

Hyper容器云及云上运维
http://geek.csdn.net/news/detail/204184
导读:和Docker不同,Hyper通过直接把虚机跟Docker Image对接起来,解决了容器技术的安全性问题,再利用技术手段解决了Hyper的轻量化问题。在Docker技术安全性等广受诟病的背景下,Hyper的出现给开发者们提供了一种新的思路。
作为一家专注于虚拟化容器技术的创业公司,可以说在国内的容器创业圈里算是比较独特的。截至目前,除了自主打造了一套兼容OCI的容器Runtime,在Github上维护了若干个开源项目之外,我们还做了一套公有云服务(https://hyper.sh)。
关于Hyper,大家比较好奇,本文将从三个方面重点分享Hyper的原理和容器云运维:从Docker到Hyper Container,Hyper Container用于公有云,容器云上运维的变化。
从Docker到Hyper Container
Docker大家应该非常熟悉,四年前,从一个相对单纯的runtime发展到今天,包含集群管理、容器编排、各种网络/存储插件等复杂的生态系统,甚至连操作系统打包都给放进去了(前不久DockerCon上发布的LinuxKit)。Docker这项技术出来之后受到大家极大地关注和追捧,可以说引发了众多领域的巨大变革,各种聚焦容器技术的开源项目、创业公司更是如雨后春笋。
但是,我们把目光回到最初,Docker刚开始出来的时候,它的本质是什么?我们认为, Docker本质上由两大块组成:容器技术 + Docker Image。
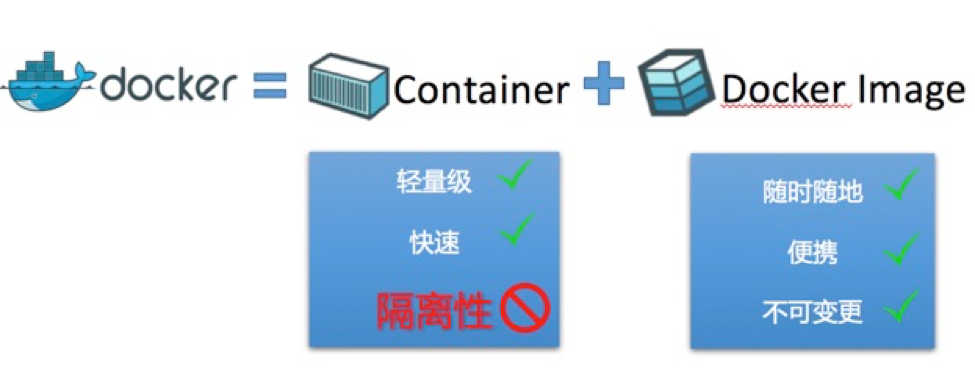
Docker Image是Docker最天才的一项创造。虽然它所用到的各种技术是之前就有的,但把这些技术以这样的姿势组合起来,之前真的是没有人想到。我们可以认为这是一种新的应用打包方式,但是它又超越了以前传统的RPM、DEB打包,RPM、DEB只是把应用的文件堆在一起,顶多再加上一些Pre-install、Post-install脚本,外部通Yum、Apt来解决依赖关系。而Docker Image不仅仅是把应用的文件给打进去,还包括了这个应用所有的依赖,再底下就是内核了。而且不止如此,它还把应用运行的一些信息,比如User、worker DIR等都给放进去,非常规范地把这个应用的方方面面都给描述出来,这个是一项前所未有的技术。
而容器技术,最早Docker用的就是LXC,跟我们广泛使用的虚拟机相比,它看起来很像虚拟机,但比虚拟机轻很多,创建速度为毫秒级。非常轻量,没有虚拟机vCPU、内存等方面的性能损耗,但同时它的缺点就是隔离度比虚拟机要弱很多,因为容器是利用内核的Namespace、Cgroup等技术来进行环境的隔离和资源的限制,一个宿主上的所有容器共享同一个内核,相对而言攻击面就会大很多。
关于这一点,圈内有很多争议,有人认为容器的安全性可以不断改进,最终达到一个可用的程度,但另一派就觉得由于它的原理是共享内核,所以从根本上就不可能做到足够的安全。争论很多,但无论如何,“容器的隔离性比虚机弱”是业界的共识,如果实在不放心,就把容器放到虚机里面去用吧。事实上这也是几乎所有公有云提供容器运行的方式:先给用户创建虚机,然后再在虚机里面跑用户的容器。没有公有云敢冒险直接在物理机上起容器分给多个租户去用。
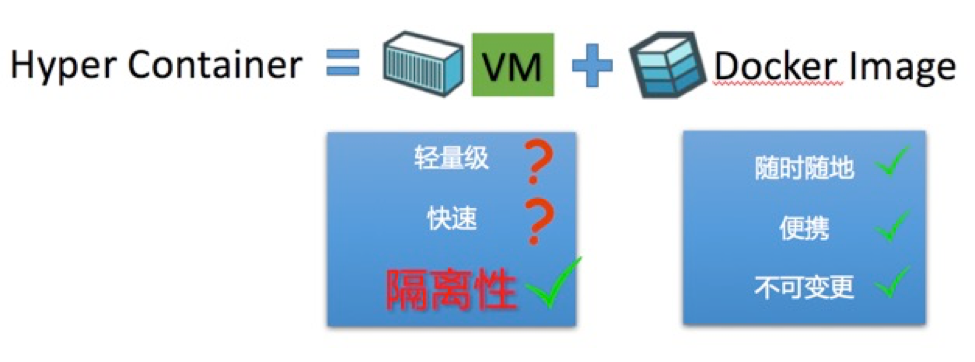
既然如此,我们就产生了一个想法:可否直接把虚机跟Docker Image对接起来?回过头来想,容器的本质到底是什么?我们认为容器的本质,其实是边界。举一个生活中的例子,我们拿一个杯子去装水,这个杯子有底、有侧边,这个底和侧边就把杯子里外的空间隔离开了,我们称之为一个容器。对于LXC而言,它是通过Namespace来做边界;而对于VM,如果把虚拟的硬件当做边界,VM也可以看做一种容器。只不过LXC是一个比较易碎的玻璃杯,甚至是纸杯,而VM则是更加坚固的不锈钢杯子。我们用VM替换LXC直接跟Docker Image对接,就得到了虚拟化容器,我们称之为Hyper Container。这样一来,隔离性的问题就解决了。但同时它还能不能保持之前的轻量和快速,这是需要考虑的问题。
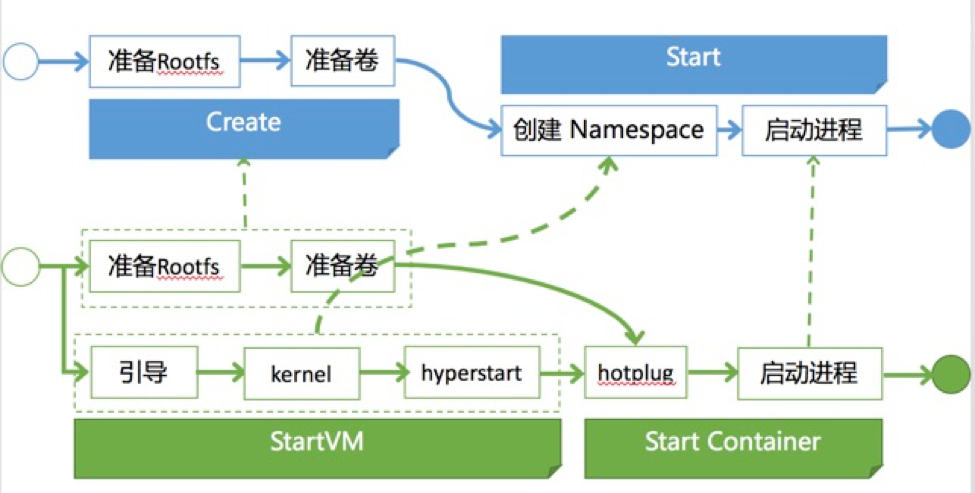
我们先看一下如何把虚机和Docker Image进行对接。这是Hyper容器启动的一个对比,上面是Docker容器,下面是Hyper容器。Docker容器起动的时候,先从Docker Image创建Rootfs,准备数据卷(如果有需要的话),这是Create过程。然后调用内核接口去创建Namespace、设置CGroup、启动APP进程,容器就起来了。而我们的Hyper容器呢?首先,准备Rootfs和数据卷部分,跟Docker是一样的。同时我们会起一个非常精简的虚机,没有完整的操作系统,只有一个Init(HyperStart)进程,然后把准备好的Rootfs和数据卷目录映射到虚机里,由HyperStart去起应用进程,整个虚机的资源都给这个应用,这样就把虚机跟Docker Image对接起来了。
接下来,我们来Hyper解决轻量和快速的问题。显然Hyper Container比LXC要重,我们需要想办法尽量使它轻量化。
首先,加快容器启动速度。起一个虚机大概需要两三秒,虽然时间也不太长,但比容器还是慢多了,怎样加快呢?1,精简VM配置和内核;2,我们做了一个VM Cache功能,预先准备虚机池,用户Run容器的时候,直接从虚机池里选取,再动态调CPU和内存。最终我们把Run一个容器的时间缩短到了300多毫秒,跟LXC差不多了。
另一方面,降低内存开销。每一个虚机都有自己的内核和Initrd,会占用一部分内存,如果宿主上同时Running几十上百个容器,这个消耗不容忽视。怎么办呢?我们的内核大牛又搞出了一项技术,就是让同一台宿主上的所有Hyper Container共享同一份内核和Initrd,大大减少了内存开销。最终效果就是每个Hyper Container额外的内存开销小于10M。
通过上述努力,Hyper Container终于做到了既轻快,又安全,完美地解决了问题。怎么样,完美吗?大家都是搞技术的,实事求是讲,没有完美的方案。大家可以看出来,Hyper Container毕竟是在虚拟机里面跑应用,跟物理机里直接跑LXC容器相比,性能上还是会打个折扣。鱼和熊掌不可兼得,一定是舍弃一些东西、取得一些东西,抛开实际场景去谈方案的优劣都是耍流氓。
Hyper Container用于公有云
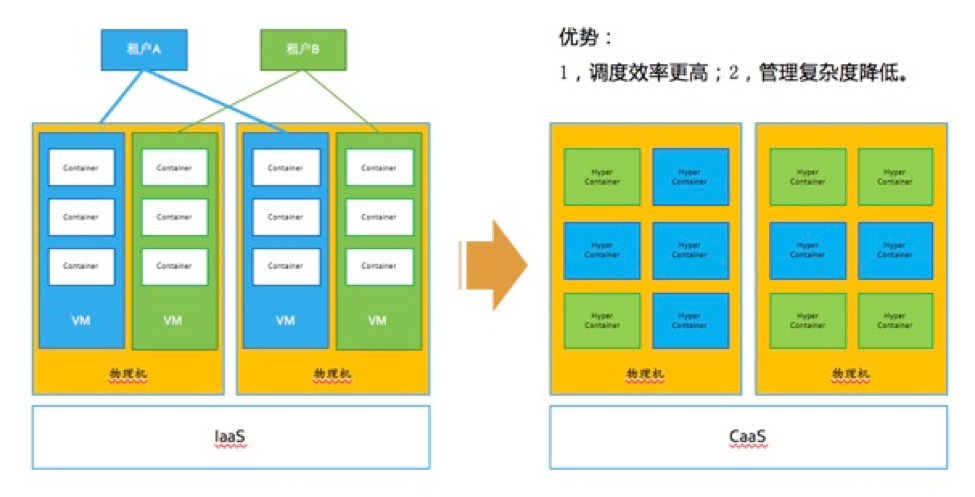
应该说,Hyper Container最合适的场景是在公有云上。前面也提到了,目前市面上所有的公有云提供容器的服务,都是先给用户创建虚拟机集群,再在集群上面构建容器平台,然后再去跑容器。这个层次结构就比较复杂,因为在公有云上,安全是必须要考虑的问题。假如直接在物理机上起容器分给多租户,某一个租户的容器被人黑进来了,就很可能突破容器的隔离进而控制整个宿主,这个后果是很严重的。但如果使用了Hyper Container,就可以把用户容器直接跑在物理机上,因为Hyper Container是虚机级别的隔离度。这样一来,云的部署架构就可以很大地简化,可以只留一层调度。从用户视角来看,管理的复杂度也大大降低了,因为不用再关心集群的事情,直接就使用容器。
基于这个想法,我们做了一个开源项目:把Kubernetes、Hyper Container、OpenStack整合在一起,最终产生了一个我们称之为Hypernetes的项目(https://github.com/hyperhq/hypernetes)。然后又基于这个项目构建了我们自己的公有容器云服务(https://hyper.sh)。应该说我们这个容器云还是挺独特的,可以认为它是一个云版的Docker。用户使用前需要下载安装一个客户端(hyper),这个客户端的命令跟Docker非常接近,熟悉Docker用法的朋友,可以很平滑的使用hyper。不同之处在于,这个hyper客户端虽然装在用户的电脑上运行,但它的所有操作最终都落在我们的云端,直接操作云上的资源。从用户的视角看,就好像拥有一台资源无限的主机,只需要按自己的需求创建、使用和销毁容器就好了,而不用操心这个主机的运行状况好不好、还有多少资源、Docker Deamon要不要升级等等,这是我们最大的理念。
有了这个最基本的功能之后,我们又做了一些比较上层的建筑:1,Hyper Compose,兼容Docker Compose规范,本地Docker Compose到云上无缝过渡;2,Hyper Service,源自Kubernetes的概念;3,Hyper Cron,这是一个比较独特的服务,就像在Linux里设定Cron任务一样,可以在我们的云上来设定在什么时间Run什么样的容器;4,Hyper Func,一个以Docker为中心的Serverless解决方案。
容器云上运维的变化
最后想分享一下我对于容器时代运维的一些思考。在容器时代,很多运维理念跟以前不太一样了。
- 资源视角。以前,资源就是机器,不管是物理机还是虚机。但是在容器云上不再有机器的概念了,只需要考虑这个应用需要多少资源,就创建多大的容器,这个是一个很大的变化。
- 环境配置管理。传统的运维都会有一套配置管理的工具(例如Puppet)来保证集群中每台机器的配置一致,但是在容器时代,一个应用所需要的依赖、配置全部打包进镜像里了,Puppet就不再需要了。不过呢,容器镜像的打包、存储、分发也是需要整套的流程,这个事情其实并不简单,复杂度甚至可能更高。
- 应用的变更。传统的运维方式,就是就是把应用的二进制文件编译好了扔到服务器上,替换旧的,重启服务,发现有问题赶紧把旧文件换回来,回滚服务,这是典型的变更方式。到了容器时代还是变成了镜像,要升级一个服务时候,重新Build镜像,分发,重新创建容器。
- Metrics 信息收集/监控。传统的方式,在机器上放Agent,收集各种Metrics,包括应用进程的信息。而用容器部署之后,应用都放进容器里了,原先收集信息的方式可能就不灵了。容器有它的一套规范。
综合起来看,每一个方面,使用容器后并不一定变得更简单,有时反而会变复杂。我认为很长时间内这两种部署方式还会同时并存。不过从长远看,把容器各方面汇总起来作为一个完整的生态去看,它带来的总的好处还是会超过付出的成本。一开始运维可能很不适应,但是我相信未来的趋势是容器,我们要往这个方向去努力。
作者简介:裴彤,Hyper运维负责人,本文来自他在CSDN主办的CCTC 2017容器与运维峰会上的演讲整理,详情点击这里



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通