
cloudera manager server迁移
一、迁移背景
服务器出了问题,导致整个cm server界面呈现出不可用的状态,也就是获取不到各个大数据组件以及主机相关的状态的信息,整个cm server的前端界面处于瘫痪的状态,不可用,刚开始怀疑是存放元数据的mysql有问题,但是经过验证,一点问题也没有,后面发现登陆服务器很卡顿,但是发现cpu和内存都没怎么使用,查看/var/log/messages日志,发现很多MCE错误,网上都说只有硬件有问题才会出现这样的错误,后来重启机器,看看这样还会不会继续报错,重启电脑也不能解决问题,暂时判定服务器硬件有问题:这样的话影响到了很多的服务,主要有CM server,datanode,nodemanager,JournalNode等,由于CM server和JournalNode很重要,所以考虑迁移到其他的机器。
/var/log/messages报错信息如下:
Jan 31 17:13:13 lgh kernel: sbridge: HANDLING MCE MEMORY ERROR Jan 31 17:13:13 lgh kernel: CPU 36: Machine Check Exception: 0 Bank 10: cc002003000800c1 Jan 31 17:13:13 lgh kernel: TSC 0 ADDR 1200417000 MISC 90000b00374068c PROCESSOR 0:406f1 TIME 1612084393 SOCKET 0 APIC 13 Jan 31 17:13:13 lgh kernel: [Hardware Error]: Machine check events logged Jan 31 17:13:14 lgh kernel: EDAC MC1: CE row 0, channel 0, label "CPU_SrcID#0_Ha#0_Channel#0_DIMM": 128 Unknown error(s): memory scrubbing on FATAL area OVERFLOW:
cpu=36 Err=0008:00c1 (ch=1), addr = 0x1200417000 => socket=0, ha=0, Channel=0(mask=1), rank=0 Jan 31 17:13:14 lgh kernel: Jan 31 19:37:31 lgh kernel: sbridge: HANDLING MCE MEMORY ERROR Jan 31 19:37:31 lgh kernel: CPU 39: Machine Check Exception: 0 Bank 10: cc002003000800c1 Jan 31 19:37:31 lgh kernel: TSC 0 ADDR 1200417000 MISC 90000b00374068c PROCESSOR 0:406f1 TIME 1612093051 SOCKET 0 APIC 19 Jan 31 19:37:31 lgh kernel: [Hardware Error]: Machine check events logged Jan 31 19:37:32 lgh kernel: EDAC MC1: CE row 0, channel 0, label "CPU_SrcID#0_Ha#0_Channel#0_DIMM": 128 Unknown error(s): memory scrubbing on FATAL area OVERFLOW:
cpu=39 Err=0008:00c1 (ch=1), addr = 0x1200417000 => socket=0, ha=0, Channel=0(mask=1), rank=0 Jan 31 19:37:32 lgh kernel:
几经查看,基本确定是内存出现了问题,但是不完全是故障,就是有隐患。
二、迁移步骤
官方网址:https://docs.cloudera.com/documentation/enterprise/latest/topics/cm_ag_restore_server.html
其实查看官方的迁移步骤很简单,但是有些情况不适合我们的集群,官方迁移的方式只适合只安装了自带组件的,如果通过jar包安装了streamsets和spark2等,这些服务就会出现问题,所以需要做一些响应的处理,整个迁移的过程整理如下;
1、选择一台合适的机器安装cloudera manager server服务,这里我们使用的是yum源的方式安装,首先配置好yum源,然后使用如下命令安装:
安装官方网址:https://docs.cloudera.com/documentation/enterprise/latest/topics/install_cm_cdh.html
yum install –y cloudera-manager-daemons cloudera-manager-server
2、将原来的机器(原来的CM server主机)目录/var/lib/cloudera-scm-server/下的所有文件复制到新的主机的相同的目录下,并保持原有的权限
scp –r root@source_ip:/var/lib/cloudera-scm-server/* /var/lib/cloudera-scm-server/
chown –R cloudera-scm: cloudera-scm /var/lib/cloudera-scm-server/
3、这一步是自己调整的,官网没说很清楚,符合自己的集群,因为我们有streamsets和spark2服务,操作如下,在/opt/cloudera下有如下目录:(这些都是在cm server的机器上)

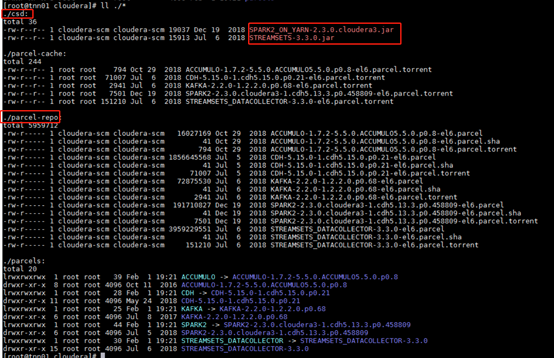
所以要把这两个目录也复制到新cm server机器上的相同目录下:
scp -r root@source_ip:/opt/cloudera/csd /opt/cloudera
scp -r root@source_ip:/opt/cloudera/parcel-repo /opt/cloudera
#然后进行权限修改
chown -R cloudera-scm:cloudera-scm csd parcel-repo
chmod 644 csd/*
4、数据库的配置(可选,如果原来数据库没问题,就跳过这一步,因为数据库没问题,所以这步是没有操作的)
安装完毕后,把原来的是数据库备份还原到新的数据库(这里只说cm相关的元数据库)
5、修改新机器cm server的配置/etc/cloudera-scm-server/db.properties,把里面的数据库的信息进行修改成原来的数据库或者是新安装备份还原过后的数据库。
6、修改原来所有cm agent机器的/etc/cloudera-scm-agent/config.ini配置,只要修改指向为新的cm server机器就好。如果是新建的数据,并且没有石油备份还原的方式,则还需要删除/var/lib/cloudera-scm-agent/cm_guid,修改配置后,重启agent
service cloudera-scm-agent restart
7、关停掉原先的cm server
service cloudera-scm-server stop
8、启动新的cm server
service cloudera-scm-server start
9、重新安装相关服务
到这里为止cm server算是迁移完了,但是当自己登陆cm前端的时候,发现cm相关的所有服务还是不可用,因为这些服务还是安装在原来有问题的机器上,比如Activity Monitor、Alert Publisher、Event Server、Host Monitor、Reports Manager、Service Monitor。所以整个cm前端页面还是瘫痪不可用的状态。其实仔细想想,这些个服务其实就是用来做监控,收集信息的一些服务,所以最终选择的方案就是:
把这些服务从有问题的机器上进行删除操作,然后再在新的机器上重新安装这些所有的服务,然后启动起来,就ok了。
出处:https://www.cnblogs.com/zsql/
如果您觉得阅读本文对您有帮助,请点击一下右下方的推荐按钮,您的推荐将是我写作的最大动力!
版权声明:本文为博主原创或转载文章,欢迎转载,但转载文章之后必须在文章页面明显位置注明出处,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号