

NoSQL之Redis集群
1.Redis 主从复制

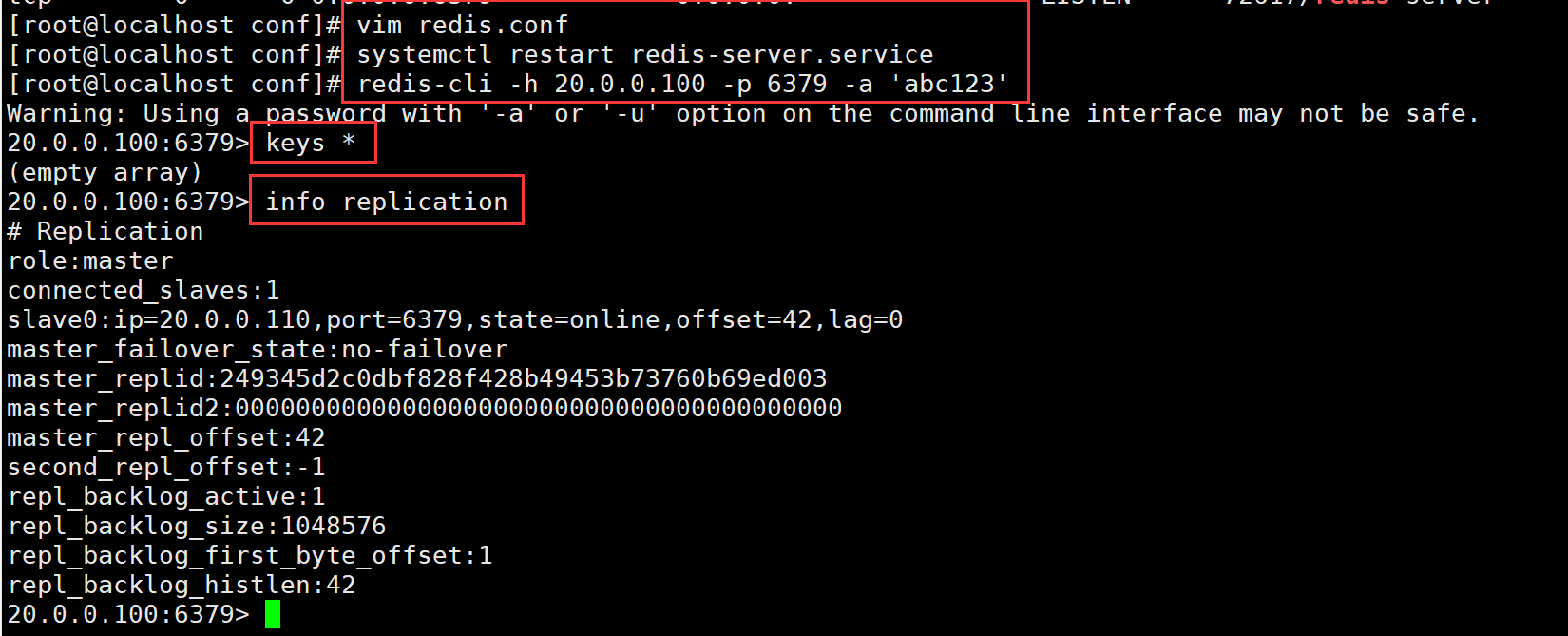
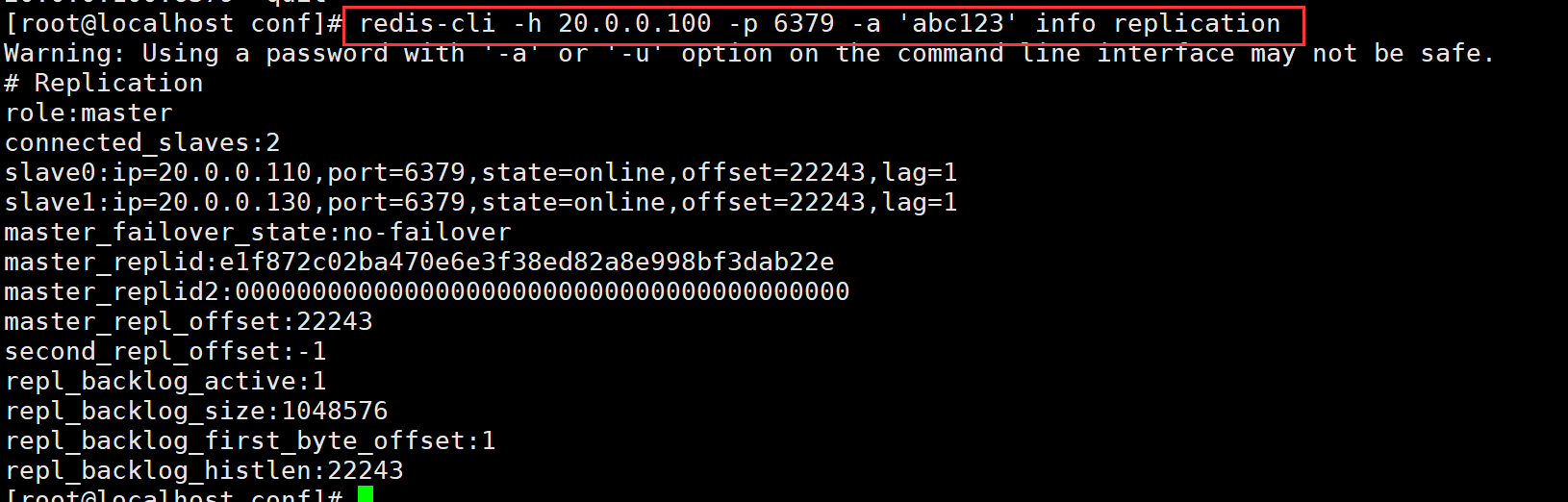
(1)Redis 主从复制工作原理
1.slave启动后,向master发送SYNC命令,master接收到SYNC命令后通过bgsave保存快照,并使用缓冲区记录保存快照这段时间内执行的写命令
2.master将保存的快照文件发送给slave,并继续记录执行的写命令
3.slave接收到快照文件后,加载快照文件,载入数据4.master快照发送完后开始向slave发送缓冲区的写命令,slave接收命令并执行,完成复制初始化
5.master每次执行一个写命令都会同步发送给slave保持master与slave之间数据的一致性
(2)搭建Redis 主从复制
环境准备
修改内核参数
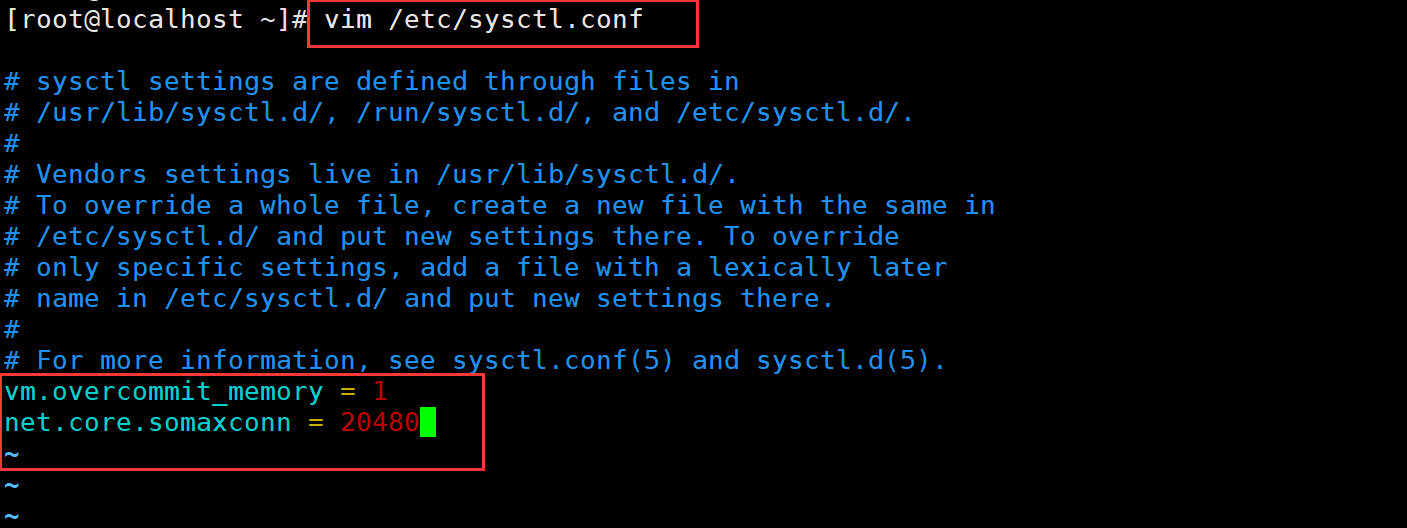
vim /etc/sysctl.conf
vm.overcommit_memory = 1
net.core.somaxconn = 20480
sysctl -p

安装redis
rpm -q gcc gcc-c++ makec
#yum install -y gcc gcc-c++ make
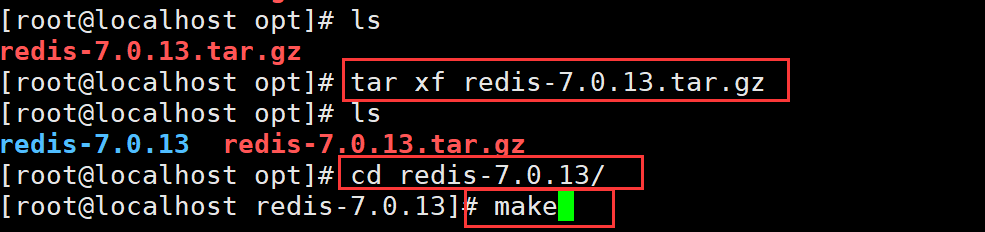
cd /opt/
rz -E 上传redis-7.0.13.tar.gz
tar xf redis-7.0.13.tar.gz
cd redis-7.0.13/
make
make PREFIX=/usr/local/redis install

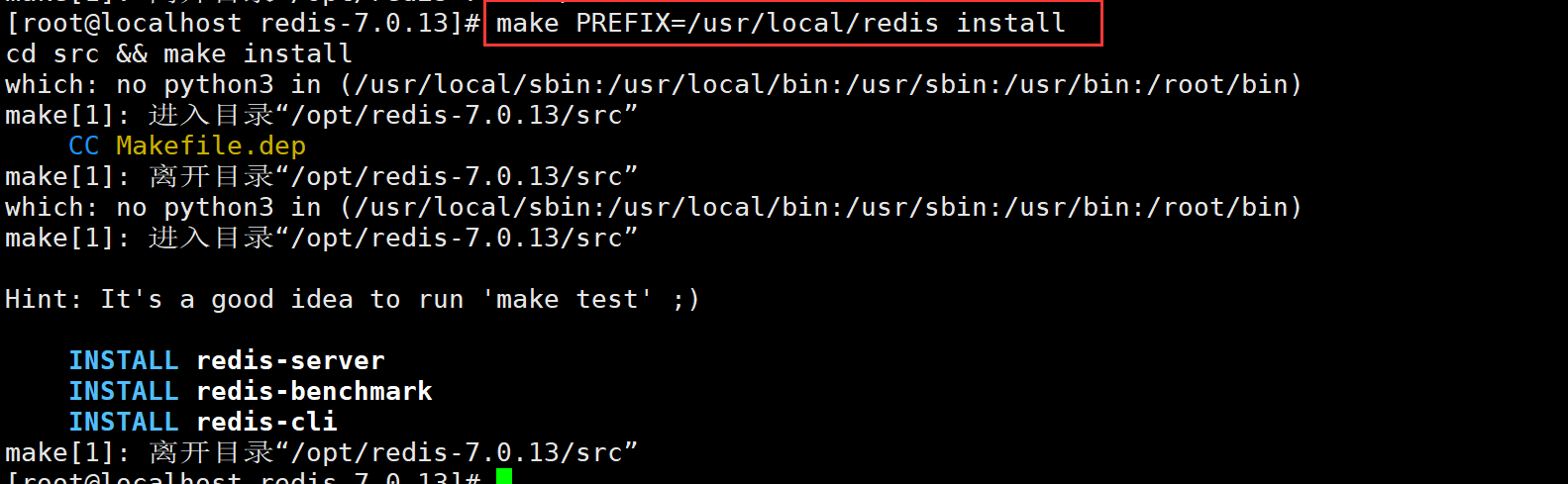
注:由于Redis源码包中直接提供了 Makefile 文件,所以在解压完软件包后,不用先执行 ./configure 进行配置,可直接执行 make 与 make install 命令进行安装。
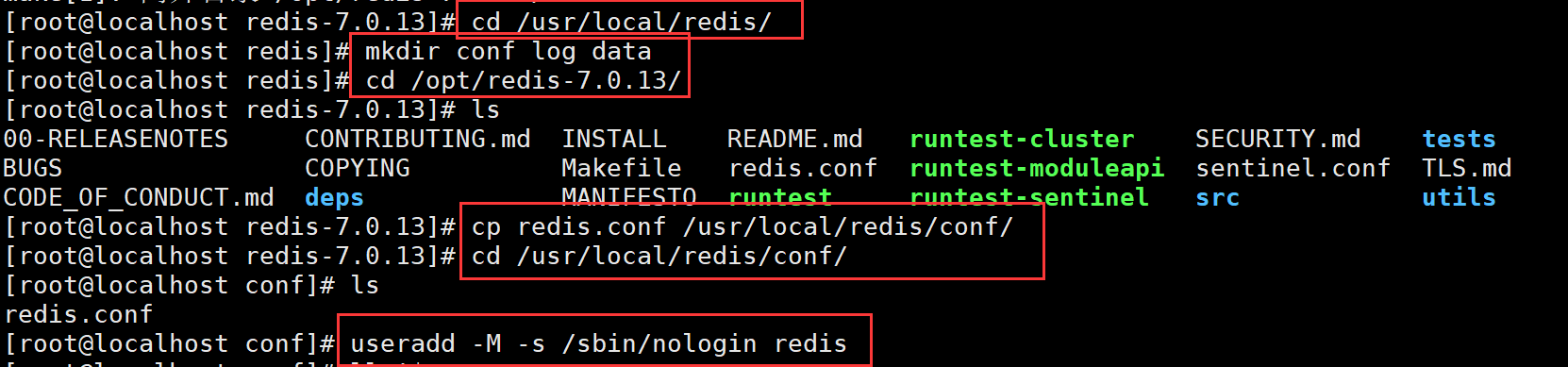
创建redis工作目录
mkdir /usr/local/redis/{conf,log,data}
cp /opt/redis-7.0.13/redis.conf /usr/local/redis/conf/
cd /usr/local/redis/conf/
useradd -M -s /sbin/nologin redis
chown -R redis.redis /usr/local/redis/

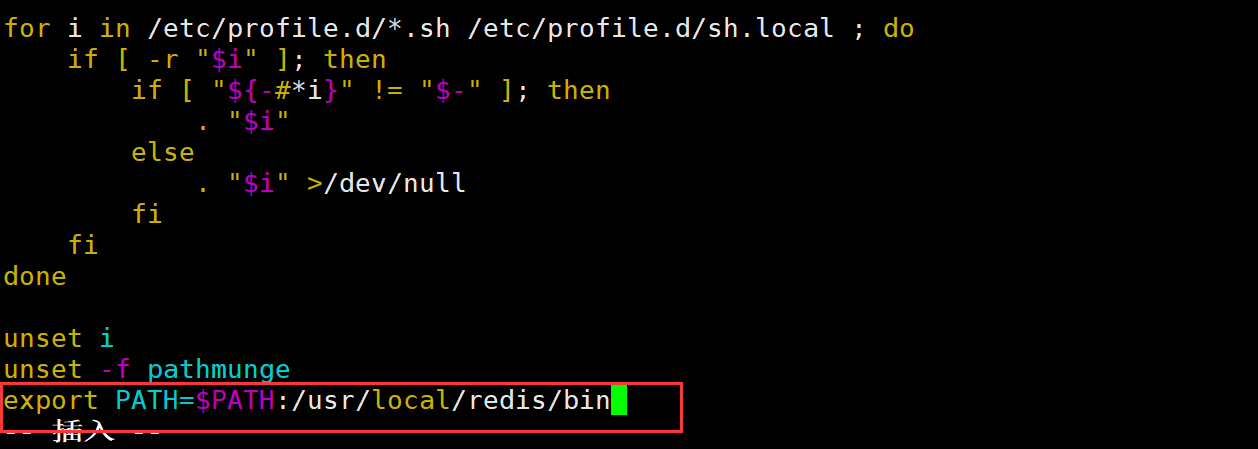
环境变量
vim /etc/profile
export PATH=$PATH:/usr/local/redis/bin
source /etc/profile

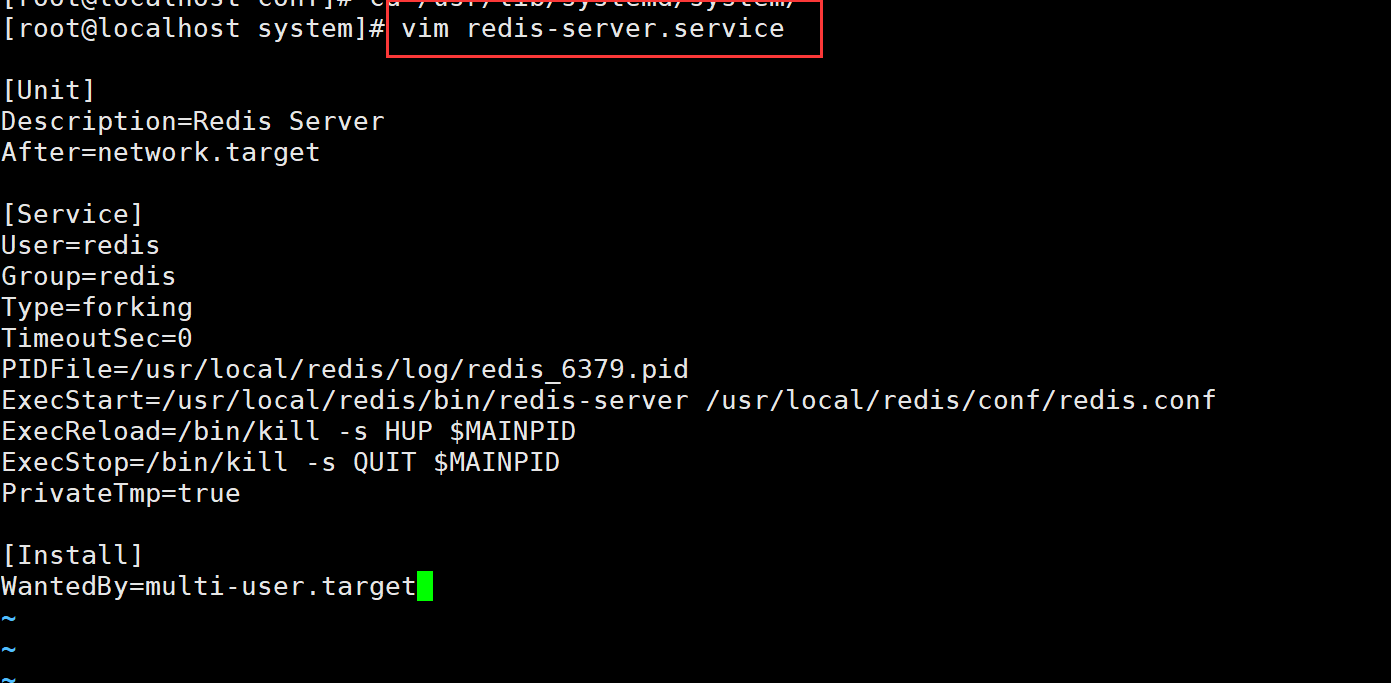
定义systemd服务管理脚本
vim /usr/lib/systemd/system/redis-server.service
[Unit]
Description=Redis Server
After=network.target
[Service]
User=redis
Group=redis
Type=forking
TimeoutSec=0
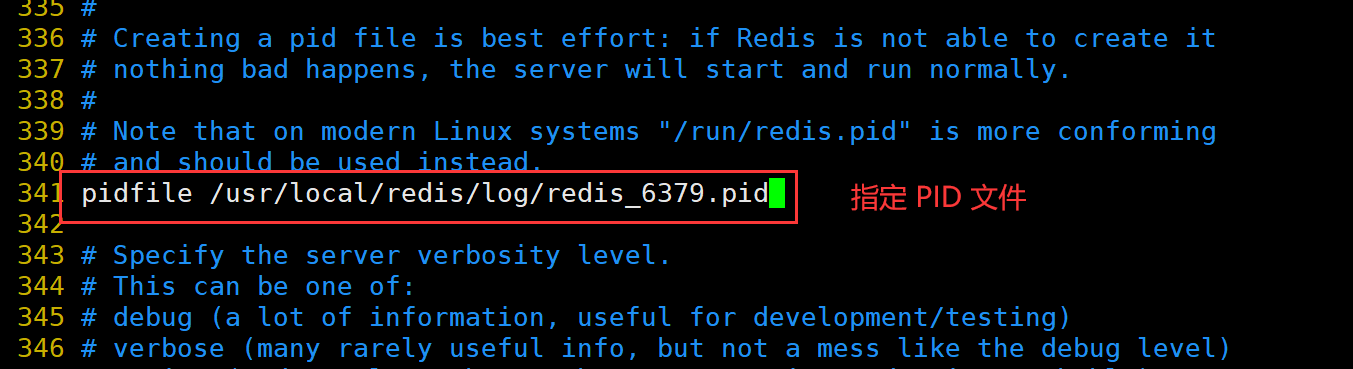
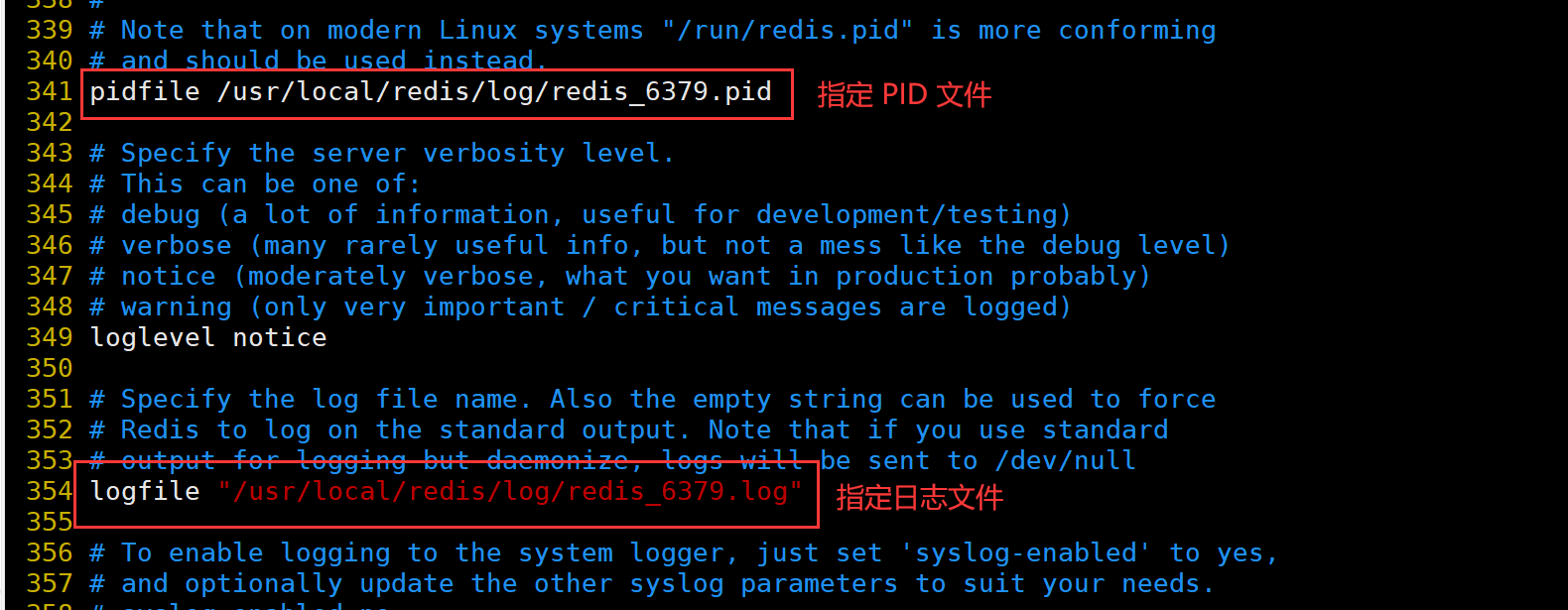
PIDFile=/usr/local/redis/log/redis_6379.pid
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true
[Install]
WantedBy=multi-user.target

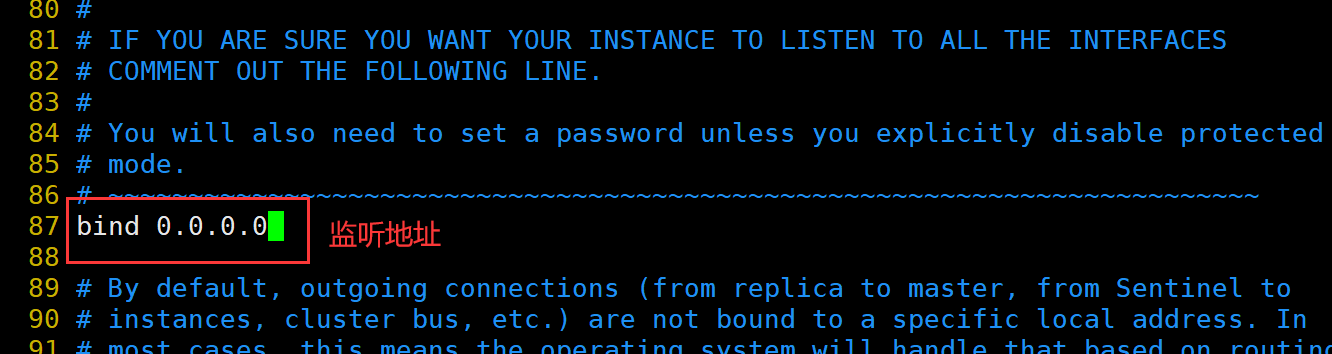
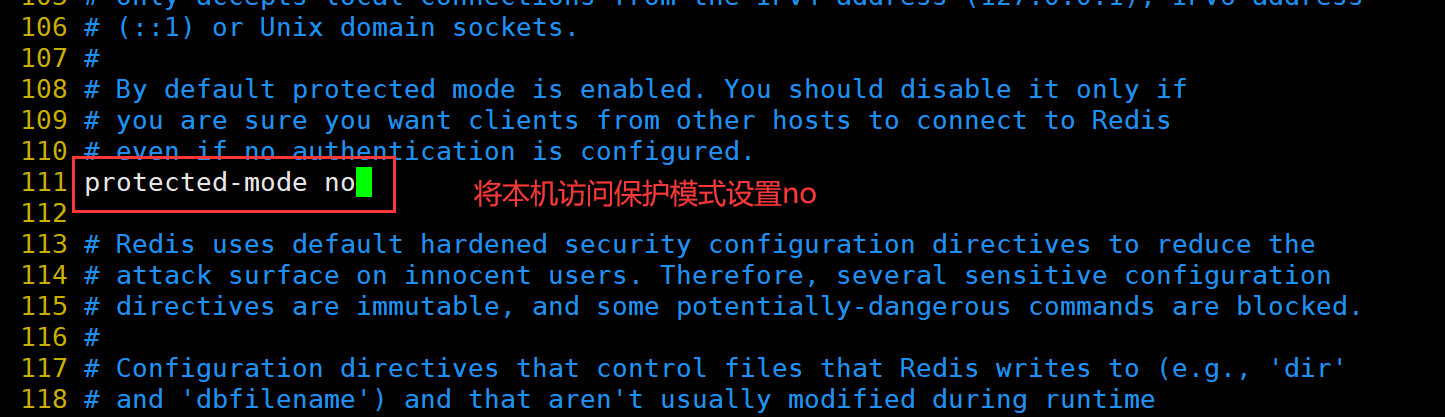
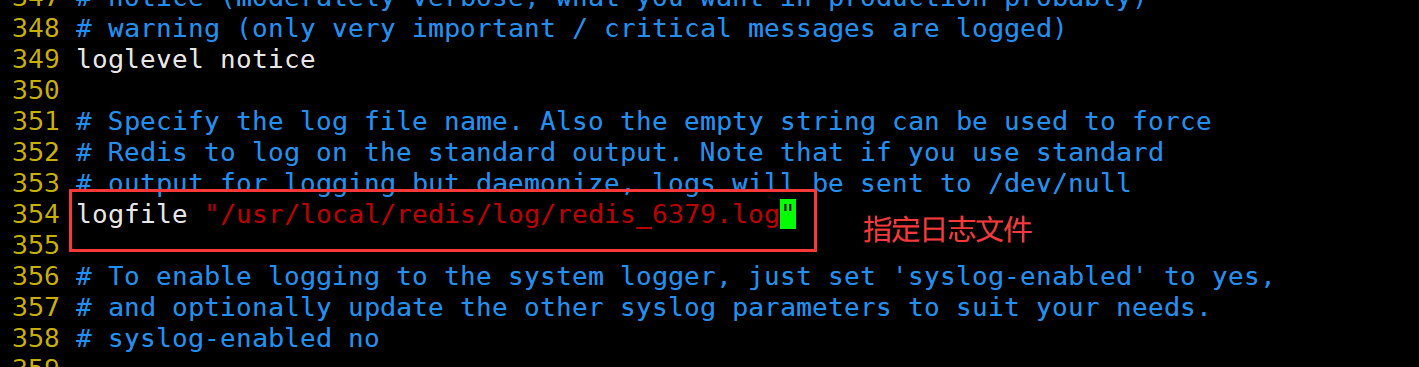
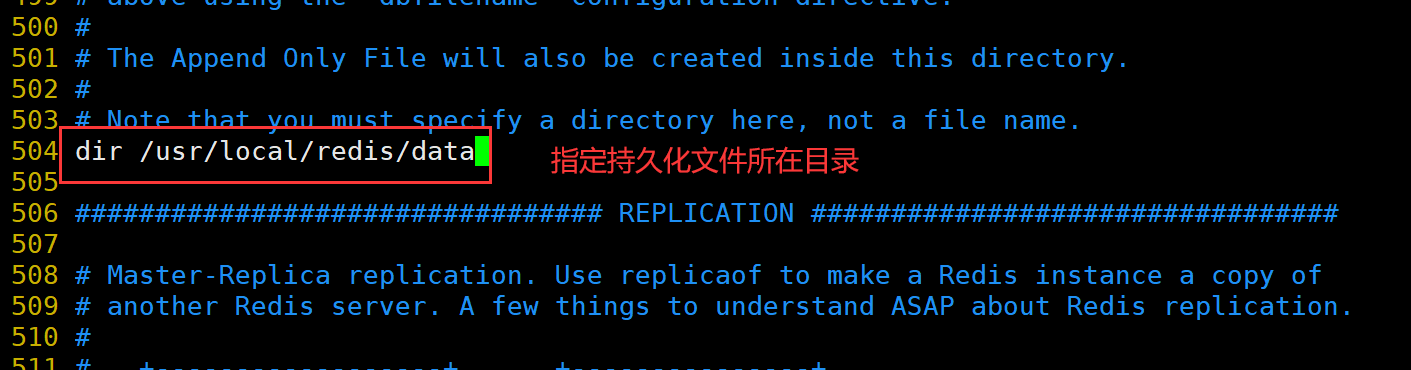
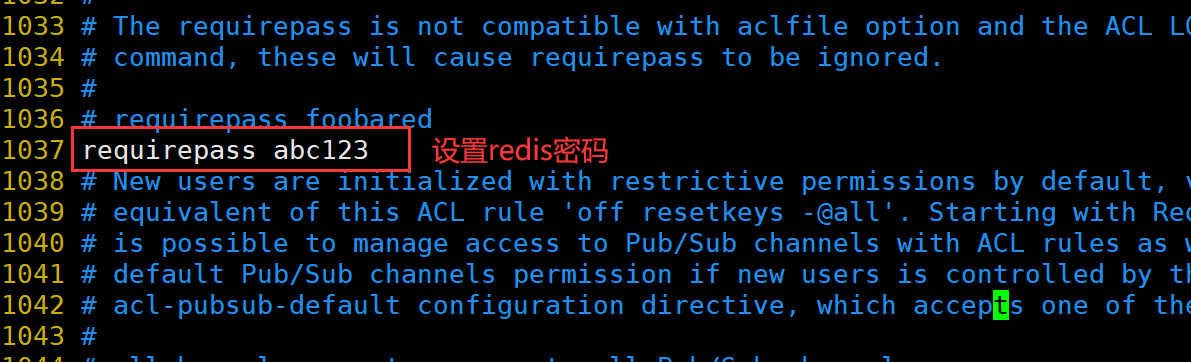
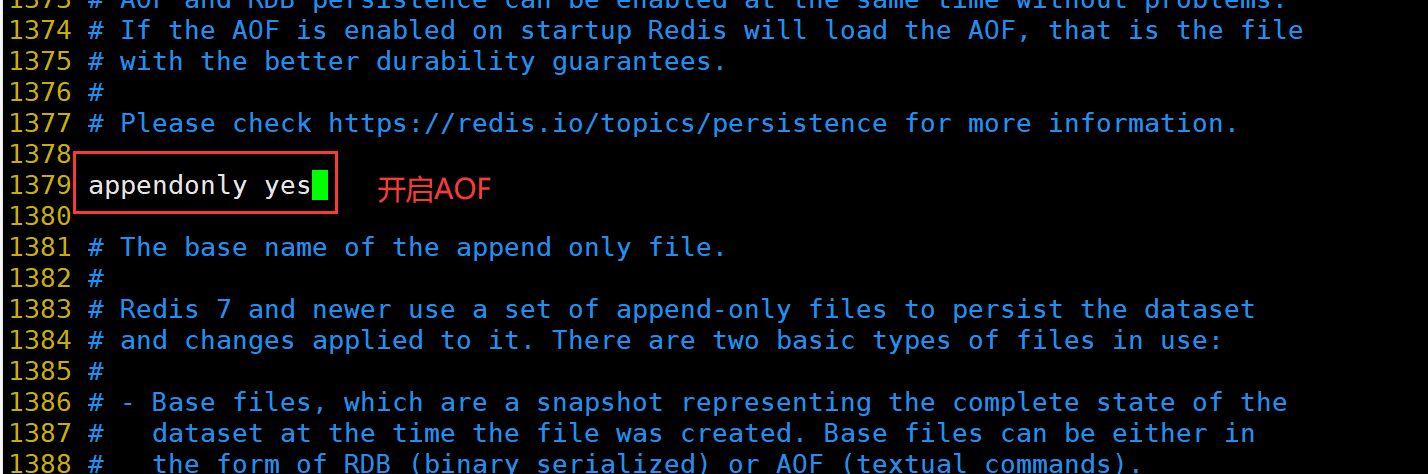
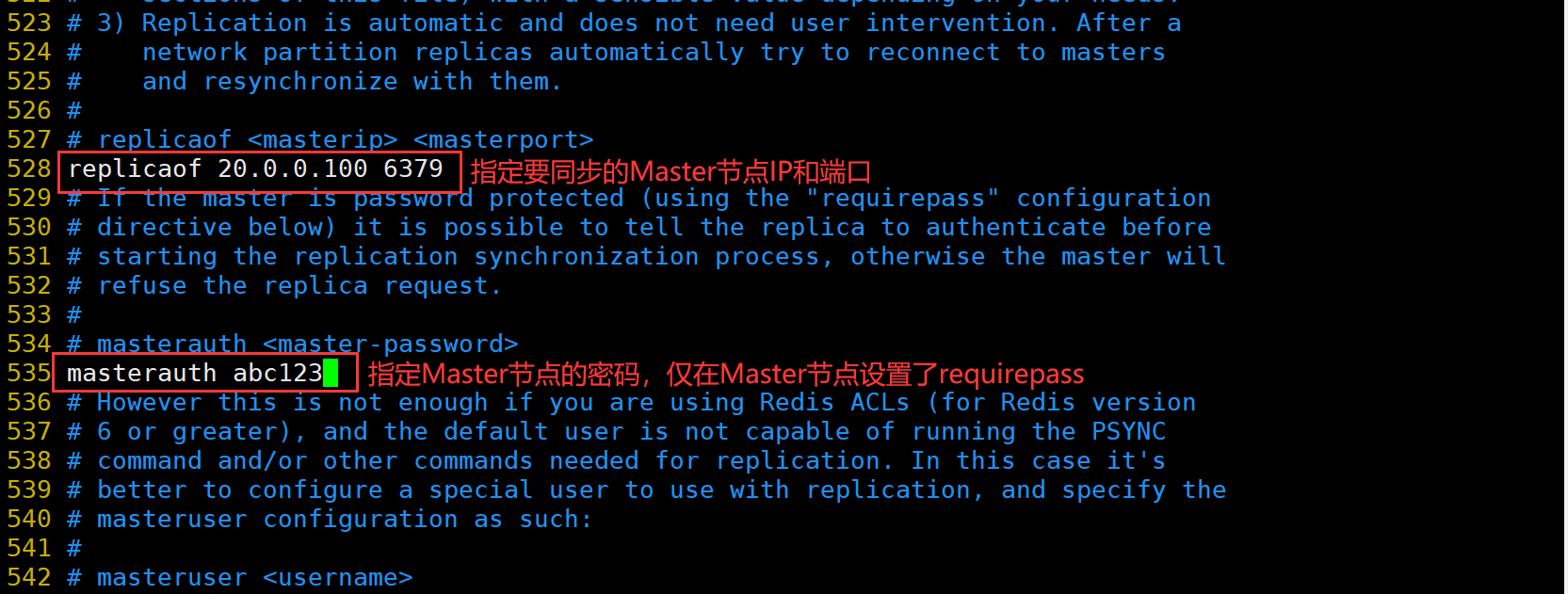
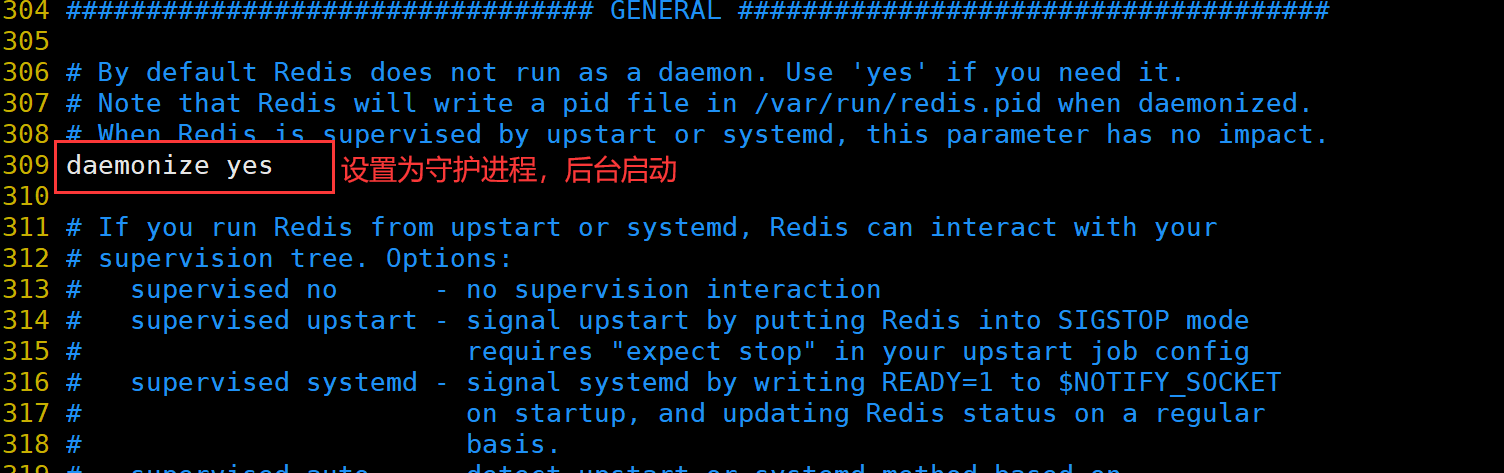
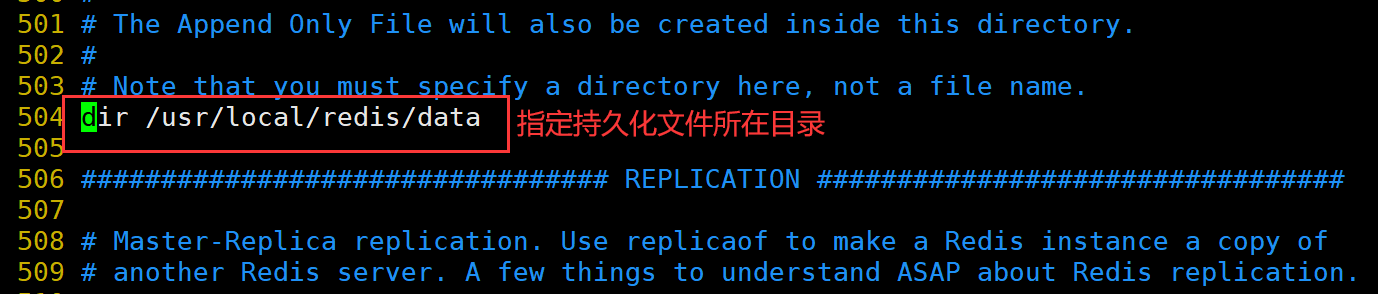
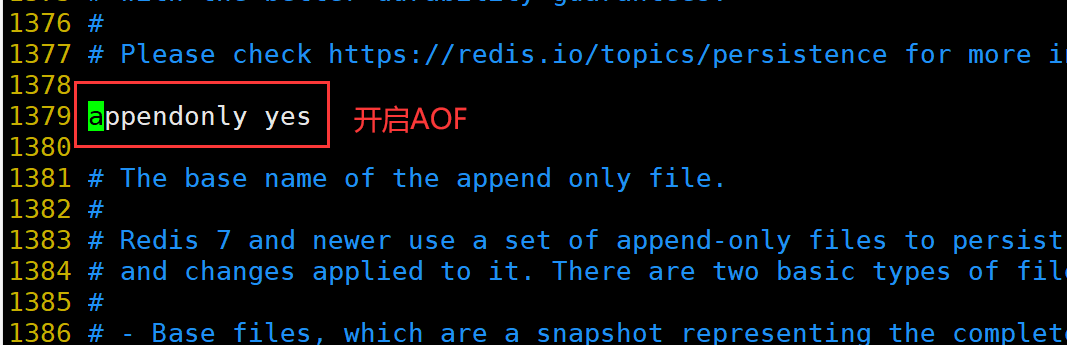
修改 Redis 配置文件(Master节点操作)
Master节点:20.0.0.100
Slave1节点:20.0.0.110
Slave2节点:20.0.0.120


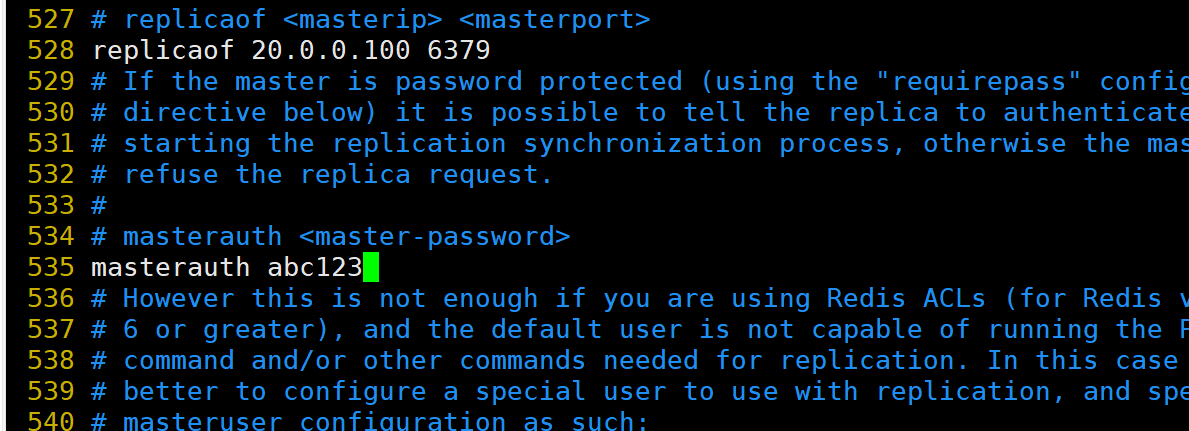
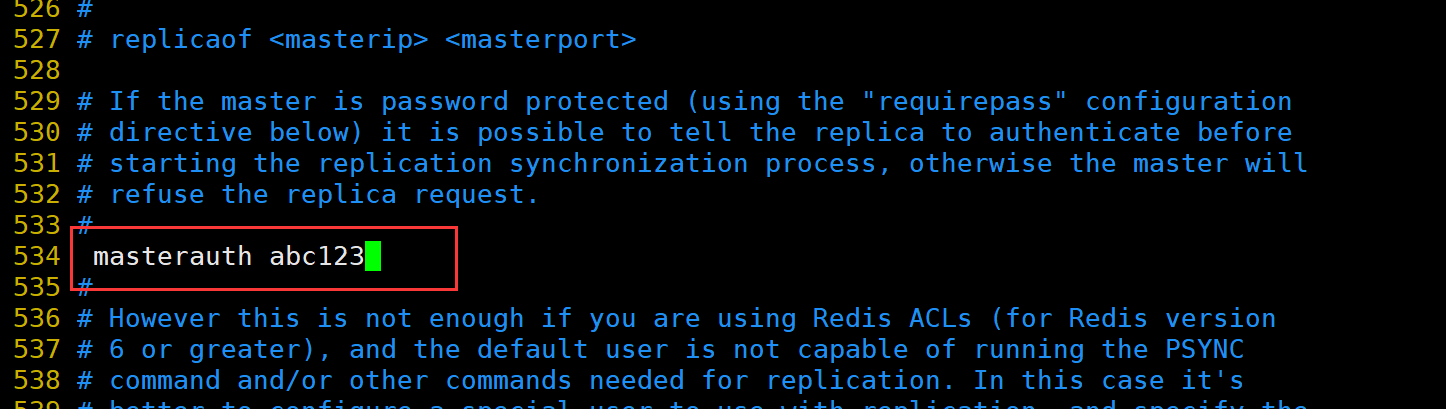
修改 Redis 配置文件(Slave节点操作)Slave1节点:20.0.0.110
Slave1节点:20.0.0.110
Slave2节点:20.0.0.120
2.Redis 哨兵模式
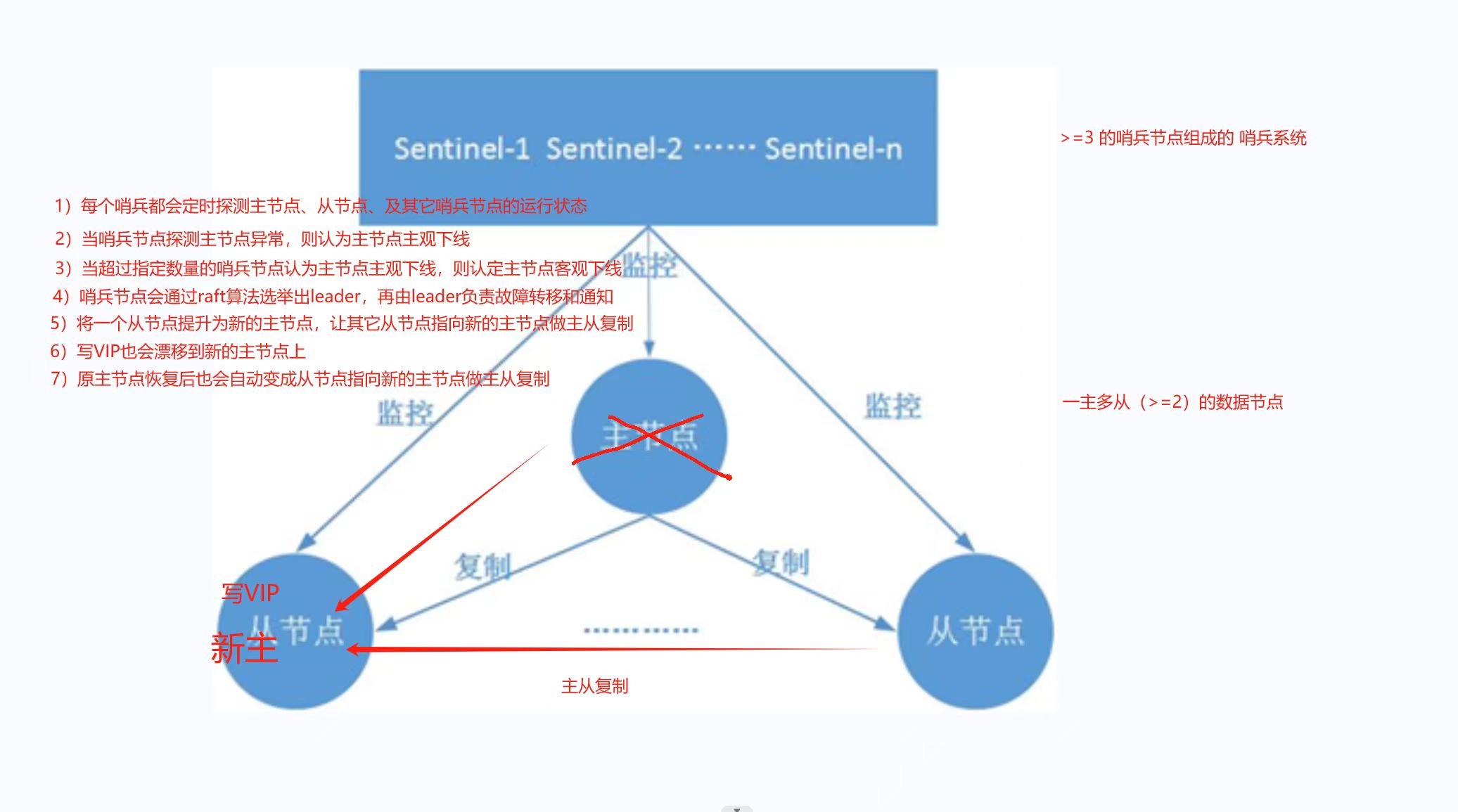
(1)Redis 哨兵工作原理
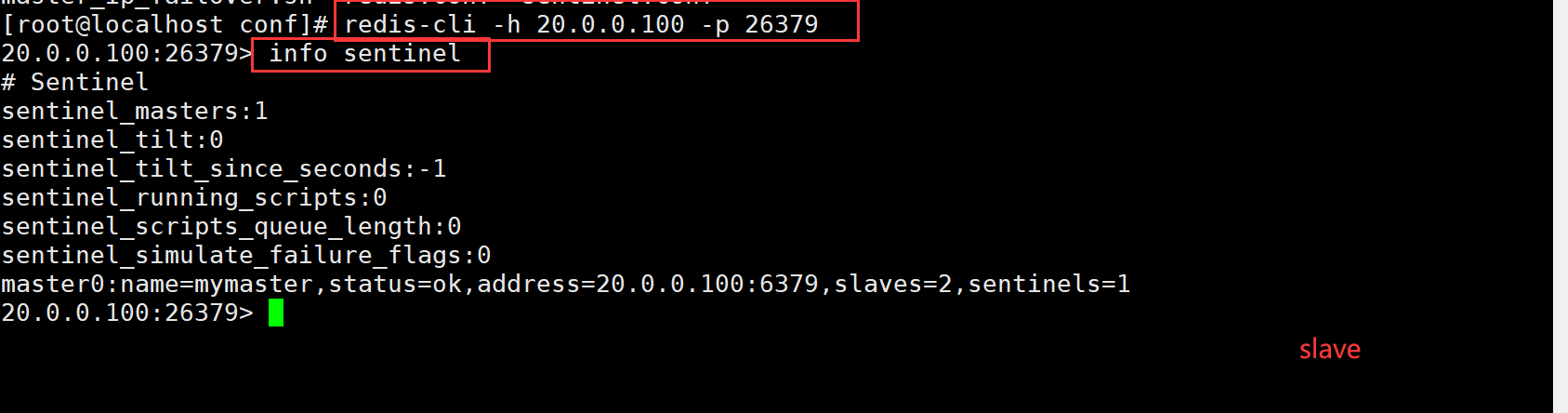
1)每个哨兵都会定时探测主节点、从节点、及其它哨兵节点的运行状态
2)当哨兵节点探测主节点异常,则认为主节点主观下线
3)当超过指定数量的哨兵节点认为主节点主观下线,则认定主节点客观下线
4)哨兵节点会通过raft算法选举出leader,再由leader负责故障转移和通知
5)将一个从节点提升为新的主节点,让其它从节点指向新的主节点做主从复制
6)写VIP也会漂移到新的主节点上
7)原主节点恢复后也会自动变成从节点指向新的主节点做主从复制
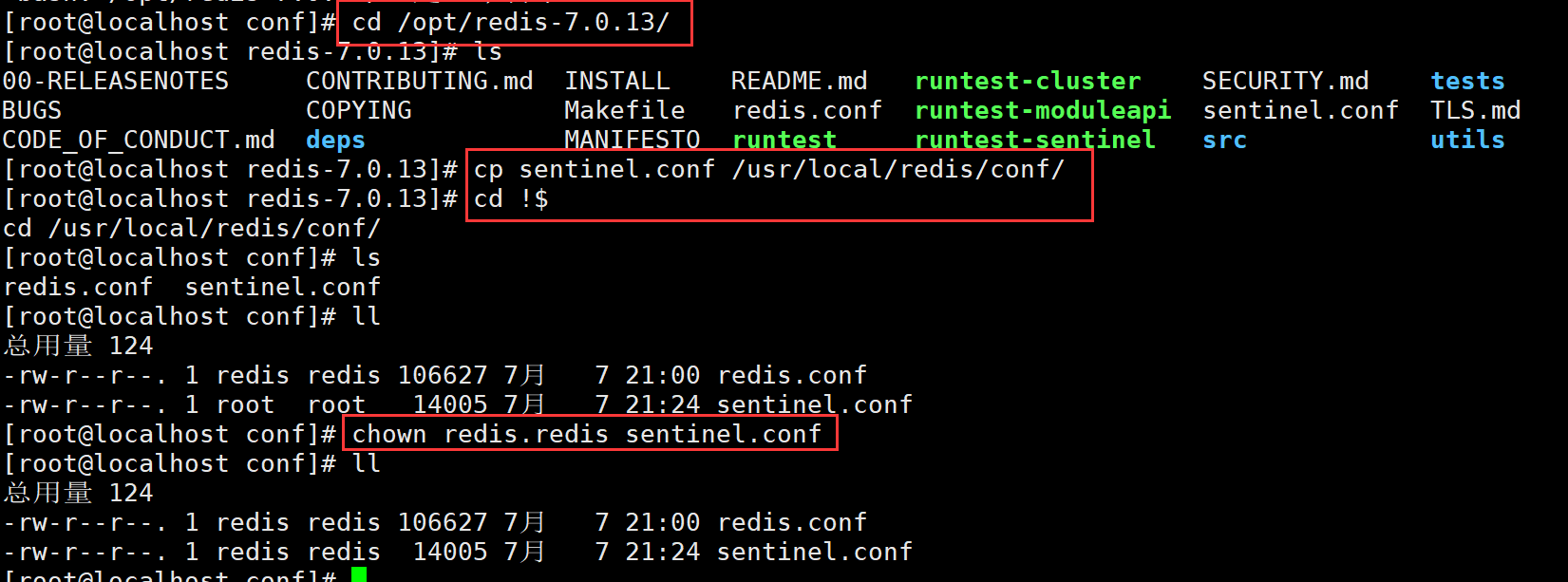
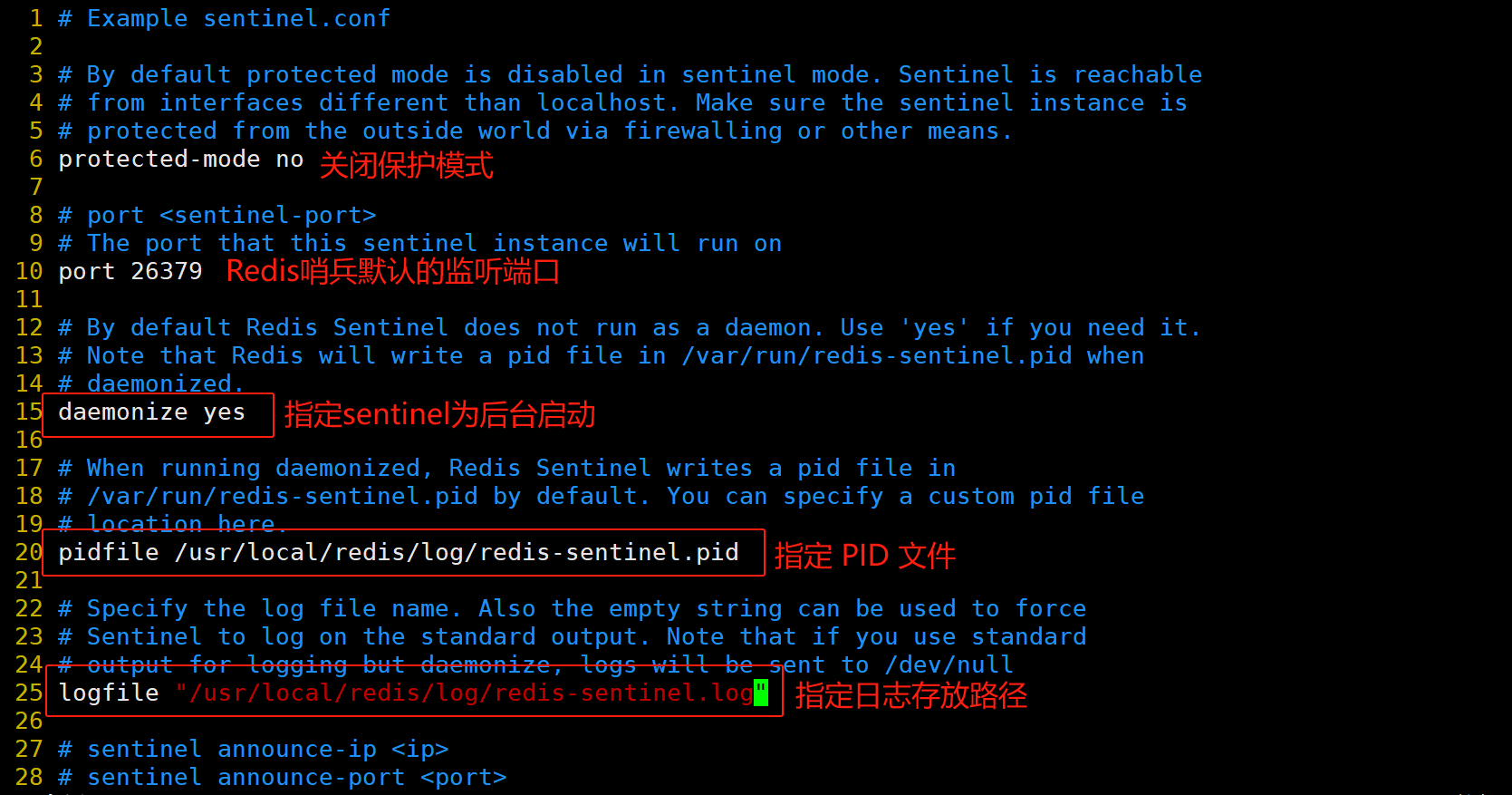
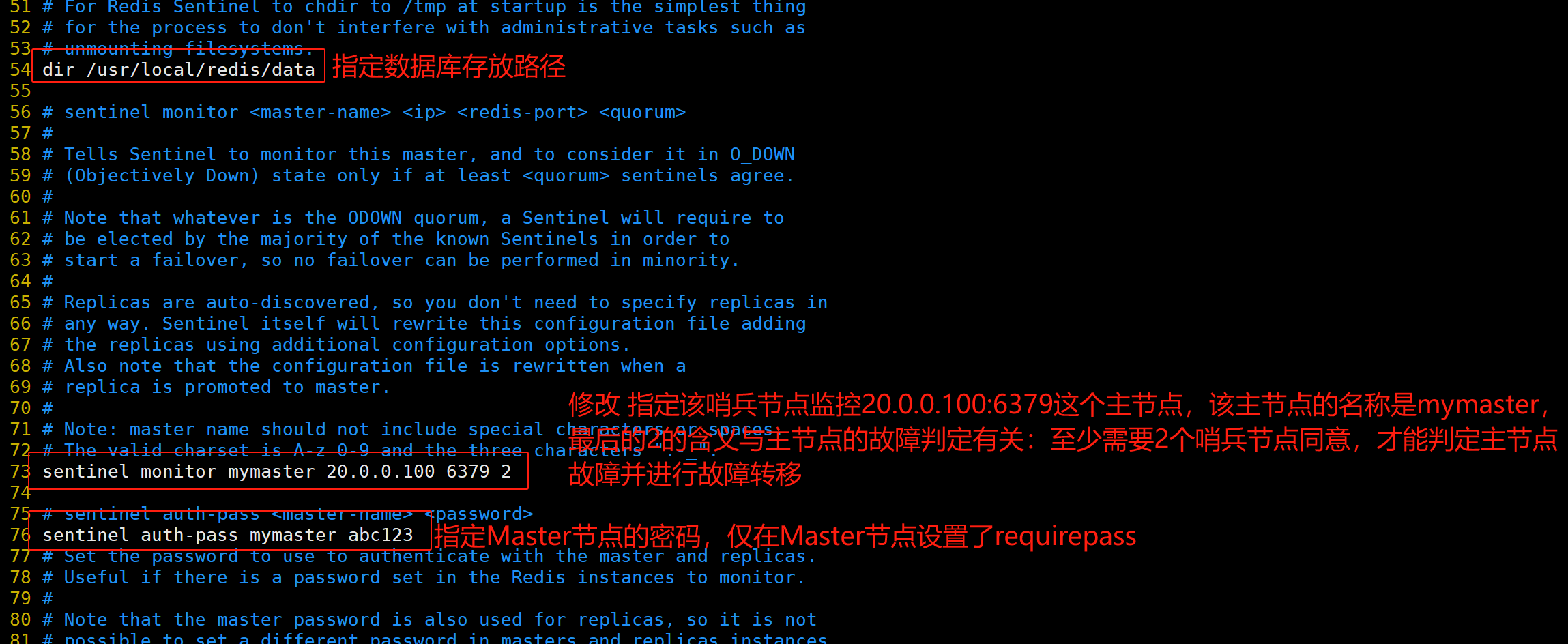
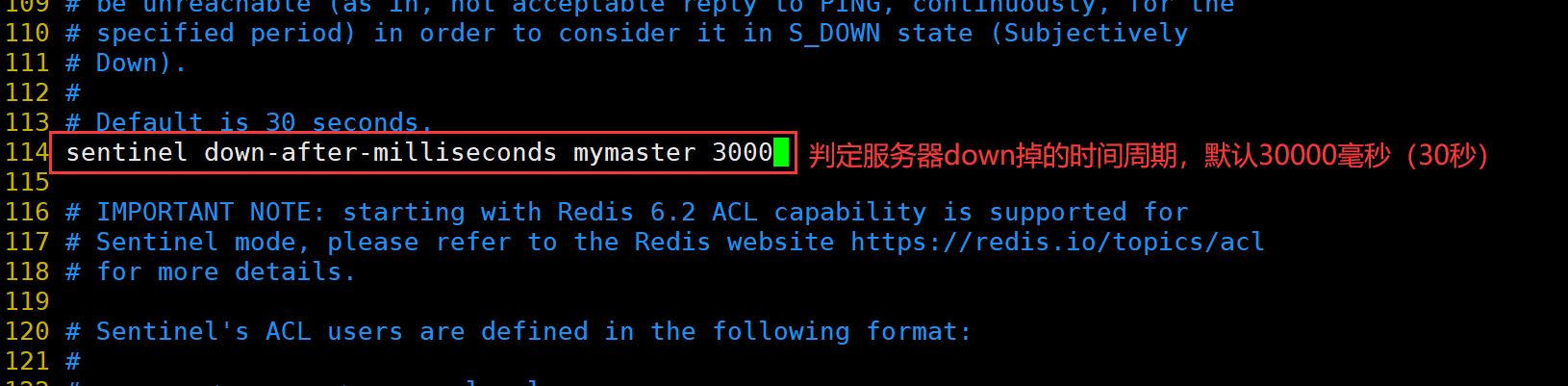
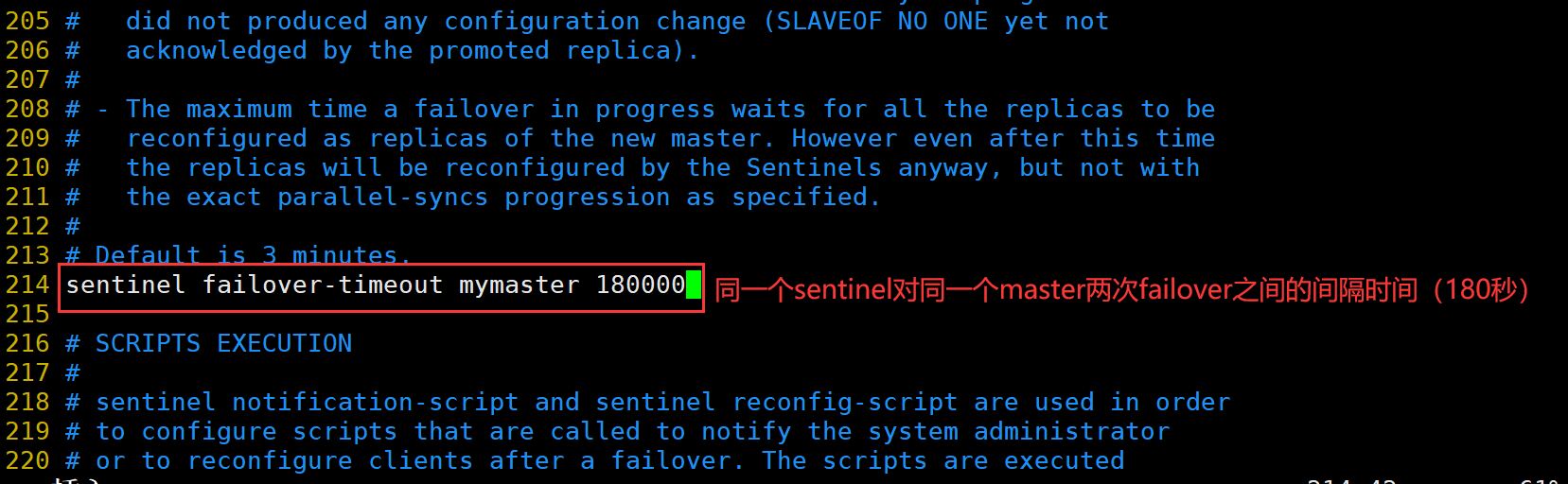
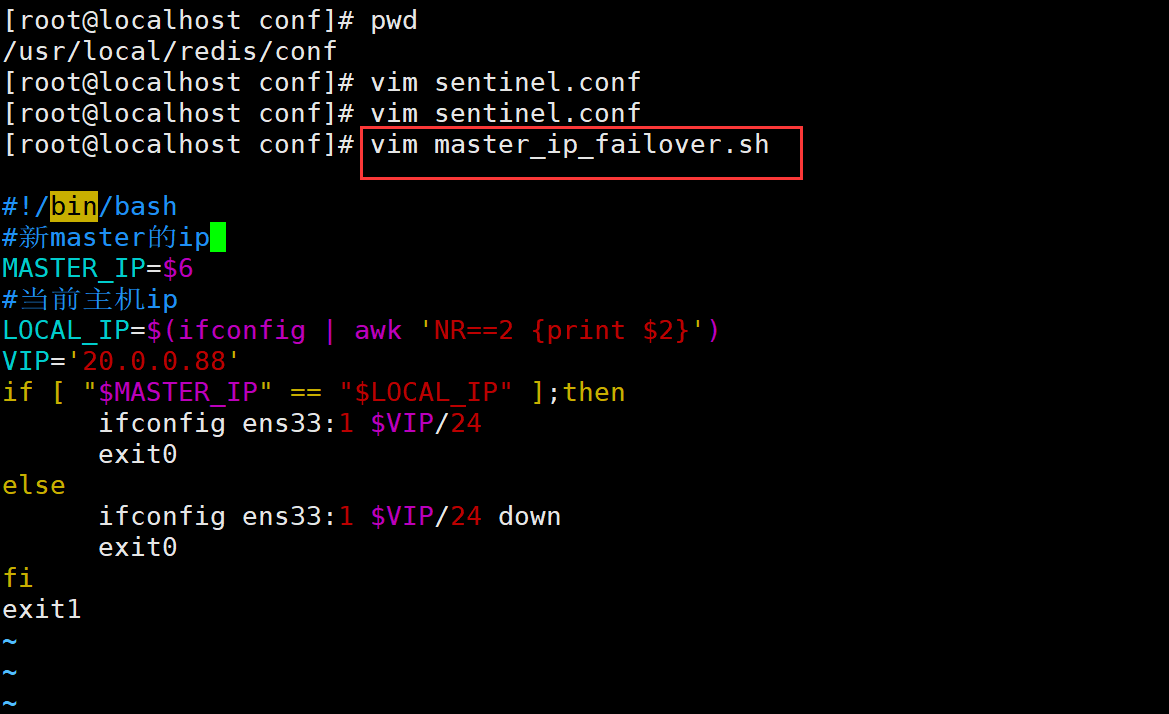
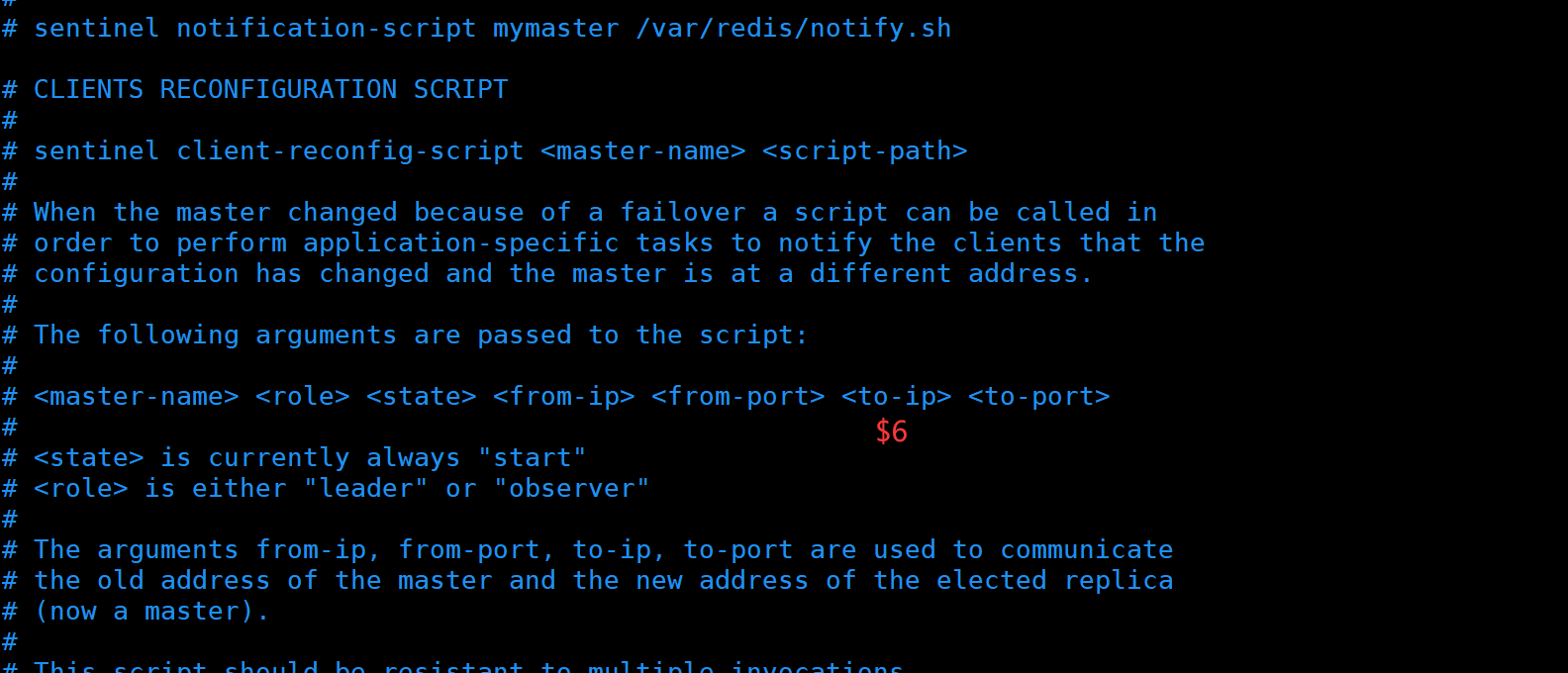
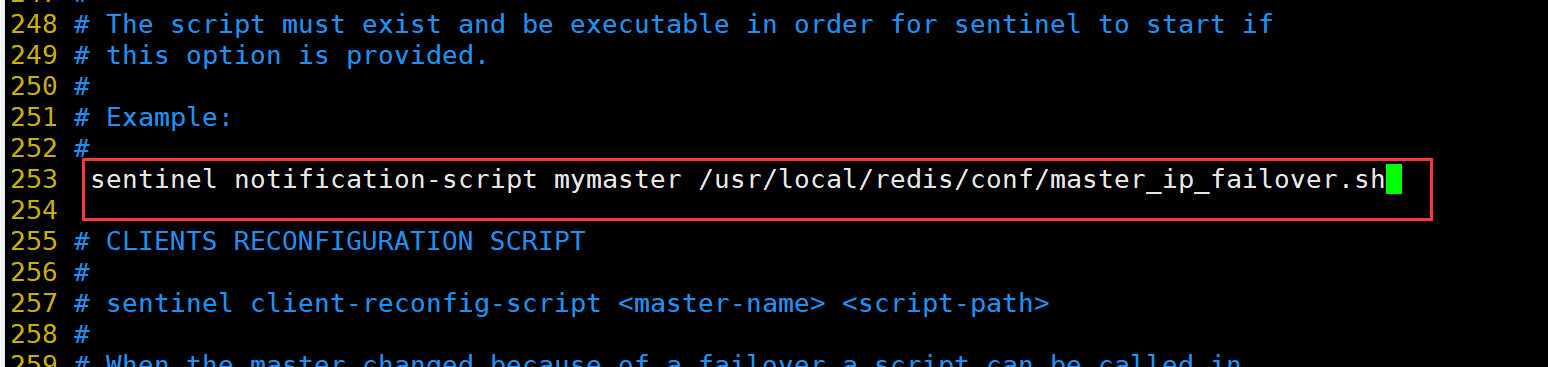
(2)搭建Redis 哨兵模式
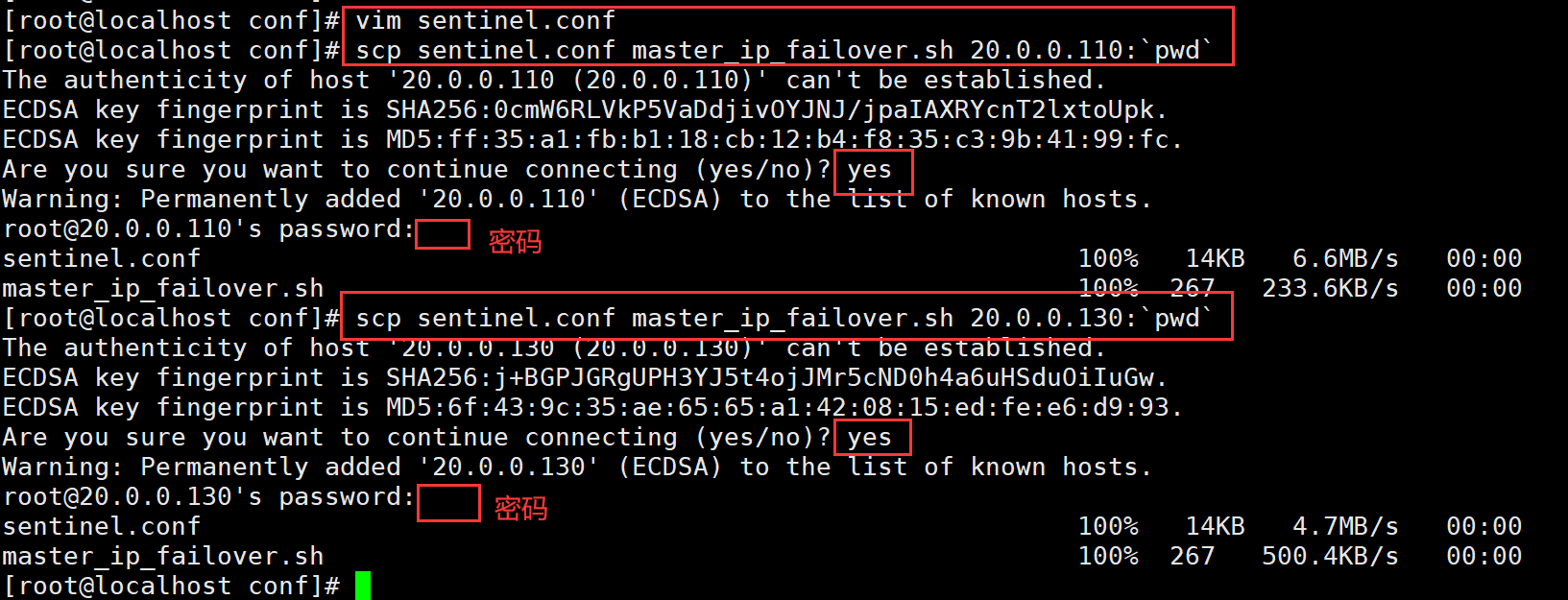
修改 Redis 哨兵模式的配置文件(所有节点操作)
cp /opt/redis-7.0.13/sentinel.conf /usr/local/redis/conf/
chown redis:redis /usr/local/redis/conf/sentinel.conf



3.Redis 集群模式
采用的算法是哈希槽分区算法
通过数据分片的方式来进行数据共享问题,同时提供数据复制和故障转移功能。
之前的两种模式数据都是在一个节点上的,单个节点存储是存在上限的。集群模式就是把数据进行分片存储,当一个分片数据达到上限的时候,就分成多个分片。
要是针对海量数据+高并发+高可用的海量数据场景,Redis集群模式的性能和高可用性均优于哨兵模式。
(1)集群模式的工作原理
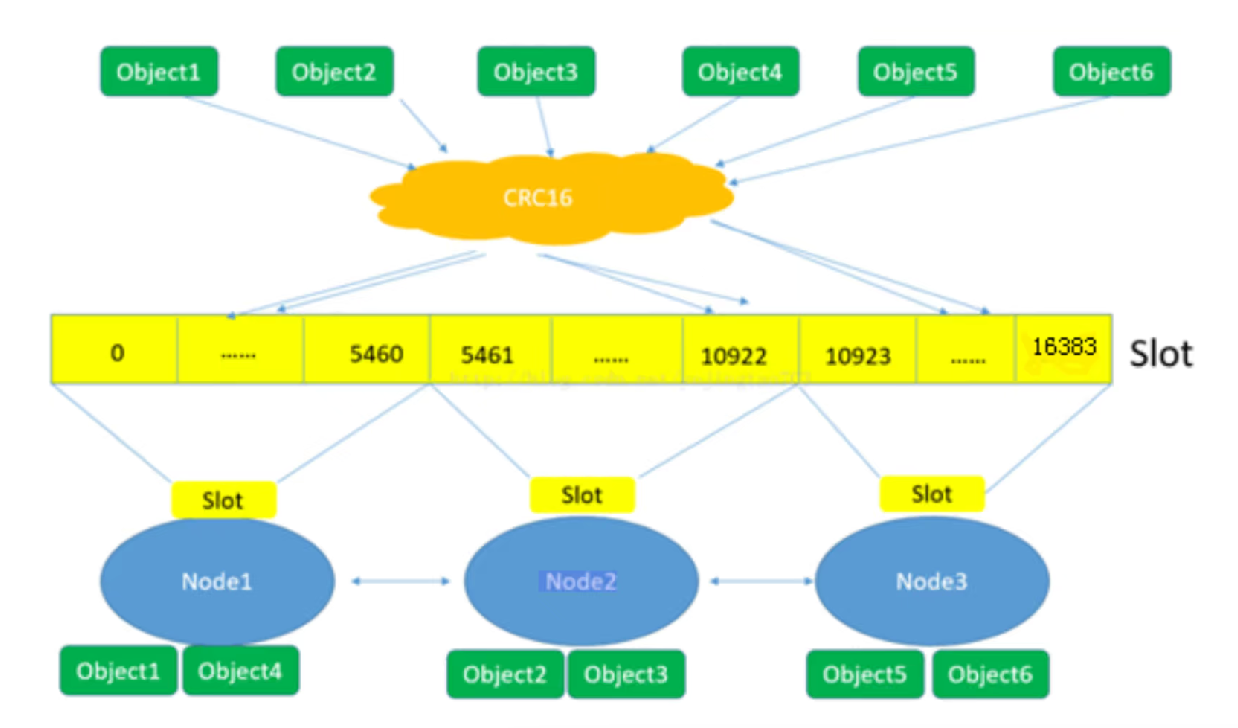
在Redis的每个节点上,都有一个插槽(slot),取值范围为0-16383
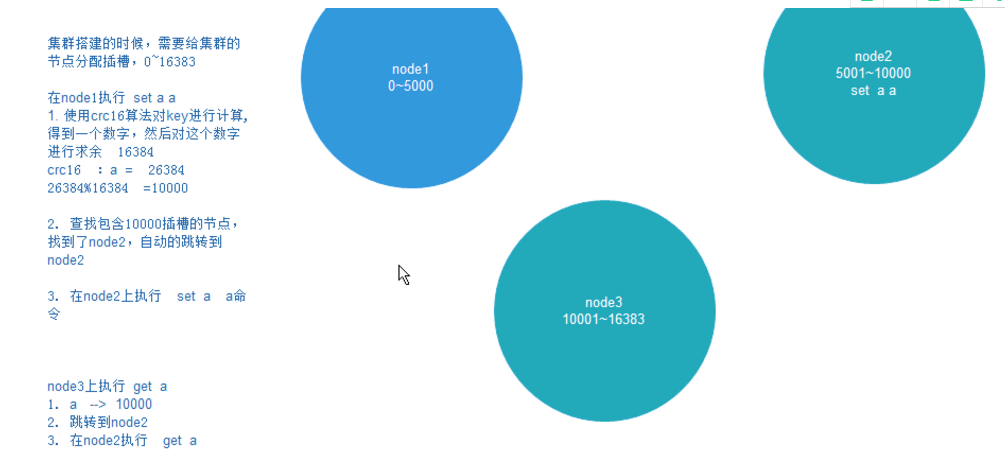
当我们存取key的时候,Redis会根据CRC16的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
为了保证高可用,Cluster模式也引入主从复制模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点
当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点都宕机了,那么该集群就无法再提供服务了
(2)集群模式的特点
自动分片:数据自动分布在不同的节点上,客户端不需要关心数据的具体位置。
高可用性:即使某个节点失败,只要大多数节点可用,集群仍然可以提供服务。
读写分离:可以通过在每个主节点上设置从节点来实现读写分离,进一步提高性能。
容错性:集群能够在节点故障时自动进行故障转移。
集群模式的局限性
多键操作限制:由于数据分布在不同的节点上,多键操作(比如 MSET、MGET、SUNION 等)要求所有相关的键必须在同一节点上。
数据迁移复杂性:当集群进行扩容或缩容时,数据迁移过程可能会比较复杂。
(3)搭建Redis 群集模式
redis的集群一般需要6个节点,3主3从。方便起见,这里所有节点在同一台服务器上模拟:
以端口号进行区分:3个主节点端口号:6001/6002/6003,对应的从节点端口号:6004/6005/6006。
##环境准备
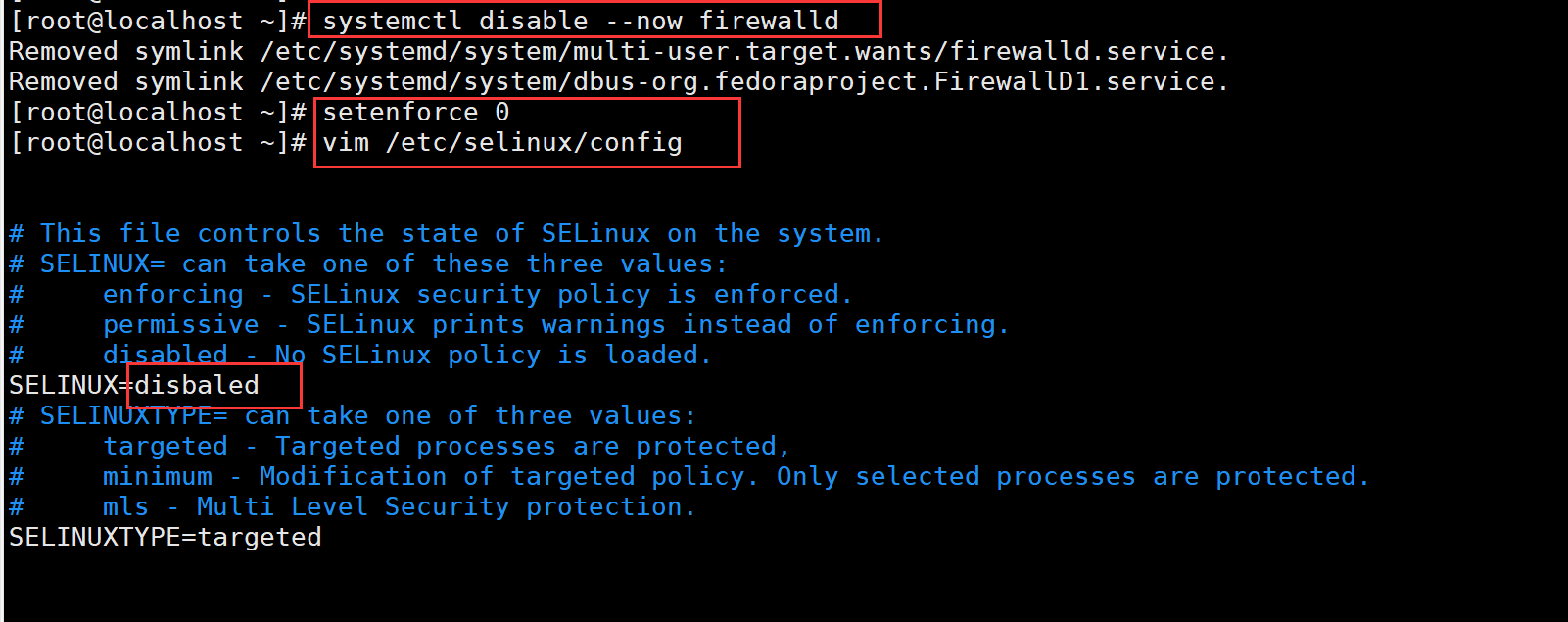
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
vim /etc/selinux/config
disabled
##修改内核参数
vim /etc/sysctl.conf
vm.overcommit_memory = 1
net.core.somaxconn = 20480
sysctl -p
##安装redis
rpm -q gcc gcc-c++ makec
#yum install -y gcc gcc-c++ make
cd /opt/
rz -E 上传redis-7.0.13.tar.gz
tar zxvf /opt/redis-7.0.13.tar.gz -C /opt/
cd /opt/redis-7.0.13/
make -j 2
make PREFIX=/usr/local/redis install
##创建redis工作目录
mkdir /usr/local/redis/{conf,log,data}
cp /opt/redis-7.0.13/redis.conf /usr/local/redis/conf/
cd /usr/local/redis/conf/
useradd -M -s /sbin/nologin redis
chown -R redis:redis /usr/local/redis/
##环境变量
vim /etc/profile
export PATH=$PATH:/usr/local/redis/bin
source /etc/profile
##定义systemd服务管理脚本
vim /usr/lib/systemd/system/redis-server.service
[Unit]
Description=Redis Server
After=network.target
[Service]
User=redis
Group=redis
Type=forking
TimeoutSec=0
PIDFile=/usr/local/redis/log/redis_6379.pid
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true
[Install]
WantedBy=multi-user.target
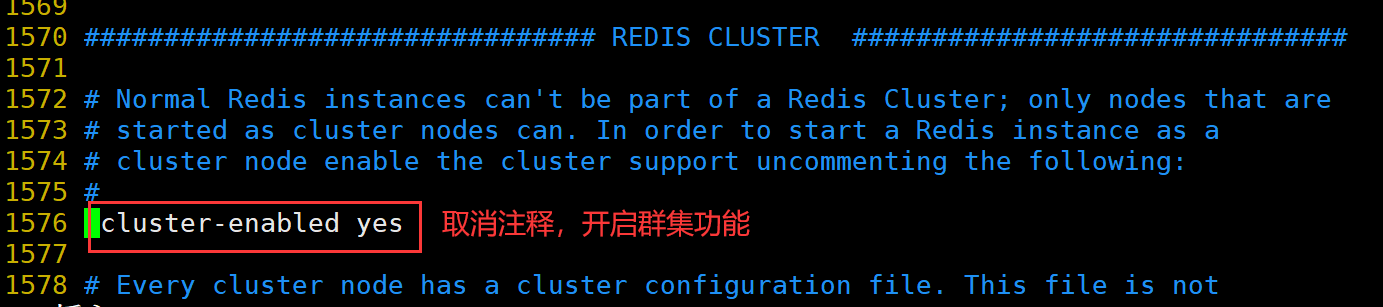
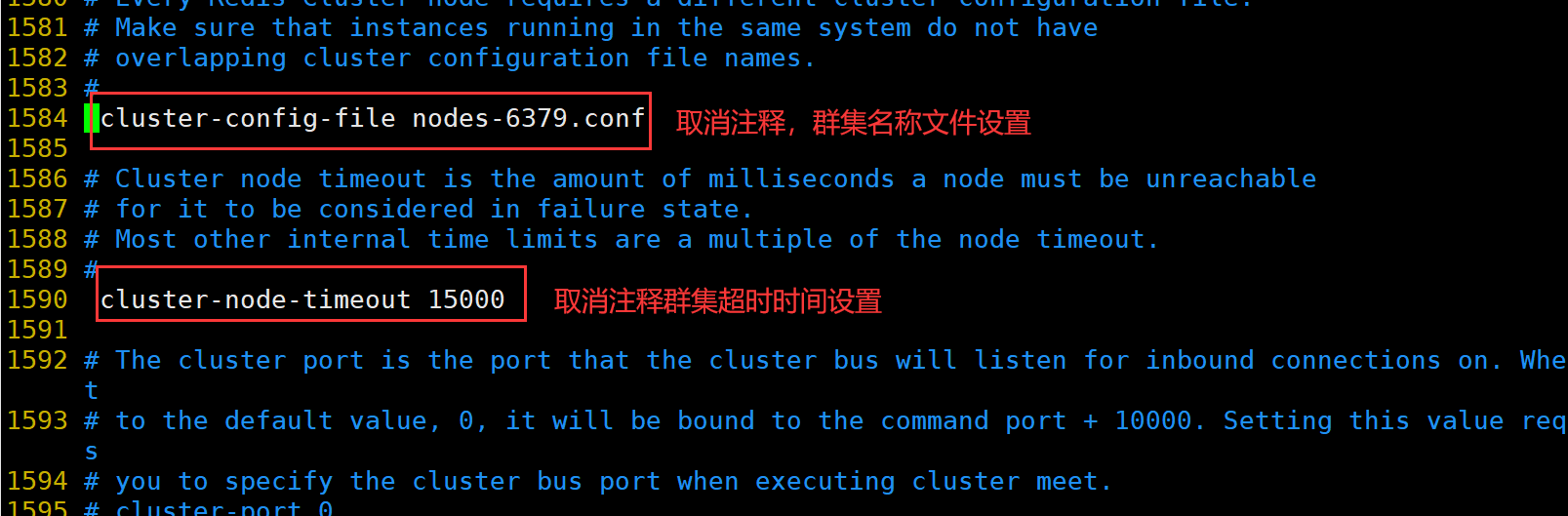
##修改 Redis 配置文件(Master节点操作)
vim /usr/local/redis/conf/redis.conf
scp redis.conf 20.0.0.110:`pwd` ##复制给其他五台服务器
....
systemctl restart redis-server.service
ps -elf | grep redis


启动集群
redis-cli --cluster create 20.0.0.100:6379 20.0.0.110:6379 20.0.0.130:6379 20.0.0.140:6379 20.0.0.150:6379 20.0.0.160:6379 --cluster-replicas 1
注:六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。下面交互的时候 需要输入 yes 才可以创建。
redis-cli -h 20.0.0.100 -p 6379 -c #加-c参数,节点之间就可以互相跳转
cluster slots #查看节点的哈希槽编号范围
set name zhangsan
cluster keyslot name #查看name键的槽编号
keys * #对应的slave节点也有这条数据,但是别的节点没有
(4)集群模式与哨兵模式的主要区别
数据分片
集群模式通过数据分片提高了系统的扩展性和性能,而哨兵模式没有数据分片功能,适用于数据量较小的场景。
高可用性
哨兵模式主要提供高可用性,能够在主节点故障时迅速进行故障转移。集群模式也提供高可用性,但是它通过分片和多个副本来实现,比哨兵模式更复杂。
写能力
集群模式由于数据分片,可以在多个节点上进行写操作,提高了写能力。哨兵模式的写能力受限于单个主节点。
