Shell编程之循环语句与函数
1.循环语句
(1)for循环语句
for 变量 in 取值列表
for ((变量=初始值; 变量范围;变量的迭代方式))
读取不同的变量值,用来逐个执行同一组命令


(2)while循环语句
重复测试某个条件,只要条件成立则反复执行


(3)untli循环语句
重复测试某个条件,只要条件不成立则反复执行

(4)双层循环



2.Shell函数
使用函数可以避免代码重复,使用函数可以将大的工程分割为若干小的功能模块,代码的可读性更强
Shell函数定义:
①
function 函数名 {
命令序列
}
②
函数名() {
命令序列
}
(1)函数返回值:
return表示退出函数并返回一个退出值,脚本中可以用\(?变量显示该值
使用原则:
(1)函数一结束就取返回值,因为\)?变量只返回执行的最后一条命令的退出状态码
(2)退出状态码必须是0~255,超出时值将为除以256取余


(2)函数传参:
通过在 调用函数时,后面跟位置参数;在函数体里使用 $1 $2 来引用函数后面跟的位置参数
注意点:
1)函数体外的 $1 $2 代表的是执行脚本时,脚本后面跟的 第一个 第二个 位置参数
$# 参数个数
$@ $* 所有参数
2)函数体里面的 $1 $2 代表的是调用函数时,函数名后面跟的 第一个 第二个 位置参数
$# 参数个数
$@ $* 所有参数
3)不管在函数体内还是函数体外,$0 都代表脚本本身
#!/bin/bash
#函数的传参
db2() {
sum=$[$1 + $2]
echo $sum
}
###### main ######
read -p "请输入第一个参数:" num1
read -p "请输入第二个参数:" num2
SUM=$(db2 num1 num2)
echo "$num1 + $num2 的和为 $SUM"


(3)函数变量的作用范围:
脚本中定义的函数只能在脚本的shell环境有效
脚本中定义的变量默认是在脚本的shell环境中全局有效(即在函数体内外都有效)
在函数体内使用 local 变量 定义的局部变量只能在函数体内有效,且此后此局部变量与函数体外同名的全局变量没有任何关系



(4)递归


3.Shell数组
(1)定义数组
"abcdef" ## 一个字符串
"a" "b" "c" "d" "e" "f" ##字符串列表
("a" "b" "c" "d" "e" "f") ##数组
(10 20 30 40 50 60)
0 1 2 3 4 5 ##元素的下标
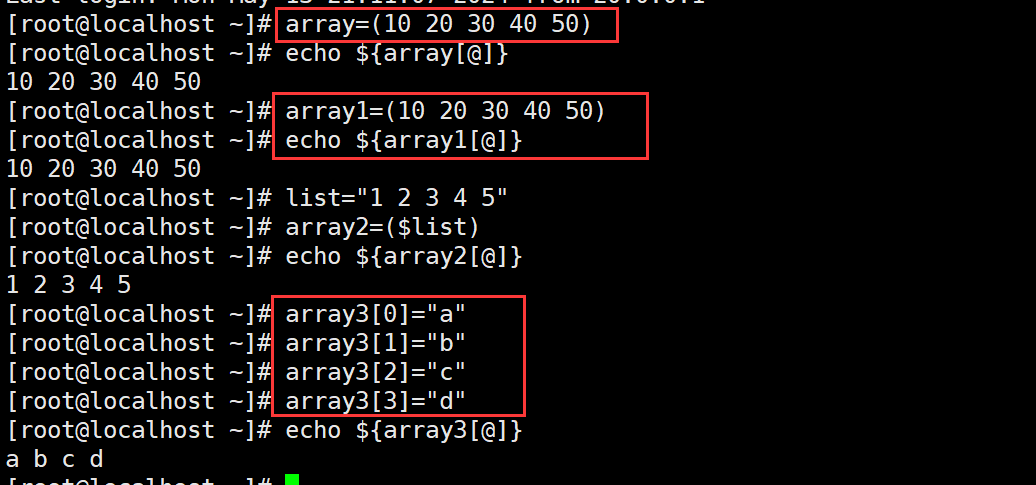
(1)数组名=(元素1 元素2 元素3 ....)
(2)数组名[0]=元素1
数组名[1]=元素2
数组名[2]=元素3
....
(3)list="元素1 元素2 元素3 ...."
数组名=($list)
(2)查看数组
(1)查看数组的元素列表
echo ${数组名[@]}
echo ${数组名[*]}
(2)查看数组的长度(元素的个数)
echo ${#数组名[@]}
echo ${#数组名[*]}
(3)查看数组的元素下标
echo ${!数组名[@]}
echo ${!数组名[*]}
(4)查看某个下标的元素值
echo ${数组名[下标]}





(3)数组分片、字符替换和删除
(1)数组分片
echo ${数组名[@]:下标:长度}
echo ${数组名[*]:下标:长度}
(2)数组字符替换
echo ${数组名[@]/旧字符/新字符}
数组名=(${数组名[*]/旧字符/新字符}) #通过重新定义的方式实现永久替换
(3)数组删除
unset 数组名[下标] #删除数组的某个下标
unset 数组名 #删除数组


(4)追加
数组追加元素
数组名[新下标]=新元素
数组名[数组长度]=新元素 #仅适用于完整的数组
数组名+=(新元素1 新元素2 ....)
数组名=("${数组名[@]}" 新元素1 新元素2 ....)

(5)数组排序算法:
(1)冒泡排序
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
基本思想:
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部。
算法思路
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。


(2)直接选择排序
与冒泡排序相比,直接选择排序的交换次数更少,所以速度会快些。
基本思想:
将指定排序位置与其它数组元素分别对比,如果满足条件就交换元素值,注意这里区别冒泡排序,不是交换相邻元素,而是把满足条件的元素与指定的排序位置交换(如从最后一个元素开始排序),这样排序好的位置逐渐扩大,最后整个数组都成为已排序好的格式。


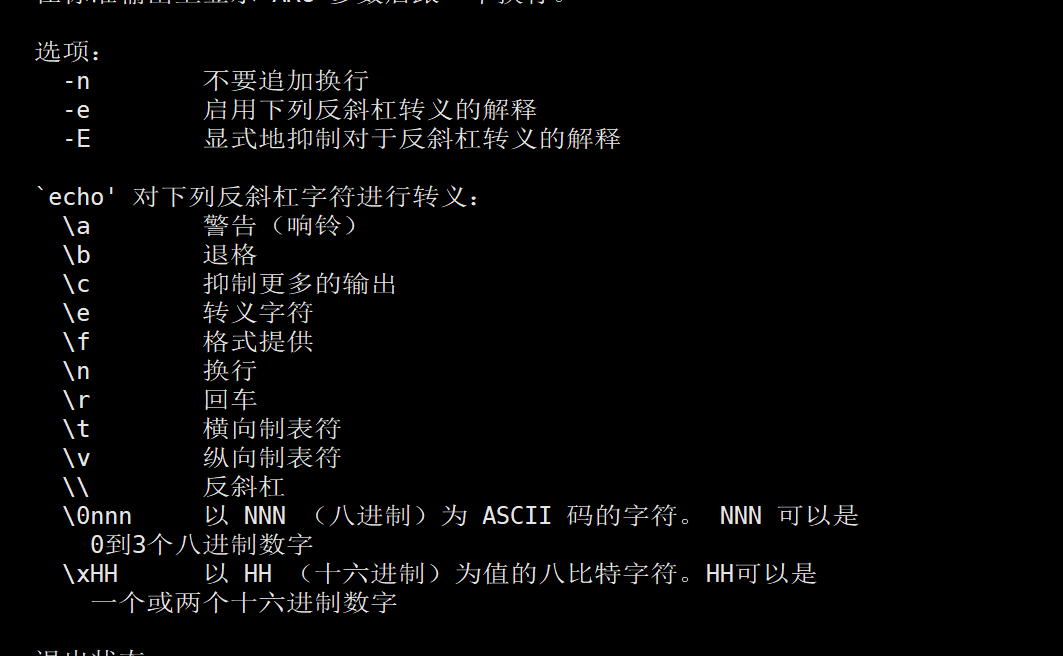
*注:
encho -n #表示不换行输出
encho -e #输出转义字符,将转义后的内容输出到屏幕上
常用的转义字符
\t #转以后表示插入tab,即横向制表符
\f #换行,但是换行后的新行的开头位置连接着上一行的行尾
\v #与\f相同
\n #换行,被输出的字符从"\n"处开始另起一行
\e #转义字符
\c #不换行输出,在"\c"后面不存在字符的情况下,作用相当于 echo -n; 但是当"\c"后面仍然存在字符时,"\c"后面的字符将不会被输出
\r #光标移至行首,但不换行,相当于使用""以后的字符覆盖""之前同等长度的字符;但是当"r"后面不存在任何字符时,""前面的字符不会被覆盖
\\ #表示插入"\"本身