

JavaScript语法 第十四章
客户端JavaScript的存在使得静态的HTML文档变成了交互式的web应用。脚本化web页面内容是JavaScript的可信目标。这一章解释了每一个web浏览器窗口、标签页和框架由一个window对象所表示。每个window对象都是有一个document属性引用了Document对象。Document对象表示窗口的内容。Document对象并非独立的,他是一个巨大的API中的核心对象,叫做文档对象模型(Document Object Model,DOM),它代表和操作文档的内容。
14.1 DOM概览
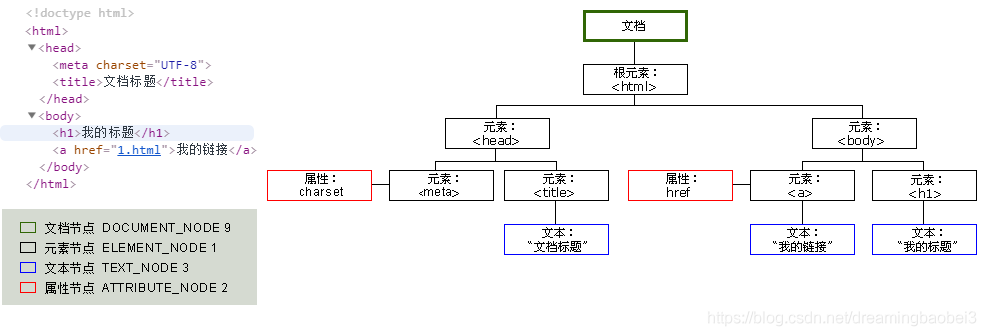
文件对象模型(DOM)是表示和操作HTML和xml文档内容的基础API。API不是特别复杂,但是需要理解大量的架构细节。首先,应该理解HTML或XML文件嵌套元素在DOM树对象中的表示。HTML文档的树状结构包含代表HTML标签或元素(如<body>、<p>)和表示文本字符的节点,他也可能包含表示HTML注解的结点。
这是文档DOM表示的树状图
14.2 选取文档元素
大多数客户端JavaScript程序运行时总是在操作一个或者多个文档元素。当这些程序启动时,可以使用全局变量document来引用Document来引用Document对象。但是,为了操作文档的元素,必须通过某种方式获取或者选取引用文档元素的Element对象。DOM定义许多方式来选取元素,查询文档的一个或多个元素的方式有如下方式:
-
用指定的id属性
-
用指定的name属性
-
用指定的标签名字
-
用指定的css类
-
匹配指定的css选择器
14.2.1 通过ID选取元素
任何HTML元素可以有一个id属性,在文档中该值必须唯一,即同一个文档中的两个元素不能有相同的ID。可以使用Document对象的getElementById()方法选取一个基于唯一ID的元素。比如:
var section=documnet.getElementById("section")
这是最简单的和常用的选取元素的方法,如果想要操作某一组指定的文档元素,提供这些元素的id属性值,并使用ID查找这些Element对象。如果需要通过ID查找很多个元素,会发现getElements()函数非常好用。
/*
* 函数接受任意多的字符串参数
* 每个参数将当做元素的id传给document.getElentById()
* 返回一个对象,它把这些id映射搭配对应的
* 如任何一个id对应的元素未定义,则抛出一个Error对象
*/
function getElements(/*ids*/){
var element={}; // 开始是一个空map映射对象
for (var i=0;i<arguments.length;i++){ //循环每个参数
var elt=document.getElementById(id); //参数是元素的id
if (elt==null) // 查找元素
throw new Error("No element eith id:"+id); // 抛出异常
element[id]=elt; // id和元素之间映射
}
return elements; // 对于元素映射返回id
}
14.2.2 通过姓名选取元素
HTML的name属性最初打算是为表单元素分配名字,咋表单数据提交到服务器时使用该属性的值。类似id属性,那么时给元素分配姓名,但是区别于id、name属性的值不是必须唯一;多个元素可以有相同的名字,在表单中,单选和复选按钮通常是这种情况。而且,和id不一样的时那么属性只在少数HTML元素中有效,包括表单、表单元素、<ifrmae>和<img> 元素。
基于name属性的值选取HTML元素,可以使用Document对象的getElementByName()方法。
var radiobuttons=ducument.getElemmentsByName("fav_clr")
getElemtByName()定义在HTMLDocument类中,而不是Document()中,使用它只针对HTML文档可用,在XML文档中不可用。它返回一个NodeList对象,后者的行为类似一个包含若干Element对象的只读数组。在IE中,getElementByName()也返回id属性匹配指定值的元素。
如果给定的名字只有一个元素,自动创建的文档属性对应的该值时元素本身。如果有多个元素,该文档属性的值是一个NodeList对象,它表现为一个包含这些元素的数组。为若干命名<iframe>元素所创建的文档属性比较特殊;它们指代这些框架的Window对象而不是Element对象。这就意味着这些元素可以作为Document属性仅通过名字来选取:
// 针对<form name="shipping">元素,得到Element对象
var form =documnet.shipping;
14.2.3 通过标签名选取元素
Document对象的getElementByTagName()方法可用来选取指定类型(标签名)的所有HTML或XML元素。
var spans=document.getElementByTagName('span');
// 在文档中获取包含所有<span>元素的只读类型组对象
类似于getElemtByName(),getElementByTagName()返回一个NodeList对象。在NodeList中返回的元素按照在文档中的顺序排序的。
var first=document.getElementByTagName("p")[0];
// 选取文档中的第一个<P>元素
Element类也定义getElementByTagName()方法,其原理和Document版本的一样。但是它只选取调用该方法的元素的后代元素。音系,要查找文档中第一个<p>元素里面的所有<span>元素。
var first=document.getElementByTagName('p')[0];
var firstspan=first.getElementByTagName('span');
14.2.4 通过css类选取元素
HTML元素的class属性值时一个以空格隔开的列表,可用为空或者包含多个标识符。它描述一种方法来定义多做相关的文档元素:在他们的class属性中有相同的标识符的任何元素属于该组的一部分。在JavaScript中class是保留字,属于客户端JavaScript使用className属性来保存HTML的class属性值。class属性通常于css样式表一起使用,对某组内的所有元素应用相同的样式,尽管如此,HTML定义了getElementByClassName()方法,它基于其class属性值中的标识符来选取成组的文档元素。
// 查找其class属性值中包含“warning”的所有元素
var warning =document.getElementByClassName("warning");
// 查找以“log”命名并且有“error”和“fa”类的元素的所有后代
var log=document.getElementById("log");
var fat=log,getElementByClassName("fa error");
14.2.5 通过css选择器选取元素
css样式表有一种非常强大的语法,那就是选择器,他用来描述文档中的若干或多组元素。
// 元素可以用ID、标签名或类来描述
# nav // id='nav'的元素
div // 所有<div>元素
.warning // 所有在class属性值中包含“warning”的元素
// 元素可以基于属性值来选取
p[lang='fr'] // 所有使用语法的段落,如:<p lang='fr'>
这个API的关键是Document方法querySelectorAll()。他接受包含了一个css选择器的字符串参数,返回一个表示文档中匹配选择器的所有元素的NodeList对象。querySelectrAll()f返回的NodeList对象并不是实时的:它包含在调用时刻选择器所匹配的元素,但它并不更新后续文档的变化。
14.3 文档结构和遍历
一旦从文档中选取一个元素,有时需要查找文档中与之在结构上相关的部分(父亲,兄弟和子女)。
14.3.1 作为节点树的文档
Document对象,它的Element对象和文档中表示的Text对象都是Node对象。
(1)parentNodes
该节点的父节点,或者针对类似Document对象一个是null,因为它没有父节点
(2)childNodes
只读的类素组对象(NodeLsit对象),他是该结点的子节点实时表示。
(3) firstChild、lastChild
该节点的子节点中的第一个和最后一个,如果该节点没有子节点则为null。
(4)nextSbling、previousSibling
该节点的兄弟节点中的前一个和下一个。具有相同父节点的两个节点为兄弟节点。节点的顺序反映了它们在文档中出现的顺序。这两个属性将节点之间以双向链表的形式连接起来。
(5)nodeType
该节点的类型。9表示Document节点,1表示Element节点,3表示Text节点,8表示Comment节点,11表示DocumentFragment节点。
(6)nodeValue
Text节点或Cemment节点的文本内容
(7)nodeName
元素的标签名、以大写形式表示
使用这些Node属性,可以用以下类似的表达式的到文档的第一个子节点下面的第二个子节点的引用。
document.childNode[0].childNodes[1]
14.3.2 作为元素树的文档
当将主要的兴趣点集中在文档中的元素上而非它们之间的文本(和它们之间的空白)上,我们可以使用另外一个更有用的API。他将文档看作是Element对象树,忽略部分文档:Text和Comment节点。
/*
* 返回元素e的第n层祖先元素,如果不存在此类祖先或者祖先不是Element
* (例如Document或者DocumentFragement),则返回null
* 如果n为0,则返回e本身,如果n为1(省略),则返回其父元素
* 如果n为2,则返回其祖父元素,以此类推
*/
function parent(e,n){
if (n===undefined) n=1;
while(n--&&e) e=e.parentNode;
if(!e ||e.nodeType!==1) return null;
return e;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异