
2024 ICPC 网络预选赛 第 2 场
“你有一天会明白,构成我们身体的原子都来自于恒星的聚变反应,也终有一天它们会归于星辰,只要你的思绪存在,就可以跨越星河,永远璀璨”

0. 批斗
难度排序:F<<A=J=I<L=G=E<C=K=H
赛后批斗,很遗憾最后只开出了
于是我继续和另一个队友去讨论了
这时候队伍排名已经遥遥领先了。接下来才是惨败。
重新读题后更新了公式,但公式莫名其妙被约没了,这时候队友怀疑思路是错的,我提出了坚信这个思路是对的观点,然后独自去推公式了。
不久后推出了存在一个
上面两个错误的观察卡了我们几乎两个多小时。当时我为了追罚时不想求导,劝队友上机三分秒掉,结果手速过慢写了十几分钟。实际上求个导找极点估计只要三五分钟。
但还是写
虽然怀疑是路径维护出了问题,但是我当时自己也没学过路径维护的正确做法,加上队友的代码很难看不确定他是不是真的错了,也没敢强行让队友重写路径维护,而是寄托于主码手自己调。
最后还是没开出来。
赛后检查发现
很遗憾晋级失败了,也不一定能成为外卡选手了。如果被宣告拿不到卡,就是有些人九月已经死了,十一月才闭掉眼睛。
前期的手速也没有任何作用,遇到
很遗憾会以这样的方式收场。
我们队手速快的人没有解决难题的能力,会做难题的人没有代码能力,或许一直是我们队伍的致命缺陷,暴露得如此彻底。
1.题解报告
F
题意:
给
题解:
线性能过,那就秒了,没什么说的。
Code
int n; std::cin >> n; std::vector<i64> a(n + 1); a[0] = 1500; int v = -1; for (int i = 1; i <= n; i++) { std::cin >> a[i]; a[i] += a[i - 1]; if (v == -1 && a[i] >= 4000) { v = i; } } std::cout << v << "\n";
A
题意:
给
每支队伍不知道其他队伍的选赛区情况(哪怕是自己学校的),询问第
题解:
容易发现这是一个欺骗题,我们并不期望能够获得的排名率尽可能优,而是希望排名尽可能高。
于是最高排名一定会选择最小的赛区。直接
维护出每个学校的队伍,假设有
考虑最优选择下的最坏情况。
令
考虑每个队伍,不妨是第
- 这个队伍如果在这些强队中,只需
- 这个队伍如果不在这些强队中,考虑
答案是
Code
int n, k; std::cin >> n >> k; const int INF = 1 << 30; int mi = INF; for (int i = 1; i <= k; i++) { int x; std::cin >> x; mi = std::min(mi, x); } std::map<std::string, std::vector<int> > sch; std::vector<int> a(n + 1); for (int i = 1; i <= n; i++) { std::string s; int x; std::cin >> x >> s; sch[s].push_back(x); a[i] = x; } std::vector<int> teams; for (auto &t : sch) { std::vector<int> vec = t.second; std::sort(vec.begin(), vec.end(), std::greater<>()); for (int i = 0; i < std::min(mi, (int)vec.size()); i++) { teams.push_back(vec[i]); } } int tot = teams.size(); std::sort(teams.begin(), teams.end()); // for (auto x : teams) std::cout << x << " "; std::cout << "\n"; for (int i = 1; i <= n; i++) { auto it = std::lower_bound(teams.begin(), teams.end(), a[i]); int rk = it - teams.begin(); std::cout << tot - rk << "\n"; }
时间复杂度依赖于排序的
J
题意:
给
开始标号为
从上往下第
数据保证物品不会被压缩成负体积。(哪怕真有这种情况也不影响做法)
题解:
任选第个
我们希望验证对于任意一个位置,相邻两个位置的关系。为了方便,不妨用下标
然后考虑仅调换两个物品的顺序
接下来验算一下关系
显然若有
证明了相邻两个物品的顺序,并且证明了传递性质。则可以证明出最优排列按偏序排序。
Code
int n; std::cin >> n; std::vector<std::array<i64, 3> > a(n + 1); for (int i = 1; i <= n; i++) { i64 w, v, c; std::cin >> w >> v >> c; a[i] = {w, v, c}; } std::sort(a.begin() + 1, a.begin() + 1 + n, [&](std::array<i64, 3> A, std::array<i64, 3> B){ // w_1 / c_1 > w_2 / c_2 -> w_1 * c_2 > w_2 * c_1 return A[0] * B[2] > B[0] * A[2]; }); i64 sum = 0, pre = 0; for (int i = 1; i <= n; i++) { sum += a[i][1] - a[i][2] * pre; pre += a[i][0]; } std::cout << sum << "\n";
时间复杂度
I
题意:
给一个十进制的无符号
如果能,输出一个多项式。
题解:
显然我们要构造一个相邻位不能同时为
首先传统进制多项式
一个经典的思路是:由于二进制与所给多项式的数位存在大量交集,且二进制一定可以构造出这个多项式。不妨只从二进制考虑微调构造出这个多项式。
考虑一个小学和初中常遇见的奥数公式:只注意
- 存在性显然。
- 每个数位只能取
不妨通过
Code
const int M = 32; void solve() { int n; std::cin >> n; if ((n >> 0 & 1) == 0 && (n >> 1 & 1) == 0) { std::cout << "NO\n"; return; } std::cout << "YES\n"; std::vector<int> ans(32); int O = __builtin_ctz(n & -n); for (int i = O, j = O; i < M; i++) { while (j < i) { j++; } while (j + 1 < M && (n >> j + 1 & 1) == 0) { j++; } if ((n >> j & 1) == 1) { ans[j] = 1; continue; } // i, j -> 100...0 -> -1 -1 -1 ... 1 ans[j] = 1; for (int k = i; k < j; k++) { ans[k] = -1; } // std::cout << i << " " << j << "\n"; i = j; } for (int i = 0; i < M; i++) { std::cout << ans[i] << " \n"[(i + 1) % 8 == 0]; } }
时间复杂度
副机位刚启动,刚好点开了这题,发现十年前写过,然后直接确定了正确做法。
但队友选择了先跟榜写掉签到题。由于签到都被队友秒了所以拖到第三道题才写。
L
题意:
开局在
- 待机,
- 让
询问使用最优操作让
题解:
设游戏开始到游戏结束的最优期望时间是
根据期望的线性性考虑期望的和等于和的期望:
考虑
- 首先有
- 要么是直接花费
- 要么是使用随机,对时间贡献是
- 要么是直接花费
- 有
于是有
由于
不难证明(比如根据单调性+端点检验)一个宽松边界是
若
这时候可以掂量一下是自己求导求极值快还是写三分快(可能对于很多队伍来说写个三分只需要一分钟)。问题可以解决。
如果求导则有
在
当时我错误地以为队友写三分会比我们推公式快,写着写着发现他不太会写,但当时已经没有决策冷静了,硬写了十几分钟才写出三分。
Code
i64 gcd(i64 a, i64 b) { return b ? gcd(b, a % b) : a; } void solve() { i64 n; std::cin >> n; // E(X) = \frac{v - 1}{2} + \frac{n}{v} -> \sqrt{2v} i64 v1 = std::sqrt(2 * n), v2 = std::sqrt(2 * n) + 1; // std::cout << "v " << v1 << " " << v2 << "\n"; auto calc = [&] (i64 v) -> std::array<i64, 2> { i64 O = v * v - v + 2LL * n, P = 2LL * v; i64 g = gcd(O, P); return {O / g, P / g}; }; std::array<i64, 2> F1 = calc(v1), F2 = calc(v2); if (F1[0] * F2[1] < F2[0] * F1[1]) { std::cout << F1[0] << " " << F1[1] << "\n"; } else { std::cout << F2[0] << " " << F2[1] << "\n"; } }
时间复杂度
最后说说我队如何唐掉的
后续我们大概宕机了半个小时,才意识到期望的和等于和的期望 + 每个位置在游戏开始时的地位是等价的这件事情。放在期末考试几乎都是送分题,前提是前晚着重复习过概率期望。但在竞赛里太少接触过纯期望了,都是马尔可夫链偏多,反应太慢菜是原罪。
再然后继续出了两个致命点:搞了半天推不出,发现有人读错题,再然后重读题,再然后改公式把公式改错了。于是卡了几乎两个小时。
G
题意:
一局游戏,
- 如果有人赢了一局,则败者会减少胜者的筹码数量。若败者筹码数量因此
- 如果平局,游戏立刻进入下一轮。
给出
询问
题解:
因为平局会导致游戏直接进入下一轮,所以平局实际上是一个状态的自环。因为只考虑获胜的后继和失败的后继,所以自环是无效状态。
于是重定义胜败的概率,
分析状态:
- 若
- 若
- 若
- 但凡
- 但凡
尝试暴力搜索这些状态,按轮次的不独立性以乘法原理维护一个搜索树前缀的概率。
不难分析出每个状态要么
或者可以注意到
这个状态递降速度等于辗转相除的递降速度,也可以认为状态个数是
Code
const int MOD = 998244353; i64 ksm(i64 a, i64 n) { i64 res = 1; a = (a + MOD) % MOD; for(;n;n>>=1,a=a*a%MOD)if(n&1)res=res*a%MOD; return res; } void solve() { i64 x, y; std::cin >> x >> y; i64 a0, a1, b; std::cin >> a0 >> a1 >> b; b = a0 + a1; i64 p0 = a0 * ksm(b, MOD - 2) % MOD; i64 p1 = a1 * ksm(b, MOD - 2) % MOD; i64 ans = 0; std::function<void(i64, i64, i64)> dfs = [&] (i64 cx, i64 cy, i64 cur) { // std::cout << cx << " " << cy << "\n"; if (cx == cy) { ans = (ans + cur * p0) % MOD; return; } else if (cx < cy) { i64 d = (cy + cx - 1) / cx - 1; // ceil( (cy - cx) / cx ) dfs(cx, cy - d * cx, cur * ksm(p0, d)) % MOD;); } else { // cx > cy i64 d = (cx + cy - 1) / cy - 1; // ceil( (cx - cy) / cy ) ans = ( ans + cur * (1 - ksm(p1, d) + MOD) ) % MOD; dfs(cx - d * cy, cy, (cur * ksm(p1, d)) % MOD;); } }; dfs(x, y, 1); std::cout << ans << "\n"; }
E
题意:
给
然后给一个
- 你开始在
- 你每走一步,所有机器人会同时走一步且一定会走一步。
- 你如果和机器人处于同一个点,视为你被击杀。
- 机器人和你同时到达
- 如果你从
- 机器人和你同时到达
询问你是否一定可以到达
题解:
首先,随机游走是欺骗性的,只需要考虑最坏情况。
注意你在某个位置能否遇到机器人,只需要考虑是否存在一个机器人有可能在当前时刻也到达这个位置。
首先注意所有机器人的移动半径都是一样的,于是可以用多源
如果存在机器人的移动半径不一样,则多源
根据任意机器人的移动半径相同,这里显然能多源
接下来分析问题。
假设机器人可以选择走或不走,怎么处理?
你的最优选一定是走最短路径,即沿着
那么从所有机器人开始做一个多源
如果你到达某个节点
于是你只需要
机器人一定会走,怎么处理?
如果你到达某个节点
- 如果
- 如果
看起来不好强行处理?
假设
- 如果
- 如果
如何处理
考虑:单层图上
常考虑思路:不妨简单粗暴的考虑一个分层图,分成两层即可。考虑让这样连边(从左图变成右图),然后在分层图上多源 bfs 。这样做可以将原图基于染色时间奇偶拆分。于是发现问题可以被解决。
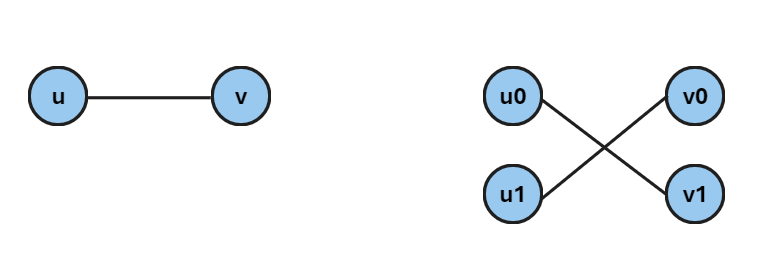
考虑在这个分层图上,从第
新图的
实际上做多源
for (auto v : adj[u]) { if (f[v][c ^ 1] != INF) { // 利用原图的连通性,实现分层的状态图转移 f[v][c ^ 1] = f[u][c] + 1; } }
对于任意一个节点
由于图上
终点可能任意一层的
多源
Code
int n, m, d; std::cin >> n >> m >> d; std::vector<std::vector<int> > adj(n + 1); for (int i = 1; i <= m; i++) { int u, v; std::cin >> u >> v; adj[u].push_back(v); adj[v].push_back(u); } const int INF = 1 << 30; std::queue<std::array<int, 2> > qe; std::vector<std::array<int, 2> > t(n + 1, {INF, INF}); int k; std::cin >> k; for (int i = 1; i <= k; i++) { int x; std::cin >> x; t[x][0] = 0; qe.push({x, 0}); } while (!qe.empty()) { auto ft = qe.front(); int u = ft[0], c = ft[1]; qe.pop(); if (t[u][c] == d) { continue; } for (auto v : adj[u]) { if (t[v][c ^ 1] == INF) { t[v][c ^ 1] = t[u][c] + 1; qe.push({v, c ^ 1}); } } } std::queue<std::array<int, 2> > qe_; std::vector<std::array<int, 2> > t_(n + 1, {INF, INF}); std::vector<std::array<int, 2> > pre(n + 1); qe_.push({1, 0}); t_[1][0] = 0; while (!qe_.empty()) { auto ft = qe_.front(); int u = ft[0], c = ft[1]; qe_.pop(); for (auto v : adj[u]) { if (t_[v][c ^ 1] == INF) { if (t[v][c ^ 1] == INF || t_[u][c] + 1 < t[v][c ^ 1]) { t_[v][c ^ 1] = t_[u][c] + 1; // 这时候 t_[v][c ^ 1] 才更新,我在这 WA 了三小时 pre[v][c ^ 1] = u; qe_.push({v, c ^ 1}); } } } } if (t_[n][0] == INF && t_[n][1] == INF) { std::cout << -1 << "\n"; } else { int x = 0; if (t_[n][x] > t_[n][x ^ 1]) { x ^= 1; } std::vector<int> road; int y = n; while (true) { road.push_back(y); if (y == 1 && x == 0) { break; } y = pre[y][x]; x ^= 1; } std::cout << (int)road.size() - 1 << "\n"; std::reverse(road.begin(), road.end()); assert((int)road.size() - 1 >= 1); for (int i = 0; i < (int)road.size(); i++) { std::cout << road[i] << " \n"[i == (int)road.size() - 1]; } }
然后这个题实际上我自己做,调了三个小时,你知道的,我不是主码手。我把在 bfs 转移的时候,把还未更新的状态用来判断是否转移合法了。去 QOJ 问了数据才找出 bug 。
这显然是维护
C
经典板子题。
题意:
题解:
注意若
举两个例子:
一
二
上述都只需要维护前缀和即可
题目中定义
现在问题为
比较动态的数组变化,需要展开观察动态的变化发生在哪里。
显然新加入的
分析
- 要么
- 要么刚好被确定无法再延长,对应
- 要么早就被确定了无法再延长。
于是增量为
如果可以动态求
如果要求静态
因为
经典问题: 通过
以下的
border
失配数组
- 作为长度是
- 作为下标是
考虑构建
考虑
若
失配的操作:
- 反复缩小
- 若
- 若
失配的实际意义:
注意:
- 这同时也是另一种证明
考虑加入
一个暴力的做法是寻找所有
考虑
- 失配指针回跳过程中:若
- 失配指针回跳结束后:
- 若
- 若
- 若
定义
考虑失配位转移的实现:
for (auto x : vec[k]) { vec[i].push_back(x); }
考虑暴力转移失配位的时空复杂度:
- 时间上,失配最多发生
- 空间上,每次失配发生导致空间加
我们不需要真的维护出动态
时空复杂度
然后不是很懂为什么这题要强制在线,可能是存在某些神奇做法可以离线秒了吧?
Code
int n; std::cin >> n; const int MOD = n; std::vector<int> nxt(n); std::vector<int> s(n), a(n), b(n); std::vector<std::vector<int> > fails(n); i64 ans = 0, pre = 0; for (int i = 0; i < n; i++) { std::cin >> s[i] >> a[i] >> b[i]; s[i] = (s[i] + ans) % MOD; pre += b[i]; if (i > 0) { int j = nxt[i - 1]; while (j > 0 && s[j] != s[i]) { fails[i].push_back(j); j = nxt[j - 1]; } if (s[j] == s[i]) { for (auto x : fails[j]) { fails[i].push_back(x); } j++; } else { fails[i].push_back(j); } nxt[i] = j; } for (auto x : fails[i]) { pre -= b[i - x]; } ans += pre * a[i]; std::cout << ans << "\n"; }
K
经典的拆位分治
题意:
给两个长度为
二分图左侧和右侧各
对
简略题解:
这显然是维护多项式的、按位的、分治
考虑某一位
如果这位上
则把这一位能异或出
如果这位上
这一位能异或出
于是先去分治算可能的答案,用这两个多项式算某个匹配的贡献后可以知道消耗了多少元素。那么剩下的元素如果能匹配就都能任选,再用组合计数算一下贡献。
详细题解:
异或问题可以拆位处理,并且更高位决定更低位。分治 DP 是显然的。
分治方向通常都是从条件更严格的位置往更不严格的方向分治。
考虑从高位往低位枚举一个
钦定忽略掉尾
但这还不够方便,考虑一个更加细致的拆分。将
若
则
让他们分别返回一个多项式
数量按组合方案数进行贡献,显然卷积
若
则
而
考虑当前的多项式
则
于是
考虑组合贡献,最多有
这部分代码为
std::vector<i64> f = dfs(A0, B0, D - 1); std::vector<i64> g = dfs(A1, B1, D - 1); std::vector<i64> F(std::min(A.size(),B.size()) + 1); for (int i = 0; i < f.size(); i++) { for (int j = 0; j < g.size(); j++) { for (int k = 0; k <= std::min(A0.size() - i, B1.size() - j); k++) { for (int l = 0; l <= std::min(A1.size() - j, B0.size() - i); l++) { F[i + j + k + l] = (F[i + j + k + l] + f[i] * g[j] % MOD * Comb[A0.size() - i][k] % MOD * Comb[B1.size() - j][k] % MOD * fac[k] % MOD * Comb[A1.size() - j][l] % MOD * Comb[B0.size() - i][l] % MOD * fac[l] % MOD ) % MOD; } } } }
注意这里
可以继续化简一下这个式子(只是化简,不能降低复杂度)。先将
于是
化简后,代码将更新成如下(本质不变)。
std::vector<i64> f = dfs(A0, B0, D - 1); std::vector<i64> g = dfs(A1, B1, D - 1); std::vector<i64> F(std::min(A.size(),B.size()) + 1); for (int i = 0; i < f.size(); i++) { for (int j = 0; j < g.size(); j++) { std::vector<i64> h = calc(A0.size() - i, B1.size() - j) * calc(A1.size() - j, B0.size() - i); for (int k = 0; k < h.size(); k++) { F[i + j + k] = (F[i + j + k] + f[i] * g[j] % MOD * h[k]) % MOD; } } }
考虑分治递归树的叶子如何处理,按位分治不需要在
考虑
注意如果递归传入了空序列,如果代码处理得不好很可能会触发
考虑如何分析复杂度?看似时间复杂度为
考虑最坏是
都不是。先别急,这不是西安赛区。分析复杂度,
假设当前层的多项式大小为
考虑能在所有
这个常数如果是无穷级数算出来也只是
要算卷积,下标用
Code
const int MOD = 998244353; const int MAXN = 205; i64 Comb[MAXN][MAXN], fac[MAXN]; void initC() { Comb[0][0] = 1; fac[0] = 1; for (int i = 1; i < MAXN; i++) { fac[i] = (fac[i - 1] * i) % MOD; Comb[i][0] = Comb[i][i] = 1; for (int j = 1; j < i; j++) { Comb[i][j] = (Comb[i][j] + Comb[i - 1][j] + Comb[i - 1][j - 1]) % MOD; } } } std::vector<i64> operator * (std::vector<i64> f, std::vector<i64> g) { std::vector<i64> F(f.size() + g.size() - 1); for (int i = 0; i < f.size(); i++) { for (int j = 0; j < g.size(); j++) { F[i + j] = (F[i + j] + f[i] * g[j]) % MOD; } } return F; } std::vector<i64> calc (int A, int B) { std::vector<i64> F(std::min(A, B) + 1); for (int i = 0; i <= std::min(A, B); i++) { F[i] = (F[i] + Comb[A][i] * Comb[B][i] % MOD * fac[i]) % MOD; } return F; }; void solve() { int N; std::cin >> N; i64 K; std::cin >> K; std::vector<i64> a(N), b(N); for (int i = 0; i < N; i++) { std::cin >> a[i]; } for (int i = 0; i < N; i++) { std::cin >> b[i]; } std::function<std::vector<i64>(std::vector<i64>, std::vector<i64>, int)> dfs = [&] (std::vector<i64> A, std::vector<i64> B, int D) -> std::vector<i64> { if (A.empty() || B.empty()) { return {1}; } auto div_to_parity = [&] (std::vector<i64> vec, std::vector<i64> &v0, std::vector<i64> &v1) { for (int i = 0; i < vec.size(); i++) { if (vec[i] >> D & 1) { v1.push_back(vec[i]); } else { v0.push_back(vec[i]); } } }; std::vector<i64> A0, A1; div_to_parity(A, A0, A1); std::vector<i64> B0, B1; div_to_parity(B, B0, B1); if (D == -1) { return calc(A.size(), B.size()); } if (K >> D & 1) { return dfs(A0, B1, D - 1) * dfs(A1, B0, D - 1); } else { std::vector<i64> f = dfs(A0, B0, D - 1); std::vector<i64> g = dfs(A1, B1, D - 1); std::vector<i64> F(std::min(A.size(),B.size()) + 1); for (int i = 0; i < f.size(); i++) { for (int j = 0; j < g.size(); j++) { std::vector<i64> h = calc(A0.size() - i, B1.size() - j) * calc(A1.size() - j, B0.size() - i); for (int k = 0; k < h.size(); k++) { F[i + j + k] = (F[i + j + k] + f[i] * g[j] % MOD * h[k]) % MOD; } } } return F; } }; int d = 60; std::vector<i64> ans = dfs(a, b, d - 1); for (int i = 1; i <= N; i++) { std::cout << ans[i] << "\n"; } }
时间复杂度
似乎这题有一个经典的边卷边算的卷积 trick ,可以用 CDQ 分治跑得更快?感觉用了就上当了。
H
人均没注意到数据随机这句话(写在输入数据里怎么注意到……),榜没歪的话实际上只能算一道银牌题。
这题的
然后由于数据随机完全有可能在上面这个基础上乱优化乱暴力一下就过了。
题意:
二维平面上有
令
你需要回答
吐槽:
从模数和权值范围来看就知道出题人是个好人而且是有东西的,因为我们只需要开
事后好像几乎查明了是 Claris 出的这题。
题解:
为了方便说明复杂度,这里把式子修改成
设第一维范围
出题人让所有数据范围同阶,有利于比赛,但并不利于补题时对算法时间复杂度分析的学习。
首先,条件反射地可以想到讲操作离线下来。
采取一个
问题处于扫描线的角度之下,会变得简单粗暴地容易处理。
扫描线
如果题目故意卡处理:
- 如果值域很大就离散化。
- 如果限制了二维的
条件反射完了,再(先)分析一下题目。
如果能从几何意义角度观察,
最直观的是:若
考虑扫描线过程重的某个时刻的点空间。
- 对于任意一组点集
- 某个新点加入,可能存在
于是定义
考虑如果当前加入了第

显然转移依赖于凸壳顶点
这里只利用了概念上的凸壳的更新转移,并不需要真的维护凸壳进行更新转移。
考虑维护
考虑答案贡献的计算。若当前扫描线坐标为
- 若
- 若
时间复杂度为
另外扫面线遍历的时间复杂度为
是否需要将第二维的点排序在这题不关键。可以注意到第二维的范围
于是总的时间复杂度为
代码如下:
The O(NM+n) solution
int n; std::cin >> n; std::vector<std::vector<std::array<int, 2> > > point(n + 1); for (int i = 1; i <= n; i++) { int x, y, w; std::cin >> x >> y >> w; point[x].push_back({y, w}); } std::vector<int> f(n, n + 1); f[0] = 0; std::vector<int> g(n, n + 1); u64 ans = 0, sum = 0; for (int i = 1; i <= n; i++) { for (auto yw : point[i]) { int y = yw[0], w = yw[1]; g = f; for (int c = 0; c <= n - 1; c++) { int nxtc = c + w >= n ? c + w - n : c + w; g[nxtc] = std::min(g[nxtc], std::max(f[c], y)); } sum = 0; for (int c = 0; c <= n - 1; c++) { f[c] = g[c]; if (f[c] != n + 1) { sum += u64(c) * (u64(n) * (n + 1) - u64(f[c]) * (f[c] - 1)) / 2; } } } ans += sum * i; } std::cout << ans << "\n";
但是这是通过不了数据的。
注意到输入数据描述里存在一行文字,“输入数据随机”。
让考虑一个看似莫名其妙的剪枝优化。
注意状态转移方程
若新加进来的第
维护所有最有凸壳的顶点的最大值为
由于不确定什么时候第一个点会出现,可以先将
实现这个优化。神秘的事情发生了,然后它就过了?
接下来将会证明这个优化的时间复杂度期望为
先讨论一件事情:
这个问题太过于经典了以至于我希望再进行一遍推导。
定义
这个问题直接用定义计算
考虑期望间的马尔可夫链转移(求第推式),不妨定义
于是我们已知
消耗一次操作后,
得到递推式后,这里不进行 DP 。累加法是一个简便常用的方法
观察这个
可以发现
于是
考虑随机状态下,已经在平面中加入了
从
关于
下述定理经典的,且会是直觉上显然的(但是证明需要生成函数爆算一下,我暂时不会,不妨暂时记一下):
对于
于是
从期望第
从期望第
于是凸壳最多会被更新
于是时间复杂度为
最终代码
Code
int n; std::cin >> n; std::vector<std::vector<std::array<int, 2> > > point(n + 1); for (int i = 1; i <= n; i++) { int x, y, w; std::cin >> x >> y >> w; point[x].push_back({y, w}); } std::vector<int> f(n, n + 1); f[0] = 0; std::vector<int> g(n, n + 1); u64 ans = 0, sum = 0; for (int i = 1, mx = n + 1; i <= n; i++) { for (auto yw : point[i]) if (yw[0] < mx) { int y = yw[0], w = yw[1]; g = f; for (int c = 0; c <= n - 1; c++) { int nxtc = c + w >= n ? c + w - n : c + w; g[nxtc] = std::min(g[nxtc], std::max(f[c], y)); } sum = 0, mx = 0; for (int c = 0; c <= n - 1; c++) { f[c] = g[c]; mx = std::max(mx, f[c]); if (f[c] != n + 1) { sum += u64(c) * (u64(n) * (n + 1) - u64(f[c]) * (f[c] - 1)) / 2; } } } ans += sum * i; } std::cout << ans << "\n";
一些鬼故事
- 我多次误把 u64 写成 u32 ?是因为 u32 以前常用,而 u64 没用过
- defint int u64 肯定会慢。最坏可能慢一倍。
- 模
- 终极鬼故事:第二段代码
// 1-st if (y < mx) { continue; } g = f; // vector g -> f // 2-nd g = f; // vector g -> f if (y < mx) { continue; }
2024-10-05 09:02:17
可能完结了。
更新
2025-02-07 01:21:29
可能是最后更新。
不出意外地没打到入围名额,但后来求到了外卡。
打算去旅游了。
然后打了两块银牌,挺魔幻的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】