub Functionality: | ||
| • Integration with IKE: | ||
| • NHRP Events: | ||
| • Configuration Example: |
Next: Configuring NHRP, Up: NHRP [Contents][Index]
10.1 Routing Design
nhrpd never handles routing of prefixes itself. You need to run somereal routing protocol (e.g. BGP) to advertise routes over the tunnels.What nhrpd does it establishes ’shortcut routes’ that optimizes therouting protocol to avoid going through extra nodes in NBMA GRE mesh.
nhrpd does route NHRP domain addresses individually using per-host prefixes.This is similar to Cisco FlexVPN; but in contrast to opennhrp which usesa generic subnet route.
To create NBMA GRE tunnel you might use the following (linux terminalcommands):
ip tunnel add gre1 mode gre key 42 ttl 64 ip addr add 10.255.255.2/32 dev gre1 ip link set gre1 up
Note that the IP-address is assigned as host prefix to gre1. nhrpd willautomatically create additional host routes pointing to gre1 whena connection with these hosts is established.
The gre1 subnet prefix should be announced by routing protocol from thehub nodes (e.g. BGP ’network’ announce). This allows the routing protocolto decide which is the closest hub and determine the relay hub on prefixbasis when direct tunnel is not established.
nhrpd will redistribute directly connected neighbors to zebra. Withinhub nodes, these routes should be internally redistributed using somerouting protocol (e.g. iBGP) to allow hubs to be able to relay all traffic.
This can be achieved in hubs with the following bgp configuration (networkcommand defines the GRE subnet):
router bgp 65555 network 172.16.0.0/16 redistribute nhrp
Next: Hub Functionality, Previous: Routing Design, Up: NHRP [Contents][Index]
10.2 Configuring NHRP
FIXME
Next: Integration with IKE, Previous: Configuring NHRP, Up: NHRP [Contents][Index]
10.3 Hub Functionality
In addition to routing nhrp redistributed host prefixes, the hub nodesare also responsible to send NHRP Traffic Indication messages thattrigger creation of the shortcut tunnels.
nhrpd sends Traffic Indication messages based on network traffic capturedusing NFLOG. Typically you want to send Traffic Indications for networktraffic that is routed from gre1 back to gre1 in rate limited manner.This can be achieved with the following iptables rule.
iptables -A FORWARD -i gre1 -o gre1 \ -m hashlimit --hashlimit-upto 4/minute --hashlimit-burst 1 \ --hashlimit-mode srcip,dstip --hashlimit-srcmask 24 \ --hashlimit-dstmask 24 --hashlimit-name loglimit-0 \ -j NFLOG --nflog-group 1 --nflog-range 128
You can fine tune the src/dstmask according to the prefix lengths youannounce internal, add additional IP range matches, or rate limitationif needed. However, the above should be good in most cases.
This kernel NFLOG target’s nflog-group is configured in global nhrp configwith:
nhrp nflog-group 1
To start sending these traffic notices out from hubs, use the nhrpper-interface directive:
interface gre1 ip nhrp redirect
Next: NHRP Events, Previous: Hub Functionality, Up: NHRP [Contents][Index]
10.4 Integration with IKE
nhrpd needs tight integration with IKE daemon for various reasons.Currently only strongSwan is supported as IKE daemon.
nhrpd connects to strongSwan using VICI protocol based on UNIX socket(hardcoded now as /var/run/charon.vici).
strongSwan currently needs few patches applied. Please check out thereleaseandworking treegit repositories for the patches.
Next: Configuration Example, Previous: Integration with IKE, Up: NHRP [Contents][Index]
10.5 NHRP Events
FIXME
Previous: NHRP Events, Up: NHRP [Contents][Index]
10.6 Configuration Example
FIXME
Next: Configuring Quagga as a Route Server, Previous: NHRP, Up: Top [Contents][Index]
11 BGP
BGP stands for a Border Gateway Protocol. The lastest BGP versionis 4. It is referred as BGP-4. BGP-4 is one of the Exterior GatewayProtocols and de-fact standard of Inter Domain routing protocol.BGP-4 is described in RFC1771, A Border Gateway Protocol4 (BGP-4).
Many extensions have been added to RFC1771. RFC2858,Multiprotocol Extensions for BGP-4 provides multiprotocol support toBGP-4.
Next: BGP router, Up: BGP [Contents][Index]
11.1 Starting BGP
Default configuration file of bgpd is bgpd.conf.bgpd searches the current directory first then/etc/quagga/bgpd.conf. All of bgpd’s command must beconfigured in
bgpd.conf.
bgpd specific invocation options are described below. Commonoptions may also be specified (see
Common Invocation Options).
- ‘-p PORT’
- ‘--bgp_port=PORT’
-
Set the bgp protocol’s port number.
- ‘-r’
- ‘--retain’
-
When program terminates, retain BGP routes added by zebra.
- ‘-l’
- ‘--listenon’
-
Specify a specific IP address for bgpd to listen on, rather than its default of INADDR_ANY / IN6ADDR_ANY. This can be useful to constrain bgpdto an internal address, or to run multiple bgpd processes on one host.
Next: BGP MED, Previous: Starting BGP, Up: BGP [Contents][Index]
11.2 BGP router
First of all you must configure BGP router with router bgpcommand. To configure BGP router, you need AS number. AS number is anidentification of autonomous system. BGP protocol uses the AS numberfor detecting whether the BGP connection is internal
one or external one.
- Command: router bgp asn
-
Enable a BGP protocol process with the specified asn. Afterthis statement you can input any
BGP Commands. You can notcreate different BGP process under different asn withoutspecifyingmultiple-instance(see Multiple instance).
- BGP: bgp router-id A.B.C.D
-
This command specifies the router-ID. If
bgpdconnects tozebrait getsinterface and address information. In that case default router ID valueis selected as the largest IP Address of the interfaces. Whenrouter zebrais not enabledbgpdcan’t get interface informationsorouter-idis set to 0.0.0.0. So please set router-id by hand.
Next: BGP decision process, Up: BGP router [Contents][Index]
11.2.1 BGP distance
- BGP: distance bgp <1-255> <1-255> <1-255>
-
This command change distance value of BGP. Each argument is distancevalue for external routes, internal routes and local routes.
- BGP: distance <1-255> A.B.C.D/M
- BGP: distance <1-255> A.B.C.D/M word
-
This command set distance value to
Next: BGP route flap dampening, Previous: BGP distance, Up: BGP router [Contents][Index]
11.2.2 BGP decision process
The decision process Quagga BGP uses to select routes is as follows:
- 1. Weight check
-
prefer higher local weight routes to lower routes.
- 2. Local preference check
-
prefer higher local preference routes to lower.
- 3. Local route check
-
Prefer local routes (statics, aggregates, redistributed) to received routes.
- 4. AS path length check
-
Prefer shortest hop-count AS_PATHs.
- 5. Origin check
-
Prefer the lowest origin type route. That is, prefer IGP origin routes toEGP, to Incomplete routes.
- 6. MED check
-
Where routes with a MED were received from the same AS,prefer the route with the lowest MED. See BGP MED.
- 7. External check
-
Prefer the route received from an external, eBGP peerover routes received from other types of peers.
- 8. IGP cost check
-
Prefer the route with the lower IGP cost.
- 9. Multi-path check
-
If multi-pathing is enabled, then check whetherthe routes not yet distinguished in preference may be considered equal. Ifbgp bestpath as-path multipath-relax is set, all such routes areconsidered equal, otherwise routes received via iBGP with identical AS_PATHsor routes received from eBGP neighbours in the same AS are considered equal.
- 10 Already-selected external check
-
Where both routes were received from eBGP peers, then prefer the route whichis already selected. Note that this check is not applied if bgp bestpath compare-routerid is configured. This check can prevent some casesof oscillation.
- 11. Router-ID check
-
Prefer the route with the lowest router-ID. If theroute has an ORIGINATOR_ID attribute, through iBGP reflection, then thatrouter ID is used, otherwise the router-ID of the peer the route wasreceived from is used.
- 12. Cluster-List length check
-
The route with the shortest cluster-listlength is used. The cluster-list reflects the iBGP reflection path theroute has taken.
- 13. Peer address
-
Prefer the route received from the peer with the highertransport layer address, as a last-resort tie-breaker.
- BGP: bgp bestpath as-path confed
-
This command specifies that the length of confederation path sets andsequences should should be taken into account during the BGP best pathdecision process.
- BGP: bgp bestpath as-path multipath-relax
-
This command specifies that BGP decision process should consider pathsof equal AS_PATH length candidates for multipath computation. Withoutthe knob, the entire AS_PATH must match for multipath computation.
- BGP: bgp bestpath compare-routerid
-
Ensure that when comparing routes where both are equal on most metrics,including local-pref, AS_PATH length, IGP cost, MED, that the tie is brokenbased on router-ID.
If this option is enabled, then the already-selected check, wherealready selected eBGP routes are preferred, is skipped.
If a route has an ORIGINATOR_ID attribute because it has been reflected,that ORIGINATOR_ID will be used. Otherwise, the router-ID of the peer theroute was received from will be used.
The advantage of this is that the route-selection (at this point) will bemore deterministic. The disadvantage is that a few or even one lowest-IDrouter may attract all trafic to otherwise-equal paths because of thischeck. It may increase the possibility of MED or IGP oscillation, unlessother measures were taken to avoid these. The exact behaviour will besensitive to the iBGP and reflection topology.
Previous: BGP decision process, Up: BGP router [Contents][Index]
11.2.3 BGP route flap dampening
- BGP: bgp dampening <1-45> <1-20000> <1-20000> <1-255>
-
This command enables BGP route-flap dampening and specifies dampening parameters.
- half-life
-
Half-life time for the penalty
- reuse-threshold
-
Value to start reusing a route
- suppress-threshold
-
Value to start suppressing a route
- max-suppress
-
Maximum duration to suppress a stable route
The route-flap damping algorithm is compatible with RFC2439. The use of this commandis not recommended nowadays, see RIPE-378.
Next: BGP network, Previous: BGP router, Up: BGP [Contents][Index]
11.3 BGP MED
The BGP MED (Multi_Exit_Discriminator) attribute has properties which cancause subtle convergence problems in BGP. These properties and problemshave proven to be hard to understand, at least historically, and may stillnot be widely understood. The following attempts to collect together andpresent what is known about MED, to help operators and Quagga users indesigning and configuring their networks.
The BGP MED (Multi_Exit_Discriminator) attribute is intended toallow one AS to indicate its preferences for its ingress points to anotherAS. The MED attribute will not be propagated on to another AS by thereceiving AS - it is ‘non-transitive’ in the BGP sense.
E.g., if AS X and AS Y have 2 different BGP peering points, then AS Xmight set a MED of 100 on routes advertised at one and a MED of 200 at theother. When AS Y selects between otherwise equal routes to or viaAS X, AS Y should prefer to take the path via the lower MED peering of 100 withAS X. Setting the MED allows an AS to influence the routing taken to itwithin another, neighbouring AS.
In this use of MED it is not really meaningful to compare the MED value onroutes where the next AS on the paths differs. E.g., if AS Y also had aroute for some destination via AS Z in addition to the routes from AS X, andAS Z had also set a MED, it wouldn’t make sense for AS Y to compare AS Z’sMED values to those of AS X. The MED values have been set by differentadministrators, with different frames of reference.
The default behaviour of BGP therefore is to not compare MED values acrossroutes received from different neighbouring ASes. In Quagga this is done bycomparing the neighbouring, left-most AS in the received AS_PATHs of theroutes and only comparing MED if those are the same.
Unfortunately, this behaviour of MED, of sometimes being compared acrossroutes and sometimes not, depending on the properties of those other routes,means MED can cause the order of preference over all the routes to beundefined. That is, given routes A, B, and C, if A is preferred to B, and Bis preferred to C, then a well-defined order should mean the preference istransitive (in the sense of orders 2) and that A would be preferred to C.
However, when MED is involved this need not be the case. With MED it ispossible that C is actually preferred over A. So A is preferred to B, B ispreferred to C, but C is preferred to A. This can be true even where BGPdefines a deterministic “most preferred” route out of the full set ofA,B,C. With MED, for any given set of routes there may be adeterministically preferred route, but there need not be any way to arrangethem into any order of preference. With unmodified MED, the order ofpreference of routes literally becomes undefined.
That MED can induce non-transitive preferences over routes can cause issues. Firstly, it may be perceived to cause routing table churn locally atspeakers; secondly, and more seriously, it may cause routing instability iniBGP topologies, where sets of speakers continually oscillate betweendifferent paths.
The first issue arises from how speakers often implement routing decisions. Though BGP defines a selection process that will deterministically selectthe same route as best at any given speaker, even with MED, that processrequires evaluating all routes together. For performance and ease ofimplementation reasons, many implementations evaluate route preferences in apair-wise fashion instead. Given there is no well-defined order when MED isinvolved, the best route that will be chosen becomes subject toimplementation details, such as the order the routes are stored in. Thatmay be (locally) non-deterministic, e.g. it may be the order the routeswere received in.
This indeterminism may be considered undesirable, though it need not causeproblems. It may mean additional routing churn is perceived, as sometimesmore updates may be produced than at other times in reaction to some event .
This first issue can be fixed with a more deterministic route selection thatensures routes are ordered by the neighbouring AS during selection. See bgp deterministic-med. This may reduce the number of updates asroutes are received, and may in some cases reduce routing churn. Though, itcould equally deterministically produce the largest possible set of updatesin response to the most common sequence of received updates.
A deterministic order of evaluation tends to imply an additional overhead ofsorting over any set of n routes to a destination. The implementation ofdeterministic MED in Quagga scales significantly worse than most sortingalgorithms at present, with the number of paths to a given destination. That number is often low enough to not cause any issues, but where there aremany paths, the deterministic comparison may quickly become increasinglyexpensive in terms of CPU.
Deterministic local evaluation can not fix the second, more major,issue of MED however. Which is that the non-transitive preference of routesMED can cause may lead to routing instability or oscillation across multiplespeakers in iBGP topologies. This can occur with full-mesh iBGP, but isparticularly problematic in non-full-mesh iBGP topologies that furtherreduce the routing information known to each speaker. This has primarilybeen documented with iBGP route-reflection topologies. However, anyroute-hiding technologies potentially could also exacerbate oscillation withMED.
This second issue occurs where speakers each have only a subset of routes,and there are cycles in the preferences between different combinations ofroutes - as the undefined order of preference of MED allows - and the routesare distributed in a way that causes the BGP speakers to ’chase’ thosecycles. This can occur even if all speakers use a deterministic order ofevaluation in route selection.
E.g., speaker 4 in AS A might receive a route from speaker 2 in AS X, andfrom speaker 3 in AS Y; while speaker 5 in AS A might receive that routefrom speaker 1 in AS Y. AS Y might set a MED of 200 at speaker 1, and 100at speaker 3. I.e, using ASN:ID:MED to label the speakers:
/---------------\
X:2------|--A:4-------A:5--|-Y:1:200
Y:3:100--|-/ |
\---------------/
Assuming all other metrics are equal (AS_PATH, ORIGIN, 0 IGP costs), thenbased on the RFC4271 decision process speaker 4 will choose X:2 overY:3:100, based on the lower ID of 2. Speaker 4 advertises X:2 to speaker 5. Speaker 5 will continue to prefer Y:1:200 based on the ID, and advertisethis to speaker 4. Speaker 4 will now have the full set of routes, and theY:1:200 it receives from 5 will beat X:2, but when speaker 4 comparesY:1:200 to Y:3:100 the MED check now becomes active as the ASes match, andnow Y:3:100 is preferred. Speaker 4 therefore now advertises Y:3:100 to 5,which will also agrees that Y:3:100 is preferred to Y:1:200, and sowithdraws the latter route from 4. Speaker 4 now has only X:2 and Y:3:100,and X:2 beats Y:3:100, and so speaker 4 implicitly updates its route tospeaker 5 to X:2. Speaker 5 sees that Y:1:200 beats X:2 based on the ID,and advertises Y:1:200 to speaker 4, and the cycle continues.
The root cause is the lack of a clear order of preference caused by how MEDsometimes is and sometimes is not compared, leading to this cycle in thepreferences between the routes:
/---> X:2 ---beats---> Y:3:100 --\
| |
| |
\---beats--- Y:1:200 <---beats---/
This particular type of oscillation in full-mesh iBGP topologies can beavoided by speakers preferring already selected, external routes rather thanchoosing to update to new a route based on a post-MED metric (e.g. router-ID), at the cost of a non-deterministic selection process. Quaggaimplements this, as do many other implementations, so long as it is notoverridden by setting bgp bestpath compare-routerid, and see alsoBGP decision process, .
However, more complex and insidious cycles of oscillation are possible withiBGP route-reflection, which are not so easily avoided. These have beendocumented in various places. See, e.g., McPherson, D. and Gill, V. and Walton, D., "Border Gateway Protocol (BGP) Persistent Route OscillationCondition", IETF RFC3345, and Flavel, A. and M. Roughan, "Stableand flexible iBGP", ACM SIGCOMM 2009, and Griffin, T. and G. Wilfong, "On the correctness of IBGP configuration", ACM SIGCOMM 2002 for concrete examples and further references.
There is as of this writing no known way to use MED for its originalpurpose; and reduce routing information in iBGP topologies;and be sure to avoid the instability problems of MED due thenon-transitive routing preferences it can induce; in general on arbitrarynetworks.
There may be iBGP topology specific ways to reduce the instability risks,even while using MED, e.g. by constraining the reflection topology and bytuning IGP costs between route-reflector clusters, see RFC3345 for details. In the near future, the Add-Path extension to BGP may also solve MEDoscillation while still allowing MED to be used as intended, by distributing"best-paths per neighbour AS". This would be at the cost of distributing atleast as many routes to all speakers as a full-mesh iBGP would, if not more,while also imposing similar CPU overheads as the "Deterministic MED" featureat each Add-Path reflector.
More generally, the instability problems that MED can introduce on morecomplex, non-full-mesh, iBGP topologies may be avoided either by:
- Setting bgp always-compare-med, however this allows MED to be comparedacross values set by different neighbour ASes, which may not producecoherent desirable results, of itself.
- Effectively ignoring MED by setting MED to the same value (e.g. 0) usingroutemap set metric on all received routes, in combination withsetting bgp always-compare-med on all speakers. This is the simplestand most performant way to avoid MED oscillation issues, where an AS is happynot to allow neighbours to inject this problematic metric.
As MED is evaluated after the AS_PATH length check, another possible use forMED is for intra-AS steering of routes with equal AS_PATH length, as anextension of the last case above. As MED is evaluated before IGP metric,this can allow cold-potato routing to be implemented to send traffic topreferred hand-offs with neighbours, rather than the closest hand-offaccording to the IGP metric.
Note that even if action is taken to address the MED non-transitivityissues, other oscillations may still be possible. E.g., on IGP cost ifiBGP and IGP topologies are at cross-purposes with each other - see theFlavel and Roughan paper above for an example. Hence the guideline that theiBGP topology should follow the IGP topology.
- BGP: bgp deterministic-med
-
Carry out route-selection in way that produces deterministic answerslocally, even in the face of MED and the lack of a well-defined order ofpreference it can induce on routes. Without this option the preferred routewith MED may be determined largely by the order that routes were receivedin.
Setting this option will have a performance cost that may be noticeable whenthere are many routes for each destination. Currently in Quagga it isimplemented in a way that scales poorly as the number of routes perdestination increases.
The default is that this option is not set.
Note that there are other sources of indeterminism in the route selectionprocess, specifically, the preference for older and already selected routesfrom eBGP peers, See BGP decision process.
- BGP: bgp always-compare-med
-
Always compare the MED on routes, even when they were received fromdifferent neighbouring ASes. Setting this option makes the order ofpreference of routes more defined, and should eliminate MED inducedoscillations.
If using this option, it may also be desirable to use routemap set metric to set MED to 0 on routes received from external neighbours.
This option can be used, together with routemap set metric to use MEDas an intra-AS metric to steer equal-length AS_PATH routes to, e.g., desiredexit points.
11.4 BGP network
Next: Route Aggregation, Up: BGP network [Contents][Index]
11.4.1 BGP route
- BGP: network A.B.C.D/M
-
This command adds the announcement network.
router bgp 1 network 10.0.0.0/8
This configuration example says that network 10.0.0.0/8 will beannounced to all neighbors. Some vendors’ routers don’t advertiseroutes if they aren’t present in their IGP routing tables;
bgpddoesn’t care about IGP routes when announcing its routes.
Next: Redistribute to BGP, Previous: BGP route, Up: BGP network [Contents][Index]
11.4.2 Route Aggregation
- BGP: aggregate-address A.B.C.D/M as-set
-
This command specifies an aggregate address. Resulting routes includeAS set.
- BGP: aggregate-address A.B.C.D/M summary-only
-
This command specifies an aggregate address. Aggreated routes willnot be announce.
Previous: Route Aggregation, Up: BGP network [Contents][Index]
11.4.3 Redistribute to BGP
Next: BGP Peer Group, Previous: BGP network, Up: BGP [Contents][Index]
11.5 BGP Peer
| • Defining Peer: | ||
| • BGP Peer commands: | ||
| • Peer filtering: |
Next: BGP Peer commands, Up: BGP Peer [Contents][Index]
11.5.1 Defining Peer
- BGP: neighbor peer remote-as asn
-
Creates a new neighbor whose remote-as is asn. peercan be an IPv4 address or an IPv6 address.
router bgp 1 neighbor 10.0.0.1 remote-as 2
In this case my router, in AS-1, is trying to peer with AS-2 at10.0.0.1.
This command must be the first command used when configuring a neighbor.If the remote-as is not specified,
bgpdwill complain like this:can't find neighbor 10.0.0.1
Next: Peer filtering, Previous: Defining Peer, Up: BGP Peer [Contents][Index]
11.5.2 BGP Peer commands
In a router bgp clause there are neighbor specific configurationsrequired.
- BGP: neighbor peer shutdown
- BGP: no neighbor peer shutdown
-
Shutdown the peer. We can delete the neighbor’s configuration by
no neighbor peer remote-as as-numberbut allconfiguration of the neighbor will be deleted. When you want topreserve the configuration, but want to drop the BGP peer, use thissyntax.
- BGP: neighbor peer description ...
- BGP: no neighbor peer description ...
-
Set description of the peer.
- BGP: neighbor peer version version
-
Set up the neighbor’s BGP version. version can be 4,4+ or 4-. BGP version 4 is the default value used forBGP peering. BGP version 4+ means that the neighbor supportsMultiprotocol Extensions for BGP-4. BGP version 4- is similar butthe neighbor speaks the old Internet-Draft revision 00’s MultiprotocolExtensions for BGP-4. Some routing software is still using thisversion.
- BGP: neighbor peer interface ifname
- BGP: no neighbor peer interface ifname
-
When you connect to a BGP peer over an IPv6 link-local address, you have to specify the ifname of the interface used for the connection. To specify IPv4 session addresses, see the
neighbor peer update-sourcecommand below.This command is deprecated and may be removed in a future release. Itsuse should be avoided.
- BGP: neighbor peer next-hop-self [all]
- BGP: no neighbor peer next-hop-self [all]
-
This command specifies an announced route’s nexthop as being equivalentto the address of the bgp router if it is learned via eBGP.If the optional keyword
allis specified the modifiation is donealso for routes learned via iBGP.
- BGP: neighbor peer update-source <ifname|address>
- BGP: no neighbor peer update-source
-
Specify the IPv4 source address to use for the BGP session to thisneighbour, may be specified as either an IPv4 address directly oras an interface name (in which case the
zebradaemon MUST be runningin order forbgpdto be able to retrieve interface state).router bgp 64555 neighbor foo update-source 192.168.0.1 neighbor bar update-source lo0
- BGP: neighbor peer default-originate
- BGP: no neighbor peer default-originate
-
bgpd’s default is to not announce the default route (0.0.0.0/0) even itis in routing table. When you want to announce default routes to thepeer, use this command.
- BGP: neighbor peer weight weight
- BGP: no neighbor peer weight weight
-
This command specifies a default weight value for the neighbor’sroutes.
- BGP: neighbor peer local-as as-number
- BGP: neighbor peer local-as as-number no-prepend
- BGP: neighbor peer local-as as-number no-prepend replace-as
- BGP: no neighbor peer local-as
-
Specify an alternate AS for this BGP process when interacting with thespecified peer. With no modifiers, the specified local-as is prepended tothe received AS_PATH when receiving routing updates from the peer, andprepended to the outgoing AS_PATH (after the process local AS) whentransmitting local routes to the peer.
If the no-prepend attribute is specified, then the supplied local-as is notprepended to the received AS_PATH.
If the replace-as attribute is specified, then only the supplied local-as isprepended to the AS_PATH when transmitting local-route updates to this peer.
Note that replace-as can only be specified if no-prepend is.
This command is only allowed for eBGP peers.
- BGP: neighbor peer ttl-security hops number
- BGP: no neighbor peer ttl-security hops number
-
This command enforces Generalized TTL Security Mechanism (GTSM), asspecified in RFC 5082. With this command, only neighbors that are thespecified number of hops away will be allowed to become neighbors. Thiscommand is mututally exclusive with
ebgp-multihop.
Previous: BGP Peer commands, Up: BGP Peer [Contents][Index]
11.5.3 Peer filtering
- BGP: neighbor peer distribute-list name [in|out]
-
This command specifies a distribute-list for the peer. direct is‘in’ or ‘out’.
- BGP: neighbor peer route-map name [in|out]
-
Apply a route-map on the neighbor. direct must be
inorout.
- BGP: bgp route-reflector allow-outbound-policy
-
By default, attribute modification via route-map policy out is not reflectedon reflected routes. This option allows the modifications to be reflected aswell. Once enabled, it affects all reflected routes.
Next: BGP Address Family, Previous: BGP Peer, Up: BGP [Contents][Index]
11.6 BGP Peer Group
Next: Autonomous System, Previous: BGP Peer Group, Up: BGP [Contents][Index]
11.7 BGP Address Family
Multiprotocol BGP enables BGP to carry routing information for multipleNetwork Layer protocols. BGP supports multiple Address FamilyIdentifier (AFI), namely IPv4 and IPv6. Support is also provided formultiple sets of per-AFI information via Subsequent Address FamilyIdentifiers (SAFI). In addition to unicast information, VPN informationRFC4364 and RFC4659, and Encapsulation informationRFC5512 is supported.
- Command: show ip bgp vpnv4 all
- Command: show ipv6 bgp vpn all
-
Print active IPV4 or IPV6 routes advertised via the VPN SAFI.
- Command: show ip bgp encap all
- Command: show ipv6 bgp encap all
-
Print active IPV4 or IPV6 routes advertised via the Encapsulation SAFI.
- Command: show bgp ipv4 encap summary
- Command: show bgp ipv4 vpn summary
- Command: show bgp ipv6 encap summary
- Command: show bgp ipv6 vpn summary
-
Print a summary of neighbor connections for the specified AFI/SAFI combination.
Next: BGP Communities Attribute, Previous: BGP Address Family, Up: BGP [Contents][Index]
11.8 Autonomous System
The AS (Autonomous System) number is one of the essentialelement of BGP. BGP is a distance vector routing protocol, and theAS-Path framework provides distance vector metric and loop detection toBGP. RFC1930, Guidelines for creation, selection, andregistration of an Autonomous System (AS) provides some background onthe concepts of an AS.
The AS number is a two octet value, ranging in value from 1 to 65535.The AS numbers 64512 through 65535 are defined as private AS numbers. Private AS numbers must not to be advertised in the global Internet.
| • AS Path Regular Expression: | ||
| • Display BGP Routes by AS Path: | ||
| • AS Path Access List: | ||
| • Using AS Path in Route Map: | ||
| • Private AS Numbers: |
Next: Display BGP Routes by AS Path, Up: Autonomous System [Contents][Index]
11.8.1 AS Path Regular Expression
AS path regular expression can be used for displaying BGP routes andAS path access list. AS path regular expression is based onPOSIX 1003.2 regular expressions. Following description isjust a subset of
POSIX regular expression. User can use fullPOSIX regular expression. Adding to that special character ’_’is added for AS path regular expression.
.-
Matches any single character.
*-
Matches 0 or more occurrences of pattern.
+-
Matches 1 or more occurrences of pattern.
?-
Match 0 or 1 occurrences of pattern.
^-
Matches the beginning of the line.
$-
Matches the end of the line.
_-
Character
_has special meanings in AS path regular expression.It matches to space and comma , and AS set delimiter { and } and ASconfederation delimiter(and). And it also matches tothe beginning of the line and the end of the line. So_can beused for AS value boundaries match.show ip bgp regexp _7675_matches to all of BGP routes which as AS number include 7675.
Next: AS Path Access List, Previous: AS Path Regular Expression, Up: Autonomous System [Contents][Index]
11.8.2 Display BGP Routes by AS Path
To show BGP routes which has specific AS path information showip bgp command can be used.
- Command: show ip bgp regexp line
-
This commands display BGP routes that matches AS path regularexpression line.
Next: Using AS Path in Route Map, Previous: Display BGP Routes by AS Path, Up: Autonomous System [Contents][Index]
11.8.3 AS Path Access List
AS path access list is user defined AS path.
- Command: ip as-path access-list word {permit|deny} line
-
This command defines a new AS path access list.
Next: Private AS Numbers, Previous: AS Path Access List, Up: Autonomous System [Contents][Index]
11.8.4 Using AS Path in Route Map
- Route Map: set as-path prepend last-as num
-
Prepend the existing last AS number (the leftmost ASN) to the AS_PATH.
Previous: Using AS Path in Route Map, Up: Autonomous System [Contents][Index]
11.8.5 Private AS Numbers
Next: BGP Extended Communities Attribute, Previous: Autonomous System, Up: BGP [Contents][Index]
11.9 BGP Communities Attribute
BGP communities attribute is widely used for implementing policyrouting. Network operators can manipulate BGP communities attributebased on their network policy. BGP communities attribute is definedin RFC1997, BGP Communities Attribute andRFC1998, An Application of the BGP Community Attributein Multi-home Routing. It is an optional transitive attribute,therefore local policy can travel through different autonomous system.
Communities attribute is a set of communities values. Eachcommunities value is 4 octet long. The following format is used todefine communities value.
AS:VAL-
This format represents 4 octet communities value.
ASis highorder 2 octet in digit format.VALis low order 2 octet indigit format. This format is useful to define AS oriented policyvalue. For example,7675:80can be used when AS 7675 wants topass local policy value 80 to neighboring peer. internet-
internetrepresents well-known communities value 0. no-export-
no-exportrepresents well-known communities valueNO_EXPORT
(0xFFFFFF01). All routes carry this value must not be advertisedto outside a BGP confederation boundary. If neighboring BGP peer ispart of BGP confederation, the peer is considered as inside a BGPconfederation boundary, so the route will be announced to the peer. no-advertise-
no-advertiserepresents well-known communities valueNO_ADVERTISE
(0xFFFFFF02). All routes carry this valuemust not be advertise to other BGP peers. local-AS-
local-ASrepresents well-known communities valueNO_EXPORT_SUBCONFED(0xFFFFFF03). All routes carry thisvalue must not be advertised to external BGP peers. Even if theneighboring router is part of confederation, it is considered asexternal BGP peer, so the route will not be announced to the peer.
When BGP communities attribute is received, duplicated communitiesvalue in the communities attribute is ignored and each communitiesvalues are sorted in numerical order.
| • BGP Community Lists: | ||
| • Numbered BGP Community Lists: | ||
| • BGP Community in Route Map: | ||
| • Display BGP Routes by Community: | ||
| • Using BGP Communities Attribute: |
Next: Numbered BGP Community Lists, Up: BGP Communities Attribute [Contents][Index]
11.9.1 BGP Community Lists
BGP community list is a user defined BGP communites attribute list.BGP community list can be used for matching or manipulating BGPcommunities attribute in updates.
There are two types of community list. One is standard communitylist and another is expanded community list. Standard community listdefines communities attribute. Expanded community list definescommunities attribute string with regular expression. Standardcommunity list is compiled into binary format when user define it.Standard community list will be directly compared to BGP communitiesattribute in BGP updates. Therefore the comparison is faster thanexpanded community list.
- Command: ip community-list standard name {permit|deny} community
-
This command defines a new standard community list. communityis communities value. The community is compiled into communitystructure. We can define multiple community list under same name. Inthat case match will happen user defined order. Once thecommunity list matches to communities attribute in BGP updates itreturn permit or deny by the community list definition. When there isno matched entry, deny will be returned. When community isempty it matches to any routes.
- Command: ip community-list expanded name {permit|deny} line
-
This command defines a new expanded community list. line is astring expression of communities attribute. line can includeregular expression to match communities attribute in BGP updates.
- Command: no ip community-list name
- Command: no ip community-list standard name
- Command: no ip community-list expanded name
-
These commands delete community lists specified by name. All ofcommunity lists shares a single name space. So community lists can beremoved simpley specifying community lists name.
- Command: show ip community-list
- Command: show ip community-list name
-
This command display current community list information. Whenname is specified the specified community list’s information isshown.
# show ip community-list Named Community standard list CLIST permit 7675:80 7675:100 no-export deny internet Named Community expanded list EXPAND permit : # show ip community-list CLIST Named Community standard list CLIST permit 7675:80 7675:100 no-export deny internet
Next: BGP Community in Route Map, Previous: BGP Community Lists, Up: BGP Communities Attribute [Contents][Index]
11.9.2 Numbered BGP Community Lists
When number is used for BGP community list name, the number hasspecial meanings. Community list number in the range from 1 and 99 isstandard community list. Community list number in the range from 100to 199 is expanded community list. These community lists are calledas numbered community lists. On the other hand normal community listsis called as named community lists.
- Command: ip community-list <1-99> {permit|deny} community
-
This command defines a new community list. <1-99> is standardcommunity list number. Community list name within this range definesstandard community list. When community is empty it matches toany routes.
- Command: ip community-list <100-199> {permit|deny} community
-
This command defines a new community list. <100-199> is expandedcommunity list number. Community list name within this range definesexpanded community list.
- Command: ip community-list name {permit|deny} community
-
When community list type is not specifed, the community list type isautomatically detected. If community can be compiled intocommunities attribute, the community list is defined as a standardcommunity list. Otherwise it is defined as an expanded communitylist. This feature is left for backward compability. Use of thisfeature is not recommended.
Next: Display BGP Routes by Community, Previous: Numbered BGP Community Lists, Up: BGP Communities Attribute [Contents][Index]
11.9.3 BGP Community in Route Map
In Route Map (see Route Map), we can match or set BGPcommunities attribute. Using this feature network operator canimplement their network policy based on BGP communities attribute.
Following commands can be used in Route Map.
- Route Map: match community word
- Route Map: match community word exact-match
-
This command perform match to BGP updates using community listword. When the one of BGP communities value match to the one ofcommunities value in community list, it is match. When
exact-matchkeyword is spcified, match happen only when BGPupdates have completely same communities value specified in thecommunity list.
- Route Map: set community none
- Route Map: set community community
- Route Map: set community community additive
-
This command manipulate communities value in BGP updates. When
noneis specified as communities value, it removes entirecommunities attribute from BGP updates. When community is notnone, specified communities value is set to BGP updates. IfBGP updates already has BGP communities value, the existing BGPcommunities value is replaced with specified community value.Whenadditivekeyword is specified, community is appendedto the existing communities value.
- Route Map: set comm-list word delete
-
This command remove communities value from BGP communities attribute.The word is community list name. When BGP route’s communitiesvalue matches to the community list word, the communities valueis removed. When all of communities value is removed eventually, theBGP update’s communities attribute is completely removed.
Next: Using BGP Communities Attribute, Previous: BGP Community in Route Map, Up: BGP Communities Attribute [Contents][Index]
11.9.4 Display BGP Routes by Community
To show BGP routes which has specific BGP communities attribute,show ip bgp command can be used. The
community value andcommunity list can be used for show ip bgp command.
- Command: show ip bgp community
- Command: show ip bgp community community
- Command: show ip bgp community community exact-match
-
show ip bgp communitydisplays BGP routes which has communitiesattribute. When community is specified, BGP routes that matchescommunity value is displayed. For this command,internetkeyword can’t be used for community value. Whenexact-matchis specified, it display only routes that have anexact match.
- Command: show ip bgp community-list word
- Command: show ip bgp community-list word exact-match
-
This commands display BGP routes that matches community listword. When
exact-matchis specified, display only routesthat have an exact match.
Previous: Display BGP Routes by Community, Up: BGP Communities Attribute [Contents][Index]
11.9.5 Using BGP Communities Attribute
Following configuration is the most typical usage of BGP communitiesattribute. AS 7675 provides upstream Internet connection to AS 100.When following configuration exists in AS 7675, AS 100 networksoperator can set local preference in AS 7675 network by setting BGPcommunities attribute to the updates.
router bgp 7675 neighbor 192.168.0.1 remote-as 100 neighbor 192.168.0.1 route-map RMAP in ! ip community-list 70 permit 7675:70 ip community-list 70 deny ip community-list 80 permit 7675:80 ip community-list 80 deny ip community-list 90 permit 7675:90 ip community-list 90 deny ! route-map RMAP permit 10 match community 70 set local-preference 70 ! route-map RMAP permit 20 match community 80 set local-preference 80 ! route-map RMAP permit 30 match community 90 set local-preference 90
Following configuration announce 10.0.0.0/8 from AS 100 to AS 7675.The route has communities value 7675:80 so when above configurationexists in AS 7675, announced route’s local preference will be set tovalue 80.
router bgp 100 network 10.0.0.0/8 neighbor 192.168.0.2 remote-as 7675 neighbor 192.168.0.2 route-map RMAP out ! ip prefix-list PLIST permit 10.0.0.0/8 ! route-map RMAP permit 10 match ip address prefix-list PLIST set community 7675:80
Following configuration is an example of BGP route filtering usingcommunities attribute. This configuration only permit BGP routeswhich has BGP communities value 0:80 or 0:90. Network operator canput special internal communities value at BGP border router, thenlimit the BGP routes announcement into the internal network.
router bgp 7675 neighbor 192.168.0.1 remote-as 100 neighbor 192.168.0.1 route-map RMAP in ! ip community-list 1 permit 0:80 0:90 ! route-map RMAP permit in match community 1
Following exmaple filter BGP routes which has communities value 1:1.When there is no match community-list returns deny. To avoidfiltering all of routes, we need to define permit any at last.
router bgp 7675 neighbor 192.168.0.1 remote-as 100 neighbor 192.168.0.1 route-map RMAP in ! ip community-list standard FILTER deny 1:1 ip community-list standard FILTER permit ! route-map RMAP permit 10 match community FILTER
Communities value keyword internet has special meanings instandard community lists. In below example
internet act asmatch any. It matches all of BGP routes even if the route does nothave communities attribute at all. So community list
INTERNETis same as above example’s FILTER.
ip community-list standard INTERNET deny 1:1 ip community-list standard INTERNET permit internet
Following configuration is an example of communities value deletion.With this configuration communities value 100:1 and 100:2 is removedfrom BGP updates. For communities value deletion, only
permitcommunity-list is used. deny community-list is ignored.
router bgp 7675 neighbor 192.168.0.1 remote-as 100 neighbor 192.168.0.1 route-map RMAP in ! ip community-list standard DEL permit 100:1 100:2 ! route-map RMAP permit 10 set comm-list DEL delete
Next: Displaying BGP routes, Previous: BGP Communities Attribute, Up: BGP [Contents][Index]
11.10 BGP Extended Communities Attribute
BGP extended communities attribute is introduced with MPLS VPN/BGPtechnology. MPLS VPN/BGP expands capability of network infrastructureto provide VPN functionality. At the same time it requires a newframework for policy routing. With BGP Extended Communities Attributewe can use Route Target or Site of Origin for implementing networkpolicy for MPLS VPN/BGP.
BGP Extended Communities Attribute is similar to BGP CommunitiesAttribute. It is an optional transitive attribute. BGP ExtendedCommunities Attribute can carry multiple Extended Community value.Each Extended Community value is eight octet length.
BGP Extended Communities Attribute provides an extended rangecompared with BGP Communities Attribute. Adding to that there is atype field in each value to provides community space structure.
There are two format to define Extended Community value. One is ASbased format the other is IP address based format.
AS:VAL-
This is a format to define AS based Extended Community value.
ASpart is 2 octets Global Administrator subfield in ExtendedCommunity value.VALpart is 4 octets Local Administratorsubfield.7675:100represents AS 7675 policy value 100. IP-Address:VAL-
This is a format to define IP address based Extended Community value.
IP-Addresspart is 4 octets Global Administrator subfield.VALpart is 2 octets Local Administrator subfield.10.0.0.1:100represents
Next: BGP Extended Communities in Route Map, Up: BGP Extended Communities Attribute [Contents][Index]
11.10.1 BGP Extended Community Lists
Expanded Community Lists is a user defined BGP Expanded CommunityLists.
- Command: ip extcommunity-list standard name {permit|deny} extcommunity
-
This command defines a new standard extcommunity-list.extcommunity is extended communities value. Theextcommunity is compiled into extended community structure. Wecan define multiple extcommunity-list under same name. In that casematch will happen user defined order. Once the extcommunity-listmatches to extended communities attribute in BGP updates it returnpermit or deny based upon the extcommunity-list definition. Whenthere is no matched entry, deny will be returned. Whenextcommunity is empty it matches to any routes.
- Command: ip extcommunity-list expanded name {permit|deny} line
-
This command defines a new expanded extcommunity-list. line isa string expression of extended communities attribute. line caninclude regular expression to match extended communities attribute inBGP updates.
- Command: no ip extcommunity-list name
- Command: no ip extcommunity-list standard name
- Command: no ip extcommunity-list expanded name
-
These commands delete extended community lists specified byname. All of extended community lists shares a single namespace. So extended community lists can be removed simpley specifyingthe name.
- Command: show ip extcommunity-list
- Command: show ip extcommunity-list name
-
This command display current extcommunity-list information. Whenname is specified the community list’s information is shown.
# show ip extcommunity-list
Previous: BGP Extended Community Lists, Up: BGP Extended Communities Attribute [Contents][Index]
11.10.2 BGP Extended Communities in Route Map
Next: Capability Negotiation, Previous: BGP Extended Communities Attribute, Up: BGP [Contents][Index]
11.11 Displaying BGP Routes
| • Show IP BGP: | ||
| • More Show IP BGP: |
Next: More Show IP BGP, Up: Displaying BGP routes [Contents][Index]
11.11.1 Show IP BGP
- Command: show ip bgp
- Command: show ip bgp A.B.C.D
- Command: show ip bgp X:X::X:X
-
This command displays BGP routes. When no route is specified itdisplay all of IPv4 BGP routes.
BGP table version is 0, local router ID is 10.1.1.1 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal Origin codes: i - IGP, e - EGP, ? - incomplete Network Next Hop Metric LocPrf Weight Path *> 1.1.1.1/32 0.0.0.0 0 32768 i Total number of prefixes 1
Previous: Show IP BGP, Up: Displaying BGP routes [Contents][Index]
11.11.2 More Show IP BGP
- Command: show ip bgp regexp line
-
This command display BGP routes using AS path regular expression (see Display BGP Routes by AS Path).
- Command: show ip bgp community community
- Command: show ip bgp community community exact-match
-
This command display BGP routes using community (see Display BGP Routes by Community).
- Command: show ip bgp community-list word
- Command: show ip bgp community-list word exact-match
-
This command display BGP routes using community list (see Display BGP Routes by Community).
Next: Route Reflector, Previous: Displaying BGP routes, Up: BGP [Contents][Index]
11.12 Capability Negotiation
When adding IPv6 routing information exchange feature to BGP. Therewere some proposals. IETF (Internet Engineering Task Force)IDR (Inter Domain Routing) WG (Working group) adopteda proposal called Multiprotocol Extension for BGP. The specificationis described in RFC2283. The protocol does not define new protocols. It defines new attributes to existing BGP. When it is used exchangingIPv6 routing information it is called BGP-4+. When it is used forexchanging multicast routing information it is called MBGP.
bgpd supports Multiprotocol Extension for BGP. So if remotepeer supports the protocol,
bgpd can exchange IPv6 and/ormulticast routing information.
Traditional BGP did not have the feature to detect remote peer’scapabilities, e.g. whether it can handle prefix types other than IPv4unicast routes. This was a big problem using Multiprotocol Extensionfor BGP to operational network.
RFC2842, CapabilitiesAdvertisement with BGP-4 adopted a feature called CapabilityNegotiation.
bgpd use this Capability Negotiation to detectthe remote peer’s capabilities. If the peer is only configured as IPv4unicast neighbor,
bgpd does not send these CapabilityNegotiation packets (at least not unless other optional BGP featuresrequire capability negotation).
By default, Quagga will bring up peering with minimal common capabilityfor the both sides. For example, local router has unicast andmulticast capabilitie and remote router has unicast capability. Inthis case, the local router will establish the connection with unicastonly capability. When there are no common capabilities, Quagga sendsUnsupported Capability error and then resets the connection.
If you want to completely match capabilities with remote peer. Pleaseuse
strict-capability-match command.
- BGP: neighbor peer strict-capability-match
- BGP: no neighbor peer strict-capability-match
-
Strictly compares remote capabilities and local capabilities. If capabilitiesare different, send Unsupported Capability error then reset connection.
You may want to disable sending Capability Negotiation OPEN messageoptional parameter to the peer when remote peer does not implementCapability Negotiation. Please use
dont-capability-negotiatecommand to disable the feature.
- BGP: neighbor peer dont-capability-negotiate
- BGP: no neighbor peer dont-capability-negotiate
-
Suppress sending Capability Negotiation as OPEN message optionalparameter to the peer. This command only affects the peer is configuredother than IPv4 unicast configuration.
When remote peer does not have capability negotiation feature, remotepeer will not send any capabilities at all. In that case, bgpconfigures the peer with configured capabilities.
You may prefer locally configured capabilities more than the negotiatedcapabilities even though remote peer sends capabilities. If the peeris configured by
override-capability, bgpd ignoresreceived capabilities then override negotiated capabilities withconfigured values.
- BGP: neighbor peer override-capability
- BGP: no neighbor peer override-capability
-
Override the result of Capability Negotiation with local configuration.Ignore remote peer’s capability value.
Next: Route Server, Previous: Capability Negotiation, Up: BGP [Contents][Index]
11.13 Route Reflector
Next: How to set up a 6-Bone connection, Previous: Route Reflector, Up: BGP [Contents][Index]
11.14 Route Server
At an Internet Exchange point, many ISPs are connected to each other byexternal BGP peering. Normally these external BGP connection are done by‘full mesh’ method. As with internal BGP full mesh formation,this method has a scaling problem.
This scaling problem is well known. Route Server is a method to resolvethe problem. Each ISP’s BGP router only peers to Route Server. RouteServer serves as BGP information exchange to other BGP routers. Byapplying this method, numbers of BGP connections is reduced fromO(n*(n-1)/2) to O(n).
Unlike normal BGP router, Route Server must have several routing tablesfor managing different routing policies for each BGP speaker. We call therouting tables as different
views. bgpd can work asnormal BGP router or Route Server or both at the same time.
Next: BGP instance and view, Up: Route Server [Contents][Index]
11.14.1 Multiple instance
To enable multiple view function of bgpd, you must turn onmultiple instance feature beforehand.
- Command: bgp multiple-instance
-
Enable BGP multiple instance feature. After this feature is enabled,you can make multiple BGP instances or multiple BGP views.
- Command: no bgp multiple-instance
-
Disable BGP multiple instance feature. You can not disable this featurewhen BGP multiple instances or views exist.
When you want to make configuration more Cisco like one,
When bgp config-type cisco is specified,
“no synchronization” is displayed.“no auto-summary” is displayed.
“network” and “aggregate-address” argument is displayed as“A.B.C.D M.M.M.M”
Quagga: network 10.0.0.0/8Cisco: network 10.0.0.0
Quagga: aggregate-address 192.168.0.0/24Cisco: aggregate-address 192.168.0.0 255.255.255.0
Community attribute handling is also different. If there is noconfiguration is specified community attribute and extended communityattribute are sent to neighbor. When user manually disable thefeature community attribute is not sent to the neighbor. In case
ofbgp config-type cisco is specified, community attribute is notsent to the neighbor by default. To send community attribute user hasto specify
neighbor A.B.C.D send-community command.
! router bgp 1 neighbor 10.0.0.1 remote-as 1 no neighbor 10.0.0.1 send-community ! router bgp 1 neighbor 10.0.0.1 remote-as 1 neighbor 10.0.0.1 send-community !
Next: Routing policy, Previous: Multiple instance, Up: Route Server [Contents][Index]
11.14.2 BGP instance and view
BGP instance is a normal BGP process. The result of route selectiongoes to the kernel routing table. You can setup different AS at thesame time when BGP multiple instance feature is enabled.
bgp multiple-instance ! router bgp 1 neighbor 10.0.0.1 remote-as 2 neighbor 10.0.0.2 remote-as 3 ! router bgp 2 neighbor 10.0.0.3 remote-as 4 neighbor 10.0.0.4 remote-as 5
BGP view is almost same as normal BGP process. The result ofroute selection does not go to the kernel routing table. BGP view isonly for exchanging BGP routing information.
- Command: router bgp as-number view name
-
Make a new BGP view. You can use arbitrary word for the name. Thisview’s route selection result does not go to the kernel routing table.
With this command, you can setup Route Server like below.
bgp multiple-instance ! router bgp 1 view 1 neighbor 10.0.0.1 remote-as 2 neighbor 10.0.0.2 remote-as 3 ! router bgp 2 view 2 neighbor 10.0.0.3 remote-as 4 neighbor 10.0.0.4 remote-as 5
Next: Viewing the view, Previous: BGP instance and view, Up: Route Server [Contents][Index]
11.14.3 Routing policy
You can set different routing policy for a peer. For example, you canset different filter for a peer.
bgp multiple-instance ! router bgp 1 view 1 neighbor 10.0.0.1 remote-as 2 neighbor 10.0.0.1 distribute-list 1 in ! router bgp 1 view 2 neighbor 10.0.0.1 remote-as 2 neighbor 10.0.0.1 distribute-list 2 in
This means BGP update from a peer 10.0.0.1 goes to both BGP view 1 and view2. When the update is inserted into view 1, distribute-list 1 isapplied. On the other hand, when the update is inserted into view 2,distribute-list 2 is applied.
Previous: Routing policy, Up: Route Server [Contents][Index]
11.14.4 Viewing the view
To display routing table of BGP view, you must specify view name.
Next: Dump BGP packets and table, Previous: Route Server, Up: BGP [Contents][Index]
11.15 How to set up a 6-Bone connection
zebra configuration =================== ! ! Actually there is no need to configure zebra ! bgpd configuration ================== ! ! This means that routes go through zebra and into the kernel. ! router zebra ! ! MP-BGP configuration ! router bgp 7675 bgp router-id 10.0.0.1 neighbor 3ffe:1cfa:0:2:2a0:c9ff:fe9e:f56 remote-as as-number ! address-family ipv6 network 3ffe:506::/32 neighbor 3ffe:1cfa:0:2:2a0:c9ff:fe9e:f56 activate neighbor 3ffe:1cfa:0:2:2a0:c9ff:fe9e:f56 route-map set-nexthop out neighbor 3ffe:1cfa:0:2:2c0:4fff:fe68:a231 remote-as as-number neighbor 3ffe:1cfa:0:2:2c0:4fff:fe68:a231 route-map set-nexthop out exit-address-family ! ipv6 access-list all permit any ! ! Set output nexthop address. ! route-map set-nexthop permit 10 match ipv6 address all set ipv6 nexthop global 3ffe:1cfa:0:2:2c0:4fff:fe68:a225 set ipv6 nexthop local fe80::2c0:4fff:fe68:a225 ! ! logfile FILENAME is obsolete. Please use log file FILENAME log file bgpd.log !
Next: BGP Configuration Examples, Previous: How to set up a 6-Bone connection, Up: BGP [Contents][Index]
11.16 Dump BGP packets and table
- Command: dump bgp all path [interval]
- Command: dump bgp all-et path [interval]
- Command: no dump bgp all [path] [interval]
-
Dump all BGP packet and events to path file.If interval is set, a new file will be created for echo interval of seconds.The path path can be set with date and time formatting (strftime).The type ‘all-et’ enables support for Extended Timestamp Header (see Packet Binary Dump Format).(see Packet Binary Dump Format)
- Command: dump bgp updates path [interval]
- Command: dump bgp updates-et path [interval]
- Command: no dump bgp updates [path] [interval]
-
Dump only BGP updates messages to path file.If interval is set, a new file will be created for echo interval of seconds.The path path can be set with date and time formatting (strftime).The type ‘updates-et’ enables support for Extended Timestamp Header (see Packet Binary Dump Format).
- Command: dump bgp routes-mrt path
- Command: dump bgp routes-mrt path interval
- Command: no dump bgp route-mrt [path] [interval]
-
Dump whole BGP routing table to path. This is heavy process.The path path can be set with date and time formatting (strftime).If interval is set, a new file will be created for echo interval of seconds.
Note: the interval variable can also be set using hours and minutes: 04h20m00.
Previous: Dump BGP packets and table, Up: BGP [Contents][Index]
11.17 BGP Configuration Examples
Example of a session to an upstream, advertising only one prefix to it.
router bgp 64512 bgp router-id 10.236.87.1 network 10.236.87.0/24 neighbor upstream peer-group neighbor upstream remote-as 64515 neighbor upstream capability dynamic neighbor upstream prefix-list pl-allowed-adv out neighbor 10.1.1.1 peer-group upstream neighbor 10.1.1.1 description ACME ISP ! ip prefix-list pl-allowed-adv seq 5 permit 82.195.133.0/25 ip prefix-list pl-allowed-adv seq 10 deny any
A more complex example. With upstream, peer and customer sessions.Advertising global prefixes and NO_EXPORT prefixes and providingactions for customer routes based on community values. Extensive use ofroute-maps and the ’call’ feature to support selective advertising ofprefixes. This example is intended as guidance only, it has NOT beentested and almost certainly containts silly mistakes, if not seriousflaws.
router bgp 64512 bgp router-id 10.236.87.1 network 10.123.456.0/24 network 10.123.456.128/25 route-map rm-no-export neighbor upstream capability dynamic neighbor upstream route-map rm-upstream-out out neighbor cust capability dynamic neighbor cust route-map rm-cust-in in neighbor cust route-map rm-cust-out out neighbor cust send-community both neighbor peer capability dynamic neighbor peer route-map rm-peer-in in neighbor peer route-map rm-peer-out out neighbor peer send-community both neighbor 10.1.1.1 remote-as 64515 neighbor 10.1.1.1 peer-group upstream neighbor 10.2.1.1 remote-as 64516 neighbor 10.2.1.1 peer-group upstream neighbor 10.3.1.1 remote-as 64517 neighbor 10.3.1.1 peer-group cust-default neighbor 10.3.1.1 description customer1 neighbor 10.3.1.1 prefix-list pl-cust1-network in neighbor 10.4.1.1 remote-as 64518 neighbor 10.4.1.1 peer-group cust neighbor 10.4.1.1 prefix-list pl-cust2-network in neighbor 10.4.1.1 description customer2 neighbor 10.5.1.1 remote-as 64519 neighbor 10.5.1.1 peer-group peer neighbor 10.5.1.1 prefix-list pl-peer1-network in neighbor 10.5.1.1 description peer AS 1 neighbor 10.6.1.1 remote-as 64520 neighbor 10.6.1.1 peer-group peer neighbor 10.6.1.1 prefix-list pl-peer2-network in neighbor 10.6.1.1 description peer AS 2 ! ip prefix-list pl-default permit 0.0.0.0/0 ! ip prefix-list pl-upstream-peers permit 10.1.1.1/32 ip prefix-list pl-upstream-peers permit 10.2.1.1/32 ! ip prefix-list pl-cust1-network permit 10.3.1.0/24 ip prefix-list pl-cust1-network permit 10.3.2.0/24 ! ip prefix-list pl-cust2-network permit 10.4.1.0/24 ! ip prefix-list pl-peer1-network permit 10.5.1.0/24 ip prefix-list pl-peer1-network permit 10.5.2.0/24 ip prefix-list pl-peer1-network permit 192.168.0.0/24 ! ip prefix-list pl-peer2-network permit 10.6.1.0/24 ip prefix-list pl-peer2-network permit 10.6.2.0/24 ip prefix-list pl-peer2-network permit 192.168.1.0/24 ip prefix-list pl-peer2-network permit 192.168.2.0/24 ip prefix-list pl-peer2-network permit 172.16.1/24 ! ip as-path access-list asp-own-as permit ^$ ip as-path access-list asp-own-as permit _64512_ ! ! ################################################################# ! Match communities we provide actions for, on routes receives from ! customers. Communities values of <our-ASN>:X, with X, have actions: ! ! 100 - blackhole the prefix ! 200 - set no_export ! 300 - advertise only to other customers ! 400 - advertise only to upstreams ! 500 - set no_export when advertising to upstreams ! 2X00 - set local_preference to X00 ! ! blackhole the prefix of the route ip community-list standard cm-blackhole permit 64512:100 ! ! set no-export community before advertising ip community-list standard cm-set-no-export permit 64512:200 ! ! advertise only to other customers ip community-list standard cm-cust-only permit 64512:300 ! ! advertise only to upstreams ip community-list standard cm-upstream-only permit 64512:400 ! ! advertise to upstreams with no-export ip community-list standard cm-upstream-noexport permit 64512:500 ! ! set local-pref to least significant 3 digits of the community ip community-list standard cm-prefmod-100 permit 64512:2100 ip community-list standard cm-prefmod-200 permit 64512:2200 ip community-list standard cm-prefmod-300 permit 64512:2300 ip community-list standard cm-prefmod-400 permit 64512:2400 ip community-list expanded cme-prefmod-range permit 64512:2... ! ! Informational communities ! ! 3000 - learned from upstream ! 3100 - learned from customer ! 3200 - learned from peer ! ip community-list standard cm-learnt-upstream permit 64512:3000 ip community-list standard cm-learnt-cust permit 64512:3100 ip community-list standard cm-learnt-peer permit 64512:3200 ! ! ################################################################### ! Utility route-maps ! ! These utility route-maps generally should not used to permit/deny ! routes, i.e. they do not have meaning as filters, and hence probably ! should be used with 'on-match next'. These all finish with an empty ! permit entry so as not interfere with processing in the caller. ! route-map rm-no-export permit 10 set community additive no-export route-map rm-no-export permit 20 ! route-map rm-blackhole permit 10 description blackhole, up-pref and ensure it cant escape this AS set ip next-hop 127.0.0.1 set local-preference 10 set community additive no-export route-map rm-blackhole permit 20 ! ! Set local-pref as requested route-map rm-prefmod permit 10 match community cm-prefmod-100 set local-preference 100 route-map rm-prefmod permit 20 match community cm-prefmod-200 set local-preference 200 route-map rm-prefmod permit 30 match community cm-prefmod-300 set local-preference 300 route-map rm-prefmod permit 40 match community cm-prefmod-400 set local-preference 400 route-map rm-prefmod permit 50 ! ! Community actions to take on receipt of route. route-map rm-community-in permit 10 description check for blackholing, no point continuing if it matches. match community cm-blackhole call rm-blackhole route-map rm-community-in permit 20 match community cm-set-no-export call rm-no-export on-match next route-map rm-community-in permit 30 match community cme-prefmod-range call rm-prefmod route-map rm-community-in permit 40 ! ! ##################################################################### ! Community actions to take when advertising a route. ! These are filtering route-maps, ! ! Deny customer routes to upstream with cust-only set. route-map rm-community-filt-to-upstream deny 10 match community cm-learnt-cust match community cm-cust-only route-map rm-community-filt-to-upstream permit 20 ! ! Deny customer routes to other customers with upstream-only set. route-map rm-community-filt-to-cust deny 10 match community cm-learnt-cust match community cm-upstream-only route-map rm-community-filt-to-cust permit 20 ! ! ################################################################### ! The top-level route-maps applied to sessions. Further entries could ! be added obviously.. ! ! Customers route-map rm-cust-in permit 10 call rm-community-in on-match next route-map rm-cust-in permit 20 set community additive 64512:3100 route-map rm-cust-in permit 30 ! route-map rm-cust-out permit 10 call rm-community-filt-to-cust on-match next route-map rm-cust-out permit 20 ! ! Upstream transit ASes route-map rm-upstream-out permit 10 description filter customer prefixes which are marked cust-only call rm-community-filt-to-upstream on-match next route-map rm-upstream-out permit 20 description only customer routes are provided to upstreams/peers match community cm-learnt-cust ! ! Peer ASes ! outbound policy is same as for upstream route-map rm-peer-out permit 10 call rm-upstream-out ! route-map rm-peer-in permit 10 set community additive 64512:3200
12 Configuring Quagga as a Route Server
The purpose of a Route Server is to centralize the peerings between BGPspeakers. For example if we have an exchange point scenario with four BGPspeakers, each of which maintaining a BGP peering with the other threewe can convert it into a centralized scenario whereeach of the four establishes a single BGP peering against the Route Server.
We will first describe briefly the Route Server model implemented by Quagga.We will explain the commands that have been added for configuring thatmodel. And finally we will show a full example of Quagga configured as RouteServer.
| • Description of the Route Server model: | ||
| • Commands for configuring a Route Server: | ||
| • Example of Route Server Configuration: |
Next: Commands for configuring a Route Server, Up: Configuring Quagga as a Route Server [Contents][Index]
12.1 Description of the Route Server model
First we are going to describe the normal processing that BGP announcementssuffer inside a standard BGP speaker, as shown in Figure 12.1,it consists of three steps:
- When an announcement is received from some peer, the ‘In’ filtersconfigured for that peer are applied to the announcement. These filters canreject the announcement, accept it unmodified, or accept it with some of itsattributes modified.
- The announcements that pass the ‘In’ filters go into theBest Path Selection process, where they are compared to otherannouncements referred to the same destination that have beenreceived from different peers (in case such otherannouncements exist). For each different destination, the announcementwhich is selected as the best is inserted into the BGP speaker’s Loc-RIB.
- The routes which are inserted in the Loc-RIB areconsidered for announcement to all the peers (except the onefrom which the route came). This is done by passing the routesin the Loc-RIB through the ‘Out’ filters corresponding to eachpeer. These filters can reject the route,accept it unmodified, or accept it with some of its attributesmodified. Those routes which are accepted by the ‘Out’ filtersof a peer are announced to that peer.
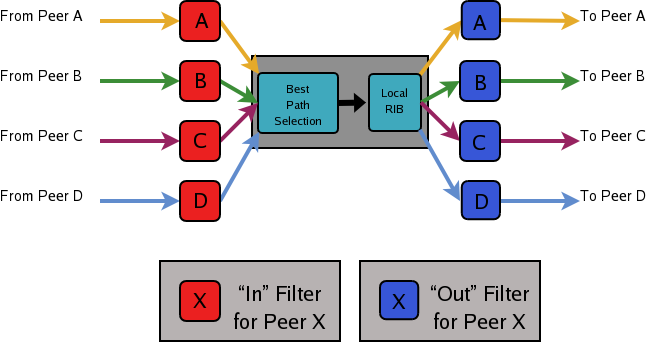
Of course we want that the routing tables obtained in each of the routersare the same when using the route server than when not. But as a consequenceof having a single BGP peering (against the route server), the BGP speakerscan no longer distinguish from/to which peer each announce comes/goes.This means that the routers connected to the routeserver are not able to apply by themselves the same input/output filtersas in the full mesh scenario, so they have to delegate those functions tothe route server.
Even more, the “best path” selection must be also performed insidethe route server on behalf of its clients. The reason is that if, afterapplying the filters of the announcer and the (potential) receiver, theroute server decides to send to some client two or more differentannouncements referred to the same destination, the client will onlyretain the last one, considering it as an implicit withdrawal of theprevious announcements for the same destination. This is the expectedbehavior of a BGP speaker as defined in RFC1771, and even thoughthere are some proposals of mechanisms that permit multiple paths forthe same destination to be sent through a single BGP peering, none arecurrently supported by most existing BGP implementations.
As a consequence a route server must maintain additional information andperform additional tasks for a RS-client that those necessary for common BGPpeerings. Essentially a route server must:
- Maintain a separated Routing Information Base (Loc-RIB)for each peer configured as RS-client, containing the routesselected as a result of the “Best Path Selection” processthat is performed on behalf of that RS-client.
- Whenever it receives an announcement from a RS-client,it must consider it for the Loc-RIBs of the other RS-clients.
- This means that for each of them the route server must pass theannouncement through the appropriate ‘Out’ filter of theannouncer.
- Then through the appropriate ‘In’ filter ofthe potential receiver.
- Only if the announcement is accepted by both filters it will be passedto the “Best Path Selection” process.
- Finally, it might go into the Loc-RIB of the receiver.
When we talk about the “appropriate” filter, both the announcer and thereceiver of the route must be taken into account. Suppose that the routeserver receives an announcement from client A, and the route server isconsidering it for the Loc-RIB of client B. The filters that should beapplied are the same that would be used in the full mesh scenario, i.e.,first the ‘Out’ filter of router A for announcements going to router B, andthen the ‘In’ filter of router B for announcements coming from router A.
We call “Export Policy” of a RS-client to the set of ‘Out’ filters thatthe client would use if there was no route server. The same applies for the“Import Policy” of a RS-client and the set of ‘In’ filters of the clientif there was no route server.
It is also common to demand from a route server that it does notmodify some BGP attributes (next-hop, as-path and MED) that are usuallymodified by standard BGP speakers before announcing a route.
The announcement processing model implemented by Quagga is shown inFigure 12.2. The figure shows a mixture of RS-clients (B, C and D)with normal BGP peers (A). There are some details that worth additionalcomments:
- Announcements coming from a normal BGP peer are alsoconsidered for the Loc-RIBs of all the RS-clients. Butlogically they do not pass through any export policy.
- Those peers that are configured as RS-clients do notreceive any announce from the ‘Main’ Loc-RIB.
- Apart from import and export policies,‘In’ and ‘Out’ filters can also be set for RS-clients. ‘In’filters might be useful when the route server has also normalBGP peers. On the other hand, ‘Out’ filters for RS-clients areprobably unnecessary, but we decided not to remove them asthey do not hurt anybody (they can always be left empty).
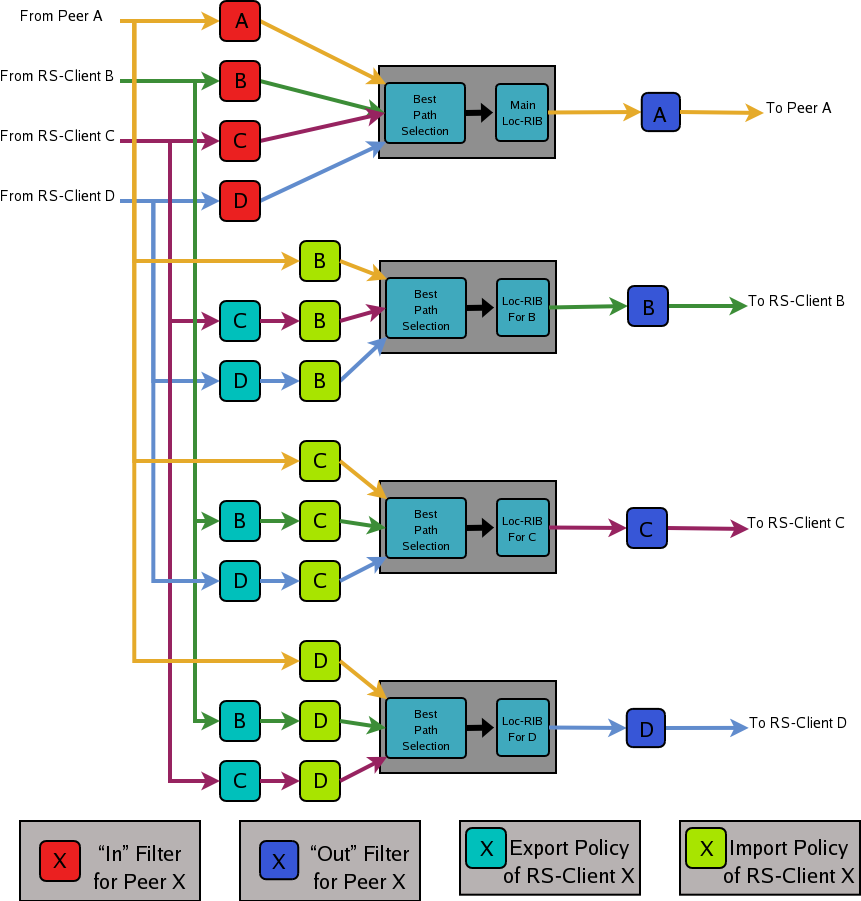
Next: Example of Route Server Configuration, Previous: Description of the Route Server model, Up: Configuring Quagga as a Route Server [Contents][Index]
12.2 Commands for configuring a Route Server
Now we will describe the commands that have been added to quaggain order to support the route server features.
- Route-Server: neighbor peer-group route-server-client
- Route-Server: neighbor A.B.C.D route-server-client
- Route-Server: neighbor X:X::X:X route-server-client
-
This command configures the peer given by peer, A.B.C.D orX:X::X:X as an RS-client.
Actually this command is not new, it already existed in standard Quagga. Itenables the transparent mode for the specified peer. This means that someBGP attributes (as-path, next-hop and MED) of the routes announced to thatpeer are not modified.
With the route server patch, this command, apart from setting thetransparent mode, creates a new Loc-RIB dedicated to the specified peer(those named ‘Loc-RIB for X’ in Figure 12.2.). Starting fromthat moment, every announcement received by the route server will be alsoconsidered for the new Loc-RIB.
- Route-Server: neigbor {A.B.C.D|X.X::X.X|peer-group} route-map WORD {import|export}
-
This set of commands can be used to specify the route-map thatrepresents the Import or Export policy of a peer which isconfigured as a RS-client (with the previous command).
- Route-Server: match peer {A.B.C.D|X:X::X:X}
-
This is a new match statement for use in route-maps, enabling them todescribe import/export policies. As we said before, an import/export policyrepresents a set of input/output filters of the RS-client. This statementmakes possible that a single route-map represents the full set of filtersthat a BGP speaker would use for its different peers in a non-RS scenario.
The match peer statement has different semantics whether it is usedinside an import or an export route-map. In the first case the statementmatches if the address of the peer who sends the announce is the same thatthe address specified by {A.B.C.D|X:X::X:X}. For export route-maps itmatches when {A.B.C.D|X:X::X:X} is the address of the RS-Client into whoseLoc-RIB the announce is going to be inserted (how the same export policy isapplied before different Loc-RIBs is shown in Figure 12.2.).
- Route-map Command: call WORD
-
This command (also used inside a route-map) jumps into a differentroute-map, whose name is specified by WORD. When the calledroute-map finishes, depending on its result the original route-mapcontinues or not. Apart from being useful for making import/exportroute-maps easier to write, this command can also be used insideany normal (in or out) route-map.
Previous: Commands for configuring a Route Server, Up: Configuring Quagga as a Route Server [Contents][Index]
12.3 Example of Route Server Configuration
Finally we are going to show how to configure a Quagga daemon to act as aRoute Server. For this purpose we are going to present a scenario withoutroute server, and then we will show how to use the configurations of the BGProuters to generate the configuration of the route server.
All the configuration files shown in this section have been takenfrom scenarios which were tested using the VNUML toolVNUML.
Next: Configuration of the BGP routers with Route Server, Up: Example of Route Server Configuration [Contents][Index]
12.3.1 Configuration of the BGP routers without Route Server
We will suppose that our initial scenario is an exchange point with threeBGP capable routers, named RA, RB and RC. Each of the BGP speakers generatessome routes (with the network command), and establishes BGP peeringsagainst the other two routers. These peerings have In and Out route-mapsconfigured, named like “PEER-X-IN” or “PEER-X-OUT”. For example theconfiguration file for router RA could be the following:
#Configuration for router 'RA'
!
hostname RA
password ****
!
router bgp 65001
no bgp default ipv4-unicast
neighbor 2001:0DB8::B remote-as 65002
neighbor 2001:0DB8::C remote-as 65003
!
address-family ipv6
network 2001:0DB8:AAAA:1::/64
network 2001:0DB8:AAAA:2::/64
network 2001:0DB8:0000:1::/64
network 2001:0DB8:0000:2::/64
neighbor 2001:0DB8::B activate
neighbor 2001:0DB8::B soft-reconfiguration inbound
neighbor 2001:0DB8::B route-map PEER-B-IN in
neighbor 2001:0DB8::B route-map PEER-B-OUT out
neighbor 2001:0DB8::C activate
neighbor 2001:0DB8::C soft-reconfiguration inbound
neighbor 2001:0DB8::C route-map PEER-C-IN in
neighbor 2001:0DB8::C route-map PEER-C-OUT out
exit-address-family
!
ipv6 prefix-list COMMON-PREFIXES seq 5 permit 2001:0DB8:0000::/48 ge 64 le 64
ipv6 prefix-list COMMON-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-A-PREFIXES seq 5 permit 2001:0DB8:AAAA::/48 ge 64 le 64
ipv6 prefix-list PEER-A-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-B-PREFIXES seq 5 permit 2001:0DB8:BBBB::/48 ge 64 le 64
ipv6 prefix-list PEER-B-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-C-PREFIXES seq 5 permit 2001:0DB8:CCCC::/48 ge 64 le 64
ipv6 prefix-list PEER-C-PREFIXES seq 10 deny any
!
route-map PEER-B-IN permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set metric 100
route-map PEER-B-IN permit 20
match ipv6 address prefix-list PEER-B-PREFIXES
set community 65001:11111
!
route-map PEER-C-IN permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set metric 200
route-map PEER-C-IN permit 20
match ipv6 address prefix-list PEER-C-PREFIXES
set community 65001:22222
!
route-map PEER-B-OUT permit 10
match ipv6 address prefix-list PEER-A-PREFIXES
!
route-map PEER-C-OUT permit 10
match ipv6 address prefix-list PEER-A-PREFIXES
!
line vty
!
Next: Configuration of the Route Server itself, Previous: Configuration of the BGP routers without Route Server, Up: Example of Route Server Configuration [Contents][Index]
12.3.2 Configuration of the BGP routers with Route Server
To convert the initial scenario into one with route server, first we mustmodify the configuration of routers RA, RB and RC. Now they must not peerbetween them, but only with the route server. For example, RA’sconfiguration would turn into:
# Configuration for router 'RA'
!
hostname RA
password ****
!
router bgp 65001
no bgp default ipv4-unicast
neighbor 2001:0DB8::FFFF remote-as 65000
!
address-family ipv6
network 2001:0DB8:AAAA:1::/64
network 2001:0DB8:AAAA:2::/64
network 2001:0DB8:0000:1::/64
network 2001:0DB8:0000:2::/64
neighbor 2001:0DB8::FFFF activate
neighbor 2001:0DB8::FFFF soft-reconfiguration inbound
exit-address-family
!
line vty
!
Which is logically much simpler than its initial configuration, as it nowmaintains only one BGP peering and all the filters (route-maps) havedisappeared.
Next: Further considerations about Import and Export route-maps, Previous: Configuration of the BGP routers with Route Server, Up: Example of Route Server Configuration [Contents][Index]
12.3.3 Configuration of the Route Server itself
As we said when we described the functions of a route server(see Description of the Route Server model), it is in charge of all theroute filtering. To achieve that, the In and Out filters from the RA, RB andRC configurations must be converted into Import and Export policies in theroute server.
This is a fragment of the route server configuration (we only showthe policies for client RA):
# Configuration for Route Server ('RS')
!
hostname RS
password ix
!
bgp multiple-instance
!
router bgp 65000 view RS
no bgp default ipv4-unicast
neighbor 2001:0DB8::A remote-as 65001
neighbor 2001:0DB8::B remote-as 65002
neighbor 2001:0DB8::C remote-as 65003
!
address-family ipv6
neighbor 2001:0DB8::A activate
neighbor 2001:0DB8::A route-server-client
neighbor 2001:0DB8::A route-map RSCLIENT-A-IMPORT import
neighbor 2001:0DB8::A route-map RSCLIENT-A-EXPORT export
neighbor 2001:0DB8::A soft-reconfiguration inbound
neighbor 2001:0DB8::B activate
neighbor 2001:0DB8::B route-server-client
neighbor 2001:0DB8::B route-map RSCLIENT-B-IMPORT import
neighbor 2001:0DB8::B route-map RSCLIENT-B-EXPORT export
neighbor 2001:0DB8::B soft-reconfiguration inbound
neighbor 2001:0DB8::C activate
neighbor 2001:0DB8::C route-server-client
neighbor 2001:0DB8::C route-map RSCLIENT-C-IMPORT import
neighbor 2001:0DB8::C route-map RSCLIENT-C-EXPORT export
neighbor 2001:0DB8::C soft-reconfiguration inbound
exit-address-family
!
ipv6 prefix-list COMMON-PREFIXES seq 5 permit 2001:0DB8:0000::/48 ge 64 le 64
ipv6 prefix-list COMMON-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-A-PREFIXES seq 5 permit 2001:0DB8:AAAA::/48 ge 64 le 64
ipv6 prefix-list PEER-A-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-B-PREFIXES seq 5 permit 2001:0DB8:BBBB::/48 ge 64 le 64
ipv6 prefix-list PEER-B-PREFIXES seq 10 deny any
!
ipv6 prefix-list PEER-C-PREFIXES seq 5 permit 2001:0DB8:CCCC::/48 ge 64 le 64
ipv6 prefix-list PEER-C-PREFIXES seq 10 deny any
!
route-map RSCLIENT-A-IMPORT permit 10
match peer 2001:0DB8::B
call A-IMPORT-FROM-B
route-map RSCLIENT-A-IMPORT permit 20
match peer 2001:0DB8::C
call A-IMPORT-FROM-C
!
route-map A-IMPORT-FROM-B permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set metric 100
route-map A-IMPORT-FROM-B permit 20
match ipv6 address prefix-list PEER-B-PREFIXES
set community 65001:11111
!
route-map A-IMPORT-FROM-C permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set metric 200
route-map A-IMPORT-FROM-C permit 20
match ipv6 address prefix-list PEER-C-PREFIXES
set community 65001:22222
!
route-map RSCLIENT-A-EXPORT permit 10
match peer 2001:0DB8::B
match ipv6 address prefix-list PEER-A-PREFIXES
route-map RSCLIENT-A-EXPORT permit 20
match peer 2001:0DB8::C
match ipv6 address prefix-list PEER-A-PREFIXES
!
...
...
...
If you compare the initial configuration of RA with the route serverconfiguration above, you can see how easy it is to generate the Import andExport policies for RA from the In and Out route-maps of RA’s originalconfiguration.
When there was no route server, RA maintained two peerings, one with RB andanother with RC. Each of this peerings had an In route-map configured. Tobuild the Import route-map for client RA in the route server, simply addroute-map entries following this scheme:
route-map <NAME> permit 10
match peer <Peer Address>
call <In Route-Map for this Peer>
route-map <NAME> permit 20
match peer <Another Peer Address>
call <In Route-Map for this Peer>
This is exactly the process that has been followed to generate the route-mapRSCLIENT-A-IMPORT. The route-maps that are called inside it (A-IMPORT-FROM-Band A-IMPORT-FROM-C) are exactly the same than the In route-maps from theoriginal configuration of RA (PEER-B-IN and PEER-C-IN), only the name isdifferent.
The same could have been done to create the Export policy for RA (route-mapRSCLIENT-A-EXPORT), but in this case the original Out route-maps where sosimple that we decided not to use the call WORD commands, and weintegrated all in a single route-map (RSCLIENT-A-EXPORT).
The Import and Export policies for RB and RC are not shown, butthe process would be identical.
Previous: Configuration of the Route Server itself, Up: Example of Route Server Configuration [Contents][Index]
12.3.4 Further considerations about Import and Export route-maps
The current version of the route server patch only allows to specify aroute-map for import and export policies, while in a standard BGP speakerapart from route-maps there are other tools for performing input and outputfiltering (access-lists, community-lists, ...). But this does not representany limitation, as all kinds of filters can be included in import/exportroute-maps. For example suppose that in the non-route-server scenario peerRA had the following filters configured for input from peer B:
neighbor 2001:0DB8::B prefix-list LIST-1 in
neighbor 2001:0DB8::B filter-list LIST-2 in
neighbor 2001:0DB8::B route-map PEER-B-IN in
...
...
route-map PEER-B-IN permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set local-preference 100
route-map PEER-B-IN permit 20
match ipv6 address prefix-list PEER-B-PREFIXES
set community 65001:11111
It is posible to write a single route-map which is equivalent tothe three filters (the community-list, the prefix-list and theroute-map). That route-map can then be used inside the Importpolicy in the route server. Lets see how to do it:
neighbor 2001:0DB8::A route-map RSCLIENT-A-IMPORT import
...
!
...
route-map RSCLIENT-A-IMPORT permit 10
match peer 2001:0DB8::B
call A-IMPORT-FROM-B
...
...
!
route-map A-IMPORT-FROM-B permit 1
match ipv6 address prefix-list LIST-1
match as-path LIST-2
on-match goto 10
route-map A-IMPORT-FROM-B deny 2
route-map A-IMPORT-FROM-B permit 10
match ipv6 address prefix-list COMMON-PREFIXES
set local-preference 100
route-map A-IMPORT-FROM-B permit 20
match ipv6 address prefix-list PEER-B-PREFIXES
set community 65001:11111
!
...
...
The route-map A-IMPORT-FROM-B is equivalent to the three filters(LIST-1, LIST-2 and PEER-B-IN). The first entry of route-mapA-IMPORT-FROM-B (sequence number 1) matches if and only if boththe prefix-list LIST-1 and the filter-list LIST-2 match. If thathappens, due to the “on-match goto 10” statement the nextroute-map entry to be processed will be number 10, and as of thatpoint route-map A-IMPORT-FROM-B is identical to PEER-B-IN. Ifthe first entry does not match, ‘on-match goto 10” will beignored and the next processed entry will be number 2, which willdeny the route.
Thus, the result is the same that with the three original filters,i.e., if either LIST-1 or LIST-2 rejects the route, it does notreach the route-map PEER-B-IN. In case both LIST-1 and LIST-2accept the route, it passes to PEER-B-IN, which can reject, acceptor modify the route.
Next: Filtering, Previous: Configuring Quagga as a Route Server, Up: Top [Contents][Index]
13 VTY shell
vtysh is integrated shell of Quagga software.
To use vtysh please specify —enable-vtysh to configure script. To usePAM for authentication use —with-libpam option to configure script.
vtysh only searches /etc/quagga path for vtysh.conf whichis the vtysh configuration file. Vtysh does not search currentdirectory for configuration file because the file includes userauthentication settings.
Currently, vtysh.conf has only two commands.
Next: VTY shell integrated configuration, Up: VTY shell [Contents][Index]
13.1 VTY shell username
- Command: username username nopassword
-
With this set, user foo does not need password authentication for user vtysh.With PAM vtysh uses PAM authentication mechanism.
If vtysh is compiled without PAM authentication, every user can use vtyshwithout authentication. vtysh requires read/write permissionto the various daemons vty sockets, this can be accomplished through useof unix groups and the –enable-vty-group configure option.
Previous: VTY shell username, Up: VTY shell [Contents][Index]
13.2 VTY shell integrated configuration
- Command: service integrated-vtysh-config
-
Write out integrated Quagga.conf file when ’write file’ is issued.
This command controls the behaviour of vtysh when it is told to write outthe configuration. Per default, vtysh will instruct each daemon to writeout their own config files when
write fileis issued. However, ifservice integrated-vtysh-configis set, whenwrite fileis issued, vtysh will instruct the daemons will write out a Quagga.conf withall daemons’ commands integrated into it.Vtysh per default behaves as if
write-conf daemonis set. Notethat both may be set at same time if one wishes to have both Quagga.conf anddaemon specific files written out. Further, note that the daemons arehard-coded to first look for the integrated Quagga.conf file before lookingfor their own file.We recommend you do not mix the use of the two types of files. Further, itis better not to use the integrated Quagga.conf file, as any syntax error init can lead to /all/ of your daemons being unable to start up. Per daemonfiles are more robust as impact of errors in configuration are limited tothe daemon in whose file the error is made.
14 Filtering
Quagga provides many very flexible filtering features. Filtering is usedfor both input and output of the routing information. Once filtering isdefined, it can be applied in any direction.
| • IP Access List: | ||
| • IP Prefix List: |
Next: IP Prefix List, Up: Filtering [Contents][Index]
14.1 IP Access List
Basic filtering is done by access-list as shown in thefollowing example.
access-list filter deny 10.0.0.0/9 access-list filter permit 10.0.0.0/8
Previous: IP Access List, Up: Filtering [Contents][Index]
14.2 IP Prefix List
ip prefix-list provides the most powerful prefix basedfiltering mechanism. In addition to
access-list functionality,ip prefix-list has prefix length range specification andsequential number specification. You can add or delete prefix basedfilters to arbitrary points of prefix-list using sequential number specification.
If no ip prefix-list is specified, it acts as permit. If ip prefix-list is defined, and no match is found, default deny is applied.
- Command: ip prefix-list name (permit|deny) prefix [le len] [ge len]
- Command: ip prefix-list name seq number (permit|deny) prefix [le len] [ge len]
-
You can create
ip prefix-listusing above commands.- seq
-
seq number can be set either automatically or manually. In thecase that sequential numbers are set manually, the user may pick anynumber less than 4294967295. In the case that sequential number are setautomatically, the sequential number will increase by a unit of five (5)per list. If a list with no specified sequential number is createdafter a list with a specified sequential number, the list willautomatically pick the next multiple of five (5) as the list number.For example, if a list with number 2 already exists and a new list withno specified number is created, the next list will be numbered 5. Iflists 2 and 7 already exist and a new list with no specified number iscreated, the new list will be numbered 10.
- le
-
lecommand specifies prefix length. The prefix list will be applied if the prefix length is less than or equal to the le prefix length. - ge
-
gecommand specifies prefix length. The prefix list will be applied if the prefix length is greater than or equal to the ge prefix length.
Less than or equal to prefix numbers and greater than or equal toprefix numbers can be used together. The order of the le and gecommands does not matter.
If a prefix list with a different sequential number but with the exactsame rules as a previous list is created, an error will result.However, in the case that the sequential number and the rules areexactly similar, no error will result.
If a list with the same sequential number as a previous list is created,the new list will overwrite the old list.
Matching of IP Prefix is performed from the smaller sequential number to thelarger. The matching will stop once any rule has been applied.
In the case of no le or ge command, the prefix length must match exactly thelength specified in the prefix list.
| • ip prefix-list description: | ||
| • ip prefix-list sequential number control: | ||
| • Showing ip prefix-list: | ||
| • Clear counter of ip prefix-list: |
Next: ip prefix-list sequential number control, Up: IP Prefix List [Contents][Index]
14.2.1 ip prefix-list description
- Command: ip prefix-list name description desc
-
Descriptions may be added to prefix lists. This command adds adescription to the prefix list.
- Command: no ip prefix-list name description [desc]
-
Deletes the description from a prefix list. It is possible to use thecommand without the full description.
Next: Showing ip prefix-list, Previous: ip prefix-list description, Up: IP Prefix List [Contents][Index]
14.2.2 ip prefix-list sequential number control
- Command: ip prefix-list sequence-number
-
With this command, the IP prefix list sequential number is displayed.This is the default behavior.
- Command: no ip prefix-list sequence-number
-
With this command, the IP prefix list sequential number is notdisplayed.
Next: Clear counter of ip prefix-list, Previous: ip prefix-list sequential number control, Up: IP Prefix List [Contents][Index]
14.2.3 Showing ip prefix-list
- Command: show ip prefix-list name seq num
-
Show IP prefix list can be used with a prefix list name and sequentialnumber.
- Command: show ip prefix-list name a.b.c.d/m
-
If the command longer is used, all prefix lists with prefix lengths equal toor longer than the specified length will be displayed.If the command first match is used, the first prefix length match will bedisplayed.
Previous: Showing ip prefix-list, Up: IP Prefix List [Contents][Index]
14.2.4 Clear counter of ip prefix-list
- Command: clear ip prefix-list
-
Clears the counters of all IP prefix lists. Clear IP Prefix List can beused with a specified name and prefix.
Next: IPv6 Support, Previous: Filtering, Up: Top [Contents][Index]
15 Route Map
Route maps provide a means to both filter and/or apply actions toroute, hence allowing policy to be applied to routes.
| • Route Map Command: | ||
| • Route Map Match Command: | ||
| • Route Map Set Command: | ||
| • Route Map Call Command: | ||
| • Route Map Exit Action Command: | ||
| • Route Map Examples: |
Route-maps are an ordered list of route-map entries. Each entry mayspecify up to four distincts sets of clauses:
- ‘Matching Policy’
-
This specifies the policy implied if the ‘Matching Conditions’ aremet or not met, and which actions of the route-map are to be taken, ifany. The two possibilities are:
- - ‘permit’: If the entry matches, then carry out the ‘SetActions’. Then finish processing the route-map, permitting the route,unless an ‘Exit Action’ indicates otherwise.
- - ‘deny’: If the entry matches, then finish processing the route-map anddeny the route (return ‘deny’).
The ‘Matching Policy’ is specified as part of the command whichdefines the ordered entry in the route-map. See below.
- ‘Matching Conditions’
-
A route-map entry may, optionally, specify one or more conditions whichmust be matched if the entry is to be considered further, as governedby the Match Policy. If a route-map entry does not explicitely specifyany matching conditions, then it always matches.
- ‘Set Actions’
-
A route-map entry may, optionally, specify one or more ‘SetActions’ to set or modify attributes of the route.
- ‘Call Action’
-
Call to another route-map, after any ‘Set Actions’ have beencarried out. If the route-map called returns ‘deny’ thenprocessing of the route-map finishes and the route is denied,regardless of the ‘Matching Policy’ or the ‘Exit Policy’. Ifthe called route-map returns ‘permit’, then ‘Matching Policy’and ‘Exit Policy’ govern further behaviour, as normal.
- ‘Exit Policy’
-
An entry may, optionally, specify an alternative ‘Exit Policy’ totake if the entry matched, rather than the normal policy of exiting theroute-map and permitting the route. The two possibilities are:
- - ‘next’: Continue on with processing of the route-map entries.
- - ‘goto N’: Jump ahead to the first route-map entry whose order inthe route-map is >= N. Jumping to a previous entry is not permitted.
The default action of a route-map, if no entries match, is to deny.I.e. a route-map essentially has as its last entry an empty ‘deny’entry, which matches all routes. To change this behaviour, one mustspecify an empty ‘permit’ entry as the last entry in the route-map.
To summarise the above:
| Match | No Match | |
|---|---|---|
| Permit | action | cont |
| Deny | deny | cont |
- ‘action’
-
- - Apply set statements
- - If call is present, call given route-map. If that returns a ‘deny’, finishprocessing and return ‘deny’.
- - If ‘Exit Policy’ is next, goto next route-map entry
- - If ‘Exit Policy’ is goto, goto first entry whose order in the listis >= the given order.
- - Finish processing the route-map and permit the route.
- ‘deny’
-
- - The route is denied by the route-map (return ‘deny’).
- ‘cont’
-
- - goto next route-map entry
Next: Route Map Match Command, Up: Route Map [Contents][Index]
15.1 Route Map Command
- Command: route-map route-map-name (permit|deny) order
-
Configure the order’th entry in route-map-name with‘Match Policy’ of either permit or deny.
Next: Route Map Set Command, Previous: Route Map Command, Up: Route Map [Contents][Index]
15.2 Route Map Match Command
Next: Route Map Call Command, Previous: Route Map Match Command, Up: Route Map [Contents][Index]
15.3 Route Map Set Command
- Route-map Command: set ipv6 next-hop global ipv6_address
-
Set the BGP-4+ global IPv6 nexthop address.
- Route-map Command: set ipv6 next-hop local ipv6_address
-
Set the BGP-4+ link local IPv6 nexthop address.
Next: Route Map Exit Action Command, Previous: Route Map Set Command, Up: Route Map [Contents][Index]
15.4 Route Map Call Command
- Route-map Command: call name
-
Call route-map name. If it returns deny, deny the route andfinish processing the route-map.
Next: Route Map Examples, Previous: Route Map Call Command, Up: Route Map [Contents][Index]
15.5 Route Map Exit Action Command
- Route-map Command: on-match next
- Route-map Command: continue
-
Proceed on to the next entry in the route-map.
- Route-map Command: on-match goto N
- Route-map Command: continue N
-
Proceed processing the route-map at the first entry whose order is >= N
Previous: Route Map Exit Action Command, Up: Route Map [Contents][Index]
15.6 Route Map Examples
A simple example of a route-map:
route-map test permit 10 match ip address 10 set local-preference 200
This means that if a route matches ip access-list number 10 it’slocal-preference value is set to 200.
See BGP Configuration Examples for examples of more sophisticateduseage of route-maps, including of the ‘call’ action.
Next: Kernel Interface, Previous: Route Map, Up: Top [Contents][Index]
16 IPv6 Support
Quagga fully supports IPv6 routing. As described so far, Quagga supportsRIPng, OSPFv3, and BGP-4+. You can give IPv6 addresses to an interfaceand configure static IPv6 routing information. Quagga IPv6 also providesautomatic address configuration via a feature
called addressauto configuration. To do it, the router must send router advertisementmessages to the all nodes that exist on the network.
Up: IPv6 Support [Contents][Index]
16.1 Router Advertisement
- Interface Command: ipv6 nd prefix ipv6prefix [valid-lifetime] [preferred-lifetime] [off-link] [no-autoconfig] [router-address]
-
Configuring the IPv6 prefix to include in router advertisements. Several prefixspecific optional parameters and flags may follow:
- valid-lifetime - the length of time in seconds during what the prefix isvalid for the purpose of on-link determination. Value
infinite representsinfinity (i.e. a value of all one bits (
0xffffffff)).Range:
<0-4294967295>Default:2592000 - preferred-lifetime - the length of time in seconds during what addressesgenerated from the prefix remain preferred. Value
infinite representsinfinity.
Range:
<0-4294967295>Default:604800 - off-link - indicates that advertisement makes no statement about on-link oroff-link properties of the prefix.
Default: not set, i.e. this prefix can be used for on-link determination.
- no-autoconfig - indicates to hosts on the local link that the specified prefixcannot be used for IPv6 autoconfiguration.
Default: not set, i.e. prefix can be used for autoconfiguration.
- router-address - indicates to hosts on the local link that the specified prefix contains a complete IP address by setting R flag.
Default: not set, i.e. hosts do not assume a complete IP address is placed.
- valid-lifetime - the length of time in seconds during what the prefix isvalid for the purpose of on-link determination. Value
infinite representsinfinity (i.e. a value of all one bits (
- Interface Command: ipv6 nd ra-interval <1-1800>
- Interface Command: no ipv6 nd ra-interval [<1-1800>]
-
The maximum time allowed between sending unsolicited multicast routeradvertisements from the interface, in seconds.
Default:
600
- Interface Command: ipv6 nd ra-interval msec <70-1800000>
- Interface Command: no ipv6 nd ra-interval [msec <70-1800000>]
-
The maximum time allowed between sending unsolicited multicast routeradvertisements from the interface, in milliseconds.
Default:
600000
- Interface Command: ipv6 nd ra-lifetime <0-9000>
- Interface Command: no ipv6 nd ra-lifetime [<0-9000>]
-
The value to be placed in the Router Lifetime field of router advertisementssent from the interface, in seconds. Indicates the usefulness of the routeras a default router on this interface. Setting the value to zero indicatesthat the router should not be considered a default router on this interface.Must be either zero or between value specified with ipv6 nd ra-interval(or default) and 9000 seconds.
Default:
1800
- Interface Command: ipv6 nd reachable-time <1-3600000>
- Interface Command: no ipv6 nd reachable-time [<1-3600000>]
-
The value to be placed in the Reachable Time field in the Router Advertisementmessages sent by the router, in milliseconds. The configured time enables therouter to detect unavailable neighbors. The value zero means unspecified (bythis router).
Default:
0
- Interface Command: ipv6 nd managed-config-flag
- Interface Command: no ipv6 nd managed-config-flag
-
Set/unset flag in IPv6 router advertisements which indicates to hosts that theyshould use managed (stateful) protocol for addresses autoconfiguration inaddition to any addresses autoconfigured using stateless addressautoconfiguration.
Default: not set
- Interface Command: ipv6 nd other-config-flag
- Interface Command: no ipv6 nd other-config-flag
-
Set/unset flag in IPv6 router advertisements which indicates to hosts thatthey should use administered (stateful) protocol to obtain autoconfigurationinformation other than addresses.
Default: not set
- Interface Command: ipv6 nd home-agent-config-flag
- Interface Command: no ipv6 nd home-agent-config-flag
-
Set/unset flag in IPv6 router advertisements which indicates to hosts thatthe router acts as a Home Agent and includes a Home Agent Option.
Default: not set
- Interface Command: ipv6 nd home-agent-preference <0-65535>
- Interface Command: no ipv6 nd home-agent-preference [<0-65535>]
-
The value to be placed in Home Agent Option, when Home Agent config flag is set, which indicates to hosts Home Agent preference. The default value of 0 standsfor the lowest preference possible.
Default: 0
- Interface Command: ipv6 nd home-agent-lifetime <0-65520>
- Interface Command: no ipv6 nd home-agent-lifetime [<0-65520>]
-
The value to be placed in Home Agent Option, when Home Agent config flag is set, which indicates to hosts Home Agent Lifetime. The default value of 0 means toplace the current Router Lifetime value.
Default: 0
- Interface Command: ipv6 nd adv-interval-option
- Interface Command: no ipv6 nd adv-interval-option
-
Include an Advertisement Interval option which indicates to hosts the maximum time, in milliseconds, between successive unsolicited Router Advertisements.
Default: not set
- Interface Command: ipv6 nd router-preference (high|medium|low)
- Interface Command: no ipv6 nd router-preference [(high|medium|low)]
-
Set default router preference in IPv6 router advertisements per RFC4191.
Default: medium
- Interface Command: ipv6 nd mtu <1-65535>
- Interface Command: no ipv6 nd mtu [<1-65535>]
-
Include an MTU (type 5) option in each RA packet to assist the attached hostsin proper interface configuration. The announced value is not verified to beconsistent with router interface MTU.
Default: don’t advertise any MTU option
interface eth0 no ipv6 nd suppress-ra ipv6 nd prefix 2001:0DB8:5009::/64
For more information see RFC2462 (IPv6 Stateless Address Autoconfiguration), RFC4861 (Neighbor Discovery for IP Version 6 (IPv6)), RFC6275 (Mobility Support in IPv6)and RFC4191 (Default Router Preferences and More-Specific Routes).
Next: SNMP Support, Previous: IPv6 Support, Up: Top [Contents][Index]
17 Kernel Interface
There are several different methods for reading kernel routing tableinformation, updating kernel routing tables, and for looking upinterfaces.
- ‘ioctl’
-
The ‘ioctl’ method is a very traditional way for reading or writingkernel information. ‘ioctl’ can be used for looking up interfacesand for modifying interface addresses, flags, mtu settings and othertypes of information. Also, ‘ioctl’ can insert and delete kernelrouting table entries. It will soon be available on almost any platformwhich zebra supports, but it is a little bit ugly thus far, so if abetter method is supported by the kernel, zebra will use that.
- ‘sysctl’
-
‘sysctl’ can lookup kernel information using MIB (ManagementInformation Base) syntax. Normally, it only provides a way of gettinginformation from the kernel. So one would usually want to change kernelinformation using another method such as ‘ioctl’.
- ‘proc filesystem’
-
‘proc filesystem’ provides an easy way of getting kernelinformation.
- ‘routing socket’
- ‘netlink’
-
On recent Linux kernels (2.0.x and 2.2.x), there is a kernel/usercommunication support called
netlink. It makes asynchronouscommunication between kernel and Quagga possible, similar to a routingsocket on BSD systems.Before you use this feature, be sure to select (in kernel configuration) the kernel/netlink support option ’Kernel/User network link driver’ and ’Routing messages’.
Today, the /dev/route special device file is obsolete. Netlinkcommunication is done by reading/writing over netlink socket.
After the kernel configuration, please reconfigure and rebuild Quagga.You can use netlink as a dynamic routing update channel between Quaggaand the kernel.
Next: Zebra Protocol, Previous: Kernel Interface, Up: Top [Contents][Index]
18 SNMP Support
SNMP (Simple Network Managing Protocol) is a widely implementedfeature for collecting network information from router and/or host.Quagga itself does not support SNMP agent (server daemon) functionalitybut is able to connect to a SNMP agent using the SMUX protocol(RFC1227) or the AgentX protocol (RFC2741) and make therouting protocol MIBs available through it.
| • Getting and installing an SNMP agent: | ||
| • AgentX configuration: | ||
| • SMUX configuration: | ||
| • MIB and command reference: | ||
| • Handling SNMP Traps: |
Next: AgentX configuration, Up: SNMP Support [Contents][Index]
18.1 Getting and installing an SNMP agent
There are several SNMP agent which support SMUX or AgentX. We recommend to use the latestversion of
net-snmp which was formerly known as ucd-snmp.It is free and open software and available at
http://www.net-snmp.org/and as binary package for most Linux distributions.net-snmp has to be compiled with
--with-mib-modules=agentx tobe able to accept connections from Quagga using AgentX protocol or with--with-mib-modules=smux to use SMUX protocol.
Nowadays, SMUX is a legacy protocol. The AgentX protocol should bepreferred for any new deployment. Both protocols have the same coverage.
Next: SMUX configuration, Previous: Getting and installing an SNMP agent, Up: SNMP Support [Contents][Index]
18.2 AgentX configuration
To enable AgentX protocol support, Quagga must have been build with the--enable-snmp or
--enable-snmp=agentx option. Both themaster SNMP agent (snmpd) and each of the Quagga daemons must beconfigured. In
/etc/snmp/snmpd.conf, master agentxdirective should be added. In each of the Quagga daemons,
agentxcommand will enable AgentX support.
/etc/snmp/snmpd.conf: # # example access restrictions setup # com2sec readonly default public group MyROGroup v1 readonly view all included .1 80 access MyROGroup "" any noauth exact all none none # # enable master agent for AgentX subagents # master agentx /etc/quagga/ospfd.conf: ! ... the rest of ospfd.conf has been omitted for clarity ... ! agentx !
Upon successful connection, you should get something like this in thelog of each Quagga daemons:
2012/05/25 11:39:08 ZEBRA: snmp[info]: NET-SNMP version 5.4.3 AgentX subagent connected
Then, you can use the following command to check everything works as expected:
# snmpwalk -c public -v1 localhost .1.3.6.1.2.1.14.1.1 OSPF-MIB::ospfRouterId.0 = IpAddress: 192.168.42.109 [...]
The AgentX protocol can be transported over a Unix socket or using TCPor UDP. It usually defaults to a Unix socket and depends on how NetSNMPwas built. If need to configure Quagga to use another transport, you canconfigure it through
/etc/snmp/quagga.conf:
/etc/snmp/quagga.conf: [snmpd] # Use a remote master agent agentXSocket tcp:192.168.15.12:705
Next: MIB and command reference, Previous: AgentX configuration, Up: SNMP Support [Contents][Index]
18.3 SMUX configuration
To enable SMUX protocol support, Quagga must have been build with the--enable-snmp=smux option.
A separate connection has then to be established between theSNMP agent (snmpd) and each of the Quagga daemons. This connectionseach use different OID numbers and passwords. Be aware that this OIDnumber is not the one that is used in queries by clients, it is solelyused for the intercommunication of the daemons.
In the following example the ospfd daemon will be connected to thesnmpd daemon using the password "quagga_ospfd". For testing it isrecommending to take exactly the below snmpd.conf as wrong accessrestrictions can be hard to debug.
/etc/snmp/snmpd.conf: # # example access restrictions setup # com2sec readonly default public group MyROGroup v1 readonly view all included .1 80 access MyROGroup "" any noauth exact all none none # # the following line is relevant for Quagga # smuxpeer .1.3.6.1.4.1.3317.1.2.5 quagga_ospfd /etc/quagga/ospf: ! ... the rest of ospfd.conf has been omitted for clarity ... ! smux peer .1.3.6.1.4.1.3317.1.2.5 quagga_ospfd !
After restarting snmpd and quagga, a successful connection can be verified inthe syslog and by querying the SNMP daemon:
snmpd[12300]: [smux_accept] accepted fd 12 from 127.0.0.1:36255 snmpd[12300]: accepted smux peer: \ oid GNOME-PRODUCT-ZEBRA-MIB::ospfd, quagga-0.96.5 # snmpwalk -c public -v1 localhost .1.3.6.1.2.1.14.1.1 OSPF-MIB::ospfRouterId.0 = IpAddress: 192.168.42.109
Be warned that the current version (5.1.1) of the Net-SNMP daemon writes a linefor every SNMP connect to the syslog which can lead to enormous log file sizes.If that is a problem you should consider to patch snmpd and comment out thetroublesome
snmp_log() line in the functionnetsnmp_agent_check_packet() in
agent/snmp_agent.c.
Next: Handling SNMP Traps, Previous: SMUX configuration, Up: SNMP Support [Contents][Index]
18.4 MIB and command reference
The following OID numbers are used for the interprocess communication of snmpd andthe Quagga daemons with SMUX only.
(OIDs below .iso.org.dod.internet.private.enterprises) zebra .1.3.6.1.4.1.3317.1.2.1 .gnome.gnomeProducts.zebra.zserv bgpd .1.3.6.1.4.1.3317.1.2.2 .gnome.gnomeProducts.zebra.bgpd ripd .1.3.6.1.4.1.3317.1.2.3 .gnome.gnomeProducts.zebra.ripd ospfd .1.3.6.1.4.1.3317.1.2.5 .gnome.gnomeProducts.zebra.ospfd ospf6d .1.3.6.1.4.1.3317.1.2.6 .gnome.gnomeProducts.zebra.ospf6d
Sadly, SNMP has not been implemented in all daemons yet. The followingOID numbers are used for querying the SNMP daemon by a client:
zebra .1.3.6.1.2.1.4.24 .iso.org.dot.internet.mgmt.mib-2.ip.ipForward ospfd .1.3.6.1.2.1.14 .iso.org.dot.internet.mgmt.mib-2.ospf bgpd .1.3.6.1.2.1.15 .iso.org.dot.internet.mgmt.mib-2.bgp ripd .1.3.6.1.2.1.23 .iso.org.dot.internet.mgmt.mib-2.rip2 ospf6d .1.3.6.1.3.102 .iso.org.dod.internet.experimental.ospfv3
The following syntax is understood by the Quagga daemons for configuring SNMP using SMUX:
Here is the syntax for using AgentX:
Previous: MIB and command reference, Up: SNMP Support [Contents][Index]
18.5 Handling SNMP Traps
To handle snmp traps make sure your snmp setup of quagga workscorrectly as described in the quagga documentation in See SNMP Support.
The BGP4 mib will send traps on peer up/down events. These should bevisible in your snmp logs with a message similar to:
‘snmpd[13733]: Got trap from peer on fd 14’
To react on these traps they should be handled by a trapsink. Configureyour trapsink by adding the following lines to /etc/snmpd/snmpd.conf:
# send traps to the snmptrapd on localhost trapsink localhost
This will send all traps to an snmptrapd running on localhost. You canof course also use a dedicated management station to catch traps.Configure the snmptrapd daemon by adding the following line to/etc/snmpd/snmptrapd.conf:
traphandle .1.3.6.1.4.1.3317.1.2.2 /etc/snmp/snmptrap_handle.sh
This will use the bash script /etc/snmp/snmptrap_handle.sh to handlethe BGP4 traps. To add traps for other protocol daemons, lookup theirappropriate OID from their mib. (For additional information about whichtraps are supported by your mib, lookup the mib onhttp://www.oidview.com/mibs/detail.html).
Make sure snmptrapd is started.
The snmptrap_handle.sh script I personally use for handling BGP4 trapsis below. You can of course do all sorts of things when handling traps,like sound a siren, have your display flash, etc., be creative ;).
#!/bin/bash
# routers name
ROUTER=`hostname -s`
#email address use to sent out notification
EMAILADDR="john@doe.com"
#email address used (allongside above) where warnings should be sent
EMAILADDR_WARN="sms-john@doe.com"
# type of notification
TYPE="Notice"
# local snmp community for getting AS belonging to peer
COMMUNITY="<community>"
# if a peer address is in $WARN_PEERS a warning should be sent
WARN_PEERS="192.0.2.1"
# get stdin
INPUT=`cat -`
# get some vars from stdin
uptime=`echo $INPUT | cut -d' ' -f5`
peer=`echo $INPUT | cut -d' ' -f8 | \
sed -e 's/SNMPv2-SMI::mib-2.15.3.1.14.//g'`
peerstate=`echo $INPUT | cut -d' ' -f13`
errorcode=`echo $INPUT | cut -d' ' -f9 | sed -e 's/\"//g'`
suberrorcode=`echo $INPUT | cut -d' ' -f10 | sed -e 's/\"//g'`
remoteas=`snmpget -v2c -c $COMMUNITY \
localhost SNMPv2-SMI::mib-2.15.3.1.9.$peer \
| cut -d' ' -f4`
WHOISINFO=`whois -h whois.ripe.net " -r AS$remoteas" | \
egrep '(as-name|descr)'`
asname=`echo "$WHOISINFO" | grep "^as-name:" | \
sed -e 's/^as-name://g' -e 's/ //g' -e 's/^ //g' | uniq`
asdescr=`echo "$WHOISINFO" | grep "^descr:" | \
sed -e 's/^descr://g' -e 's/ //g' -e 's/^ //g' | uniq`
# if peer address is in $WARN_PEER, the email should also
# be sent to $EMAILADDR_WARN
for ip in $WARN_PEERS; do
if [ "x$ip" == "x$peer" ]; then
EMAILADDR="$EMAILADDR,$EMAILADDR_WARN"
TYPE="WARNING"
break
fi
done
# convert peer state
case "$peerstate" in
1) peerstate="Idle" ;;
2) peerstate="Connect" ;;
3) peerstate="Active" ;;
4) peerstate="Opensent" ;;
5) peerstate="Openconfirm" ;;
6) peerstate="Established" ;;
*) peerstate="Unknown" ;;
esac
# get textual messages for errors
case "$errorcode" in
00)
error="No error"
suberror=""
;;
01)
error="Message Header Error"
case "$suberrorcode" in
01) suberror="Connection Not Synchronized" ;;
02) suberror="Bad Message Length" ;;
03) suberror="Bad Message Type" ;;
*) suberror="Unknown" ;;
esac
;;
02)
error="OPEN Message Error"
case "$suberrorcode" in
01) suberror="Unsupported Version Number" ;;
02) suberror="Bad Peer AS" ;;
03) suberror="Bad BGP Identifier" ;;
04) suberror="Unsupported Optional Parameter" ;;
05) suberror="Authentication Failure" ;;
06) suberror="Unacceptable Hold Time" ;;
*) suberror="Unknown" ;;
esac
;;
03)
error="UPDATE Message Error"
case "$suberrorcode" in
01) suberror="Malformed Attribute List" ;;
02) suberror="Unrecognized Well-known Attribute" ;;
03) suberror="Missing Well-known Attribute" ;;
04) suberror="Attribute Flags Error" ;;
05) suberror="Attribute Length Error" ;;
06) suberror="Invalid ORIGIN Attribute" ;;
07) suberror="AS Routing Loop" ;;
08) suberror="Invalid NEXT_HOP Attribute" ;;
09) suberror="Optional Attribute Error" ;;
10) suberror="Invalid Network Field" ;;
11) suberror="Malformed AS_PATH" ;;
*) suberror="Unknown" ;;
esac
;;
04)
error="Hold Timer Expired"
suberror=""
;;
05)
error="Finite State Machine Error"
suberror=""
;;
06)
error="Cease"
case "$suberrorcode" in
01) suberror="Maximum Number of Prefixes Reached" ;;
02) suberror="Administratively Shutdown" ;;
03) suberror="Peer Unconfigured" ;;
04) suberror="Administratively Reset" ;;
05) suberror="Connection Rejected" ;;
06) suberror="Other Configuration Change" ;;
07) suberror="Connection collision resolution" ;;
08) suberror="Out of Resource" ;;
09) suberror="MAX" ;;
*) suberror="Unknown" ;;
esac
;;
*)
error="Unknown"
suberror=""
;;
esac
# create textual message from errorcodes
if [ "x$suberror" == "x" ]; then
NOTIFY="$errorcode ($error)"
else
NOTIFY="$errorcode/$suberrorcode ($error/$suberror)"
fi
# form a decent subject
SUBJECT="$TYPE: $ROUTER [bgp] $peer is $peerstate: $NOTIFY"
# create the email body
MAIL=`cat << EOF
BGP notification on router $ROUTER.
Peer: $peer
AS: $remoteas
New state: $peerstate
Notification: $NOTIFY
Info:
$asname
$asdescr
Snmpd uptime: $uptime
EOF`
# mail the notification
echo "$MAIL" | mail -s "$SUBJECT" $EMAILADDR
Next: Packet Binary Dump Format, Previous: SNMP Support, Up: Top [Contents][Index]
Appendix A Zebra Protocol
A.1 Overview of the Zebra Protocol
Zebra Protocol is used by protocol daemons to communicate with thezebra daemon.
Each protocol daemon may request and send information to and from thezebra daemon such as interface states, routing state,nexthop-validation, and so on. Protocol daemons may also install routeswith zebra. The zebra daemon manages which route is installed into theforwarding table with the kernel.
Zebra Protocol is a streaming protocol, with a common header. Twoversions of the header are in use. Version 0 is implicitely versioned.Version 1 has an explicit version field. Version 0 can be distinguishedfrom all other versions by examining the 3rd byte of the header, whichcontains a marker value for all versions bar version 0. The marker bytecorresponds to the command field in version 0, and the marker value isa reserved command in version 0.
We do not anticipate there will be further versions of the header forthe foreseeable future, as the command field in version 1 is wideenough to allow for future extensions to done compatibly throughseperate commands.
Version 0 is used by all versions of GNU Zebra as of this writing, andversions of Quagga up to and including Quagga 0.98. Version 1 will beused as of Quagga 1.0.
A.2 Zebra Protocol Definition
A.2.1 Zebra Protocol Header (version 0)
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-------------------------------+---------------+ | Length (2) | Command (1) | +-------------------------------+---------------+
A.2.2 Zebra Protocol Common Header (version 1)
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-------------------------------+---------------+-------------+ | Length (2) | Marker (1) | Version (1) | +-------------------------------+---------------+-------------+ | Command (2) | +-------------------------------+
A.2.3 Zebra Protocol Header Field Definitions
- ‘Length’
-
Total packet length including this header. The minimum length is 3bytes for version 0 messages and 6 bytes for version 1 messages.
- ‘Marker’
-
Static marker with a value of 255 always. This is to allow version 0Zserv headers (which do not include version explicitely) to bedistinguished from versioned headers. Not present in version 0messages.
- ‘Version’
-
Version number of the Zserv message. Clients should not continueprocessing messages past the version field for versions they do notrecognise. Not present in version 0 messages.
- ‘Command’
-
The Zebra Protocol command.
A.2.4 Zebra Protocol Commands
| Command | Value |
|---|---|
| ZEBRA_INTERFACE_ADD | 1 |
| ZEBRA_INTERFACE_DELETE | 2 |
| ZEBRA_INTERFACE_ADDRESS_ADD | 3 |
| ZEBRA_INTERFACE_ADDRESS_DELETE | 4 |
| ZEBRA_INTERFACE_UP | 5 |
| ZEBRA_INTERFACE_DOWN | 6 |
| ZEBRA_IPV4_ROUTE_ADD | 7 |
| ZEBRA_IPV4_ROUTE_DELETE | 8 |
| ZEBRA_IPV6_ROUTE_ADD | 9 |
| ZEBRA_IPV6_ROUTE_DELETE | 10 |
| ZEBRA_REDISTRIBUTE_ADD | 11 |
| ZEBRA_REDISTRIBUTE_DELETE | 12 |
| ZEBRA_REDISTRIBUTE_DEFAULT_ADD | 13 |
| ZEBRA_REDISTRIBUTE_DEFAULT_DELETE | 14 |
| ZEBRA_IPV4_NEXTHOP_LOOKUP | 15 |
| ZEBRA_IPV6_NEXTHOP_LOOKUP | 16 |
Next: Command Index, Previous: Zebra Protocol, Up: Top [Contents][Index]
Appendix B Packet Binary Dump Format
Quagga can dump routing protocol packet into file with a binary format(see Dump BGP packets and table).
It seems to be better that we share the MRT’s header format forbackward compatibility with MRT’s dump logs. We should also define thebinary format excluding the header, because we must support both IPv4 and v6 addresses as socket addresses and / or routing entries.
In the last meeting, we discussed to have a version field in theheader. But Masaki told us that we can define new ‘type’ value ratherthan having a ‘version’ field, and it seems to be better because wedon’t need to change header format.
Here is the common header format. This is same as that of MRT.
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Time | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Type | Subtype | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
If ‘type’ is PROTOCOL_BGP4MP_ET, the common header format willcontain an additional microsecond field (RFC6396 2011).
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Time | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Type | Subtype | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Microsecond | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
If ‘type’ is PROTOCOL_BGP4MP, ‘subtype’ is BGP4MP_STATE_CHANGE, andAddress Family == IP (version 4)
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source AS number | Destination AS number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Interface Index | Address Family | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Old State | New State | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Where State is the value defined in RFC1771.
If ‘type’ is PROTOCOL_BGP4MP, ‘subtype’ is BGP4MP_STATE_CHANGE,and Address Family == IP version 6
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source AS number | Destination AS number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Interface Index | Address Family | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Old State | New State | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
If ‘type’ is PROTOCOL_BGP4MP, ‘subtype’ is BGP4MP_MESSAGE,and Address Family == IP (version 4)
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source AS number | Destination AS number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Interface Index | Address Family | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | BGP Message Packet | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Where BGP Message Packet is the whole contents of theBGP4 message including header portion.
If ‘type’ is PROTOCOL_BGP4MP, ‘subtype’ is BGP4MP_MESSAGE,and Address Family == IP version 6
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source AS number | Destination AS number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Interface Index | Address Family | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination IP address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination IP address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | BGP Message Packet | | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
If ‘type’ is PROTOCOL_BGP4MP, ‘subtype’ is BGP4MP_ENTRY,and Address Family == IP (version 4)
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | View # | Status | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Time Last Change | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Address Family | SAFI | Next-Hop-Len | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Next Hop Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Prefix Length | Address Prefix [variable] | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Attribute Length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | BGP Attribute [variable length] | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
If ‘type’ is PROTOCOL_BGP4MP, ‘subtype’ is BGP4MP_ENTRY,and Address Family == IP version 6
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | View # | Status | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Time Last Change | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Address Family | SAFI | Next-Hop-Len | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Next Hop Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Next Hop Address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Next Hop Address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Next Hop Address (Cont'd) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Prefix Length | Address Prefix [variable] | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Address Prefix (cont'd) [variable] | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Attribute Length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | BGP Attribute [variable length] | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
BGP4 Attribute must not contain MP_UNREACH_NLRI.If BGP Attribute has MP_REACH_NLRI field, it must haszero length NLRI, e.g., MP_REACH_NLRI has only AddressFamily, SAFI and next-hop values.
If ‘type’ is PROTOCOL_BGP4MP and ‘subtype’ is BGP4MP_SNAPSHOT,
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | View # | File Name [variable] | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
The file specified in "File Name" contains all routing entries, which are in the format of “subtype == BGP4MP_ENTRY”.
Constants: /* type value */ #define MSG_PROTOCOL_BGP4MP 16 #define MSG_PROTOCOL_BGP4MP_ET 17 /* subtype value */ #define BGP4MP_STATE_CHANGE 0 #define BGP4MP_MESSAGE 1 #define BGP4MP_ENTRY 2 #define BGP4MP_SNAPSHOT 3
Next: VTY Key Index, Previous: Packet Binary Dump Format, Up: Top [Contents][Index]
Command Index
Next: Index, Previous: Command Index, Up: Top [Contents][Index]
VTY Key Index
Previous: VTY Key Index, Up: Top [Contents][Index]
Index
Footnotes
(1)
GNU/Linux has very flexible kernel configuration features
(2)
For some set of objects to havean order, there must be some binary ordering relation that is definedfor every combination of those objects, and that relation mustbe transitive. I.e., if the relation operator is ≺, and if a ≺ b and b ≺ c then that relation must carry overand it must be that a ≺ c for the objects to have anorder. The ordering relation may allow for equality, i.e. a ≺ b and b ≺ a may both be true amd imply thata and b are equal in the order and not distinguished by it, inwhich case the set has a partial order. Otherwise, if there is an order,all the objects have a distinct place in the order and the set has a totalorder.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通