Hdfs存储策略
一、磁盘选择策略
1.1、介绍
在HDFS中,所有的数据都是存在各个DataNode上的.而这些DataNode上的数据都是存放于节点机器上的各个目录中的,而一般每个目录我们会对应到1个独立的盘,以便我们把机器的存储空间基本用上.这么多的节点,这么多块盘,HDFS在进行写操作时如何进行有效的磁盘选择呢
HDFS目前的2套磁盘选择策略都是围绕着"数据均衡"的目标设计的:RoundRobinVolumeChoosingPolicy和AvailableSpaceVolumeChoosingPolicy
1.2、RoundRobinVolumeChoosingPolicy
名称可以拆成2个单词,RoundRobin和VolumeChoosingPolicy,VolumeChoosingPolicy理解为磁盘选择策略,RoundRobin这个是一个专业术语,叫做"轮询",类似的还有一些别的类似的术语,Round-Robin Scheduling(轮询调度),Round-Robin 算法等.RoundRobin轮询的意思用最简单的方式翻译就是一个一个的去遍历,到尾巴了,再从头开始。
理论上来说这种策略是蛮符合数据均衡的目标的,因为一个个的写吗,每块盘写入的次数都差不多,不存在哪块盘多写少写的现象,但是唯一的不足之处在于每次写入的数据量是无法控制的,可能我某次操作在A盘上写入了512字节的数据,在轮到B盘写的时候我写了128M的数据,数据就不均衡了,所以说轮询策略在某种程度上来说是理论上均衡但还不是最好的。
实现很简单:
volumes 参数其实就是通过 dfs.datanode.data.dir 配置的目录。blockSize 就是咱们副本的大小。RoundRobinVolumeChoosingPolicy 策略先轮询的方式拿到下一个 volume ,如果这个 volume 的可用空间比需要存放的副本大小要大,则直接返回这个 volume 用于存放数据;如果当前 volume 的可用空间不足以存放副本,则以轮询的方式选择下一个 volume,直到找到可用的 volume,如果遍历完所有的 volumes 还是没有找到可以存放下副本的 volume,则抛出 DiskOutOfSpaceException 异常。
从上面的策略可以看出,这种轮询的方式虽然能够保证所有磁盘都能够被使用,但是如果 HDFS 上的文件存在大量的删除操作,可能会导致磁盘数据的分布不均匀,比如有的磁盘存储得很满了,而有的磁盘可能还有很多存储空间没有得到利用。
1.3、AvailableSpaceVolumeChoosingPolicy
剩余可用空间磁盘选择策略.这个磁盘选择策略比第一种设计的就精妙很多了,首选他根据1个阈值,将所有的磁盘分为了2大类,高可用空间磁盘列表和低可用空间磁盘列表.然后通过1个随机数概率,会比较高概率下选择高剩余磁盘列表中的块,然后对这些磁盘列表进行轮询策略的选择。
可用空间磁盘选择策略是从 Hadoop 2.1.0 开始引入的(详情参见:HDFS-1804)。这种策略优先将数据写入具有最大可用空间的磁盘(通过百分比计算的)。在实现上可用空间选择策略内部用到了上面介绍的轮询磁盘选择策略,具体的实现代码在 org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy 类中,核心实现如下:
areAllVolumesWithinFreeSpaceThreshold 函数的作用是先计算所有 volumes 的最大可用空间和最小可用空间,然后使用最大可用空间减去最小可用空间得到的结果和 balancedSpaceThreshold(通过 dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold 参数进行配置,默认值是 10G) 进行比较。
可用空间策略会以下面三种情况进行处理:
1、如果所有的 volumes 磁盘可用空间都差不多,那么这些磁盘得到的最大可用空间和最小可用空间差值就会很小,这时候就会使用轮询磁盘选择策略来存放副本。
2、如果 volumes 磁盘可用空间相差比较大,那么可用空间策略会将 volumes 配置中的磁盘按照一定的规则分为 highAvailableVolumes 和 lowAvailableVolumes。具体分配规则是先获取 volumes 配置的磁盘中最小可用空间,加上 balancedSpaceThreshold(10G),然后将磁盘空间大于这个值的 volumes 放到 highAvailableVolumes 里面;小于等于这个值的 volumes 放到 lowAvailableVolumes 里面。
比如我们拥有5个磁盘组成的 volumes,编号和可用空间分别为 1(1G)、2(50G)、3(25G)、4(5G)、5(30G)。按照上面的规则,这些磁盘的最小可用空间为 1G,然后加上 balancedSpaceThreshold,得到 11G,那么磁盘编号为1、4的磁盘将会放到 lowAvailableVolumes 里面,磁盘编号为2,3和5将会放到 highAvailableVolumes 里面。
到现在 volumes 里面的磁盘已经都分到 highAvailableVolumes 和 lowAvailableVolumes 里面了。
2.1、如果当前副本的大小大于 lowAvailableVolumes 里面所有磁盘最大的可用空间(mostAvailableAmongLowVolumes,在上面例子中,lowAvailableVolumes 里面最大磁盘可用空间为 5G),那么会采用轮询的方式从 highAvailableVolumes 里面获取相关 volumes 来存放副本。
2.2、剩下的情况会以 75%(通过 dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction 参数进行配置,推荐将这个参数设置成 0.5 到 1.0 之间)的概率在 highAvailableVolumes 里面以轮询的方式 volumes 来存放副本;25% 的概率在 lowAvailableVolumes 里面以轮询的方式 volumes 来存放副本。
然而在一个长时间运行的集群中,由于 HDFS 中的大规模文件删除或者通过往 DataNode 中添加新的磁盘仍然会导致同一个 DataNode 中的不同磁盘存储的数据很不均衡。即使你使用的是基于可用空间的策略,卷(volume)不平衡仍可导致较低效率的磁盘I/O。比如所有新增的数据块都会往新增的磁盘上写,在此期间,其他的磁盘会处于空闲状态,这样新的磁盘将会是整个系统的瓶颈
1.4、相关配置
dfs.datanode.fsdataset.volume.choosing.policy:The class name of the policy for choosing volumes in the list of directories. Defaults to org.apache.hadoop.hdfs.server.datanode.fsdataset.RoundRobinVolumeChoosingPolicy. If you would like to take into account available disk space, set the value to "org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy".。这两种磁盘选择策略都是对 org.apache.hadoop.hdfs.server.datanode.fsdataset.VolumeChoosingPolicy 接口进行实现。
dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold:默认值(10737418240:10G)只有在AvailableSpaceVolumeChoosingPolicy配置下才生效,
dfs.datanode.available-space-volume-choosing-policy.balanced-space-preference-fraction:默认值(0.75f)只有在AvailableSpaceVolumeChoosingPolicy配置下才生效
参考网址:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
https://blog.csdn.net/weixin_41076809/article/details/80047557
https://blog.csdn.net/androidlushangderen/article/details/50531760
二、存储策略
2.1、存储类型
DISK:默认的存储类型,磁盘存储
ARCHIVE:具有存储密度高(PB级),但计算能力小的特点,可用于支持档案存储。
SSD:固态硬盘
RAM_DISK:DataNode中的内存空间
HDFS中是定义了这4种类型,SSD,DISK一看就知道是什么意思,这里看一下其余的2个,RAM_DISK,其实就是Memory内存,而ARCHIVE并没有特指哪种存储介质,主要的指的是高密度存储数据的介质来解决数据量的容量扩增的问题.这4类是被定义在了StorageType类中:
public enum StorageType { // sorted by the speed of the storage types, from fast to slow RAM_DISK(true), SSD(false), DISK(false), ARCHIVE(false); ...
旁边的true或者false代表的是此类存储类型是否是transient特性的.transient的意思是指转瞬即逝的,并非持久化的.在HDFS中,如果没有主动声明数据目录存储类型的,默认都是DISK,配置属性dfs.datanode.data.dir中进行本地对应存储目录的设置,同时带上一个存储类型标签,声明此目录用的是哪种类型的存储介质,例子如下:
[SSD]file:///grid/dn/ssd0
如果目录前没有带上[SSD]/[DISK]/[ARCHIVE]/[RAM_DISK]这4种中的任何一种,则默认是DISK类型.
2.2、存储原理
-
DataNode通过心跳汇报自身数据存储目录的StorageType给NameNode,
-
随后NameNode进行汇总并更新集群内各个节点的存储类型情况
-
待复制文件根据自身设定的存储策略信息向NameNode请求拥有此类型存储介质的DataNode作为候选节点
2.3、存储类型选择策略
HDFS中提供热、暖、冷、ALL_SSD、One_SSD、Lazy_Persistence等存储策略。为了根据不同的存储策略将文件存储在不同的存储类型中,引入了一种新的存储策略概念。HDFS支持以下存储策略:
6种策略:
- Hot - for both storage and compute. The data that is popular and still being used for processing will stay in this policy. When a block is hot, all replicas are stored in DISK.
- Cold - only for storage with limited compute. The data that is no longer being used, or data that needs to be archived is moved from hot storage to cold storage. When a block is cold, all replicas are stored in ARCHIVE.
- Warm - partially hot and partially cold. When a block is warm, some of its replicas are stored in DISK and the remaining replicas are stored in ARCHIVE.
- All_SSD - for storing all replicas in SSD.
- One_SSD - for storing one of the replicas in SSD. The remaining replicas are stored in DISK.
- Lazy_Persist - for writing blocks with single replica in memory. The replica is first written in RAM_DISK and then it is lazily persisted in DISK.
热(hot)
-
用于大量存储和计算
-
当数据经常被使用,将保留在此策略中
-
当block是hot时,所有副本都存储在磁盘中。
冷(cold)
-
仅仅用于存储,只有非常有限的一部分数据用于计算
-
不再使用的数据或需要存档的数据将从热存储转移到冷存储中
-
当block是cold时,所有副本都存储在Archive中
温(warm)
-
部分热,部分冷
-
当一个块是warm时,它的一些副本存储在磁盘中,其余的副本存储在Archive中
全SSD
- 将所有副本存储在SSD中
单SSD
- 在SSD中存储一个副本,其余的副本存储在磁盘中。
懒持久
- 用于编写内存中只有一个副本的块。副本首先写在RAM_Disk中,然后惰性地保存在磁盘中。
HDFS存储策略由以下字段组成:
-
策略ID(Policy ID)
-
策略名称(Policy Name)
-
块放置的存储类型列表(Block Placement)
-
用于创建文件的后备存储类型列表(Fallback storages for creation)
-
用于副本的后备存储类型列表(Fallback storages for replication)
当有足够的空间时,块副本将根据#3中指定的存储类型列表存储。当列表#3中的某些存储类型耗尽时,将分别使用#4和#5中指定的后备存储类型列表来替换空间外存储类型,以便进行文件创建和副本。
以下是一个典型的存储策略表格:
| Policy ID | Policy Name | Block Placement (n replicas) | Fallback storages for creation | Fallback storages for replication |
|---|---|---|---|---|
| 15 | Lazy_Persist | RAM_DISK: 1, DISK: n-1 | DISK | DISK |
| 12 | All_SSD | SSD: n | DISK | DISK |
| 10 | One_SSD | SSD: 1, DISK: n-1 | SSD, DISK | SSD, DISK |
| 7 | Hot (default) | DISK: n | ARCHIVE | |
| 5 | Warm | DISK: 1, ARCHIVE: n-1 | ARCHIVE, DISK | ARCHIVE, DISK |
| 2 | Cold | ARCHIVE: n | ||
| 1 | Provided | PROVIDED: 1, DISK: n-1 | PROVIDED, DISK | PROVIDED, DISK |
注意事项:
-
Lazy_Persistence策略仅对单个副本块有用。对于具有多个副本的块,所有副本都将被写入磁盘,因为只将一个副本写入RAM_Disk并不能提高总体性能。
-
对于带条带的擦除编码文件,合适的存储策略是ALL_SSD、HOST、CORD。因此,如果用户为EC文件设置除上述之外的策略,在创建或移动块时不会遵循该策略。
2.4、命令
hdfs storagepolicies -help
$ hdfs storagepolicies -help
[-listPolicies]
List all the existing block storage policies.
[-setStoragePolicy -path <path> -policy <policy>]
Set the storage policy to a file/directory.
<path> The path of the file/directory to set storage policy
<policy> The name of the block storage policy
[-getStoragePolicy -path <path>]
Get the storage policy of a file/directory.
<path> The path of the file/directory for getting the storage policy
1个设置命令,2个获取命令,最简单的使用方法是事先划分好冷热数据存储目录。设置好对应的Storage Policy,然后后续相应的程序在对应分类目录下写数据,自动继承父目录的存储策略。在较新版的Hadoop发布版本中增加了数据迁移工具(hdfs mover -help)。此工具的重要用途在于他会扫描HDFS上的文件,判断文件是否满足其内部设置的存储策略,如果不满足,就会重新迁移数据到目标存储类型节点上。
列出所有存储策略:hdfs storagepolicies -listPolicies
[root@node1 Examples]# hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
设置存储策略:hdfs storagepolicies -setStoragePolicy -path
| -path |
引用目录或文件的路径 |
|---|---|
| -policy |
存储策略的名称 |
取消存储策略:取消文件或目录的存储策略。在执行unset命令之后,将应用当前目录最近的祖先存储策略,如果没有任何祖先的策略,则将应用默认的存储策略。
hdfs storagepolicies -unsetStoragePolicy -path
| -path |
引用目录或文件的路径 |
|---|
获取存储策略:hdfs storagepolicies -getStoragePolicy -path
| -path |
引用目录或文件的路径。 |
|---|
2.5、配置
-
dfs.storage.policy.enabled:启用/禁用存储策略功能。默认值是true
-
dfs.datanode.data.dir:在每个数据节点上,应当用逗号分隔的存储位置标记它们的存储类型。这允许存储策略根据策略将块放置在不同的存储类型上。
磁盘上的DataNode存储位置/grid/dn/disk 0应该配置为[DISK]file:///grid/dn/disk0
SSD上的DataNode存储位置/grid/dn/ssd 0应该配置为 [SSD]file:///grid/dn/ssd0
存档上的DataNode存储位置/grid/dn/Archive 0应该配置为 [ARCHIVE]file:///grid/dn/archive0
将RAM_磁盘上的DataNode存储位置/grid/dn/ram0配置为[RAM_DISK]file:///grid/dn/ram0
如果DataNode存储位置没有显式标记存储类型,它的默认存储类型将是磁盘。
2.6、冷热温三阶段数据存储
为了更加充分的利用存储资源,我们可以将数据分为冷、热、温三个阶段来存储。
| /data/hdfs-test/data_phase/hot | 热阶段数据 |
|---|---|
| /data/hdfs-test/data_phase/warm | 温阶段数据 |
| /data/hdfs-test/data_phase/cold | 冷阶段数据 |
配置存储目录:
进入到Hadoop配置目录,编辑hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file:///export/server/hadoop-3.1.4/data/datanode,ARCHIVE]file:///export/server/hadoop-3.1.4/data/archive</value>
<description>DataNode存储名称空间和事务日志的本地文件系统上的路径</description>
</property>
然后分发到其他节点,再重启hdfs。
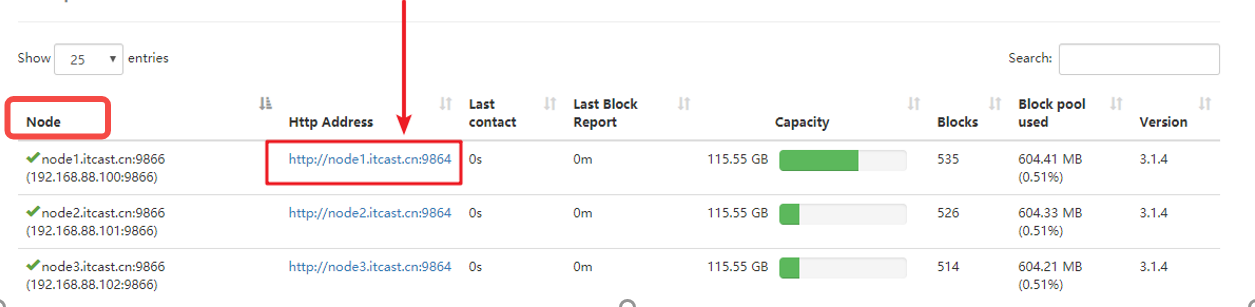
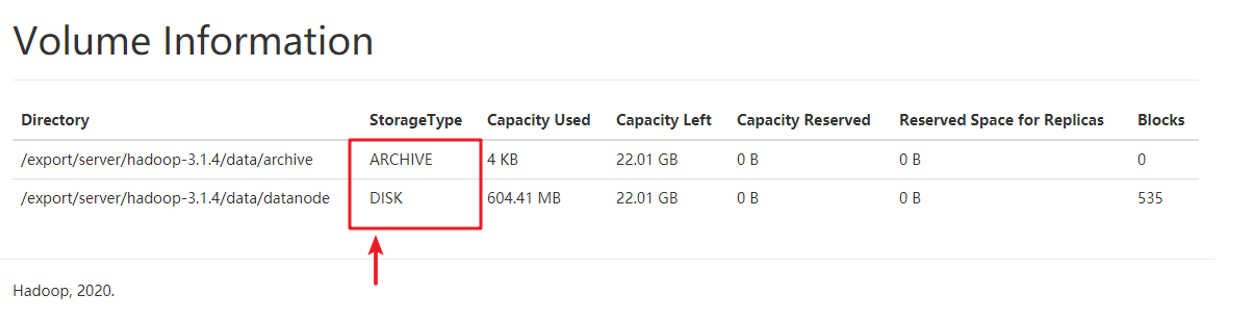
可以看到,现在配置的是两个目录,一个StorageType为ARCHIVE、一个Storage为DISK。
配置策略:
- 创建目录
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/hot
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/warm
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/cold
- 查看当前HDFS支持的存储策略
[root@node1 Examples]# hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
- 分别设置三个目录的存储策略
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/hot -policy HOT
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/warm -policy WARM
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/cold -policy COLD
- 查看三个目录的存储策略
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/hot
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/warm
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/cold
- 测试
分别上传文件
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/hot
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/warm
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/cold
查看不同存储策略文件的block位置
hdfs fsck /data/hdfs-test/data_phase/hot/profile -files -blocks -locations
[root@node1 hadoop]# hdfs fsck /data/hdfs-test/data_phase/hot/profile -files -blocks -locations
Connecting to namenode via http://node1.itcast.cn:9870/fsck?ugi=root&files=1&blocks=1&locations=1&path=%2Fdata%2Fhdfs-test%2Fdata_phase%2Fhot%2Fprofile
FSCK started by root (auth:SIMPLE) from /192.168.88.100 for path /data/hdfs-test/data_phase/hot/profile at Sun Oct 11 22:03:05 CST 2020
/data/hdfs-test/data_phase/hot/profile 3158 bytes, replicated: replication=3, 1 block(s): OK
0. BP-538037512-192.168.88.100-1600884040401:blk_1073742535_1750 len=3158 Live_repl=3 [DatanodeInfoWithStorage[192.168.88.101:9866,DS-96feb29a-5dfd-4692-81ea-9e7f100166fe,DISK], DatanodeInfoWithStorage[192.168.88.100:9866,DS-79739be9-5f9b-4f96-a005-aa5b507899f5,DISK], DatanodeInfoWithStorage[192.168.88.102:9866,DS-e28af2f2-21ae-4aa6-932e-e376dd04ddde,DISK]]
hdfs fsck /data/hdfs-test/data_phase/warm/profile -files -blocks -locations
/data/hdfs-test/data_phase/warm/profile 3158 bytes, replicated: replication=3, 1 block(s): OK
0. BP-538037512-192.168.88.100-1600884040401:blk_1073742536_1751 len=3158 Live_repl=3 [DatanodeInfoWithStorage[192.168.88.102:9866,DS-636f34a0-682c-4d1b-b4ee-b4c34e857957,ARCHIVE], DatanodeInfoWithStorage[192.168.88.101:9866,DS-ff6970f8-43e0-431f-9041-fc440a44fdb0,ARCHIVE], DatanodeInfoWithStorage[192.168.88.100:9866,DS-79739be9-5f9b-4f96-a005-aa5b507899f5,DISK]]
hdfs fsck /data/hdfs-test/data_phase/cold/profile -files -blocks -locations
/data/hdfs-test/data_phase/cold/profile 3158 bytes, replicated: replication=3, 1 block(s): OK
0. BP-538037512-192.168.88.100-1600884040401:blk_1073742537_1752 len=3158 Live_repl=3 [DatanodeInfoWithStorage[192.168.88.102:9866,DS-636f34a0-682c-4d1b-b4ee-b4c34e857957,ARCHIVE], DatanodeInfoWithStorage[192.168.88.101:9866,DS-ff6970f8-43e0-431f-9041-fc440a44fdb0,ARCHIVE], DatanodeInfoWithStorage[192.168.88.100:9866,DS-ca9759a0-f6f0-4b8b-af38-d96f603bca93,ARCHIVE]]
我们可以看到:
-
hot目录中的block,3个block都在DISK磁盘
-
warm目录中的block,1个block在DISK磁盘,另外两个在archive磁盘
-
cold目录中的block,3个block都在archive磁盘
参考:https://blog.csdn.net/androidlushangderen/article/details/51105876
2.7、内存存储
介绍
-
HDFS支持写入由DataNode管理的堆外内存
-
DataNode异步地将内存中数据刷新到磁盘,从而减少代价较高的磁盘IO操作,这种写入称之为懒持久写入
-
HDFS为懒持久化写做了较大的持久性保证。在将副本保存到磁盘之前,如果节点重新启动,有非常小的几率会出现数据丢失。应用程序可以选择使用懒持久化写,以减少写入延迟
该特性从ApacheHadoop 2.6.0开始支持。
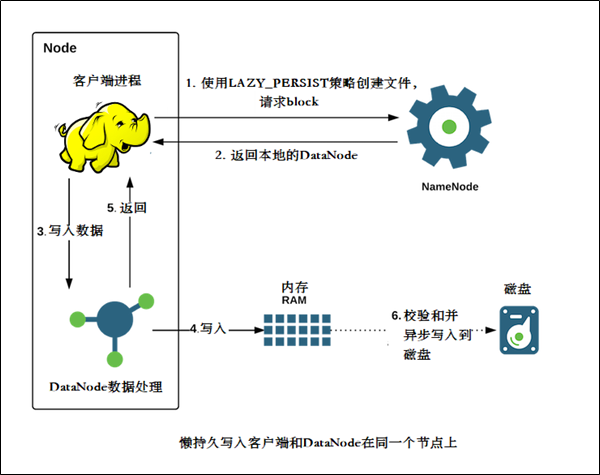
适用场景
-
比较适用于,当应用程序需要往HDFS中以低延迟的方式写入相对较低数据量(从几GB到十几GB(取决于可用内存)的数据量时
-
内存存储适用于在集群内运行,且运行的客户端与HDFS DataNode处于同一节点的应用程序。使用内存存储可以减少网络传输的开销
-
如果内存不足或未配置,使用懒持久化写入的应用程序将继续工作,会继续使用磁盘存储。
配置
1、确定用于存储在内存中的副本内存量
- 在指定DataNode的hdfs-site.xml设置dfs.datanode.max.locked.memory ,这个参数和缓存共用
- DataNode将确保懒持久化的内存不超过dfs.datanode.max.locked.memory
- 例如,为内存中的副本预留32 GB
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>34359738368</value>
</property>
在设置此值时,请记住,还需要内存中的空间来处理其他事情,例如数据节点和应用程序JVM堆以及操作系统页缓存。如果在与数据节点相同的节点上运行YARN节点管理器进程,则还需要YARN容器的内存
2、配置datanode
-
在每个DataNode节点上初始化一个RAM磁盘
-
通过选择RAM磁盘,可以在DataNode进程重新启动时保持更好的数据持久性
下面的设置可以在大多数Linux发行版上运行,目前不支持在其他平台上使用RAM磁盘。
选择tmpfs(VS ramfs)
-
Linux支持使用两种类型的RAM磁盘-tmpfs和ramfs
-
tmpfs的大小受linux内核的限制,而ramfs可以使用所有系统可用的内存
-
tmpfs可以在内存不足情况下交换到磁盘上。但是,许多对性能要求很高的应用运行时都禁用内存磁盘交换
-
HDFS当前支持tmpfs分区,而对ramfs的支持正在开发中
挂载RAM磁盘
- 使用Linux中的mount命令来挂载内存磁盘。例如:挂载32GB的tmpfs分区在/mnt/dn-tmpfs
sudo mount -t tmpfs -o size=32g tmpfs /mnt/dn-tmpfs/
-
建议在/etc/fstab创建一个入口,在DataNode节点重新启动时,将自动重新创建RAM磁盘
-
另一个可选项是使用/dev/shm下面的子目录。这是tmpfs默认在大多数Linux发行版上都可以安装
-
确保挂载的大小大于或等于dfs.datanode.max.locked.memory,或者写入到/etc /fstab
-
不建议使用多个tmpfs对懒持久化写入的每个DataNode节点进行分区
设置RAM_DISK存储类型tmpfs标签
-
标记tmpfs目录中具有RAM_磁盘存储类型的目录
-
在hdfs-site.xml中配置dfs.datanode.data.dir。例如,在具有三个硬盘卷的DataNode上,/grid /0, /grid /1以及 /grid /2和一个tmpfs挂载在 /mnt/dn-tmpfs, dfs.datanode.data.dir必须设置如下:
<property>
<name>dfs.datanode.data.dir</name>
<value>/grid/0,/grid/1,/grid/2,[RAM_DISK]/mnt/dn-tmpfs</value>
</property>
- 这一步至关重要。如果没有RAM_DISK标记,HDFS将把tmpfs卷作为非易失性存储,数据将不会保存到持久存储,重新启动节点时将丢失数据
其他配置
-
确保启用存储策略:确保全局设置中的存储策略是已启用的。默认情况下,此设置是打开的
-
使用内存存储
-
使用懒持久化存储策略
-
指定HDFS使用LAZY_PERSIST策略,可以对文件使用懒持久化写入
可以通过以下三种方式之一进行设置:
-
在目录上设置㽾策略,将使其对目录中的所有新文件生效
-
这个HDFS存储策略命令可以用于设置策略.
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST #命令方式
fs.setStoragePolicy(path, "LAZY_PERSIST"); //编程方式
三、副本放置策略
3.1、介绍
目前在HDFS中现有的副本放置策略类有2大继承子类,分别为BlockPlacementPolicyDefault, BlockPlacementPolicyWithNodeGroup,
最经典的3副本策略用的就是BlockPlacementPolicyDefault策略类.3副本如何存放在这个策略中得到了非常完美的实现.在BlockPlacementPolicyDefault类中的注释具体解释了3个副本的存放位置:
The class is responsible for choosing the desired number of targets for placing block replicas. The replica placement strategy is that if the writer is on a datanode, the 1st replica is placed on the local machine, otherwise a random datanode. The 2nd replica is placed on a datanode that is on a different rack. The 3rd replica is placed on a datanode which is on a different node of the rack as the second replica.
简要概况起来3点:
1st replica. 如果写请求方所在机器是其中一个datanode,则直接存放在本地,否则随机在集群中选择一个datanode.
2nd replica. 第二个副本存放于不同第一个副本的所在的机架.
3rd replica.第三个副本存放于第二个副本所在的机架,但是属于不同的节点
3.2、BlockPlacementPolicyDefault
策略核心方法chooseTargets
在默认放置策略方法类中,核心方法就是chooseTargets,但是在这里有2种同名实现方法,唯一的区别是有无favoredNodes参数.favoredNodes的意思是偏爱,喜爱的节点,只要分为如下三个步骤:
-
初始化操作:计算每个机架所允许最大副本数,创建节点黑名单
-
选择目标节点:将所选节点加入到结果列表中,同时加入到移除列表中,意为已选择过的节点
-
排序目标节点列表,形成pipeline
Pipeline节点的形成:整个过程就是传入目标节点列表参数,经过getPipeline方法的处理,然后返回此pipeline.先来看getPipeline的注释:
Return a pipeline of nodes. The pipeline is formed finding a shortest path that starts from the writer and traverses all nodes This is basically a traveling salesman problem.
关键是这句The pipeline is formed finding a shortest path that
starts from the writer,就是说从writer所在节点开始,总是寻找相对路径最短的目标节点,最终形成pipeline,学习过算法的人应该知道,这其实也是经典的TSP旅行商问题
一句话概况来说,就是选出一个源节点,根据这个节点,遍历当前可选的下一个目标节点,找出一个最短距离的节点,作为下一轮选举的源节点,这样每2个节点之间的距离总是最近的,于是整个pipeline节点间的距离和就保证是足够小的了.那么现在另外一个问题还没有解决,如何定义和计算2个节点直接的距离: 要计算其中的距离,我们首先要了解HDFS中如何定义节点间的距离,其中涉及到了拓扑逻辑结构的概念,结构图如下:
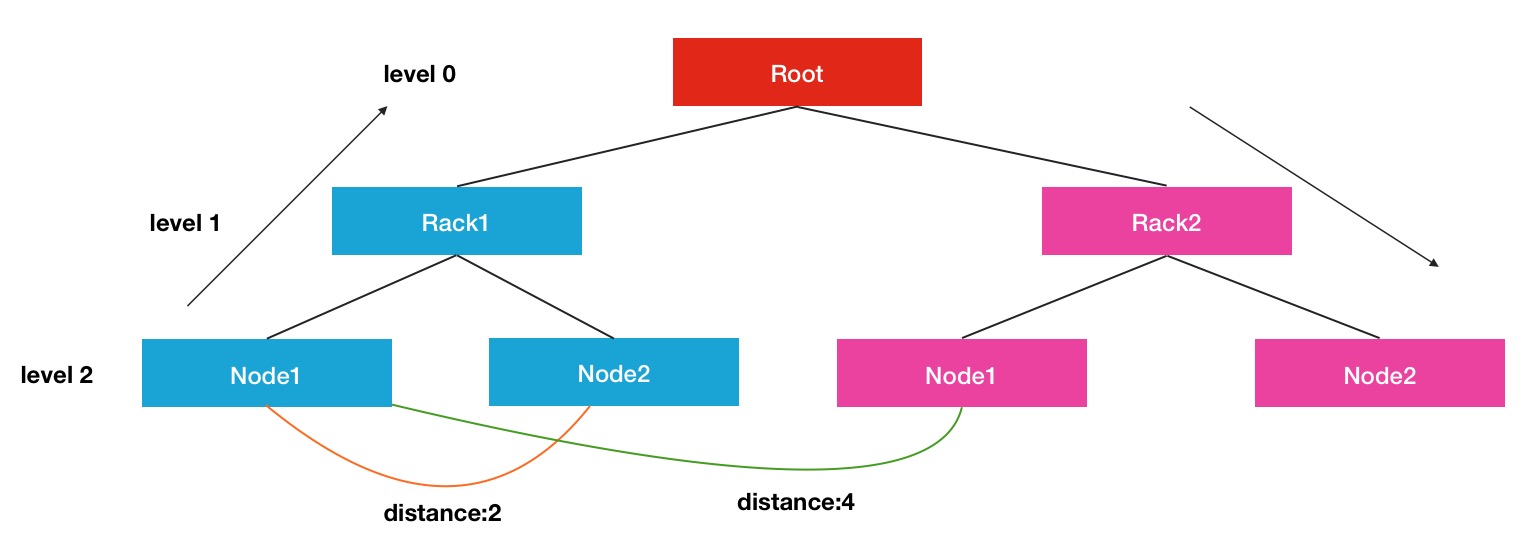
这里显示的是一个三层结构的树形效果图,Root可以看出是一个大的集群,下面划分出了许多个机架,每个机架下面又有很多属于此机架的节点.在每个连接点中,是通过交换机和路由器进行连接的.每个节点间的距离计算方式是通过寻找最近的公共祖先所需要的距离作为最终的结果.比如Node1到Node2的距离是2,就是Node1->Rack1, Rack1->Node2.同理,Rack1的Node1到Rack2的Node1的距离就是4.
chooseTarget方法主逻辑:
final Node localNode = chooseTarget(numOfReplicas, writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storagePolicy, EnumSet.noneOf(StorageType.class), results.isEmpty());
numOfReplicas, 额外需要复制的副本数
excludedNodes,移除节点集合,此集合内的节点不应被考虑作为目标节点
results,当前已经选择好的目标节点集合
storagePolicy,存储类型选择策略
首节点的选择:
-
如果writer请求方本身位于集群中的一个datanode之上,则第一个副本的位置就在本地节点上,很好理解,这样直接就是本地写操作了.
-
如果writer请求方纯粹来源于外界客户端的写请求时,则从已选择好的目标节点result列表中挑选第一个节点作为首个节点.
-
如果result列表中还是没有任何节点,则会从集群中随机挑选1个node作为第一个localNode
经典的3副本存放位置,多余的副本随机存放的原理即可.当然在其间选择的过程中可能会发生异常,因为有的时候我们没有配置机架感知,集群中都属于一个默认机架的default-rack,则会导致chooseRemoteRack的方法出错,因为没有满足条件的其余机架,这时需要一些重试策略.
chooseLocalStorage,chooseLocalRack,chooseRemoteRack和chooseRandom方法,四个选择目标节点位置的方法其实是一个优先级渐渐降低的方法,首先选择本地存储位置.如果没有满足条件的,再选择本地机架的节点,如果还是没有满足条件的,进一步降级选择不同机架的节点,最后随机选择集群中的节点
目标节点存储判断好坏条件:
-
storage的存储类型是要求给定的存储类型
-
storage不能是READ_ONLY只读的
-
storage不能是坏的
-
storage所在机器不应该是已下线或下线中的节点
-
storage所在节点不应该是旧的,一段时间内没有更新心跳的节点
-
节点内保证有足够的剩余空间能满足写Block要求的大小
-
要考虑节点的IO负载繁忙程度
-
要满足同机架内最大副本数的限制
参考:https://blog.csdn.net/androidlushangderen/article/details/51178253
出处:https://www.cnblogs.com/zsql/
如果您觉得阅读本文对您有帮助,请点击一下右下方的推荐按钮,您的推荐将是我写作的最大动力!
版权声明:本文为博主原创或转载文章,欢迎转载,但转载文章之后必须在文章页面明显位置注明出处,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号