

文件处理命令与正则表达式
1.sort命令--对行内容进行升序排序
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序。
比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
XXX | sort 选项
sort 选项 文件
sort [选项] 参数
cat file | sort 选项
| 常用选项 | |
|---|---|
| -n | 按照数字进行排序 |
| -r | 反向排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
| -t | 指定字段分隔符,默认使用[Tab]键分隔 |
| -k | 指定排序字段 |
| -o <输出文件> | 将排序后的结果转存至指定文件 |
| -f | 忽略大小写,会将小写字都转换为大写字母来进行比较 |
| -b | 忽略每行前面的空格 |






2.uniq命令--对连续的重复行进行去重
用于报告或者忽略文件中连续的重复行,常与 sort 命令结合使用
XXX | uniq 选项
uniq 选项 文件
uniq [选项] 参数
cat file | uniq 选项
| 常用选项 | |
|---|---|
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |

3.tr命令--对输入的内容进行替换
常用来对来自标准输入的字符进行替换、压缩和删除
XXX | tr 选项 '参数1' ['参数2']
tr [选项] [参数]
| 常用选项 | |
|---|---|
| -c | 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符;用字符集2 替换 字符集1 |
| -t | 字符集2 替换 字符集1,不加选项同结果。 |


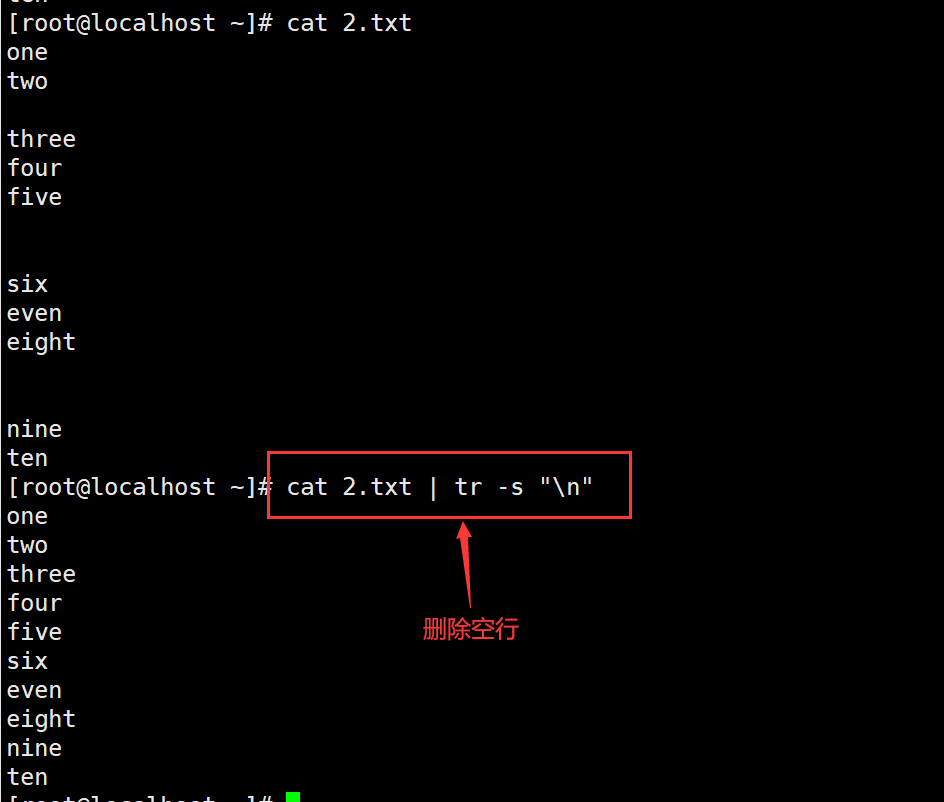
(1)删除空行
cat 文件 | grep -v "^$"
cat 文件 | tr -s "\n"

(2) Windows的另起一行格式(\r\n)转换成Linux的另起一行格式(\n)
cat 文件 | tr -d '\r' > 新文件
dos2unix 文件




(3)对数组排序
echo ${数组名[@]} | tr ' ' '\n' | sort -rn | tr '\n' ' '

4.cut命令--对行内容进行字段截取
显示行中的指定部分,删除文件中指定字段
XXX | cut 选项 参数
cut 参数
cat file | cut 选项
-d '分隔符' -f 字段序号 #根据 -d 指定的分隔符的截取显示 -f 指定的字段
字符串分片
echo ${变量:下标:长度} #下标起始从0开始
echo $变量 | cut -b 起始下标-终止下标 #下标起始从1开始
expr substr $变量 起始下标 长度 #下标起始从1开始
| 常用选项 | |
|---|---|
| -f | 通过指定哪一个字段进行提取。cut命令使用“TAB”作为默认的字段分隔符 |
| -d | “TAB”是默认的分隔符,使用此选项可以更改为其他的分隔符 |
| --complement | 取反,不显示 -f 指定的字段 |
| --output-delimiter '分隔符' | 指定输出的字段分隔符 |




5.split命令--linux下将一个大的文件拆分成若干小文件
| 常用选项 | |
|---|---|
| -l | 以行数拆分 |
| –b | 以大小拆分 |
| -d | 输出的目标文件后缀用数字替代 |
如何将一个10G文件分割为10个1G的文件
split -b 1G -d 原文件 目标文件名前缀
如何将一个100行文件分割为10个10行的文件
split -l 10 -d 原文件 目标文件名前缀

6.paste命令--用于合并文件的列
paste 选项 文件1 文件2...
paste [-s] [-d <间隔字符>] 文件...
| 常用选项 | |
|---|---|
| -d <间隔字符> | 用指定的间隔字符取代制表符 |
| -s | 把多行内容合并为一行进行显示 |
合并文件的行
cat 文件1 文件2 ... > 新文件
合并文件的列
paste -d '分隔符' 文件1 文件2 ... > 新文件


7.eval命令
命令字前加上eval时,shell会在执行命令之前扫描它两次。eval命令将首先会先扫描命令行进行所有的置换,然后再执行该命令。该命令适用于那些一次扫描无法实现其功能的变量。该命令对变量进行两次扫描。
eval 在命令行执行前,先将命令行里的变量置换成对应的值后,再执行命令
a=100
b=a
eval echo \$$b 置换成--> echo $a 执行-> 100
eval $b=50 置换成--> a=50 执行
echo $a -> 50


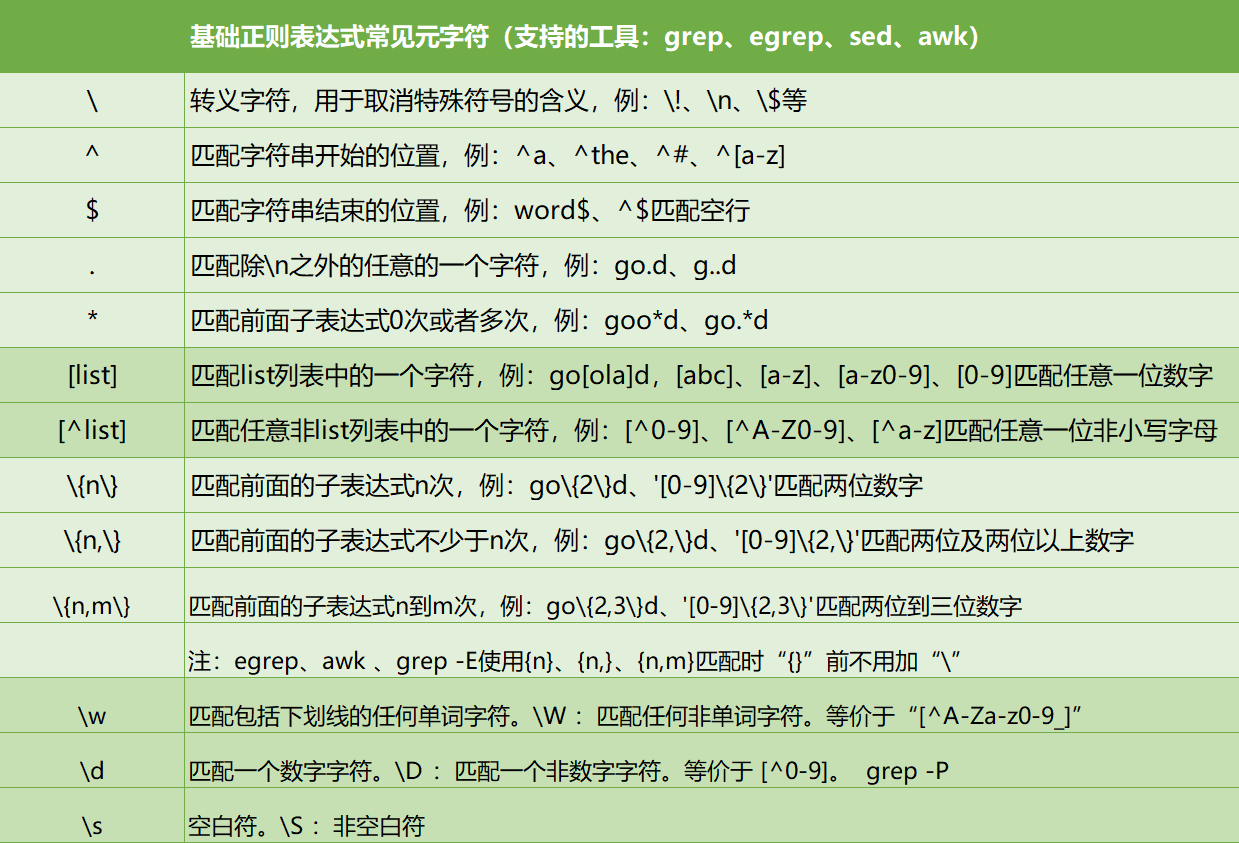
8.正则表达式
通常用于判断语句中,用来检查某一字符串是否满足某一格式。作用对象文件内容。
由普通字符与元字符组成
通配符————作用范围 匹配文件/目录名
正则表达式————作用范围 匹配文件内容
普通字符包括大小写字母、数字、标点符号及一些其他符号
元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符或表达式)在目标对象中的出现模式
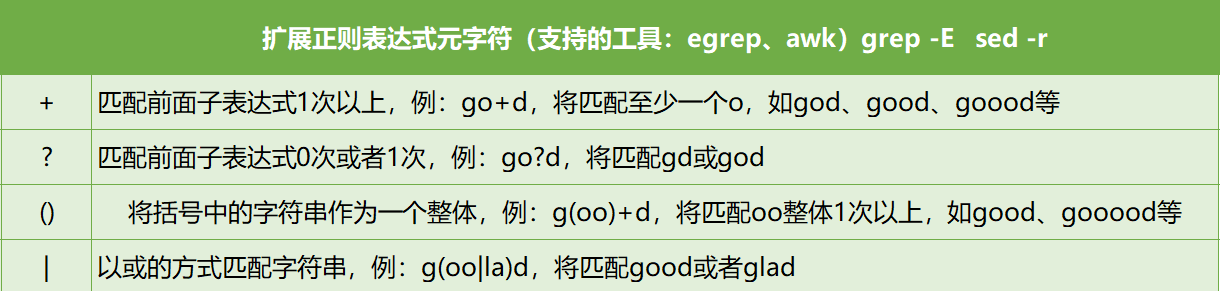
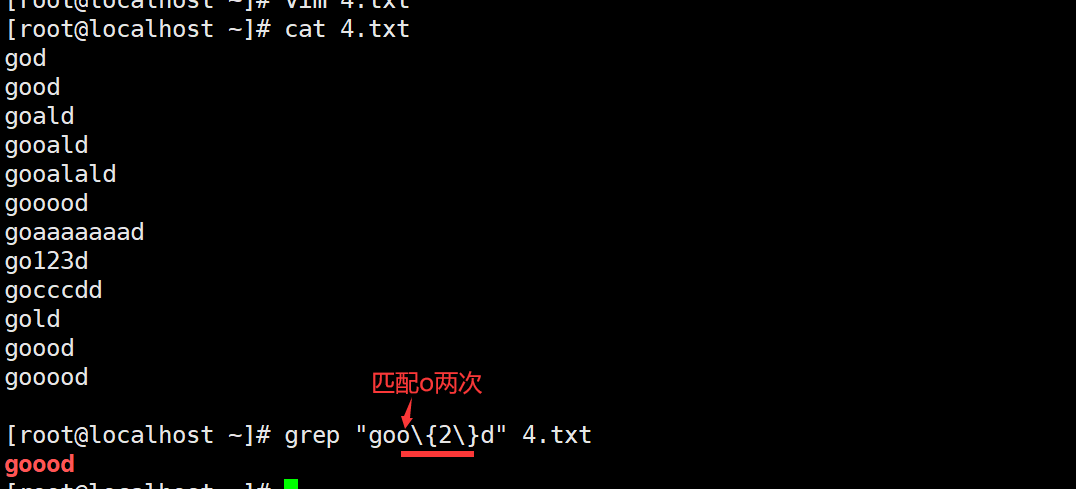
*注:grep sed 使用时 {} 前面要加 \ ;egrep awk grep -E sed -r 使用时 {} 前面不用加 \



题1.02588888888、025-5555555555、025 12345678、025 54321678、025ABC88888、025-85432109、028-85643210、0251-52765421区号025开头,号码与区号间可以是空格、-、没有,号码必须是5或者8开头的八位数
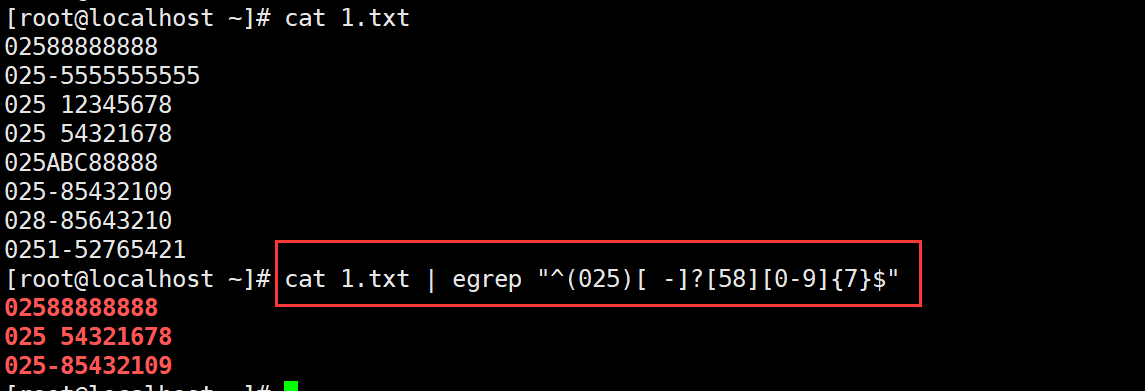
题2.




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了