mysql之innodb存储引擎---BTREE索引实现
在阅读本篇文章可能需要一些B树和B+树的基础
一、B树和B+树的区别
1、B树的键值不会出现多次,而B+树的键值一定会出现在叶子节点上,而且在非叶子节点也可能会重复出现
2、B数存储真实数据,B+数叶子节点存储真实数据,非叶子节点存储只存储键值
3、B树的查找效率和键在树中所在的位置有关,B+树的复杂度是固定的,即树的高度
4、B树的键位置不固定,键不重复,节约存储空间,但是在插入和删除等操作性能低。B树的深度较B+树要深,耗费磁盘IO次数就多
二、聚簇索引和辅助索引
1、聚集索引(聚簇索引)
就是按照每张表的主键构造一棵B+树,叶子节点中存放整个表的记录数据,所以聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中的数据也是索引的一部分,每个数据页都是通过双向链表进行连接。叶子节点的数据都是根据主键进行排序的,所以比较适合范围查询和顺序查询。叶子节点存放的是完整的数据记录,非叶子节点存放的是键值以及指向数据页的偏移量(指针)。
聚集索引是逻辑上连续的:一是因为数据页通过双向链表连接,按照主键顺序排序;另一点是每个页面的记录也是通过双向链表进行维护,物理存储上可以同样不按照主键排序。
2、二级索引(辅助索引,非聚集索引)
叶子节点并不包含所有的数据,叶子节点除了包含键值外,还有一个类似指针的东西(用来查找辅助索引中不包含的数据),用来对应聚集索引中的一整行数据。一个表可以有多个辅助索引。就是在使用辅助索引的时候,因为辅助索引只存储了部分数据,如果根据辅助索引查找不到所需要的目标数据,就会通过辅助索引的指针,也就是键值中的值来查找聚集索引中的全部数据,然后根据数据取出我们需要查找的列。
在辅助索引中找不到所需要的数据,称为非覆盖索引,否则为覆盖索引。使用覆盖索引能避免再去访问聚集索引,提高性能。索引的设计很重要。
3、聚集索引和辅助索引的逻辑关系
1、自定义的聚集索引
索引结构:[主键列][TRXID][ROLLPTR][其他建表创建的非主键列]
参与记录的比较列:主键列
内节点的key列:[主键列]+PageNo指针
2、未定义的聚集索引
索引结构:[ROWID][TRXID][ROLLPTR][其他建表创建的非主键列]
参与记录的比较列:ROWID
内节点的key列:[ROWID]+PageNo指针
3、自定义主键的二级唯一索引
索引结构:[唯一索引列][主键列]
参与记录的比较列:唯一索引列,主键列
内节点的key列:[唯一索引列]+PageNo指针
4、自定义主键的二级非唯一索引
索引结构:[非唯一索引列][主键列]
参与记录的比较列:非唯一索引列,主键列
内节点的key列:[非唯一索引列][主键列]+PageNo指针
5、未定义主键的二级唯一索引
索引结构:[唯一索引列][ROWID]
参与记录的比较列:唯一索引列,ROWID
内节点的key列:[唯一索引列]+PageNo指针
6、未定义主键的二级非唯一索引
索引结构:[非唯一索引列][ROWID]
参与记录的比较列:非唯一索引列,ROWID
内节点的key列:[非唯一索引列][ROWID]+PageNo指针
三、BTREE的实现
索引是一种存储方式,与磁盘的息息相关,所以磁盘的性能的高低直接影响数据库的查询性能。磁盘的性能和顺序读写有关。
在数据库的读写时,必须操作的数据为有效数据,否则为无效数据,索引的设计原则是尽可能的较低对无效数据的读取访问。
关系型数据库的特点:
数据按行存储,一行数据中必有键,其他列的值可以看成值,所以每行数据可以看成键值对,键值可以排序,可以组合。
B+树的设计特点:
1、将磁盘或者存储文件划分为许多个大小相同的块或者页,而每个块中可以存储多行数据,多个数据行在一个块内的存储格式可以先不用考虑。这样就迎合了磁盘顺 序读写性能高的特点。
2、一个块的数据组织管理通过双向链表的方式进行管理,
3、一个块内的数据都是有序的,所以在块中查找数据通过二分法查找速度快。
4、B+数的构成就是把每一个块作为树的节点,通过B+树来组织不同块之间的关系。
5、因为数据行是一个键值对,正好B+树的内节点存储了键,叶子节点存储数据。通过内节点的键值和一个位置信息(内节点与下层节点或者叶子节点之间的指针), 就可以找到其孩子节点
一个简单的B+树如图所示:
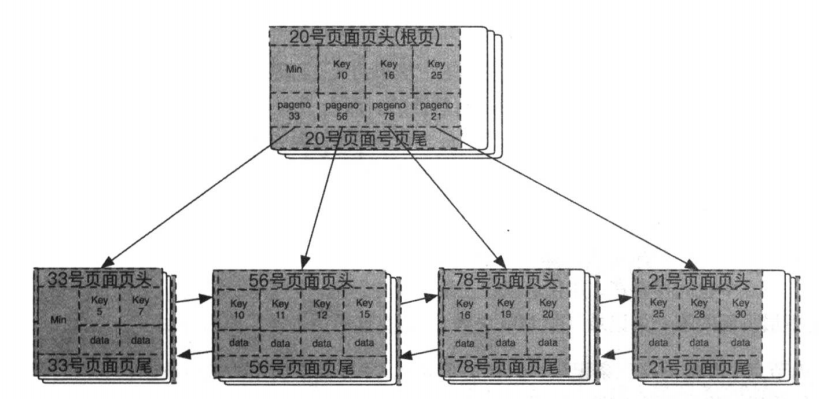
示例:树形结构图
上图是一个基本完善的树结构索引,所有的页都被随机编号。内节点存储包括key和pageno信息,可以理解为键值存储,对于叶子节点就不一样了,叶子节点不会再有指针指向其他页面,所以叶子节点存储的是完整的数据。对于聚集索引,data部分就存储了除主键列之外的所有列的组合,辅助索引存储的就是这行记录对应主键的组合,用于查找要查询的数值。
在每一层的最左边都有一个Min记录,是为了更好的组织树形结构的的指针,用于判断是否已经搜索到了边界,pageno指针用于指向下一层最左边的记录,指向比本页中所有key都小的页面。
每个页都有页头和页尾,用来记录页的存储状态,比如如何存储,存了多少,什么顺序等
所有叶子节点从左到右,从小到大顺序排列,双向链表连接。遍历全表只要遍历所有叶子节点即可。
叶子节点和内节点有重复key,内节点只存储key,又来检索,叶子节点用来存储key和对应的值。
一个页至少要存两条数据,否则B+树就不是B+树了,不能起到一个索引的作用,实质上变成了双向链表。
接下来看一个数据页的页面内容图,如下图所示:

主要结构如下:
文件管理头信息(38)
FIL_PAGE_SPACE_OR_CHECKSUM:存储本页的checksum值,校验页面是否完整
FIL_PAGE_OFFSET:表示该页面在当前表空间的页面号
FIL_PAGE_PRE:用来存储叶子节点的上一个页面,如果已经是最左边页面,则值为FIL_NULL
FIL_PAGE_NEXT:用来存储叶子节点的下一个页面,如果已经是最右边页面,则值为FIL_NULL
FIL_PAGE_LSN:存储当前页面最后一次啊被修改时对应日志的LSN值
FIL_PAGE_TYPE:存储页面类型
FIL_PAGE_FLUSH_LSN:用来存储innodb存储引擎最大被flush到的LSN值。
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID:用来对应是哪一个表空间文件的。
页面信息(56)
PAGE_N_DIR_SLOTS:用来存储slot的个数
PAGE_HEAP_TOP:存储当前页面还没有使用的空间的最小位置
PAGE_N_HEAP:存储当前页面堆管理空间中存储的记录数
PAGE_FREE:用来存储当前页面已经被删除的记录所占用的空间组成的链表首指针
PAGE_GARBAGE:存储当前页面已经被标记为删除的记录数
PAGE_LAST_INSERT:存储当前页面最后的插入记录的位置
PAGE_DIRECTION:表示上次插入的方向
PAGE_N_DIRECTION:表示同一方向连续插入的次数
PAGE_N_RECS:存储当前页面存储的记录数
PAGE_MAX_TRX_ID:用来存储在修改当前页面的所有事务中的最大事务号
PAGE_LEVEL:用来存储B+树到了第几次
PAGE_INDEX_ID:存储当前页面所属索引的id
PAGE_BTR_SEG_LEAF:用来存储B+树叶子段的段头地址
PAGE_BTR_SEG_TOP:存储内节点段的段地址
最大记录(13)和最小记录(13)
最大记录和最小记录的作用:用来判断是否到了页的最边界,起到一个标志的作用
页尾(8):用来检验页面的修改是不是完整的。
四、BTREE的管理
show INDEX from table #查看表的索引信息

Table:表名
Non_unique:非唯一索引,primary key为0,因为主键必须唯一
Key_name:索引名
Seq_in_index:索引中该列的位置
Cloumn_name:索引列名
Collaction:列的存储方式,A表示排序,B+树总是排序,NULL表示无序
Cardinality:表唯一值的数量估值
Sub_part:是否是列的部分索引
Packed:关键字如何被压缩
Null:该列是否允许NULL值
Index_type:索引类型,innodb只支持B+tree索引,所以都为BTREE
Comment:注释
其中Cardinality值非常关键,优化器会根据这个值判断是否使用这个索引,但是这个值并不是实时更新的,可以使用命令analyze table table_name来更新该值,Cardinality是一个预估值,对于大表的统计是通过抽样的形式进行统计的,所以每次统计的值可能是不一样的。
参考:
《msyql运维内参》 《mysql技术内幕:Innodb存储引擎》
出处:https://www.cnblogs.com/zsql/
如果您觉得阅读本文对您有帮助,请点击一下右下方的推荐按钮,您的推荐将是我写作的最大动力!
版权声明:本文为博主原创或转载文章,欢迎转载,但转载文章之后必须在文章页面明显位置注明出处,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号