

机器学习-实验一
名称 |
内容 |
|---|---|
| 博客班级 | 班级链接 |
| 作业要求 | 作业链接 |
| 学号 | 3180701118 |
一.实验目的
1.理解感知器算法原理,能实现感知器算法;
2.掌握机器学习算法的度量指标;
3.掌握最小二乘法进行参数估计基本原理;
4.针对特定应用场景及数据,能构建感知器模型并进行预测。
二.实验内容
1.安装Pycharm,注册学生版。
2.安装常见的机器学习库,如Scipy、Numpy、Pandas、Matplotlib,sklearn等。
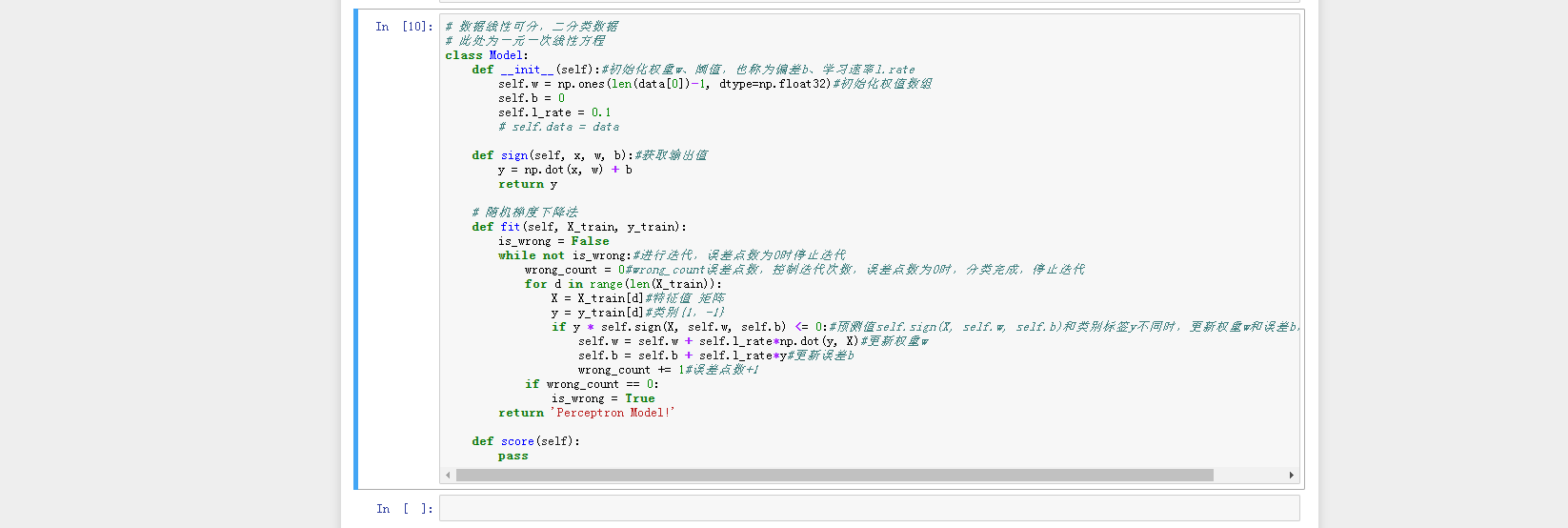
3.编程实现感知器算法。
4.熟悉iris数据集,并能使用感知器算法对该数据集构建模型并应用
三.实验过程及结果
实验代码及注释
import pandas as pd
#Pandas,是python的一个数据分析包,Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
#DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表,单元格可以存放数值、字符串等。
import numpy as np
#引用numpy库,它是处理数值计算最为基础的类库
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
#引用画图工具
%matplotlib inline
# load data载入数据
iris = load_iris() #ris数据集(鸢尾花数据集)
df = pd.DataFrame(iris.data, columns=iris.feature_names)
#iris数据集中属性feature_names包括四个:Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度),特征值都为正浮点数,单位为厘米。
df['label'] = iris.target
#iris.target为目标值,目标值为鸢尾花的分类(Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾))
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
#获取数据集中的列名
df.label.value_counts()
#value_counts():计算series里面相同数据出现的频率(次数);
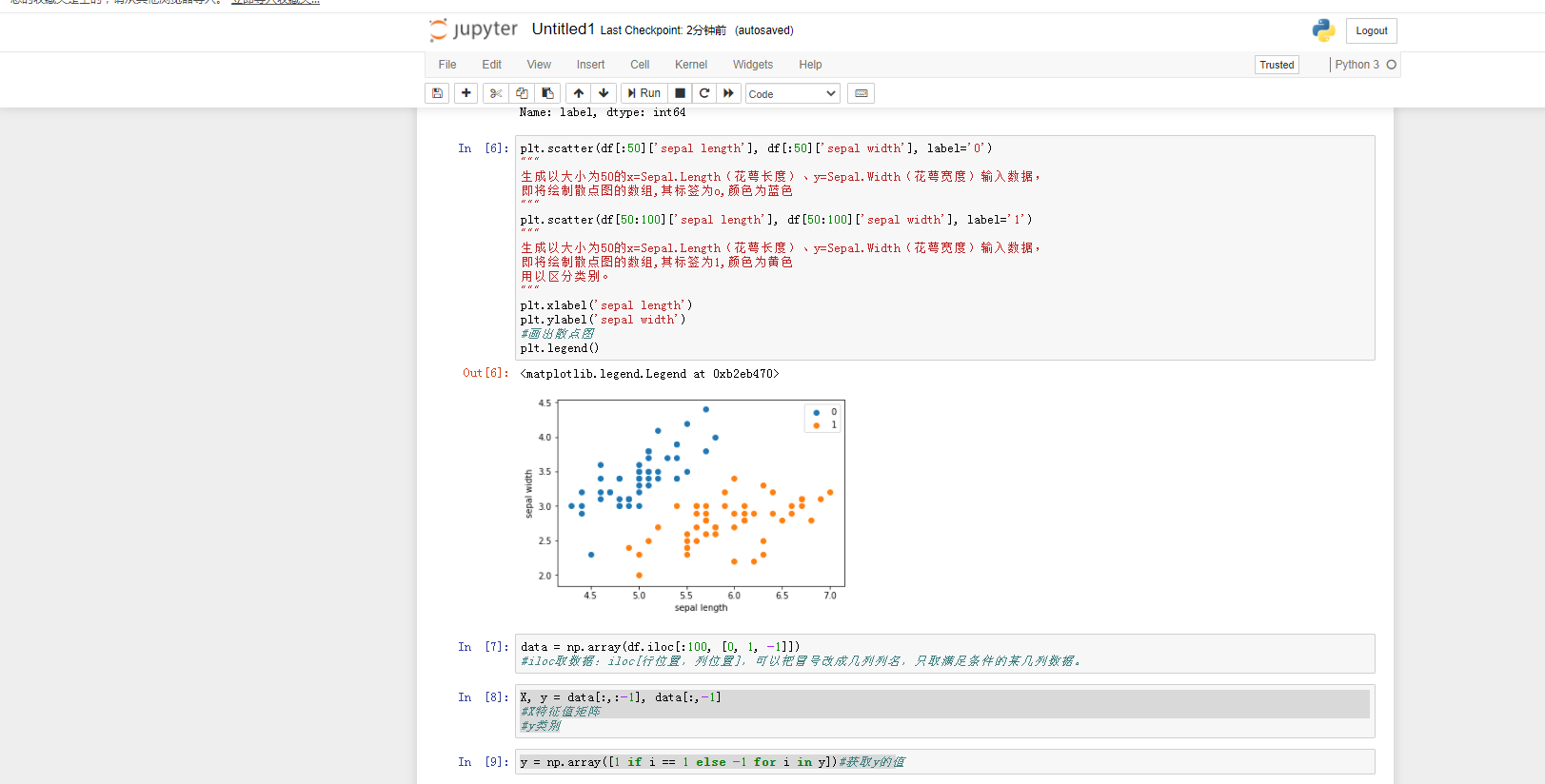
plt.scatter(df[:50]['sepal length'], df[:50]['sepal width'], label='0')
#生成以大小为50的x=Sepal.Length(花萼长度)、y=Sepal.Width(花萼宽度)输入数据,
#即将绘制散点图的数组,其标签为o,颜色为蓝色
plt.scatter(df[50:100]['sepal length'], df[50:100]['sepal width'], label='1')
#生成以大小为50的x=Sepal.Length(花萼长度)、y=Sepal.Width(花萼宽度)输入数据,
#即将绘制散点图的数组,其标签为1,颜色为黄色
#用以区分类别。
plt.xlabel('sepal length')
plt.ylabel('sepal width')
#画出散点图
plt.legend()
data = np.array(df.iloc[:100, [0, 1, -1]])
#iloc取数据:iloc[行位置,列位置],可以把冒号改成几列列名,只取满足条件的某几列数据。
X, y = data[:,:-1], data[:,-1]
#X特征值矩阵
#y类别
实验结果截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号