kmp算法
今天突然打开以前用c语言编写的kmp算法,细细看了下,发现有点遗忘,所以写下这篇随笔加深下我对串匹配算法的理解。
串匹配:在源字符串中查找是否存在目标字符串。
下面我先写几组字符串:
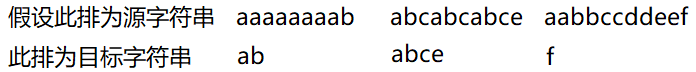
显然,聪明的我们,一眼就能看出来答案。但是要说到算法实现,相信有点编程基础的,很快会在脑子里想到两层暴力循环解决,我把部分代码编写了一下。
以上述第二组字符串为例:(为了叙述方便,黑箭头所指的位置记为失配点,蓝箭头所指的位置表示正在判断是否匹配的位置)

1 int i; 2 int j; 3 for (i = 0; i <= strLen - subStrLen; i++) { //strLen源串长度 subStrLen目标串长度 4 for (j = 0; j < subStrLen; j++) { 5 if (str[i + j] != subStr[j]) //str源串 subStr目标串 6 break; 7 } 8 if ( j >= subStrLen) { 9 // 存在 10 ... 11 return; 12 } 13 } 14 15 // 不存在
上面代码逻辑简单,也能判断字符串是否匹配,但时间复杂度很高,最坏情况下时间复杂度为 n * m; n = strLen, m=subStrLen。
有一种时间复杂度近似为o(n + m)的算法,那就是kmp算法。接下来,我叙述下我理解的kmp算法。
首先:在匹配时,
如果目标字符串首元素失配,应该用源串失配点的下一个元素与目标字符串首元素比较。
如果不是目标字符串首元素失配。 在失配时,不往前回溯,即直接从失配点处比较,这样一趟下来时间复杂度近似为o(n + m)。但目标串该用哪个元素的值去和源串失配点处的值比较呢?一定是第一个吗?先看几组例子:
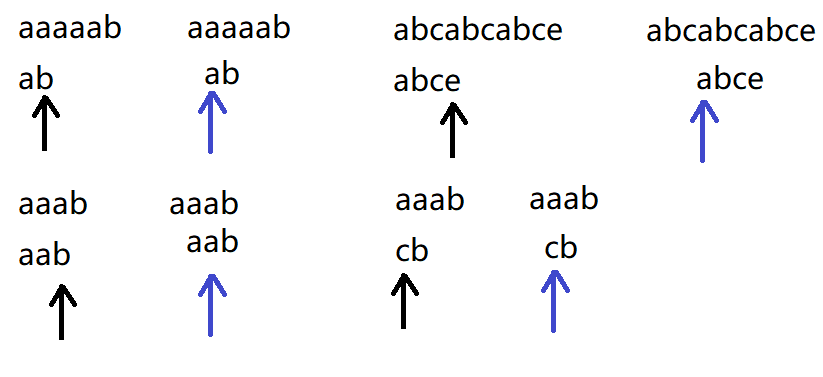
并不都是第一个,比如第三个例子。现在我们思考如何在失配时确定合适的目标串元素来进行后续比较(next数组的形成过程)。
假如目标串下标为0的元素失配,虽然不在我们这种情况以内(看上边红色的字),但我们只能用目标串下标为0的和源串失配点下一个比较。
假如目标串下标为1的元素失配,我们只能用目标串下标为0的和源串失配点处的值比较。
仔细思考发现,失配若发生在下标为0或1的情况下,我们只能用目标串下标为0的进行比较。
现在考虑除失配发生在下标为0或1以外的其他情况,看上面第三个例子,它是用目标串下标为1的和源串失配点进行比较,原因是当目标串下标为2的发生失配后,两字符串(源和目标)在失配点前面的元素对应相同,而目标串下标为2的前一个元素和下标为0的元素也相同,即源串下标为1的和目标串下标为0的相同,所以第三个例子蓝色箭头前面的一组a不用比较,是相同的。发现这个过程可以与源串毫无关系,即仅通过目标串和失配点便可推出那个合适的位置。
对于目标串aab,假如在b处失配,应比较下标为2的前一个元素和下标为0的元素是否相同,而这个下标为0正是目标串aab,在下标为2的前一个元素失配时,所要找的合适位置。
接着举几个例子,找一下当目标字符串在对应下标位置失配时所要找的合适位置的下标(我已经找出来了)

上面一行数字便表示当目标字符串在对应位置失配时所要找的目标串合适位置的下标 (即next数组)
总结出规律:
假如匹配时目标串在某处失配(下标0,1除外,因为0,1失配时,要找的合适位置直接是首元素),应比较该处的前一个元素和在该处的前一个元素失配时,所应找的合适位置的元素是否相同。若相同,则把该处的前一个元素失配时,所应找的合适位置的下一个元素作为自己失配时要找的合适位置。若不同,则用该处的前一个元素和在该处的前一个元素失配时,找到的合适位置所对应的元素失配时,所找的合适位置的元素进行比较,依次往前,直到找到相等的,则把与该处的前一个元素相等的那个元素在失配时所找到的合适位置的下一个元素作为自己失配时要找的合适位置。若未找到相等的,则把首元素作为自己失配时要找的合适位置。
这段话,最好用上面aabaabcaab这个例子跟踪一遍。
进行上述操作,相当于,若在某处失配,查看失配处前面会有多少元素与源串重复,不用参加比较。
根据上述思路,给出求next数组的代码,最好再用上面aabaabcaab这个例子对比代码跟踪一遍。
1 void getNextArray(int *arr, char *subStr) { 2 int len = strlen(subStr); 3 int i = 2; 4 int j = 0; 5 arr[0] = arr[1] = 0; 6 7 while (i < len) { 8 if (subStr[i - 1] == subStr[j]) 9 { 10 arr[i] = ++j; 11 i++; 12 } 13 else if (0 == j) { 14 arr[i] = 0; 15 i++; 16 } 17 else 18 j = arr[j]; 19 } 20 21 }
有了next数组,紧接着就容易多了,我给出一组匹配过程,可以根据这组过程理解一下下边代码。

1 int Kmp(char *str, char *subStr) { 2 int i = 0; 3 int j = 0; 4 int Len = strlen(str); 5 int len = strlen(subStr); 6 int *next = (int *) calloc(sizeof(int), len); 7 getNextArray(next, subStr); 8 9 while(Len - i + j >= len) { 10 if(str[i] == subStr[j]) { 11 i++; 12 j++; 13 if(j >= len) { 14 free(next); 15 return i - j; 16 } 17 } 18 else if(0 == j) 19 i++; 20 else 21 j = next[j]; 22 } 23 24 free(next); 25 return -1; 26 27 }
主函数
int main() { char str[80]; char subStr[80]; int index; printf("please the src string:"); gets(str); printf("please the sub string:"); gets(subStr); index = Kmp(str, subStr); if(index == -1) printf("Not Found!\n"); else printf("the index is %d\n", index); return 0; }
结果:
please the src string:aaaaaabcffhsjsss
please the sub string:js
the index is 12

 浙公网安备 33010602011771号
浙公网安备 33010602011771号