
mysql备份和恢复
对于DBA来说,数据的备份和恢复是一项很基本的操作。在意外的情况下(服务器宕机,磁盘损坏,RAID卡损坏等),要保证数据不丢失,或者是最小程度的丢失,是每个DBA每时每刻应该关心数据库的备份了。本来说明下备份的工具,原理以及使用。
一、备份与恢复的概述
按照是否能够继续提供服务,将数据库备份类型划分为:
热备份:(在线备份)在数据库运行的过程中进行备份,并且不影响数据库的任何操作
温备份:能读不能写,在数据运行的过程中进行备份,但是对数据有影响,如需要加全局锁保证数据的一致性。
冷备份:(离线备份)在停止数据库的情况下,复制备份数据库的物理文件。
按照备份后文件的内容分类:
逻辑备份:备份文件时可读的文本文件,比如sql语句,适合数据库的迁移和升级,但是恢复时间比较长。
裸文件备份:复制数据库的物理文件
按照备份数据库的内容分类:
完全备份:对数据库进行一个完整的备份
增量备份:在完全备份的基础上,对数据库的增量进行备份
日志备份:只要是对binlog的备份
二、冷备
只需要备份mysql数据库的frm文件,共享表空间文件,独立表空间文件(*.ibd),重做日志文件,以及msyql的配置文件my.cnf。
优点:
备份简单,只需要复制文件就可以
恢复简单,只需要把文件恢复到指定位置
恢复速度快,
缺点:
备份文件较大,因为表空间存在大量的其他数据,比如undo段,插入缓冲等
不能总是轻易跨平台
三、逻辑备份
3.1、mysqldump
语法:
mysqldump [OPTIONS] database [tables] mysqldump [OPTIONS] --databases [OPTIONS] DB1 [DB2 DB3...] mysqldump [OPTIONS] --all-databases [OPTIONS]
选项:
-u, --user=name #指定用户名 -S, --socket=name #指定套接字路径 -p, --password[=name] #指定密码 -P, --port=3306 #指定端口 -h, --host=name #指定主机名 -r, --result-file=name #将导出结果保存到指定的文件中,在Linux中等同于覆盖重定向。 --all-databases, -A #指定dump所有数据库。等价于使用--databases选定所有库 --databases, -B #指定需要dump的库。该选项后的所有内容都被当成数据库名;在输出文件中的每个数据库前会加上建库语句和use语句 --ignore-table=db_name.tbl_name #导出时忽略指定数据库中的指定表,同样可用于忽略视图,要忽略多个则多次写该选项 -d, --no-data #不导出表数据,可以用在仅导出表结构的情况。 --events, -E #导出事件调度器 --routines, -R #导出存储过程和函数。但不会导出它们的属性值,若要导出它们的属性,可以导出mysql.proc表然后reload --triggers #导出触发器,默认已开启 --tables #覆盖--databases选项,导出指定的表。但这样只能导出一个库中的表。格式为--tables database_name tab_list --where='where_condition', -w 'where_condition' #指定筛选条件并导出表中符合筛选的数据,如--where="user='jim'" --add-drop-database #在输出中的create database语句前加上drop database语句先删除数据库 --add-drop-table #在输出的create table语句前加上drop table语句先删除表,默认是已开启的 --add-drop-trigger #在输出中的create trigger语句前加上drop trigger语句先删除触发器 -n, --no-create-db #指定了--databases或者--all-databases选项时默认会加上数据库创建语句,该选项抑制建库语句的输出 -t, --no-create-info #不在输出中包含建表语句 --replace #使用replace代替insert语句 --default-character-set=charset_name #在导出数据的过程中,指定导出的字符集。很重要,客户端服务端字符集不同导出时可能乱码,默认使用utf8 --set-charset #在导出结果中加上set names charset_name语句。默认启用。 --compact #简化输出导出的内容,几乎所有注释都不会输出 --complete-insert, -c #在insert语句中加上插入的列信息 --create-options #在导出的建表语句中,加上所有的建表选项 --tab=dir_name, -T dir_name #将每个表的结构定义和数据分别导出到指定目录下文件名同表名的.sql和txt文件中,其中.txt #文件中的字段分隔符是制表符。要求mysqldump必须和MySQL Server在同一主机,且mysql用 #户对指定的目录有写权限,并且连接数据库的用户必须有file权限。且指定要dump的表,不能和 #--databases或--all-databases一起使用。它的实质是执行select into outfile。 --fields-terminated-by=name #指定输出文件中的字段分隔符 --fields-enclosed-by=name #指定输出文件中的字段值的包围符,如使用引号将字符串包围起来引用 --fields-optionally-enclosed-by=name #指定输出文件中可选字段引用符 --fields-escaped-by=name #指定输出文件中的转义符 --lines-terminated-by=name #指定输出文件中的换行符 -Q, --quote-names #引用表名和列名时使用的标识符,默认使用反引号"`" --delayed-insert #对于非事务表,在insert时支持delayed功能,但在MySQL5.6.6开始该选项已经废弃 --disable-keys, -K #在insert语句前后加上禁用和启用索引语句,大量数据插入时该选项很适合。默认开启 --insert-ignore #使用insert ignore语句替代insert语句 --quick, -q #快速导出数据,该选项对于导出大表非常好用。默认导出数据时会一次性检索表中所有数据并加入 #到内存中,而该选项是每次检索一行并导出一行 --add-locks #在insert语句前后加上lock tables和unlock tables语句,默认已开启。 --flush-logs, -F #在开始dump前先flush logs,如果同时使用了--all-databases则依次在每个数据库dump前flush, #如果同时使用了--lock-all-tables,--master-data或者--single-transaction,则仅flush #一次,等价于使用flush tables with read lock锁定所有表,这样可以让dump和flush在完全精 #确的同一时刻执行。 --flush-privileges #在dump完所有数据库后在数据文件的结尾加上flush privileges语句,在导出的数据涉及mysql库或 #者依赖于mysql库时都应该使用该选项 --lock-all-tables, -x #为所有表加上一个持续到dump结束的全局读锁。该选项在dump阶段仅加一次锁,一锁锁永久且锁所有。 #该选项自动禁用--lock-tables和--single-transaction选项 --lock-tables, -l #在dump每个数据库前依次对该数据库中所有表加read local锁(多次加锁,lock tables...read local), #这样就允许对myisam表进行并发插入。对于innodb存储引擎,使用--single-transaction比 --lock-tables #更好,因为它不完全锁定表。因为该选项是分别对数据库加锁的,所以只能保证每个数 #据库的一致性而不能保证所有数据库之间的一致性。该选项主要用于myisam表,如果既有myisam又有 #innodb,则只能使用--lock-tables,或者分开dump更好 --single-transaction #该选项在dump前将设置事务隔离级别为repeatable read并发送一个start transaction语句给 #服务端。该选项对于导出事务表如innodb表很有用,因为它在发出start transaction后能保证导 #出的数据库的一致性时而不阻塞任何的程序。该选项只能保证innodb表的一致性,无法保证myisam表 #的一致性。在使用该选项的时候,一定要保证没有任何其他连接在使用ALTER TABLE,CREATE TABLE, #DROP TABLE,RENAME TABLE,TRUNCATE TABLE语句,因为一致性读无法隔离这些语句。 #--single-transaction 选项和--lock-tables选项互斥,因为lock tables会隐式提交事务。 #要导出大的innodb表,该选项结合--quick选项更好 --no-autocommit #在insert语句前后加上SET autocommit = 0,并在需要提交的地方加上COMMIT语句 --order-by-primary #如果表中存在主键或者唯一索引,则排序后按序导出。对于myisam表迁移到innobd表时比较有用,但是 #这样会让事务变得很长很慢
简单使用(由于比较简单,不具体阐述):
mysqldump -uroot -p123456 -A -r all.sql #备份所有数据库 mysqldump -uroot -p123456 -A > all.sql #备份所有数据库 mysqldump -uroot -p123456 -B test test1 > db_test.sql #备份test和test1数据库 mysqldump -uroot -p123456 --single-transaction -A > all.sql #innodb开始事务备份所有数据 mysqldump -uroot -p123456 --default-character-set=latin1 -A > all.sql #指定字符集备份所有数据 mysqldump -uroot -p123456 --tables test gxt1 -r gxt.sql #备份test库的gxt1表
mysqldump工具使用建议:
1.从性能考虑:在需要导出大量数据的时候,使用--quick选项可以加速导出,但导入速度不变。如果是innodb表,则可以同时加上--no-autocommit选项,这样大量数据量导入时将极大提升性能。
2.一致性考虑:对于innodb表,几乎没有理由不用--single-transaction选项。对于myisam表,使用--lock-all-tables选项要好于--lock-tables。既有innodb又有myisam表时,可以分开导出,又能保证一致性,还能保证效率。
3.方便管理和维护性考虑:在导出时flush log很有必要。加上--flush-logs选项即可。而且一般要配合--lock-all-tables选项或者--single-transaction选项一起使用,因为同时使用时,只需刷新一次日志即可,并且也能保证一致性。同时,还可以配合--master-data=2,这样就可以方便地知道二进制日志中备份结束点的位置。
4.字符集考虑:如果有表涉及到了中文数据,在dump时,一定要将dump的字符集设置的和该表的字符集一样。
5.杂项考虑:备份过程中会产生二进制日志,但是这是没有必要的。所以在备份前可以关掉,备份完后开启。set sql_log_bin=0关闭,set sql_log_bin=1开启。
msyqldump结合binlog日志实现增量备份
1、首先全备:mysqldump -uroot -p123456 -q --no-autocommit --flush-logs --single-transaction --master-data=2 --tables test gxt1 > gxt.sql
2、修改表中的数据:insert into test.gxt1 values(1,'王麻子');
3、备份二进制日志:mysqlbinlog mysql-bin.000002 >new_gxt.sql #这里需要指定时间或者指定position对增量进行备份
4、模拟删掉:drop table test.gxt1;
5、恢复:
mysql>use test;
mysql>source gxt.sql;
mysql>source new_gxt.sql;
总结
msyqldump是属于逻辑备份,备份sql语句,简单,但是由于恢复时都是通过insert进行插入,所有恢复速度慢,mysqldump备份myisam表时因为要加--lock-all-tables,这时要备份的数据库全部被上锁,可读不可写,所以实现的是温备。mysqldump备份innodb表时因为要加--single-transaction,会自动将隔离级别设置为repeatable read并开启一个事务,这时mysqldump将获取dump执行前一刻的行版本,并处于一个长事务中直到dump结束。所以不影响目标数据库的使用,可读也可写,即实现的是热备
3.2、select ... into outfile
load data infile和select into outfile语句是配套的。可以通过参数secure_file_priv对其进行控制是否可以使用:

常用自定义格式说明:
fields terminated by 'string'指定字段分隔符; enclosed by 'char'指定所有字段都使用char符号包围,如果指定了optionally则只用在字符串和日期数据类型等字段上,默认未指定; escaped by 'char'指定转义符。 lines starting by 'string'指定行开始符,如每行开始记录前空一个制表符; lines terminated by 'string'为行分隔符。 默认: fileds terminated by '\t' enclosed by '' escaped by '\\' lines terminated by '\n' starting by ''
简单使用例子:
select * from test into outfile '/data/t_data.sql'; select * into outfile '/data/t_data.sql' from test; select id,name from test into outfile '/data/t_data.sql'; select * from t into outfile '/data/t_data1.sql' fields terminated by ',' enclosed by '\'' lines starting by '\t' terminated by '\n';
3.3、逻辑备份的恢复
语法很简单:
mysql -uroot -p123456 < all_bak.sql
mysql>source /root/all_bak.sql #登录mysql
3.4、load data infile
选项同select into outfile是一样的,增加了gnore N lines|rows表示忽略前N行数据不导入,set col_name=expr表示对列进行一些表达式运算
基本使用:
load data infile '/home/data1.sql' into table test.gxt fields terminated by ',' (id,name)set is_enable=1; #指定字段 load data infile '/home/data1.sql' into table test.gxt fields terminated by ',' enclosed by '\'' escaped by '\\' lines starting by '\t' terminated by '\n'; load data infile '/home/data1.sql' into table test.gxt fields terminated by ',' enclosed by '\'' escaped by '\\' lines starting by '\t' terminated by '\n' ignore 2 rows; #忽略前两行 load data infile '/home/data1.sql' into table test.gxt fields terminated by ',' enclosed by '\'' escaped by '\\' lines starting by '\t' terminated by '\n' set id=id+5; #设置列,下同 load data infile '/home/data1.sql' into table test.gxt fields terminated by ',' enclosed by '\'' escaped by '\\' lines starting by '\t' terminated by '\n' set name=concat(name,'@qq.com'); load data infile '/home/data1.sql' into table test.gxt fields terminated by ',' enclosed by '\'' escaped by '\\' lines starting by '\t' terminated by '\n' set name=concat(name,'@qq.com'), id=id+5;
3.5、mysqldump导出
本质和select into outfile一样
mysql -uroot -p123456 -e "select * from test.gxt" > a.txt #虽然这样也可以导出数据,但是是没有格式的
mysqldump -uroot -p123456 --tab /data/test test gxt1 #这里指定的目录mysql用户需要有写权限,还需要设定参数secure-file-priv=/data/test

如上的导出方式,既有表结构的定义,又有表数据的导出。
mysqldump的"--tab"选项同样可以指定各种分隔符。如"--fields-terminated-by=...,--fields-enclosed-by=...,--fields-optionally-enclosed-by=...,--fields-escaped-by=..."。以下是指定字段分隔符为","
3.6、mysqlimport导入
mysqlimport本质上就是load data infile的命令接口,而且大多数的语法与之相似,不同的是mysqlimport可以同时导入多张表,通过参数--user-thread并发导入不同的文件
简单使用例子:
mysqlimport -uroot -p123456 --fields-terminated-by=',' test '/home/t.txt'
mysqlimport -uroot -p123456 --fields-terminated-by=',' --user-thread test '/home/t.txt' 'home/gxt1.txt' #并发导入两个表
四、热备
4.1、xtrabackup安装
官网地址:https://www.percona.com/downloads/Percona-XtraBackup-LATEST/
1、配置yum源:yum installhttps://repo.percona.com/yum/percona-release-latest.noarch.rpm (推荐)
2、安装:yum install percona-xtrabackup-24
本来装了个最新版yum install percona-xtrabackup-80,但是。。。有点尴尬(版本8.0不支持mysql5.x),新版本已经没有innobackupex这个工具了
安装完成之后会生成如下工具:
[root@lgh3 ~]# rpm -ql percona-xtrabackup-24 | grep bin |xargs ls -l
lrwxrwxrwx 1 root root 10 Sep 10 05:33 /usr/bin/innobackupex -> xtrabackup
-rwxr-xr-x 1 root root 3846952 Jul 5 03:59 /usr/bin/xbcloud
-rwxr-xr-x 1 root root 3020 Jul 5 03:53 /usr/bin/xbcloud_osenv
-rwxr-xr-x 1 root root 3603744 Jul 5 03:59 /usr/bin/xbcrypt
-rwxr-xr-x 1 root root 3612192 Jul 5 03:59 /usr/bin/xbstream
-rwxr-xr-x 1 root root 21730616 Jul 5 03:59 /usr/bin/xtrabackup
xbcloud和xbcloud_osenv是xtrabackup新的高级特性:云备份;
xbcrypt也是新的特性,加密备份集;
xbstream是xtrabackup的流数据功能,通过流数据功能,可将备份内容打包并传给管道后的压缩工具进行压缩;
xtrabackup是主程序
innobackupex在以前是一个perl脚本,会调用xtrabackup这个二进制工具,从xtrabackup 2.3开始,该工具使用C语言进行了重写,当前它是xtabackup二进制工具的一个软连接,但是实际的使用方法却不同,并且在以后的版本中会删除该工具
4.2、xtrabackup备份原理
实现过程分为三个阶段:分别为备份过程(backup阶段)、准备过程(prepare阶段)、恢复过程(copy back阶段)
4.2.1、备份过程(backup阶段)
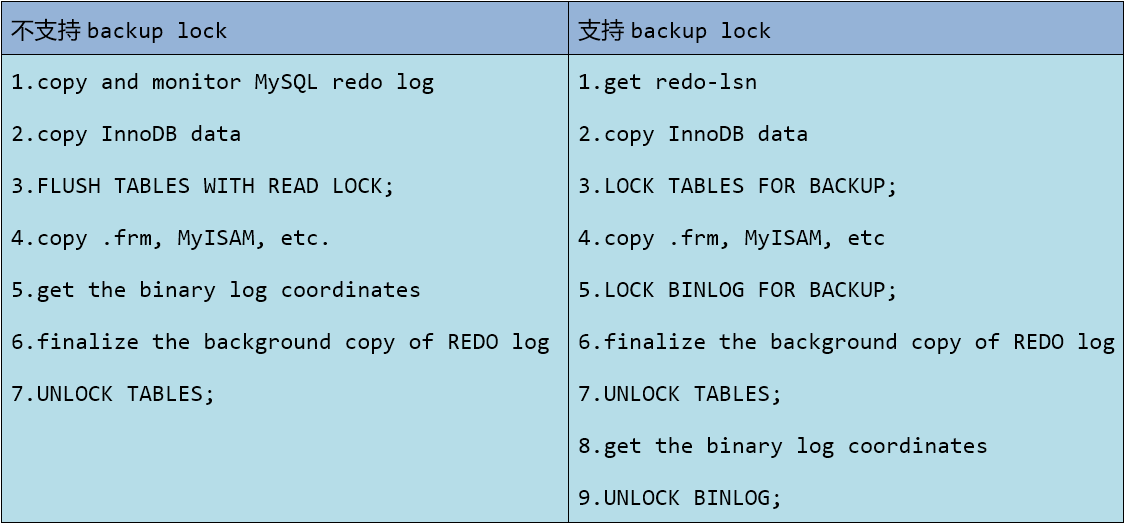
在备份的过程中会分为两种情况,主要是根据percona Server工具是否支持backup lock(备份锁)
backup lock(备份锁):在全局范围内只对非innodb表加锁,所以持有该锁后无法修改非innodb表,但却不影响innodb表的DML。当然,因为是全局锁,所以也会阻塞DDL操作。
二进制日志锁:在全局范围内锁定二进制日志,所以会阻塞其他会话修改二进制日志。这样可以保证能够获取到二进制日志中一致性的位置坐标
第一种情况(支持):
1、启动xtrabackup时,会记录LSN并拷贝redo log到xtrabackup_logfile文件中。
2、拷贝innodb表的数据文件(表空间文件*.ibd或者是ibdata1)此时补考呗frm文件
3、拷贝非innodb文件,拷贝之前需要对非innodb表进行加锁防止拷贝时有语句修改这些类型的表数据。xtrabackup通过lock tables for backup获取轻量级的backup locks来替代flush tables with read lock,因为它只锁定非innodb表,所以由此实现了innodb表的真正热备。
4、拷贝非innodb表的数据和.frm文件,拷贝其他存储引擎类型的文件。
5、当拷贝阶段完成后,最后获取二进制日志中一致性位置的坐标点、结束redo log的监控和拷贝、释放锁等。收尾阶段的过程是这样的:先通过lock binlog for bakcup来获取二进制 日志锁,然后结束redo log的监控和拷贝,再unlock tables释放表锁,随后获取二进制日志的一致性位置坐标点,最后unlock binlog释放二进制日志锁
6、如果一切都OK,xtrabackup将以状态码0退出。
第二种情况(不支持):
1、启动xtrabackup时,会记录LSN并拷贝redo log到xtrabackup_logfile文件中。
2、拷贝innodb表的数据文件(表空间文件*.ibd或者是ibdata1)此时补考呗frm文件
3、拷贝非innodb文件,拷贝之前需要对非innodb表进行加锁防止拷贝时有语句修改这些类型的表数据。只能通过flush tables with read lock来获取全局读锁,但这样也同样会锁住 innodb表,杀伤力太大。
4、拷贝非innodb表的数据和.frm文件,拷贝其他存储引擎类型的文件。
5、当拷贝阶段完成后,最后获取二进制日志中一致性位置的坐标点、结束redo log的监控和拷贝、释放锁等。收尾阶段的过程是这样的:获取二进制日志的一致性坐标点、结束 redo log的监控和拷贝、释放锁。
6、如果一切都OK,xtrabackup将以状态码0退出。
可以从图看对比更加详细,见下图:

4.2.2、准备过程(prepare阶段)
这个阶段的实质就是对备份的innodb数据应用redo log,该回滚的回滚,该前滚的前滚,最终保证xtrabackup_logfile中记录的redo log已经全部应用到备份数据页上,并且实现了一致性。当应用结束后,会重写"xtrabackup_logfile"再次保证该redo log和备份的数据是对应的。
4.2.3、恢复过程(copy back阶段)
xtrabackup的恢复过程实质是将备份的数据文件和结构定义等文件拷贝回MySQL的datadir。同样可以拷贝到任意机器上。要求恢复之前MySQL必须是停止运行状态,且datadir是空目录
4.3、innobackupex工具
4.3.1、全备和恢复
条件:账号和密码,以及给定备份目录(默认xtrabackup连接数据库的时候从配置文件中去读取和备份相关的配置,可以使用选项--defaluts-file指定连接时的参数配置文件,但如果指定该选项,该选项只能放在第一个选项位置。)
[root@lgh3 ~]# mkdir /backup #新建备份目录 [root@lgh3 ~]# chown -R mysql:mysql /backup #修改目录拥有者 [root@lgh3 ~]# innobackupex --user=root --password=123456 /backup/ #备份
然后我们查看目录/backup/

备份目录下是一个以时间戳命名的目录,然后接着继续往下面看:
[root@lgh3 ~]# ll /backup/2019-09-10_21-39-30/ total 12340 -rw-r----- 1 root root 490 Sep 10 21:39 backup-my.cnf -rw-r----- 1 root root 365 Sep 10 21:39 ib_buffer_pool -rw-r----- 1 root root 12582912 Sep 10 21:39 ibdata1 drwxr-x--- 2 root root 4096 Sep 10 21:39 mysql drwxr-x--- 2 root root 8192 Sep 10 21:39 performance_schema drwxr-x--- 2 root root 8192 Sep 10 21:39 sys drwxr-x--- 2 root root 52 Sep 10 21:39 test drwxr-x--- 2 root root 52 Sep 10 21:39 test1 -rw-r----- 1 root root 21 Sep 10 21:39 xtrabackup_binlog_info -rw-r----- 1 root root 135 Sep 10 21:39 xtrabackup_checkpoints -rw-r----- 1 root root 466 Sep 10 21:39 xtrabackup_info -rw-r----- 1 root root 2560 Sep 10 21:39 xtrabackup_logfile
其中:
mysql、performance_schemasys、test、test1为数据库的备份
ibdata1为共享表空间
backup-my.cnf是拷贝过来的配置文件,但是里面只包含[mysqld]配置片段和备份有关的选项
[root@lgh3 2019-09-10_21-39-30]# cat backup-my.cnf # This MySQL options file was generated by innobackupex. # The MySQL server [mysqld] innodb_checksum_algorithm=crc32 innodb_log_checksum_algorithm=strict_crc32 innodb_data_file_path=ibdata1:12M:autoextend innodb_log_files_in_group=2 innodb_log_file_size=50331648 innodb_fast_checksum=false innodb_page_size=16384 innodb_log_block_size=512 innodb_undo_directory=./ innodb_undo_tablespaces=0 server_id=1000 redo_log_version=1 server_uuid=74b64a5b-cfba-11e9-95d0-000c2994d425 master_key_id=0
xtrabackup_binlog_info中记录的是当前使用的二进制日志文件
[root@lgh3 2019-09-10_21-39-30]# cat xtrabackup_binlog_info
mysql-bin.000008 154
xtrabackup_checkpoints中记录了备份的类型是全备还是增备,还有备份的起始、终止LSN号
[root@lgh3 2019-09-10_21-39-30]# cat xtrabackup_checkpoints backup_type = full-backuped from_lsn = 0 to_lsn = 2613099 last_lsn = 2613108 compact = 0 recover_binlog_info = 0 flushed_lsn = 2613108
xtrabackup_info中记录的是备份过程中的一些信息。
xtrabackup_logfile是复制和监控后写的redo日志。该日志是备份后下一个操作"准备"的关键。只有通过它才能实现数据一致性
根据上节所说的xtrabackup的原理,我们知道在全备完之后,还有一个准备过程,这个过程主要是为了保证数据的一致性。因为坑你存在innodb数据,则还不能用来恢复。因为从xtrabackup开始备份的时候就监控着MySQL的redo log,在拷贝的innodb数据文件中很可能还有未提交的事务,并且拷贝完innodb数据之后还可能提交了事务或者开启了新的事务等等。总之,全备之后的状态不一定是一致的。
接下来进行准备阶段的操作:准备阶段使用的模式选项是"--apply-log"。准备阶段不会连接MySQL,所以不用指定连接选项如--user等。还有一个参数"--use-memory",该选项默认值为100M,值越大准备的过程越快。
[root@lgh3 2019-09-10_21-39-30]# pwd /backup/2019-09-10_21-39-30 [root@lgh3 2019-09-10_21-39-30]# innobackupex --apply-log `pwd` #等于 innobackupex --apply-log /backup/2019-09-10_21-39-30

当出现如上状态,则表示准备阶段已经完成,则我们可以继续进行下一步操作了,即恢复操作。恢复过程要求停止服务器,并且datadir目录为空。所以接下来我们先准备这两个条件:
-rw-r--r-- 1 root root 1975750 Jul 31 22:21 redis-5.0.5.tar.gz [root@lgh3 ~]# cat /etc/my.cnf | grep datadir #查找datadir目录 datadir=/data/mysql [root@lgh3 ~]# service mysqld stop #停止msyql服务 Shutting down MySQL.. SUCCESS! [root@lgh3 ~]# mv /data/mysql/ /data/mysql_bak #备份文件 [root@lgh3 ~]# mkdir /data/mysql [root@lgh3 ~]# chown -R mysql:mysql /data/mysql #新建
满足如上的条件之后我们进行恢复操作:恢复时使用的模式是"--copy-back",选项后指定要恢复的源备份目录
[root@lgh3 ~]# innobackupex --copy-back /backup/2019-09-10_21-39-30/
然后结尾提示:表示成功
接下来我们查看datadir目录:
[root@lgh3 ~]# ll /data/mysql total 122932 -rw-r----- 1 root root 365 Sep 10 22:04 ib_buffer_pool -rw-r----- 1 root root 12582912 Sep 10 22:04 ibdata1 -rw-r----- 1 root root 50331648 Sep 10 22:04 ib_logfile0 -rw-r----- 1 root root 50331648 Sep 10 22:04 ib_logfile1 -rw-r----- 1 root root 12582912 Sep 10 22:04 ibtmp1 -rw-r----- 1 mysql mysql 4996 Sep 10 22:06 lgh3.err drwxr-x--- 2 root root 4096 Sep 10 22:04 mysql drwxr-x--- 2 root root 8192 Sep 10 22:04 performance_schema drwxr-x--- 2 root root 8192 Sep 10 22:04 sys drwxr-x--- 2 root root 52 Sep 10 22:04 test drwxr-x--- 2 root root 52 Sep 10 22:04 test1 -rw-r----- 1 root root 22 Sep 10 22:04 xtrabackup_binlog_pos_innodb -rw-r----- 1 root root 466 Sep 10 22:04 xtrabackup_info -rw-r----- 1 root root 1 Sep 10 22:04 xtrabackup_master_key_id
发现该目录的拥有者不是mysql用户,然后我们修改之:chown -R mysql:mysql /data/mysql,然后启动服务器
从上看出来,全备和恢复就成功了
4.3.2、增备和恢复
增量备份就是在全量备份的基础上进行增加新增数据的备份。xtrabackup实现增量备份的原理是对全备份的终点LSN和当前的LSN进行比较,增备时将从终点LSN开始一直备份到当前的LSN。在备份时也有redo log的监控线程,对于增备过程中导致LSN增长的操作也会写入到日志中。增备的实现依赖于LSN,所以只对innodb有效,对myisam表使用增备时,背后进行的是全备。
1、进行全备,这里重新备份一次:innobackupex --user=root --password=123456 /backup/
2、为了实现增量, 我们干掉test库:mysql -uroot -p123456 -e 'drop database test',然后新增库,新增表等操作
3、查看xtrabackup_checkpoints可以得知相关的LSN
[root@lgh3 2019-09-10_22-24-39]# cat xtrabackup_checkpoints
backup_type = full-backuped
from_lsn = 0
to_lsn = 2613682
last_lsn = 2613691
compact = 0
recover_binlog_info = 0
flushed_lsn = 2613691
4、进行增备:使用"--incremental"选项表示增量备份,增量备份时需要通过"--incremental-basedir=fullback_PATH"指定基于哪个备份集备份,因为是第一次增备,所以要基于完全备份增量集。xtrabackup提供的选项"--incremental-lsn=N"可以显式指定增备的起始LSN,默认会自动获取。显式指定LSN时,可以无需提供增备的basedir。
innobackupex --user=root --password=123456 --incremental /backup/ --incremental-basedir=/backup/2019-09-10_22-24-39/
备份完成后,我们查看/backup/目录,看得出来新增了一个目录,然后我们进去看一下
[root@lgh3 backup]# ll total 0 drwxr-x--- 7 root root 248 Sep 10 22:24 2019-09-10_22-24-39 drwxr-x--- 9 root root 301 Sep 10 22:34 2019-09-10_22-33-59 [root@lgh3 backup]# cd 2019-09-10_22-33-59 [root@lgh3 2019-09-10_22-33-59]# ll total 1160 -rw-r----- 1 root root 490 Sep 10 22:34 backup-my.cnf -rw-r----- 1 root root 365 Sep 10 22:34 ib_buffer_pool -rw-r----- 1 root root 1130496 Sep 10 22:34 ibdata1.delta -rw-r----- 1 root root 44 Sep 10 22:33 ibdata1.meta drwxr-x--- 2 root root 4096 Sep 10 22:34 mysql drwxr-x--- 2 root root 8192 Sep 10 22:34 performance_schema drwxr-x--- 2 root root 8192 Sep 10 22:34 sys drwxr-x--- 2 root root 79 Sep 10 22:34 test1 drwxr-x--- 2 root root 76 Sep 10 22:34 test2 drwxr-x--- 2 root root 76 Sep 10 22:34 test3 drwxr-x--- 2 root root 76 Sep 10 22:34 test4 -rw-r----- 1 root root 21 Sep 10 22:34 xtrabackup_binlog_info -rw-r----- 1 root root 139 Sep 10 22:34 xtrabackup_checkpoints -rw-r----- 1 root root 537 Sep 10 22:34 xtrabackup_info -rw-r----- 1 root root 2560 Sep 10 22:34 xtrabackup_logfile [root@lgh3 2019-09-10_22-33-59]# cat xtrabackup_checkpoints backup_type = incremental from_lsn = 2613682 to_lsn = 2640367 last_lsn = 2640376 compact = 0 recover_binlog_info = 0 flushed_lsn = 2640376
从上看出来,我们实现了增量的备份。接下来就是准备阶段了
增备的准备过程和全备的准备过程有点不一样,不到最后恢复的时候不能进行任何"准备"过程。为了保证将所有的备份集进行整合,需要使用在每个备份集的"准备"过程中使用"--redo-only"选项,这样应用日志时会"直线向前"直到最后一个备份集。它的本质是向全备集中不断的追加应用增备中的日志。但是,最后一个增备集需要作为备份集整合的终点,所以它不能使用"--redo-only"选项。整合完成之后,原来的全备就已经完整了,这时再对追加完成的全备集进行一次"准备"即可用于后面的恢复。
假设我们在全备(假设为bak_all)的基础上,进行了增备bak1,bak2(bak文件都代表备份的以时间戳命名的目录)两次,那么我们的准备过程就如下:
# 对整合的开始备份集——全备集应用日志,并指定"--redo-only"表示开始进入日志追加 innobackupex --apply-log --redo-only /backup/2019-09-10_22-24-39 #这里2019-09-10_22-24-39代表bak_all # 对第一个增备集进行"准备",将其追加到全备集中 innobackupex --apply-log --redo-only /backup/bak_all --incremental-dir=/backup/bak1 # 对第二个增备集进行"准备",将其追加到全备集中,但是不再应用"--redo-only",表示整合的结束点 innobackupex --apply-log /backup/bak_all --incremental-dir=/backup/bak2 # 对整合完成的全备集进行一次整体的"准备" innobackupex --apply-log /backup/bak_all
接下来进行恢复过程。步骤同全备恢复一样,清空datadir目录,stop服务
rm -rf /data/mysql
service mysqld stop
innobackupex --copy-back /backup/2019-09-10_23-07-28/
到这里就完成了增备的恢复,这里实验了好几次,所以好几个文件夹的名字可能是不一样的。
4.3.3、表的导入和导出
导出表是在"准备"的过程中进行的,不是在备份的时候导出。对于一个已经备份好的备份集,使用"--apply-log"和"--export"选项即可导出备份集中的表
innobackupex --apply-log --export /backup/2019-09-10_23-07-28/
[root@lgh3 test2]# pwd /backup/2019-09-10_23-07-28/test2 [root@lgh3 test2]# ll total 132 -rw-r----- 1 root root 67 Sep 10 23:11 db.opt -rw-r--r-- 1 root root 423 Sep 10 23:23 gxt.cfg -rw-r----- 1 root root 16384 Sep 10 23:23 gxt.exp -rw-r----- 1 root root 8586 Sep 10 23:11 gxt.frm -rw-r----- 1 root root 98304 Sep 10 23:11 gxt.ibd
如上多了一个exp结尾的文件。其中.cfg文件是一种特殊的innodb数据字典文件,它和exp文件的作用是差不多的,只不过后者还支持在xtradb中导入
导入则是要在mysql服务器上导入来自于其它服务器的某innodb表,需要先在当前服务器上创建一个跟原表表结构一致的表,而后才能实现将表导入,将来自于"导出"表的的.ibd和.exp文件复制到当前服务器的数据目录或者是也可以复制.cfg文件。复制过去后要修改拥有者权限:chown -R mysql:mysql /data/mysql
mysql> ALTER TABLE test2.gxt DISCARD TABLESPACE; #干掉表空间
mysql> ALTER TABLE test2.gxt IMPORT TABLESPACE;
这样即完成了单个表的导出和导入
4.3.4、部分备份和恢复
部分备份只有一点需要注意:在恢复的时候不要通过"--copy-back"的方式拷贝回datadir,而是应该使用导入表的方式。尽管使用拷贝的方式有时候是可行的,但是很多情况下会出现数据库不一致的状态。
创建部分备份有三种方式:
1、通过"--include"选项可以指定正则来匹配要备份的表,这种方式要使用完整对象引用格式,即db_name.tab_name的方式。
2、将要备份的表分行枚举到一个文件中,通过"--tables-file"指定该文件。
3、或者使用"--databases"指定要备份的数据库或表,指定备份的表时要使用完整对象引用格式,多个元素使用空格分开。
使用前两种部分备份方式,只能备份innodb表,不会备份任何myisam,即使指定了也不会备份。而且要备份的表必须有独立的表空间文件,也就是说必须开启了innodb_file_per_table,更精确的说,要备份的表是在开启了innodb_file_per_table选项之后才创建的。第三种备份方式可以备份myisam表
例如:
innobackupex --user=root --password=123456 --include='^back*[.]num_*' /backup/
备份好之后会在/backup/目录下生成一个以时间戳命名的目录,就是备份的目录
恢复过程同全备的恢复过程:见4.3.1节
4.4、xtrabackup工具
xtrabackup工具有两种常用运行模式:"--backup"和"--prepare"。还有两个比较少用的模式:"--stats"和"--print-param"。
4.4.1、全备和恢复
备份路径由参数--target-dir指定:
xtrabackup --backup --user=root --password=123456 --datadir=/data/mysql --target-dir=/backup/bak_all
准备:
xtrabackup --prepare --target-dir=/backup/bak_all
恢复:xtrabackup自身不能恢复,只能通过拷贝备份集的方式来恢复。例如使用rsync或者cp等。另外,恢复时也一样要求MySQL是stop状态,datadir是空目录。并且拷贝完成后要修改datadir中文件的所有者和属组为mysql用户和组。
service mysqld stop rm -rf /data/mysql/* rsync -azP /backup/bak_all/* /data/mysql chown -R mysql.mysql /data/mysql
4.4.2、增备和恢复
1、全备:
xtrabackup --backup --user=root --password=123456 --datadir=/data/mysql --target-dir=/backup/bak_all
2、增备
xtrabackup --backup --user=root --password=123456 --target-dir=/bacpup/bak1 --incremental-basedir=/backup/bak_all --datadir=/data/mysql/ #增备1
xtrabackup --backup --user=root --password=123456 --target-dir=/bacpup/bak2 --incremental-basedir=/backup/bak1 --datadir=/data/mysql/ #增备2
3、准备
xtrabackup --prepare --apply-log-only --target-dir=/backup/bak_all xtrabackup --prepare --apply-log-only --target-dir=/backup/bak_all --incremental-dir=/backup/bak1 xtrabackup --prepare --target-dir=/backup/bak_all --incremental-dir=/backup/bak2
4、恢复:见4.3.1节全备恢复
其他mysql文章请看:MYSQL学习系列
参考:
《mysql技术内幕:innodb存储引擎》
https://www.cnblogs.com/f-ck-need-u/p/9018716.html#auto_id_13
出处:https://www.cnblogs.com/zsql/
如果您觉得阅读本文对您有帮助,请点击一下右下方的推荐按钮,您的推荐将是我写作的最大动力!
版权声明:本文为博主原创或转载文章,欢迎转载,但转载文章之后必须在文章页面明显位置注明出处,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号